Spring Cloud - Stream, 분산 캐싱 (1/2)
in DEV on MSA(Spring) DB Eda Event-driven-architecture Mda Message-driven-architecture Spring-cloud-stream Redis Caching
이 포스트는 MSA 를 보다 편하게 도입할 수 있도록 해주는 Spring Cloud Stream 과 Redis 를 사용한 분산 캐싱에 대해 기술한다. 관련 소스는 github/assu10 를 참고 바란다.
이 포스트에선 비동기 메시지를 사용하여 마이크로서비스 간 통신하는 스프링 기반의 마이크로서비스를 설계하는 법을 다룬다.
메시지를 사용하여 상태 변화를 표현하는데 이러한 개념을 EDA (Event Driven Architecture, 이벤트 기반 아키텍처) 혹은 MDA (Message Driven Architecture, 메시지 기반 아키텍처) 라고 한다.
EDA 기반의 방식을 사용하면 서비스들을 높은 수준으로 분리할 수 있다.
이제 동기식과 비동기식 방식의 상태 변화 전달의 차이점과 EDA 의 장단점, 그리고 직접 EDA 를 구축해보도록 하자.
나아가 후반부엔 Redis 와 Kafka 를 사용하여 EDA 기반의 분산 캐싱을 구현해 본다.
1. EDA (이벤트 기반 아키텍처) 와 캐싱 솔루션
EDA 에 대해 알아보기 전에 먼저 캐싱 솔루션에 대해 알아본다.
캐시를 사용하는 가장 큰 이유는 바로 성능 향상이다.
예를 들어 회원 데이터의 패턴은 변경이 드물고 거의 회원 테이블의 기본 키로 데이터를 조회한다. 이런 경우 DB 액세스 없이 회원 데이터를 조회(=캐싱)할 수 있다면 응답 시간과 비용이 크게 절감될 것이다.
- 캐싱의 핵심 사항
- 캐싱 데이터는 A 라는 서비스 내의 모든 인스턴스에 대해 일관성이 있어야 함
- 모든 인스턴스에 대해 동일한 캐싱 데이터가 보장되어야 하므로 데이터를 마이크로서비스 안에 로컬 캐싱해서는 안 된다.
- 마이크로서비스를 호스팅하는 컨테이너 메모리에 데이터를 캐싱하면 안 됨
- 런타임 컨테이너는 크기에 제약이 있는 경우가 있으며,
로컬 캐싱은 클러스터 내 다른 모든 인스턴스와 동기화를 보장해야 하므로 복잡성이 증가한다.
- 런타임 컨테이너는 크기에 제약이 있는 경우가 있으며,
- 캐싱 원본 데이터의 변화 (업데이트, 삭제 등) 가 발생할 때 캐싱 데이터를 이용하는 서비스는 상태 변화를 인식할 수 있어야 함
- 캐싱된 데이터를 삭제하고 업데이트할 수 있어야 한다.
- 캐싱 데이터는 A 라는 서비스 내의 모든 인스턴스에 대해 일관성이 있어야 함
위 내용은 두 가지 방법으로 구현이 가능한데 하나는 동기식 요청-응답 모델 로 구현하는 것이고, 다른 하나는 비동기식 요청-응답 모델(EDA) 로 구현하는 것이다.
회원 서비스의 데이터를 이벤트 서비스가 캐싱하여 사용한다고 가정해보자.
회원 서비스의 데이터가 변경되었을 때 동기식 요청-응답 모델은 REST 방식의 엔드포인트를 사용하여 서로 통신한다.
비동기식 요청-응답 모델은 회원 서비스가 데이터 변경을 알리는 비동기 이벤트인 메시지를 큐에 발행(publish)한다. 이벤트 서비스는 중개자(메시지 브로커)에게서 해당 내용을 수신하여 회원 데이터를 캐시에서 삭제한다.
각 방법에 대해 좀 더 상세히 알아봄으로써 EDA 의 장단점을 파악해보자.
1.1 동기식 요청-응답 모델
데이터 캐시를 위해 가장 많이 사용되는 분산 키-값 DB 인 레디스를 사용할 것이다.
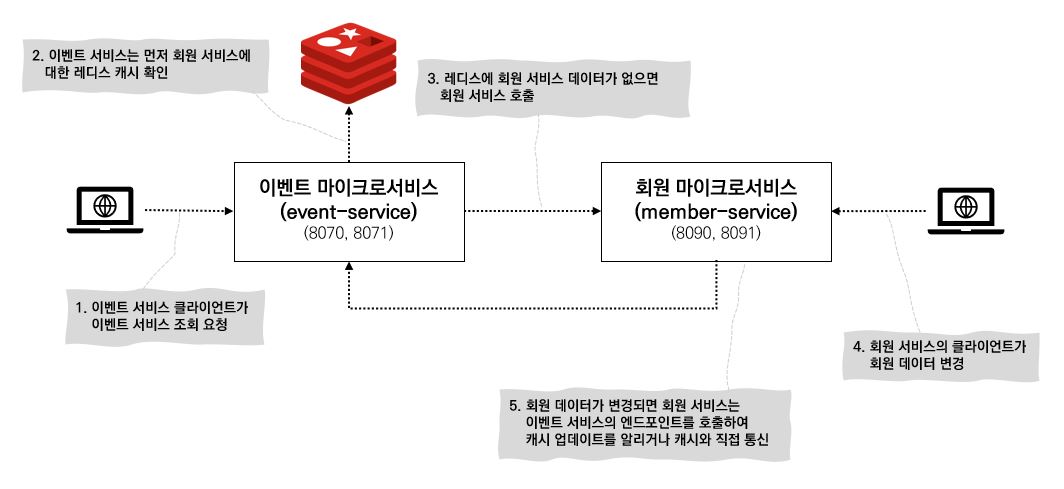
이벤트 서비스에서 회원 데이터를 조회해야 하는 경우 이벤트 서비스는 먼저 레디스 클러스터에서 원하는 데이터가 있는지 확인한다. 만일 원하는 데이터가 레디스에 없다면 REST 기반의 엔드 포인트를 사용하여 회원 서비스를 호출하여 전달받은 데이터를 레디스에 저장 후 클라이언트에게로 반환한다.
이때 회원 서비스 클라이언트가 회원 데이터를 변경하면 회원 서비스는 이벤트 서비스의 캐시 데이터를 무효화하기 위해 이벤트 서비스의 엔드 포인트를 호출한다.
여기서 캐시 무효화를 위해 REST 기반의 엔드 포인트 호출할 때 발생하는 (동기식 상태 변화 전달 시) 문제점이 있다.
- 서비스 간의 강한 결합
- 회원 데이터가 변경되면 회원 서비스는 이벤트 서비스와 직접 통신함으로써 강한 결합이 생긴다.
- 레디스 캐시 데이터의 무효화를 위해 이벤트 서비스가 무효화 용도로 노출한 엔드 포인트를 호출하거나
이벤트 서비스가 소유한 레디스 서버와 직접 통신하여 데이터를 무효화해야 하는데 회원 서비스가 레디스와 직접 통신하면 다른 서비스가 소유하는 데이터 저장소와 통신하게 되는 것이므로 절대 금기해야 할 사항이다.
또한, 회원 서비스가 직접 레디스와 통신하면 이벤트 서비스가 구현한 비즈니스 로직의 규칙에 오류가 발생할 수 있다.
- 쉽게 깨지는 서비스들의 관계
- 이벤트 서비스가 다운되거나 느려지면 회원 서비스는 이벤트 서비스와 직접 통신하므로 영향을 받는다.
- 레디스 서버가 다운되면 두 서비스 모두 다운될 가능성도 있다.
- 새로운 소비자 추가 시 유연하지 못한 구조
- 회원 데이터의 변경 수신이 필요한 다른 서비스 추가 시 회원 서비스는 해당 서비스 호출을 호출해야 한다.
즉, 회원 서비스의 코드 수정 및 패치가 필요하다.
- 회원 데이터의 변경 수신이 필요한 다른 서비스 추가 시 회원 서비스는 해당 서비스 호출을 호출해야 한다.
1.2 비동기식 요청-응답 모델 (EDA)
메시징 방식을 사용하면 이벤트 서비스와 회원 서비스 사이에 큐를 삽입하는데 이 큐의 용도는 회원 데이터를 조회하는데 사용되는 것이 아니라 회원 데이터의 상태가 변할 때 회원 서비스가 메시지를 발행하는데 사용된다.
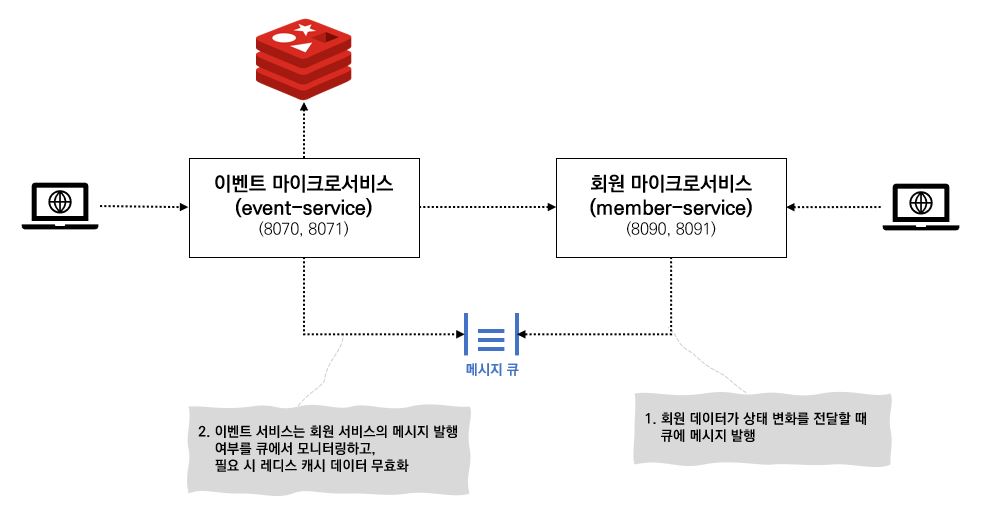
회원 데이터가 변경될 때마다 회원 서비스는 큐에 메시지를 발행하는데, 이벤트 서비스는 메시지 큐를 모니터링하고 있다가 메시지가 들어오면 레디스 캐시의 회원 데이터를 무효화한다.
중개자 역할을 하는 메시지 큐를 도입 시 아래와 같은 장점이 있다.
- 느슨한 결합
- 동기식 통신의 의존성을 완전히 제거할 수는 없지만 회원 데이터를 조회하는 엔드 포인트만 노출함으로써 의존성을 줄일 수 있다.
- 데이터 상태 변화를 전달하는 과정에서 두 서비스가 서로 연관이 없으므로 결합이 사라진다.
- 내구성
- 큐가 존재함으로써 이벤트 서비스(=Consumer) 가 다운되어도 메시지 전달을 보장할 수 있고,
회원 서비스는 이벤트 서비스가 가용상태가 아니더라도 메시지를 계속 발행할 수 있다.
(큐에 저장된 메시지는 이벤트 서비스가 가용상태가 될 때까지 유지됨)
- 큐가 존재함으로써 이벤트 서비스(=Consumer) 가 다운되어도 메시지 전달을 보장할 수 있고,
- 유연성
- 회원 서비스는 누가 메시지를 사용하는지 모르기 때문에 원래 발신 서비스에 영향을 주지 않으면서 새로운 메시지 소비자(=새로운 기능)을 쉽게 추가할 수 있다.
(기존 서비스에 영향을 주지 않으면서 새로운 기능을 추가)
- 회원 서비스는 누가 메시지를 사용하는지 모르기 때문에 원래 발신 서비스에 영향을 주지 않으면서 새로운 메시지 소비자(=새로운 기능)을 쉽게 추가할 수 있다.
- 확장성
- 메시지가 큐에 저장되기 때문에 회원 서비스 (=Publisher) 는 응답을 기다리지 않아도 된다.
- 큐에서 메시지를 읽는 이벤트 서비스(=Consumer) 가 메시지를 빠르게 처리하지 못하면 Consumer 인스턴스를 늘려 처리 속도를 줄일 수 있다.
1.3. EDA 단점
EDA 역시 단점이 있기 때문에 아래 내용을 주의하여 설계하여야 한다.
- 메시지 처리에 대한 다양한 시나리오 파악
- 단순히 메시지 발행/소비 방법 이상의 전반적인 흐름 파악이 필요하다.
- 예를 들어 메시지가 반드시 순서대로 처리되어 하는 로직이 있다면 모든 메시지를 서로 독립적으로 소비하도록 구성해야 한다.
즉, 데이터 상태 변화를 엄격하게 다뤄야 하거나 예외 발생, 순서대로 반드시 처리되어야 하는 기능은 로직 설계 단계에서부터 고려되어야 한다. - 메시지 실패 시 에러 처리 후 재시도 할 것인지 실패한 채로 둘 것인지 등 전반적으로 고려할 부분이 많다.
- 메시지 로깅
- 웹 서비스 호출과 메시징을 경유하는 트랜잭션을 추적하기 위해 상관관계 ID를 사용하여 디버깅에 문제가 없도록 해야 한다.
- 상관관계 ID 는 트랜잭션 시작 시점에 생성되는 고유한 숫자로 메시지 발행/소비 시에도 함께 전달된다.
- 메시지 추적 (메시지 코레오그래피, message choreography)
- EDA 는 선형적으로 처리되지 않기 때문에 비즈니스 로직 추론이 더 어려워진다.
따라서 EDA 기반의 디버깅은 트랜잭션의 순서가 바뀌고 다른 시점에 실행될 수 있는 서비스들의 로그를 꼼꼼히 살펴보아야 한다.
- EDA 는 선형적으로 처리되지 않기 때문에 비즈니스 로직 추론이 더 어려워진다.
2. 스프링 클라우드 스트림
스프링 클라우드 스트림은 애플리케이션에 메시지 발행자와 소비자를 쉽게 구축할 수 있는 애너테이션 기반 프레임워크다.
스프링 클라우드 스트림은 메시징 플랫폼의 구현 세부 사항(소스, 채널, 바인더)을 추상화하고, 여러 메시지 플랫폼 (Kafka, RabbitMQ 등) 과 사용될 수 있다.
이 포스트에선 Kafka 메시지 버스(메시지 브로커)를 사용할 것이다.
Kafka 는 비동기적으로 메시지 스트림을 보낼 수 있는 경량의 고성능 메시지 버스이다.
이제 스프링 클라우드 스트림 아키텍처에 대해 알아보도록 하자.
스프링 클라우드 스트림 아키텍처에서 메시지 발행자 (Publisher) 역할을 하는 서비스가 있고, 소비자 (Consumer) 역할을 하는 서비스가 있는데 이 포스트에선 회원 서비스를 발행자, 이벤트 서비스를 소비자로 진행할 것이다.
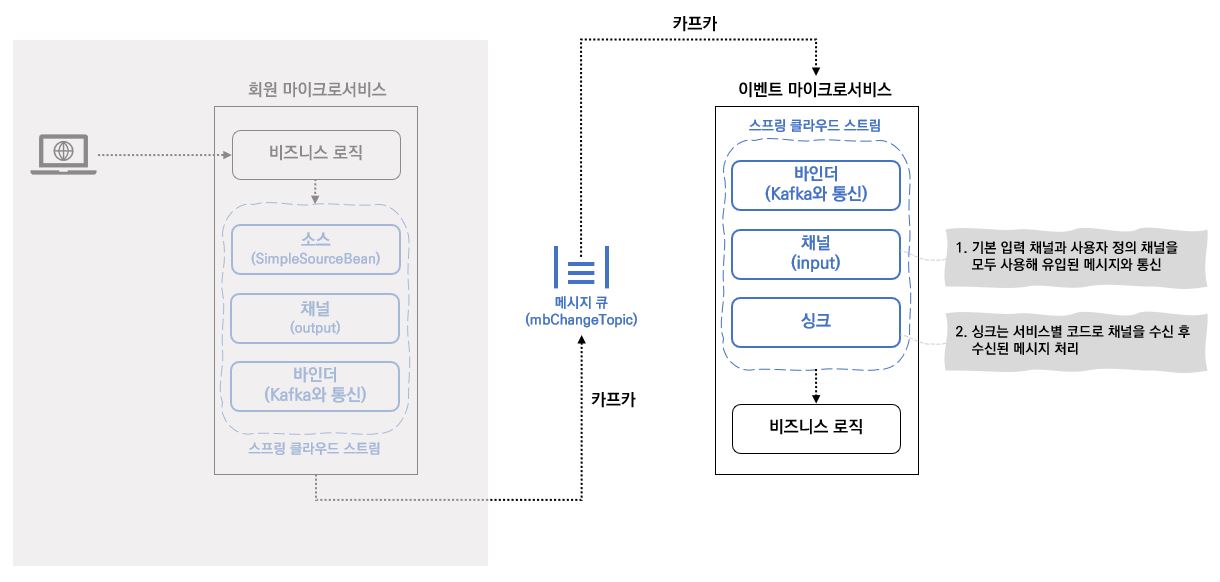
스프링 클라우드 스트림 아키텍처는 SOURCE (소스), CHANNEL (채널), BINDER (바인더), SINK (싱크) 4개의 컴포넌트로 이루어지는데 아래 그림을 보며 이해해보도록 하자.
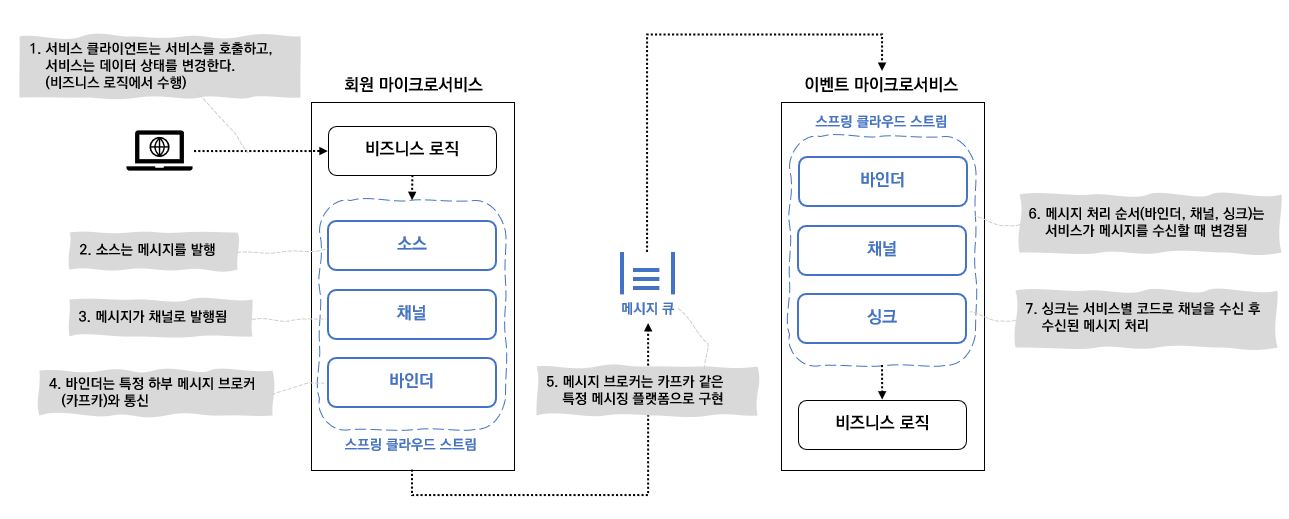
- SOURCE (소스)
- 서비스는 소스를 사용하여 메시지를 발행
- 소스는 발행될 메시지를 표현하는 POJO (Plain Old Java Object) 를 전달받은 애너테이션 인터페이스
- 소스는 메시지를 전달받아 직렬화 (기본 JSON) 하여 채널로 발행
- CHANNEL (채널)
- 메시지를 발생/소비한 후 메시지를 보관할 큐를 추상화한 것
- 채널명은 항상 큐의 이름과 관련이 있지만 코드에서는 큐 이름을 사용하는 것이 아니라 채널명을 사용함
따라서 채널이 읽거나 쓰는 큐 전환 시 코드가 아닌 구성 정보 (*.yaml) 변경
- BINDER (바인더)
- 특정 메시지 플랫폼 (Kafka 와 같은) 과 통신
- SINK (싱크)
- 서비스는 싱크를 사용하여 큐에서 메시지를 수신
- 수신되는 메시지를 위해 채널을 수신 대기하고, 메시지를 다시 POJO 로 역직렬화함
3. 메시지 발행자와 소비자 구현
이제 회원 서비스가 이벤트 서비스로 메시지를 전달할 수 있도록 구성해보자.
3.1. 메시지 발행자 구현 (회원 서비스)
회원 데이터가 추가/수정/삭제될 때마다 회원 서비스가 Spring Cloud Stream Kafka 토픽에 메시지를 발행해서 토픽으로 회원 데이터 변경 이벤트가 발생했음을 알려주도록 수정할 것이다.
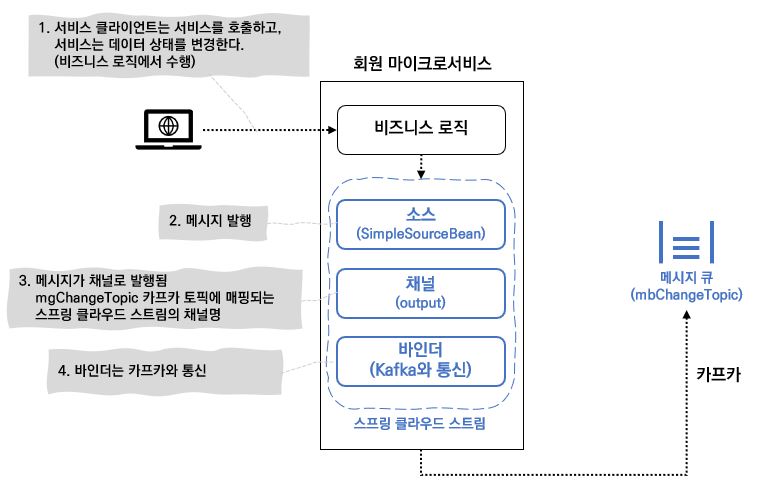
발행되는 메시지 안에는 사용자 아이디, 액션 정보 (Add, Update, Delete) 가 포함된다.
회원 서비스에 스프링 클라우드 스트림과 Spring Cloud Stream Kafka 의존성을 추가한다.
member-service > pom.xml
<!-- 스프링 클라우드 스트림 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<!-- 스프링 클라우드 Spring Cloud Stream Kafka (메시지 브로커) -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
이제 애플리케이션이 스프링 클라우드 스트림의 메시지 브로커와 바인딩하도록 부트스트랩 클래스에 @EnableBinding(Source.class) 를 추가한다. Source.class 를 사용하면 해당 애플리케이션이 Source 클래스에 정의된 채널들을 이용하여 메시지 브로커와 통신한다.
member-service > MemberServiceApplication.java
@SpringBootApplication
@EnableEurekaClient
@EnableResourceServer // 보호 자원으로 설정
@EnableBinding(Source.class) // 이 애플리케이션을 메시지 브로커와 바인딩하도록 스프링 클라우드 스트림 설정
// Source.class 로 지정 시 해당 서비스가 Source 클래스에 정의된 채널들을 이용해 메시지 브로커와 통신
public class MemberServiceApplication {
// ... 생략
}
발행될 메시지를 담을 POJO 를 만든다.
member-service > MemberChangeModel.java
/**
* 발행될 메시지를 표현하는 POJO
*/
public class MemberChangeModel {
private String type;
private String action;
private String userId;
private String correlationId;
public MemberChangeModel(String type, String action, String userId, String correlationId) {
this.type = type;
this.action = action;
this.userId = userId;
this.correlationId = correlationId;
}
// ... getter, setter 생략
}
이제 메시지를 발행할 코드를 구현해보자.
member-service > SimpleSourceBean.java
/**
* 메시지 브로커에 메시지 발행
*/
@Component
public class SimpleSourceBean {
private final Source source;
private static final Logger logger = LoggerFactory.getLogger(SimpleSourceBean.class);
/**
* 스프링 클라우드 스트림은 서비스가 사용할 소스 인터페이스 구현을 주입
*/
public SimpleSourceBean(Source source) {
this.source = source;
}
/**
* 메시지 발행
*/
public void publishMemberChange(String action, String userId) {
logger.debug("======= Sending kafka message {} for User Id : {}", action, userId);
// com.assu.cloud.memberservice.event.model.MemberChangeModel
logger.debug("======= MemberChangeModel.class.getTypeName() : {}", MemberChangeModel.class.getTypeName());
// 발행될 메시지는 자바 POJO
MemberChangeModel change = new MemberChangeModel(MemberChangeModel.class.getTypeName(),
action,
userId,
CustomContext.getCorrelationId());
// 메시지를 보낼 준비가 되면 Source 클래스에 정의된 채널에서 send() 메서드 사용
source.output().send(MessageBuilder.withPayload(change).build());
}
}
스프링 클라우드의 Source 인터페이스를 주입받아 사용하는데 이 Source 는 아래와 같은 구조이다.
Source
// Source interface
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
메시지 토픽에 대한 모든 통신은 채널 이라는 스트림 구조로 발생한다. 채널은 인터페이스로 표현되고, 해당 소스에선 Source 인터페이스를 사용한다.
Source 인터페이스 는 스프링 클라우드에서 정의한 인터페이스로 output() 이라는 단일 메서드를 노출한다.
후반부에 사용자 정의 인터페이스를 사용해서 여러 메시징 채널을 노출해 볼 것이다.
이 Source 인터페이스 는 서비스가 단일 채널에만 발행할 때 사용하기 편리하다.
output() 는 MessageChannel 클래스 타입을 반환하는데 이 MessageChannel 은 메시지 브로커에 메시지를 보내는 방법을 정의한다.
실제 메시지를 발행하는 publishMemberChange() 메서드에서 MemberChangeModel 라는 POJO 를 만든다.
메시지 발행 준비가 되면 source.output() 메서드가 반환한 MessageChannel 클래스의 send() 메서드를 사용한다.
send() 메서드는 스프링 Message 클래스를 매개 변수로 받는데 MessageBuilder 헬퍼 클래스를 사용하여 POJO 를 스프링 message 클래스로 변환한다.
이제 스프링 클라우드 스트림의 Source 가 Spring Cloud Stream Kafka 메시지 브로커와 Spring Cloud Stream Kafka 메시지 토픽에 매핑되도록 구성한다.
각 설명은 주석을 참고하도록 한다.
(기존에 설정한 rabbitMQ 관련 설정과 의존성은 주석처리 필요)
config-repo > member-service.yaml
# 스프링 클라우드 스트림 설정
spring:
cloud:
stream: # stream.bindings 는 스트림의 메시지 브로커에 발행하려는 구성의 시작점
bindings:
output: # output 은 채널명, SimpleSourceBean.publishMemberChange() 의 source.output() 채널에 매핑됨
destination: mbChangeTopic # 메시지를 넣은 메시지 큐(토픽) 이름
content-type: application/json # 스트림에 송수신할 메시지 타입의 정보 (JSON 으로 직렬화)
kafka: # stream.kafka 는 해당 서비스를 Kafka 에 바인딩
binder:
zkNodes: localhost # zkNodes, brokers 는 스트림에게 Kafka 와 주키퍼의 네트워크 위치 전달
brokers: localhost
지금까지 스프링 클라우드 스트림으로 메시지를 발행하는 코드와 Kafka 를 메시지 브로커로 구성하였다.
실제 메시지를 발행하는 엔드포인트는 아래와 같이 구성하면 된다.
member-service > MemberController.java
private final CustomConfig customConfig;
private final EventRestTemplateClient eventRestTemplateClient;
private final SimpleSourceBean simpleSourceBean;
public MemberController(CustomConfig customConfig, EventRestTemplateClient eventRestTemplateClient, SimpleSourceBean simpleSourceBean) {
this.customConfig = customConfig;
this.eventRestTemplateClient = eventRestTemplateClient;
this.simpleSourceBean = simpleSourceBean;
}
// ... 생략
/**
* 단순 메시지 발행
*/
@PostMapping("/{userId}")
public void saveUserId(@PathVariable("userId") String userId) {
// DB 에 save 작업 구현
simpleSourceBean.publishMemberChange("SAVE", userId);
}
메시지에 추가되는 내용들
메시지에는 변경된 userId 만 포함시키고, 변경된 데이터의 복사본은 넣지 않는 것이 좋다.
즉, 변경된 사실만 전파하고 그 서비스들이 DB 에서 새로운 데이터 사본을 가져오도록 구성해야 한다.
이러한 방식은 실행 시간 측면에서는 더 많은 비용이 들지만 항상 최신 데이터 복사본으로 작업하는 것을 보장한다.
(큐에 메시지가 오래 보관되거나 데이터를 포함한 이전 메시지가 실패할 수도 있기 때문에 전달되는 데이터가 최신이라는 보장을 못함)데이터는 비순차적으로 검색될 수 있으므로 변경된 데이터까지 메시지에 포함시킬 경우
메시지의 상태 전달 시엔 메시지에 시간 스탬프를 넣거나 버전 번호를 포함시켜 데이터를 소비하는 서비스가 가진 데이터보다 이전 데이터인지 확인하여야 한다.
3.2. Spring Cloud Stream Kafka 설치
Apache Kafka 에 접속하여 Binary downloads 에서 Kafka 를 다운로드 받은 후 압축을 푼다. 이때 저장 경로가 너무 길면 실행 시 오류가 나니 C 나 D 드라이브 바로 아래에 두도록 한다.
압축을 푼 후 config 폴더 내 zookeeper.properties 와 server.properties 파일을 각각 아래와 같이 수정해준다.
zookeeper.properties, server.properties
# zookeeper.properties
dataDir=C:\\myhome\\03_Study\\kafka_2.13-2.6.0\\zkdata
# server.properties
log.dirs=C:\\myhome\\03_Study\\kafka_2.13-2.6.0\\logs
Kafka 는 Zookeeper 를 사용하기 때문에 주키퍼부터 실행한 후 Kafka 를 실행한다.
-- 주키퍼 실행
C:\kafka_2.13-2.6.0\bin\windows>.\zookeeper-server-start.bat ..\..\config\zookeeper.properties
-- Spring Cloud Stream Kafka 실행
C:\kafka_2.13-2.6.0\bin\windows>.\kafka-server-start.bat ..\..\config\server.properties
-- Spring Cloud Stream Kafka 토픽 리스트 조회
C:\kafka_2.13-2.6.0\bin\windows>.\kafka-topics.bat --list --zookeeper localhost:2181
__consumer_offsets
mbChangeTopic
springCloudBus
아직까지는 딱히 눈으로 확인할만한 요소가 없다. 아래 메시지 소비자 구현 후 제대로 메시지 수신이 이루어지는지 확인해보도록 하자.
3.3. 메시지 소비자 구현 (이벤트 서비스)
이벤트 서비스에 스프링 클라우드 스트림과 Spring Cloud Stream Kafka 의존성을 추가한다.
member-service > pom.xml
<!-- 스프링 클라우드 스트림 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<!-- 스프링 클라우드 Spring Cloud Stream Kafka (메시지 브로커) -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
이제 애플리케이션이 스프링 클라우드 스트림의 메시지 브로커와 바인딩하도록 부트스트랩 클래스에 @EnableBinding(Sink.class) 를 추가한다. Sink.class 를 사용하면 해당 애플리케이션이 Sink 클래스에 정의된 채널들을 이용하여 메시지 브로커와 통신한다.
@EnableBinding(Sink.class) 은 Sink 인터페이스에 기본 채널을 노출한다. Sink 인터페이스의 채널은 input 이라고 하며, 채널로 들어오는 메시지를 수신한다.
Sink input 채널에 들어오는 메시지를 처리하기 위해 @StreamListener 애너테이션을 사용한다.
@StreamListener 은 input 채널에 메시지가 수신될 때마다 해당 메서드가 실행되도록 스트림을 설정한다. 스트림은 채널에서 받은 메시지를 MemberChangeModel POJO 로 자동 역직렬화한다.
event-service > EventServiceApplication.java
@SpringBootApplication
@EnableEurekaClient
@EnableResourceServer // 보호 자원으로 설정
@EnableBinding(Sink.class) // 이 애플리케이션을 메시지 브로커와 바인딩하도록 스프링 클라우드 스트림 설정
// Sink.class 로 지정 시 해당 서비스가 Sink 클래스에 정의된 채널들을 이용해 메시지 브로커와 통신
public class EventServiceApplication {
// ... 생략
/**
* 채널에서 받은 메시지를 MemberChangeModel 이라는 POJO 로 자동 역직렬화
* @param mbChange
*/
@StreamListener(Sink.INPUT) // 메시지가 입력 채널에서 수신될 때마다 이 메서드 실행
public void loggerSink(MemberChangeModel mbChange) {
logger.info("======= Received an event for organization id {}", mbChange.getUserId());
}
}
이제 메시지 브로커의 토픽을 input 채널에 매핑한다.
config-repo > event-service.yaml
# 스프링 클라우드 스트림 설정
spring:
cloud:
stream:
bindings:
input: # input 은 채널명, EventServiceApplication 의 Sink.INPUT 채널에 매핑되고, input 채널을 mgChangeTopic 큐에 매핑함
destination: mbChangeTopic # 메시지를 넣은 메시지 큐(토픽) 이름
content-type: application/json
group: eventGroup # 메시지를 소비할 소비자 그룹의 이름
kafka: # stream.kafka 는 해당 서비스를 Kafka 에 바인딩
binder:
zkNodes: localhost # zkNodes, brokers 는 스트림에게 Kafka 와 주키퍼의 네트워크 위치 전달
brokers: localhost
위에 보면 input 이라는 채널이 있는데 이 채널은 부트스트랩 클래스에서 작성한 Sink.INPUT 채널에 매핑한다.
bindings.input.group 은 메시지를 소비할 소비자의 그룹명이다.
동일한 메시지 큐를 수신하는 여러 서비스 모두 많은 인스턴스를 갖고 있는데 서비스 인스턴스 그룹 안에서는 하나의 서비스 인스턴스만 메시지를 사용하고 처리해야 한다.
group 프로퍼티는 서비스 인스턴스 그룹에서 메시지 복사본 하나만 소비할 것을 보장한다.
3.4. 메시지 서비스 확인
이제 회원 서비스와 이벤트 서비스, 주키퍼, Kafka 를 모두 실행한 후 메시지 이벤트가 잘 발행/소비되는지 확인해보도록 하자.
[POST] http://localhost:8090/member/assu
이벤트 서비스 로그에 아래와 같이 출력되는 것을 확인할 수 있다.
INFO 25304 --- [container-0-C-1] c.a.c.e.EventServiceApplication : ======= Received an event for organization id assu
다음 포스트에서 스프링 클라우드 스트림을 사용한 분산 캐싱과 사용자 정의 채널에 대해 알아본다.
