Spring Cloud - Sleuth, Open Zipkin 을 이용한 분산 추적 (4/4) - 로그 시각화를 위한 Open Zipkin 사용
in DEV on MSA(Spring) Centralized-log Sleuth Open-zipkin
이 포스트는 로그 시각화를 위한 Open Zipkin 에 대해 기술한다. 관련 소스는 github/assu10 를 참고 바란다.
바로 전 포스트인 Spring Cloud Sleuth, Open Zipkin 을 이용한 분산 추적 (3/4) - 로그 추적을 위한 Sleuth 사용 에서는 분산된 로그를 추적하기 위해 Spring Cloud Sleuth 를 이용하여 추적 ID 와 스팬 ID 를 로그에 추가하는 방법에 대해 알아보았다.
이제 로그를 추적하는 것보다 여러 마이크로서비스 간 트랜잭션의 흐름을 시각화하는 방법에 대해 알아보자.
분산 추적은 여러 마이크로서비스 간에 트랜잭션이 어떻게 흐르고 있는지 시각적으로 보여주는데 이를 APM (Application Performance Management) 와 혼동하지는 말자.
APM 은 실제 코드에서 발생한 저성능 데이터와 CPU, I/O 사용률과 같은 응답 시간 이외의 성능 데이터도 제공할 수 있다.
이 글을 읽고나면 아래와 같은 내용을 알게 될 것이다.
- 마이크로서비스의 전 구간 모니터링에 사용되어 트랜잭션의 흐름을 시각화하는 Open Zipkin 의 사용법
1. Open Zipkin
Open Zipkin 을 사용하면 아래와 같은 이점을 얻을 수 있다.
- 트랜잭션의 소요 시간을 그래픽으로 확인
- 호출에 관련된 각 마이크로서비스별로 소요된 시간 분석 가능
Open Zipkin 은 MSA 에서 성능 문제를 확인할 수 있는 매우 편리한 도구이다.
2. Open Zipkin 설정 및 사용
Open Zipkin 를 사용하기 위해 아래와 같은 순서로 진행을 할 것이다.
- 추적 데이터를 기록할 서비스에서 Sleuth 와 Open Zipkin 의존성 설정
- Open Zipkin 서버에 연결되도록 각 서비스의 스프링 프로퍼티 구성
- 데이터를 수집하는 Open Zipkin 서버 설치 및 구성
- 각 클라이언트가 Open Zipkin 에 추적 정보를 전송하는데 필요한 샘플링 전략 정의 (=추적 레벨 결정)
2.1. 추적 데이터를 기록할 서비스에서 Sleuth 와 Open Zipkin 의존성 설정
각 마이크로 서비스에 Sleuth 와 Open Zipkin 의존성을 추가한다.
zuul, event-service, member-service > pom.xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2.2. Open Zipkin 서버에 연결되도록 각 서비스의 스프링 프로퍼티 구성
zuul, event-service, member-service > application.yaml
spring:
zipkin:
base-url: http://localhost:9411 # Open Zipkin 통신에 사용되는 URL
2.3. 데이터를 수집하는 Open Zipkin 서버 설치 및 구성
Open Zipkin 은 알아보니 Springboot 2.x 버전부터는 사용자 구현을 더 이상 지원하지 않는다고 한다.
좀 더 정확히 말하면 Open Zipkin Custom Server 지원은 하지만 커뮤니티에서는 지원하지 않는다는 의미이다.
그래서 Custom Server 를 만들면서 문제점이 발생할 경우 그것은 전적으로 개발자 책임이라는 이야기도 덧붙이고 있다고 한다.
위와 같은 이유로 Open Zipkin 에서 가이드하는대로 jar 파일을 받아 서버를 기동시킨다.
Open Zipkin jar download 에서 jar 파일을 다운로드 받은 후 아래처럼 기동하여 준다.
인메모리로 연동하여 open zipkin 실행
C:\myhome\03_Study\13_SpringCloud> java -jar .\zipkin-server-2.23.2-exec.jar
elasticsearch 로 연동하여 open zipkin 실행
C:\myhome\03_Study\13_SpringCloud> java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://127.0.0.1:9200 -jar .\zipkin-server-2.23.2-exec.jar
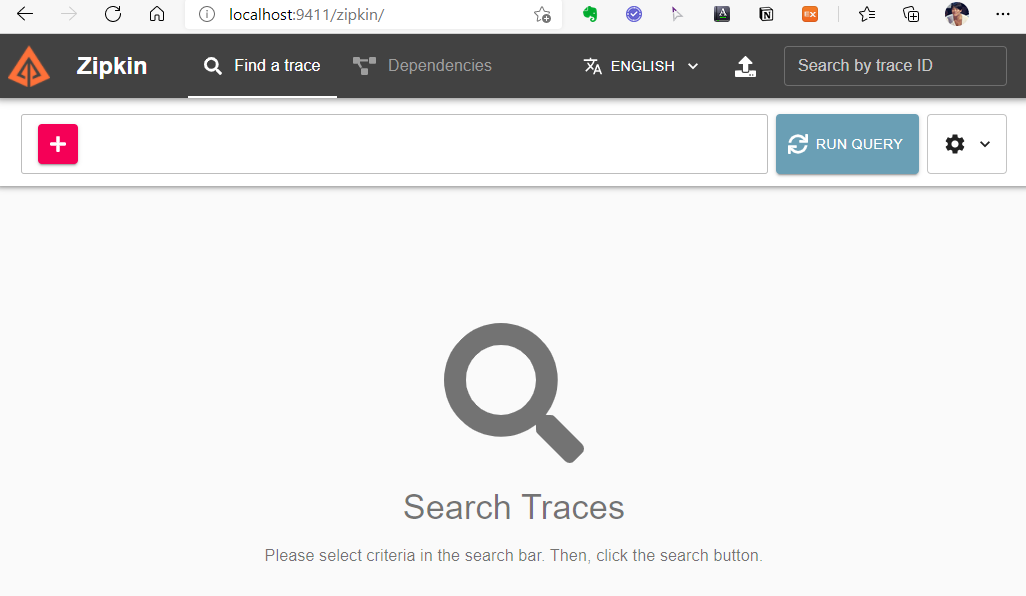
http://localhost:9411 에 접속하면 Open Zipkin 서버의 첫 화면을 볼 수 있다.
Open Zipkin 은 아래 4 가지 저장소를 지원한다.
- 인메모리 데이터
- MySQL
- Cassandra
- ElasticSearch
Open Zipkin 에 사용되는 각 데이터 저장소 구성에 대한 자세한 설명은 Open Zipkin 의 깃허브 저장소인 https://github.com/openzipkin/zipkin/tree/master/zipkin-server 를 참고하세요.
기본적으로 Open Zipkin 은 추적 데이터를 저장하는데 인메모리 데이터 저장소를 사용하지만 인메모리 데이터베이스는 보유가능한 데이터의 양이 제한되어 있고, Open Zipkin 서버가 종료되거나 고장나면 저장된 데이터가 유실되기 때문에 실제 운영 시스템에는 적합하지 않다.
이 포스트에선 인메모리 데이터 저장소와 함께 Open Zipkin 을 사용한다. (ElasticSearch 로 Zipkin 연동하여 보는 법도 있습니다.)
2.4. 각 클라이언트가 Open Zipkin 에 추적 정보를 전송하는데 필요한 샘플링 전략 정의 (=추적 레벨 결정)
지금까지 클라이언트가 Open Zipkin 서버와 통신이 가능하도록 구성하였다.
Open Zipkin 을 사용하기 전에 설정할 것이 하나 더 있는데 각 서비스가 Open Zipkin 에 데이터를 기록할 빈도를 정의하는 것이다.
Open Zipkin 의 기본 설정은 전체 트랜잭션의 10%만 Open Zipkin 서버에 기록한다.
100% 샘플링을 하면 정확한 트랜잭션 추적이 가능하지만 반대로 매번 샘플링 및 로그를 서버에 전송해야 하기 때문에 성능 저하를 유발할 수 있기 때문에 이 비율을 적절하게 조정할 수 있다.
이 트랜잭션 샘플링 비율은 각 서비스의 프로퍼티를 통해 재설정 가능하다.
2.2.0 버전부터는 설정에 관계없이 무조건적으로 1초에 1000샘플링까지 가능하다고 합니다.
event-service, member-service > application.yaml
spring:
zipkin:
enabled: true
base-url: http://localhost:9411 # Open Zipkin 통신에 사용되는 URL
sleuth:
enabled: true
sampler:
probability: 1.0 # Open Zipkin 으로 데이터를 전송하는 트랜잭션 샘플링 비율
3. Open Zipkin 으로 트랜잭션 추적
서비스 운영을 하는 중 이벤트 서비스 중 하나가 느리게 동작한다는 CS 를 받았다고 하자.
이벤트 서비스는 회원 서비스와도 통신을 하고, 두 서비스는 각 다른 데이터베이스를 호출한다.
여기선 두 개의 서비스만을 예로 들었지만 실제 운영 시엔 더 많은 마이크로서비스들이 서로 호출하며 의존하고 있을 것이다.
여기서 어떤 서비스가 성능에 이슈가 발생했는지 추적할 때 일반적으로 아래와 같은 순서로 추적을 할 것이다.
- 의심가는 서비스의 특정 기능들을 수행해가며 성능 저하가 발생한 기능을 찾는다.
- 기능을 찾은 후 소스를 따라가며 성능 저하가 발생할 만한 마이크로서비스 내의 코드를 추측으로 찾아낸 후 수정한다.
(트랜잭션 소요시간 측정 지표가 없으므로 정확한 원인이 아닌 추측에 의한 원인 파악이다) - 수정 후 성능 저하가 개선되었는지 확인한다.
만일 기능 수정 후 성능 저하 개선이 되지 않았다면 다시 1~3의 과정을 거쳐 성능 저하가 발생한 기능을 찾은 후 수정해야 한다.
이 작업은 생각보다 개발자들의 많은 시간을 빼앗는다. (휴… ;ㅁ;)
따라서 트랜잭션에 속한 모든 서비스와 개별 성능 시간을 이해하고 측정하는 것은 MSA 와 같은 분산 아키텍쳐에서 매우 중요한 부분이다.
위에서 Open Zipkin 을 사용하기 위한 모든 설정을 마쳤으니 이제 Open Zipkin 을 이용하여 트랜잭션을 관찰해보도록 하자.
Zuul 을 통해 회원 서비스를 호출하는 간단한 API 를 호출해보자.
흐름은 Zuul 서비스 → 회원 서비스 이다.
member-service > MemberController.java
@GetMapping(value = "name/{nick}")
public String getYourName(ServletRequest req, @PathVariable("nick") String nick) {
logger.info("[MEMBER] ASSU name/{nick} logging...nick is {}.", nick);
return "[MEMBER] Your name is " + customConfig.getYourName() + " / nickname is " + nick + " / port is " + req.getServerPort();
}
이제 Open Zipkin 웹콘솔인 http://localhost:9411/zipkin/ 로 접속하여 Open Zipkin 이 추적한 트랜잭션을 살펴보자.
상단 쿼리 필터 조건에서 serviceName 을 선택하면 Open Zipkin 으로 트랜잭션이 수집된 서비스들의 목록이 리스트업되는데 추적하고자 하는 서비스를 선택 후 좌측의 RUN QUERY 를 눌러 수집된 트랜잭션을 검색한다.
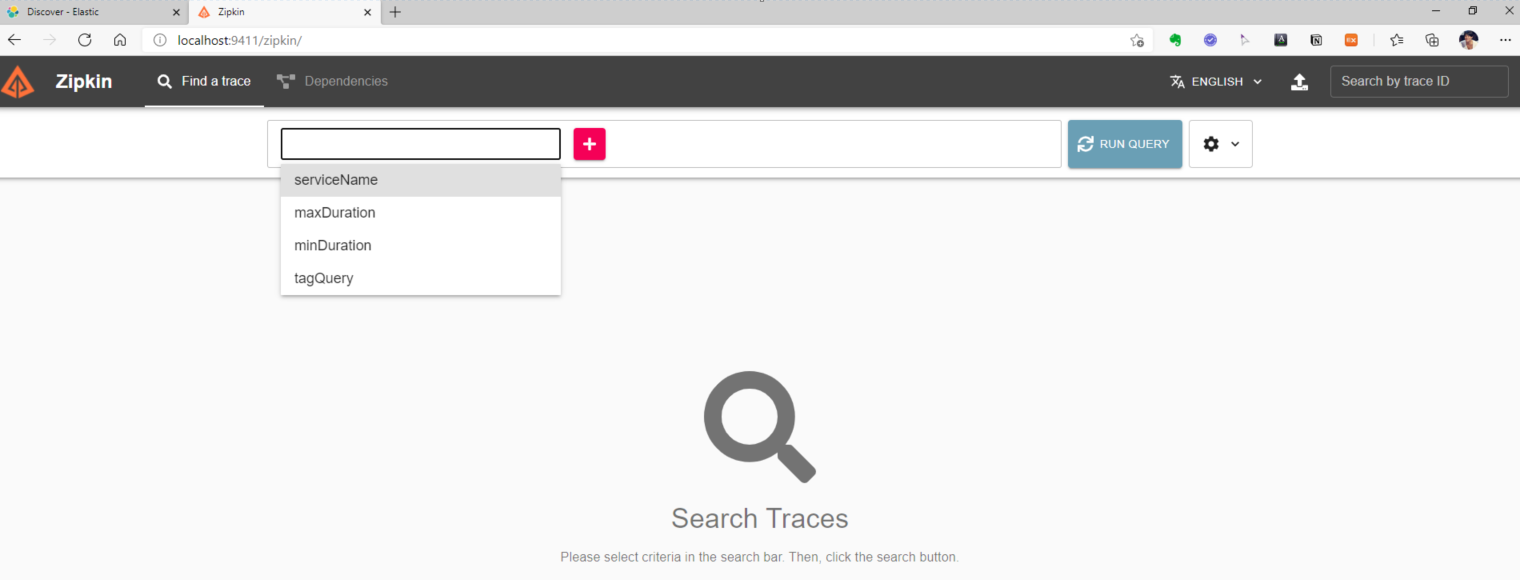

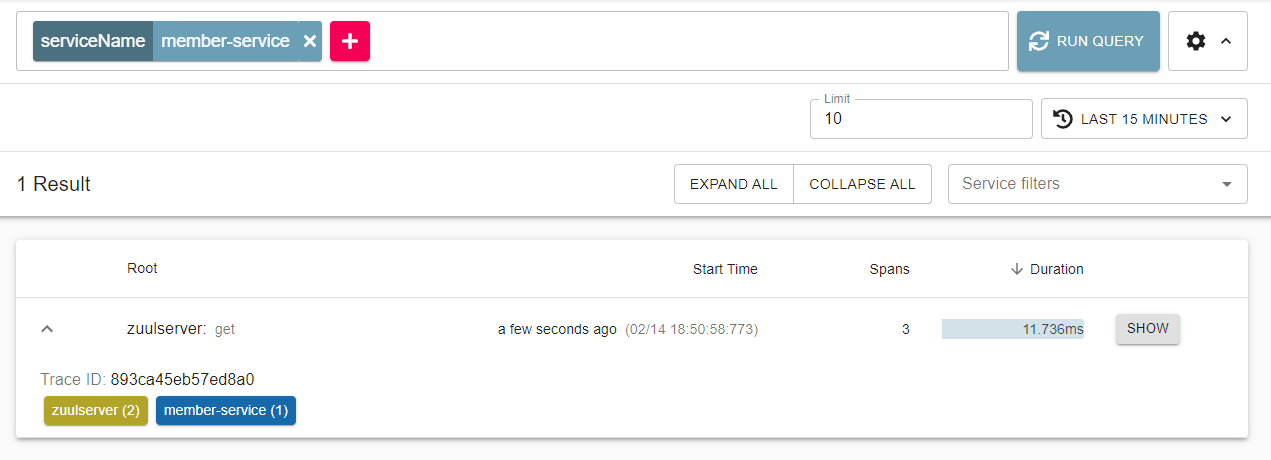
위 그림에서 Open Zipkin 이 수집한 1개의 트랜잭션을 볼 수 있다.
위의 1개의 트랜잭션은 Zuul 게이트웨이에서 2개의 스팬, 회원 서비스에서 1개의 스팬 총 3개의 스팬이 수집되었다.
각 트랜잭션은 하나 이상의 스팬으로 나뉘는데 Open Zipkin 에서 스팬은 타이밍 정보가 포함된 특정 서비스나 특정 호출을 의미한다.
이 트랜잭션의 흐름은 Zuul 서비스 → 회원 서비스 인데 왜 Zuul 게이트웨이의 스팬이 2개가 포착되었을까?
Zuul 게이트웨이는 HTTP 호출을 그대로 전달하는 것이 아니라 유입되는 HTTP 호출이 있다면 그 호출을 종료한 후 대상 서비스(여기에서는 회원 서비스)로 새로운 호출을 만들어 호출한다.
이렇게 원래 호출을 종료함으로써 Zuul은 게이트웨이로 들어가는 개별 호출에 사전 필터, 라우팅 필터, 사후 필터를 추가할 수 있는 것이고, 위 그림에서 Zuul 서비스의 스팬이 2개로 보이는 이유이기도 하다.
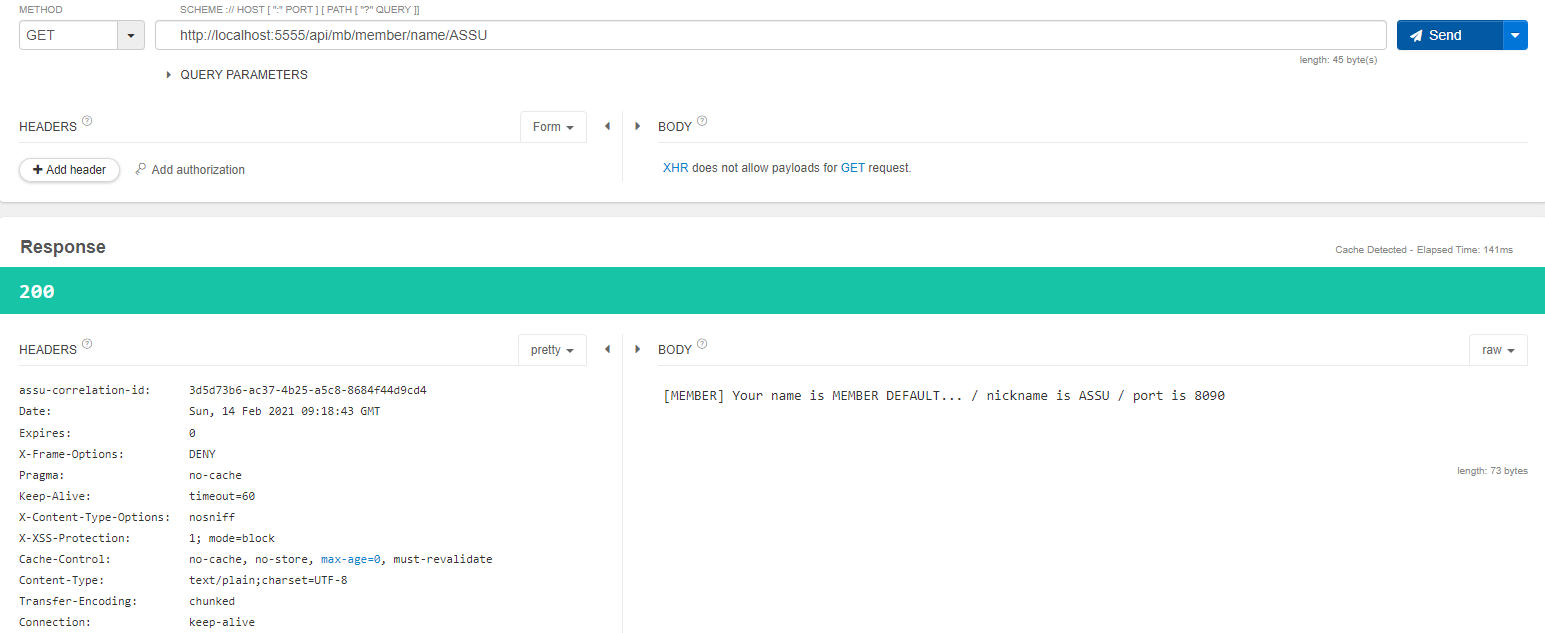
http://localhost:5555/api/mb/member/name/ASSU API 호출은 Trace ID 는 893ca45eb57ed8a0 이고, 총 11.736ms 가 소요된 것을 알 수 있다.
이제 좌측의 SHOW 를 클릭하여 좀 더 상세한 내용을 보자.
아래 화면처럼 트랜잭션 내 각 스팬에 소요된 시간과 순서를 볼 수 있다.
Zuul 관점에서 전체 트랜잭션은 총 11.736 ms 가 소요되었고, Zuul 에서 호출된 회원 서비스의 처리 시간이 전체 호출 시간인 11.736 ms 에서 8.675 ms 를 차지한다.
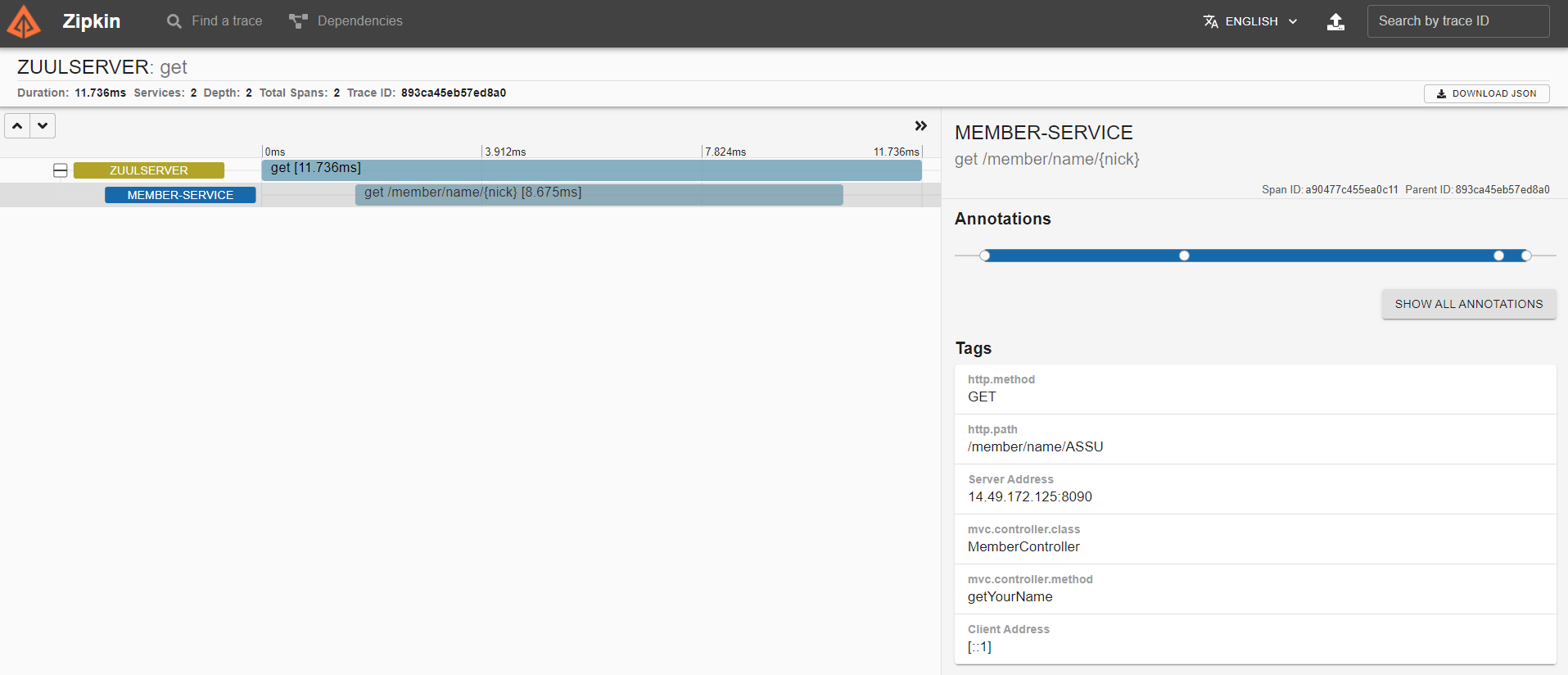
좌측 상단의 SHOW ALL ANNOTATIONS 를 클릭하면 좀 더 상세한, 사실 제일 중요한 정보를 알 수 있다.
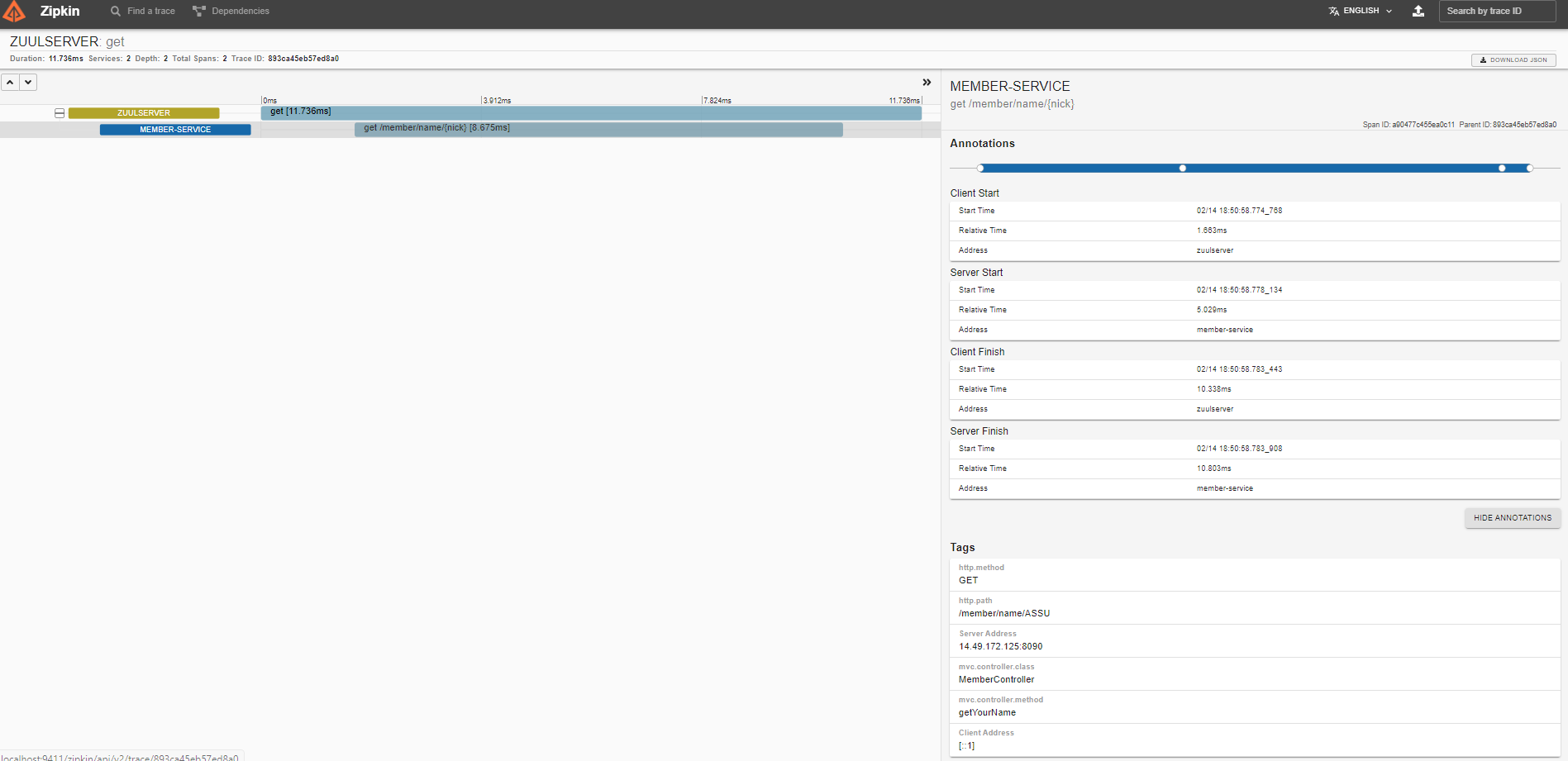
ANNOTATIONS 부분만 따로 분석해보자. 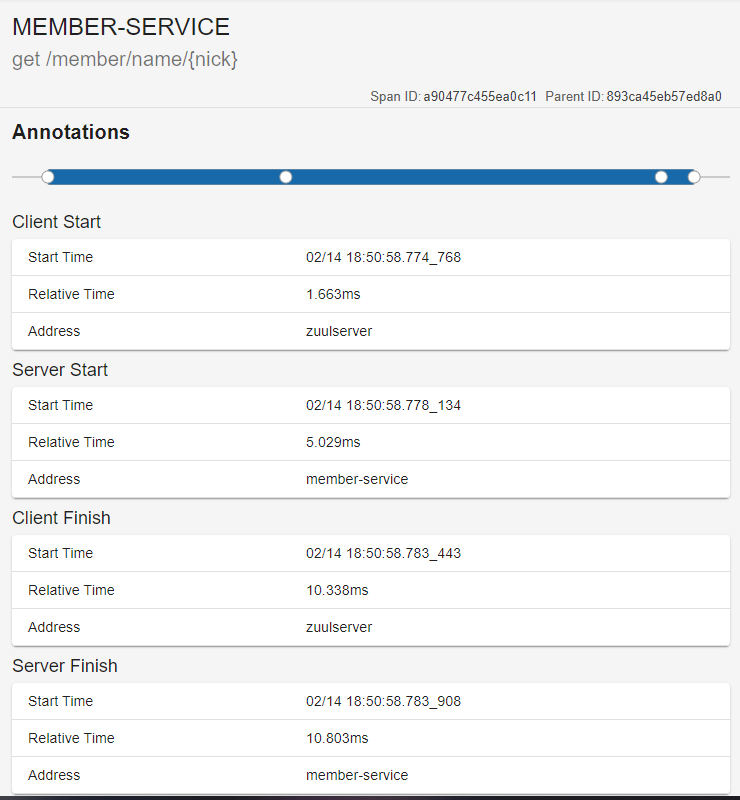
위 내용엔 클라이언트(Zuul)가 회원 서비스를 호출한 시점, 회원 서비스가 호출을 받은 시점과 회원 서비스가 응답한 시점의 정보가 기록되어 있다.
이 정보는 네트워크 지연 문제를 식별하는데 매우 중요한 정보이다.
지금까지 트랜잭션을 시각화해주는 Open Zipkin 에 대해 알아보았다.
통합된 로깅 플랫폼도 중요하지만 마이크로서비스 사이의 트랜잭션을 시각적으로 추적할 수 있는 기능도 운영상 매우 소중한 도구이다.
Open Zipkin 은 서비스 호출이 이루어질 때 서비스 사이에 존재하는 의존성을 확인할 수 있고, 스프링 기반이 아닌 레디스 같은 데이터베이스 서버의 성능을 파악할 수 있도록 사용자 정의 스팬도 재정의하여 사용할 수 있다.
참고 사이트 & 함께 보면 좋은 사이트
- 스프링 마이크로서비스 코딩공작소
- 스프링 부트와 스프링 클라우드로 배우는 스프링 마이크로서비스
- Open Zipkin 공홈
- Open Zipkin Quick Start
- Open Zipkin 설정 1
- Open Zipkin 설정 2
- Open Zipkin Github
- Open Zipkin jar download
- Spring Cloud Zipkin and Sleuth Example
- Open Zipkin 에 사용되는 각 데이터 저장소 구성법
