Spring Cloud - Sleuth, Open Zipkin 을 이용한 분산 추적 (3/4) - 로그 추적을 위한 Sleuth 사용
in DEV on MSA(Spring) Centralized-log Sleuth Open-zipkin
이 포스트는 로그 추적을 할 수 있도록 지원하는 Sleuth 사용법에 대해 기술한다. 관련 소스는 github/assu10 를 참고 바란다.
바로 전 포스트인 Spring Cloud Sleuth, Open Zipkin 을 이용한 분산 추적 (2/4) - ELK 스택 에서는 마이크로서비스에서 분산되고 파편화되는 로깅 문제를 중앙 집중형 로깅 방식(ELK Stack)으로 해결하는 방법에 대해 알아보았다.
중앙 집중형 로깅 솔루션을 사용하면 모든 로그를 중앙 저장소에 보관할 수 있지만
여전히 트랜잭션의 전 구간을 추적하는 것은 거의 불가능하다.
여러 마이크로서비스에 걸쳐 있는 트랜잭션의 전 구간을 추적하려면 하나의 연관 ID (Correlation ID)가 필요하다.
이 글을 읽고 나면 아래와 같은 내용을 알게 될 것이다.
- 마이크로서비스의 추적성 확보를 위한 Spring Cloud Sleuth 의 사용법
1. Spring Cloud Sleuth 와 Open Zipkin
Spring Cloud Sleuth 와 Open Zipkin 의 역할은 각각 아래와 같다.
- Sleuth
- 상관관계 ID 를 사용하여 HTTP 호출을 추적하는 스프링 클라우드 프로젝트
- 생성 중인 추적 데이터를 Open Zipkin 에 공급할 수 있는 연결 고리(hook)를 제공
- 생성된 상관관계 ID 를 모든 시스템 호출로 통과시키기 위해 필터를 추가하고, 다른 스프링 컴포넌트와 상호 작용하는 방식으로 활용
- Open Zipkin
- 여러 서비스 사이의 트랜잭션 흐름을 보여주는 오픈 소스 기반의 데이터 시각화 도구
- 트랜잭션을 컴포넌트별로 분해하고 성능 과열점(hotspot) 이 어디서 발생했는지 시각적으로 확인 가능
2. Sleuth
분산 로그 추적은 구간(span) 과 추적(trace) 개념으로 동작한다.
- 구간(span)
- 하나의 작업 단위
- 전체 트랜잭션에서 고유한 숫자
- 예를 들어 하나의 서비스 호출은 64bit 의
스팬 ID(span ID)로 식별됨
- 추적(trace)
- 여러 개의 구간으로 이루어진 한 세트의 트리 구조
- 전체 트랜잭션의 일부를 나타내는 고유 ID
추적 ID(trace ID)를 사용하여 서비스의 호출을 처음부터 끝까지 추적 가능
아마 위의 설명만으론 잘 이해가 되지 않을 수 있는데 아래 그림을 보면 이해하는데 도움이 될 것이다.

위 다이어그램처럼 동일한 추적 아이디가 모든 마이크로서비스에 전달되어 트랜잭션의 전 구간을 추적할 수 있게 된다.
전에 포스트했던 Spring Cloud - Netflix Zuul(2/2) 의 2. 사전 필터와 3. 사후 필터에서 트랜잭션을 추적할 목적으로 아래와 같은 방식으로 상관관계 ID 를 활용하였다.
- Zuul 의 사전 필터를 사용하여 유입되는 모든 HTTP 요청을 검사하고 상관관계 ID 가 없으면 삽입
- 서비스에서 나가는 호출의 HTTP 헤더에 상관관계 ID 를 추가하여 서비스의 모든 HTTP 호출이 상관관계 ID 를 전파할 수 있도록 인터셉터 작성
Sleuth는 위 과정의 복잡성을 아래와 같이 관리한다.
- 상관관계 ID 가 없으면 상관관계 ID 를 생성하여 서비스 호출에 주입
- 서비스에서 나가는 호출에 대한 상관관계 ID 전파를 관리하여 트랜잭션의 상관관계 ID 를 자동으로 나가는 호출에 추가함
- 상관관계 정보를 스프링 MDC 로그에 추가하여 상관관계 ID 가 스프링 부트의 기본 SLF4J와 Logback 구현으로 자동적으로 로깅됨
- 선택적으로 서비스의 추적 정보를 Open Zipkin 분산 추적 플랫폼에 전송
이제 마이크로서비스에 Sleuth를 적용해보도록 하자.
2.1. 마이크로서비스에 Sleuth 추가
Sleuth를 적용하는 방법은 매우 간단하다.
각 마이크로 서비스에 Sleuth 의존성을 추가하기만 하면 된다.
member-service, event-service > pom.xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
이제 각 서비스는 아래와 같은 기능을 할 수 있다.
- 서비스로 들어오는 모든 HTTP 호출을 검사하고 그 호출에서 Sleuth의 추적 정보가 존재하는지 확인한다. 추적 정보가 있다면 마이크로서비스로 전달된 추적 정보를 수집하여 로깅을 위해 서비스에 제공한다.
- 서비스에서 나가는 모든 HTTP 호출과 스프링이 메시징 채널의 메시지에 삽입한다.
이제 두 개의 마이크로서비스를 통과하는 API 호출 후 의존성을 추가하기 전과 후의 로그를 비교해보자.
http://localhost:5555/api/mb/member/gift/ASSU
Sleuth 의존성 추가 전
-- member-service
2021-01-30 20:46:40.566 INFO 22744 --- [nio-8090-exec-1] MemberController : [MEMBER] gift/{name} logging...name is ASSU.
-- event-service
2021-01-30 20:46:40.919 INFO 21756 --- [nio-8070-exec-1] EventController : [EVENT] Gift is ASSU logging...gift is {}.
Sleuth 의존성 추가 후
-- member-service
2021-01-30 20:48:25.056 INFO [,e6fcd377c5c46bd9,e6fcd377c5c46bd9,true] 15792 --- [nio-8090-exec-1] MemberController : [MEMBER] gift/{name} logging...name is ASSU.
-- event-service
2021-01-30 20:48:25.438 INFO [,e6fcd377c5c46bd9,15a21c3858c0b1e0,true] 22052 --- [nio-8070-exec-1] EventController : [EVENT] Gift is ASSU logging...gift is {}.
INFO 다음에 이상한 문구가 찍힌 것이 보일 텐데 각 항목의 의미는 아래와 같다. [,e6fcd377c5c46bd9,e6fcd377c5c46bd9,true]
- 첫 번째 값 : 어플리케이션 이름 (application.yaml 에 spring.application.name 을 지정해주었지만 빈 값으로 나온다. 혹시나 하여 bootstrap.yaml 에 지정하니 정상적으로 출력됨)
- 두 번째 값 : 추적 ID (하나의 트랜잭션의 고유 식별자이며 해당 요청의 모든 서비스 호출에 전달됨)
- 세 번째 값 : 스팬 ID (하나의 트랜잭션의 일부를 나타내는 고유 ID)
- 네 번째 값 : Open Zipkin 전송 여부 (추적을 위해 Open Zipkin 서버에 데이터 전송 여부를 결정하는 플래그, Open Zipkin은 다음 포스트 때 다룰 예정)
회원 서비스와 이벤트 서비스의 추적 ID 는 e6fcd377c5c46bd9 로 동일하고 스팬 ID 는 각각 e6fcd377c5c46bd9, 15a21c3858c0b1e0 로 다른 것을 알 수 있다.
이렇게 다른 스팬 ID 로 트랜잭션의 구간을 구별할 수 있다.
네 번째 값인 Open Zipkin 전송 여부는, 대용량 서비스에서 생성된 추적 데이터의 양은 엄청나고 모두 가치가 있는 것은 아니기 때문에 트랜잭션을 Open Zipkin에 보낼 시점과 방법을 결정하는 데 사용된다.
그럼 Kibana 에 접속하여 로그를 확인해보자.
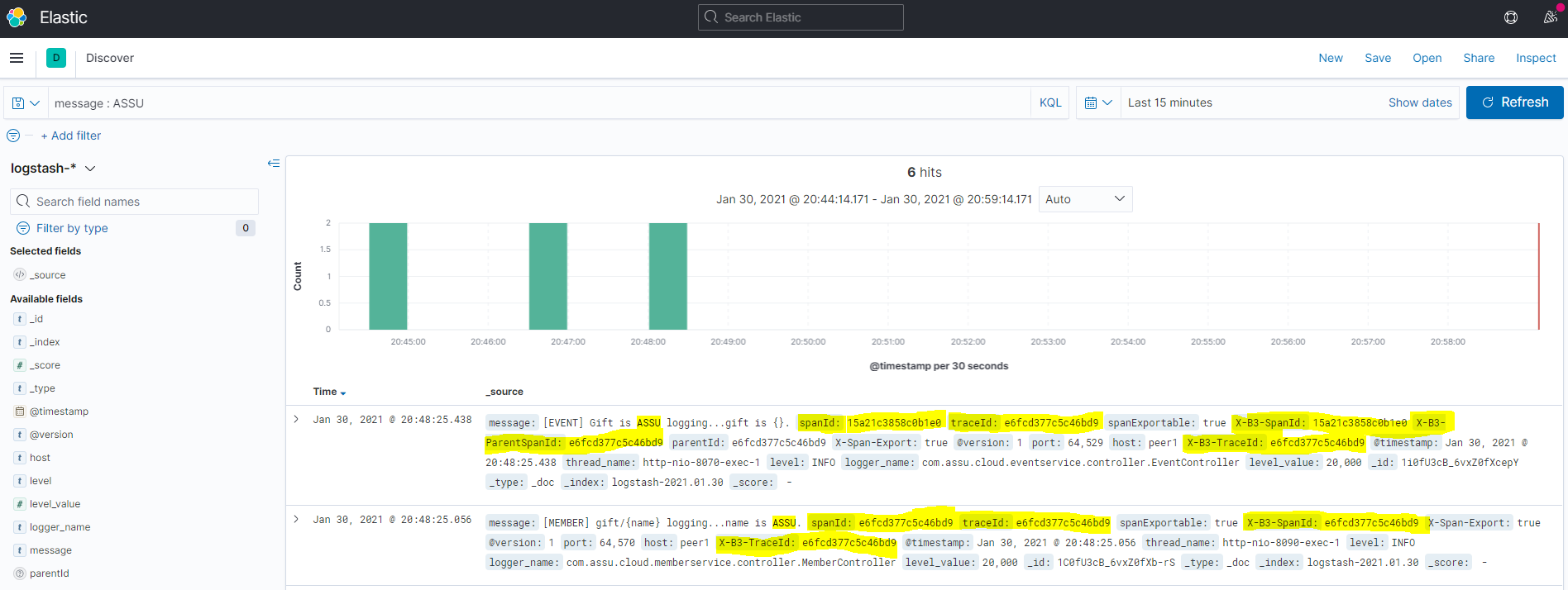
kibana 상의 로그를 보면 추적 ID 와 스팬 ID 가 함께 로깅되는 것을 확인할 수 있다. 다른 서비스에 의해 호출당한 로깅의 경우 ParentSpanId, parentId 항목이 있는데 이는 해당 서비스를 호출한 서비스의 SpanId를 의미한다.
지금까지 마이크로 서비스의 추적성 확보를 위해 Sleuth를 사용하여 로그에 추적 ID 와 스팬 ID 를 넣어 활용하는 방법에 대해 알아보았다.
이후엔 전 구간 모니터링에 사용되어 트랜잭션의 흐름을 시각화하는 Open Zipkin에 대해 알아보도록 하겠다.
참고 사이트 & 함께 보면 좋은 사이트
- 스프링 마이크로서비스 코딩공작소
- 스프링 부트와 스프링 클라우드로 배우는 스프링 마이크로서비스
- Spring Cloud Sleuth Reference Documentation
- Open Zipkin 공홈
- 로깅 시스템 #4 - Correlation id & MDC
