Spring Cloud - Sleuth, Open Zipkin 을 이용한 분산 추적 (1/4) - 이론
in DEV on MSA(Spring), Centralized-log, Elasticsearch, Sleuth, Zipkin, Msa-tracker, Logging-tracker, Monitoring
이 포스트는 MSA 를 보다 편하게 도입할 수 있도록 해주는 Spring Cloud Sleuth, Open Zipkin 에 대해 기술한다.
관련 소스는 github/assu10 를 참고 바란다.
MSA 는 복잡한 모놀리식 시스템을 더 작고 다루기 쉬운 부분으로 분해하는 강력한 설계 패러다임이다.
다루기 쉬운 이 부분들은 독립적으로 빌드 및 배포할 수 있지만, 유연한만큼 복잡해진다.
이러한 특징 때문에 MSA 에 대한 로깅과 모니터링은 큰 고민거리이다.
서로 다른 개별 마이크로서비스에서 발생하는 로그를 연결지어 트랜잭션의 처음부터 끝까지 순서대로 추적해내는 것은 매우 어렵다.
이러한 문제점을 해결하기 위해서 로그 데이터를 인덱싱하고, 검색할 수 있는 중앙 수집 지점을 만들어 전체 서비스 인스턴스의 모든 로그를 실시간 스트리밍하는 방법이 있다.
이 포스트에선 마이크로서비스의 로깅과 모니터링의 필요성에 대해 알아본 후 다양한 아키텍쳐와 기술을 살펴보며 로깅과 모니터링 관련 문제를 해결할 수 있는 방법에 대해 기술한다.
개인적으로 MSA 로 구성된 시스템에서 로그 관리는 정말 중요하다고 생각한다. 운영 시 이슈가 발생했을 때 각 서버에 접속해서 그 순서대로 이슈 추적을 하려고 한다면… 정말 너무 생각하기도 싫다. ㅠㅠ
이 글을 읽고 나면 중앙 집중식 로그관리, 모니터링 및 대시보드 외 아래와 같은 내용을 알게 될 것이다.
- 로그 관리를 위한 다양한 옵션, 도구 및 기술
1. 로그 관리의 난제
로그는 실행 중인 프로세스에서 발생하는 이벤트의 흐름이다.
전통적인 비클라우드 환경에서 클라우드 환경으로 옮겨오면 애플리케이션은 더 이상 미리 정의한 사양의 특정 장비에 종속되지 않는다.
배포에 사용되는 장비는 그때마다 다를 수 있고, 도커 같은 컨테이너는 본질적으로 짧은 수명을 전제로 한다.
즉, 결국 디스크의 저장 상태에 더 이상 의존할 수 없음을 의미한다.
디스크에 기록된 로그는 컨테이너가 재기동되면 사라질 수 있다.
따라서 로그 파일을 로컬 장비의 디스크에 기록하는 것에 의존해서는 절대 안된다.
12요소 애플리케이션에서 말하는 원칙 중 하나는 로그 파일을 애플리케이션 내부에 저장하지 말라는 로그 외부화이다.
12요소 애플리케이션 원칙은 클라우드에서의 운영 - 12요소 애플리케이션 를 참고하세요.
마이크로서비스는 독립적인 물리적 장치 혹은 가상 머신에서 운영되기 때문에 외부화하지 않은 로그 파일은 결국 각 마이크로서비스 별로 파편화된다.
즉, 여러 마이크로서비스에 걸쳐서 발생하는 트랜잭션을 처음부터 끝까지 순서대로 추적하는 것이 불가능해진다는 의미이다.
2. 중앙 집중식 로깅
위와 같은 문제점을 해결하려면 로그의 출처에 상관없이 모든 로그를 중앙 집중적으로 저장, 분석해야 한다.
즉, 로그의 저장과 처리를 서비스 실행 환경에서 분리하는 것이다.
중앙 집중식 로깅의 장점은 로컬 I/O나 디스크 쓰기 블로킹이 없으며, 로컬 장비의 디스크 공간을 사용하지 않는다는 점이다.
이런 방식은 빅데이터 처리에 사용되는 람다 아키텍처와 근본적으로 비슷하다.
람다 아키텍처는 Lambda Architecture 를 참고하세요.
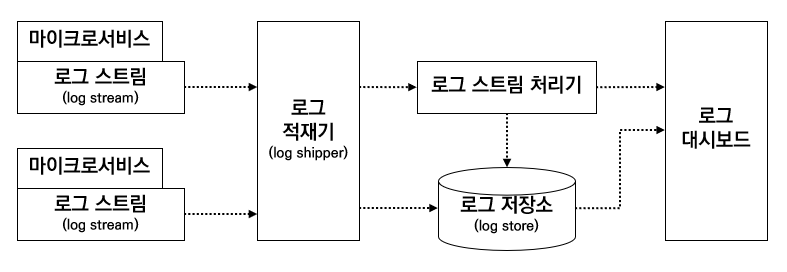
위 그림은 중앙 집중식 로깅 방식을 구성하는 컴포넌트들의 흐름이다. 각 컴포넌트들에 대해선 아래 3.3. 컴포넌트들의 조합 에서 설명한다.
그렇다면 이렇게 중앙 집중식 로깅 시 로그에 필요한 정보는 무엇이 있을까?
각 로그 메시지엔 아래의 내용이 포함되어야 한다.
- 메시지
- 컨텍스트
- 타임스탬프, IP 주소, 사용자 정보, 처리 상세정보(서비스, 클래스, 함수 등), 로그 유형, 분류 등의 정보를 담고 있어야 함
- 상관관계 ID (correlation ID)
- 서비스 호출 사이에서 추적성을 유지하기 위해 사용됨
3. 로깅 솔루션 종류
중앙 집중식 로깅 아키텍처을 구현하는데 사용할 수 있는 옵션은 여러 가지가 있다.
오픈 소스 및 상용 제품이 이미 많이 나와있고, 사내 구축형, 로컬 관리형, 클라우드 기반 등 여러 가지 구현 모델별로 존재한다.
필요한 기능을 이해하고 그에 맞는 올바른 솔루션을 선택하는 것이 중요하다.
[스프링 부트와 사용할 수 있는 로그 수집 솔루션]
(좀 더 자세한 내용은 표 바로 아래에 설명이 있습니다.)
| 제품명 | 구현 모델 | 비고 |
|---|---|---|
Papertail | - 프리미엄 모델 - 상용 - 클라우드 기반 | - https://www.papertrail.com/ - 프리미엄/계층형 가격 모델 - 클라우드 서비스만 지원 |
Sumo Logic | - 프리미엄 모델 - 상용 - 클라우드 기반 | - https://www.sumologic.com/ - 프리미엄/계층형 가격 모델 - 클라우드 서비스만 지원 - 기업용 계정으로 등록 가능 (Gmail 이나 Yahoo 계정 불가) |
Splunk | - 상용만 지원 - 사내 구축형과 클라우드 기반 | - https://www.splunk.com/ - 가장 오래되고 포괄적인 로그 관리 및 수집 도구 -원래는 사내 구축형 솔루션이었으나 이후 클라우드 제공 |
Graylog | - 상용 - 오픈 소스 - 사내 구축형 | - https://www.graylog.org/ - 사내 구축형으로 설계된 오픈 소스 플랫폼 |
ELK | - 상용 - 오픈 소스 - 일반적으로 사내 구축형으로 구현 | - https://www.elastic.co/kr/ - 범용 검색 엔진 - ELK 스택을 이용한 로그 수집 |
상용
일정의 사용료를 지불하고 구입해서 사용하는 소프트웨어
프리미엄 모델
기존 서비스는 무상으로 제공하고 추가적인 기능은 비용을 추가 부과
3.1. 클라우드 서비스
첫 번째 방법은 SaaS 솔루션과 같은 다양한 클라우드 로깅 서비스 사용이다.
SaaS 솔루션은 클라우드 컴퓨팅, IaaS, PaaS, SaaS 를 참고하세요.
Loggly- 가장 많이 사용되는 클라우드 기반 로깅 서비스 중 하나
- 스프링부트 마이크로서비스는
Loggly의Log4j,Logback appenders를 사용하여 로그 메시지를Loggly서비스로 직접 스트리밍 가능
Papertrail- 프리미엄/계층형 가격 모델
- 월간 무료로 100MB 의 로그 수집 (첫 달은 보너스 16GB 추가)
48시간 동안 로그 검색이 가능하고, 7일간 로그 기록됨 - 유료인 경우 한 달에 1GB 의 저장 용량과 1년 간 보관하는 것을 기준으로 월 7달러부터 시작한다.
맞춤형 용량과 보존 기간에 따라 월 230달러까지 다양하다.
애플리케이션이 AWS 에 배포된 경우에는 로그 분석을 위해 AWS CloudTrail 을 Loggly 와 통합할 수 있다. Splunk 는 클라우드 서비스와 사내 구축형 모두 지원한다.
그 외 Logsene, Sumo Logic, Google Cloud Logging, Logentries 가 있다.
3.2. 내장 가능(=사내 구축형)한 로깅 솔루션
두 번째 방법은 사내 데이터 센터 또는 클라우드에 설치되어 전 구간을 아우르는 로그 관리 기능을 제공하는 도구들을 사용하는 것이다.
Graylog- 인기있는 오픈소스 로그 관리 솔루션 중 하나
- 로그 저장소로
ElasticSearch를 사용하고, 메타데이터 저장소로MongoDB사용 Log4j로그 스트리밍을 위해GELF라이브러리 사용
Splunk- 로그 관리 및 분석에 사용하는 상용 도구 중 하나
- 로그를 수집하는 다른 솔루션은 로그 스트리밍 방식을 사용하는데
Splunk는 로그 파일 적재 방식 사용
3.3. 컴포넌트들의 조합
마지막 방법은 여러 컴포넌트들을 선택하여 커스텀 로깅 솔루션을 구축하는 것이다.
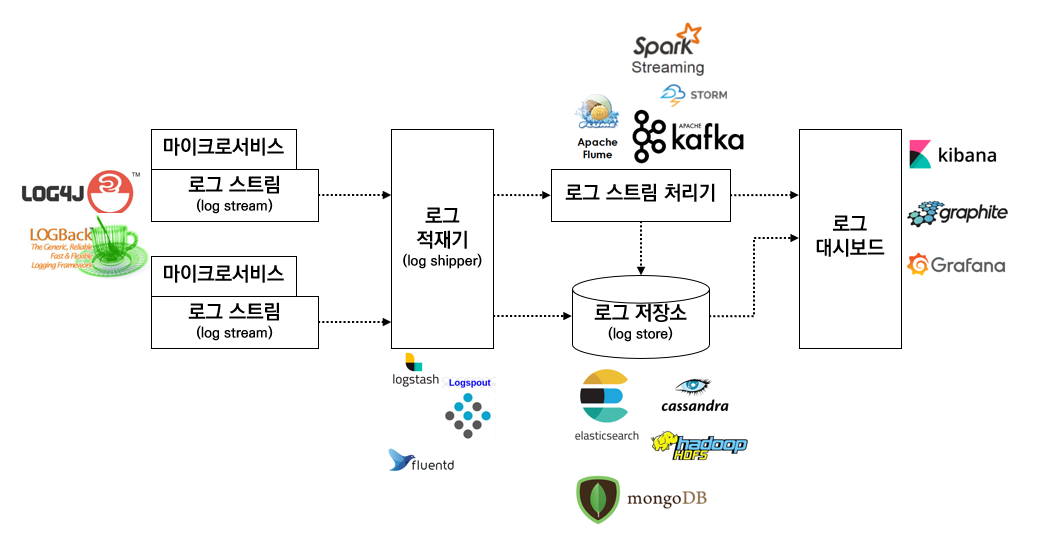
- 로그 스트림 (log stream)
- 로그 생산자가 만들어내는 로그 메시지의 스트림
- 로그 생산자는 마이크로서비스, 네트워크 장비일 수도 있음
Loggly의Log4j,Logback appenders
- 로그 적재기 (log shipper)
- 서로 다른 로그 생산자나 종단점에서 나오는 로그 메시지 수집
- 수집된 로그는 DB 에 쓰거나, 대시보드에 푸시하거나, 실시간 처리를 담당하는 스트림 처리 종단점으로 보내는 등 여러 다른 종담점으로 메시지 보냄
Logstash- 로그 파일을 수집하고 적재하는데 사용할 수 있는 강력한 데이터 파이프라인 도구
- 서로 다른 소스에서 스티리밍 데이터를 받아 다른 대상과 동기화하는 메커니즘을 제공하는 브로커 역할
Log4j와Logback appenders는 스프링부트 마이크로서비스에서Logstash로 그 메시지를 직접 보내는 데 사용 가능Logstash는 스트링부트 마이크로서비스로부터 받은 로그 메시지를ElasticSearch,HDFS(Hadoop Distributed File System, 하둡 분산형 파일 시스템)또는 다른 DB 에 저장
FluentdLogSpout와 마찬가지로Logstash와 매우 유사하지만 도커 컨테이너 기반 환경에서는LogSpout이 더 적합함
- 로그 스트림 처리기
- 신속한 의사 결정에 필요한 실시간 로그 이벤트 분석
- 대시보드로 정보를 전송하거나 알람 공지의 역할
- self-healing system (자체 치유 시스템) 에서는 스트림 처리기가 문제점을 바로잡는 역할을 수행하기도 함 예를 들어 특정 서비스 호출에 대한 응답으로 404 오류가 지속적으로 발생하는 경우 스트림 처리기가 처리 가능
Apache Flume과Kafka를Storm또는Spark Streaming과 함께 사용Log4j에는 로그 메시지를 수집하는 데 유용한Flume appenders가 있음 이러한 메시지는 분산된Kafka메시지 큐에 푸시되고, 스트림 처리기는Kafka에서 데이터를 수집하고ElasticSearch혹은 기타 로그 저장소로 보내기 전에 즉시 처리함
- 로그 저장소 (log store)
- 모든 로그 메시지 저장
- 로그 저장소로 들어오는 데이터는 인덱싱되어 검색 가능한 형식으로 저장됨
- 실시간 로그 메시지는 일반적으로
ElasticSearch에 저장됨
ElasticSearch사용 시 클라이언트가 텍스트 기반 인덱스를 기반으로 쿼리 가능 - 대용량 데이터를 처리할 수 있는
HDFS(Hadoop Distributed File System, 하둡 분산형 파일 시스템)와 같은 NoSQL DB 은 일반적으로 아카이브된 로그 메시지를 저장 MongoDB,Cassandra는 매월 집계되는 트랜잭션 수와 같은 요약 데이터를 저장하는데 사용- 오프라인 로그 처리는
Hadoop의MapReduce프로그램을 사용하여 수행 가능
- 로그 대시보드
- 로그 분석 결과를 그래프나 차트로 나타냄
- 운영 조직이나 관리 조직에서 많이 사용
ElasticSearch데이터 스토어 상에서 사용되는Kibana가 있음- 그 외
Graphite,Grafana도 로그 분석 보고서 표시하는데 사용됨
지금까지 분산 로그 추적에 관한 전반적인 내용을 살펴보았다.
이 후엔 중앙 집중형 로그와 분산 로그 추적을 직접 구현해보는 예제를 포스트하도록 하겠다.
참고 사이트 & 함께 보면 좋은 사이트
- 스프링 마이크로서비스 코딩공작소
- 스프링 부트와 스프링 클라우드로 배우는 스프링 마이크로서비스
- Lambda Architecture
- Zipkin을 이용한 MSA 환경에서 분산 트렌젝션의 추적 #1
