Redis - 데이터 모델링
이 포스트는 Redis 의 데이터 모델링에 관해 알아본다.
1. 용어
용어에 대한 설명은 Redis 기본, 데이터 처리 명령어, String 의 2. 데이터 처리 명령어 에도 간략히 정리되어 있습니다.
RDBMS 와 비교하여 Key-Value DB 에서 사용되는 용어를 정리하면 아래와 같다.
Table- TableField/Elements- ColumnData Sets- RowKey- PK- RDBMS 에서 테이블이 하나의 PK 와 컬럼들로 구성되는 것처럼 K-V DB 는 하나의 Key 와 하나 이상의 Field/Elements 로 구성
RDBMS 는 NOT NULL, CHECK, UNIQUE 와 같은 제약 조건을 통해 원치 않는 데이터가 특정 컬럼에 저장되는 것을 방지할 수 있지만,
K-V DB 는 이런 제약 조건 기능이 제공되지 않는다.
2. Redis 데이터 모델링 가이드 라인
2.1. Hash-Hash 데이터 모델
- RDBMS 의 Parent-Child 관계와 유사
- 주문(Parent)-운송(Child)
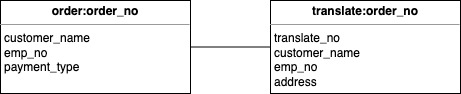
# Parent(주문)
127.0.0.1:6379> hset order:20220801 customer_name "assu" emp_no 1111 payment_type 'credit'
(integer) 3
127.0.0.1:6379> hgetall order:20220801
1) "customer_name"
2) "assu"
3) "emp_no"
4) "1111"
5) "payment_type"
6) "credit"
# Child(운송)
127.0.0.1:6379> hset translate:20220801 translate_no 1112 customer_name 'assu' emp_no 1111 address 'seoul'
(integer) 4
127.0.0.1:6379> hgetall translate:20220801
1) "translate_no"
2) "1112"
3) "customer_name"
4) "assu"
5) "emp_no"
6) "1111"
7) "address"
8) "seoul"
2.2. Hash-List 데이터 모델
- RDBMS 의 Master-Detail 관계와 유사
- 주문공통(Master)-주문상세(Detail)
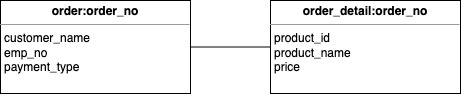
# Master(주문공통)
127.0.0.1:6379> hset order:20220802 customer_name 'assu' emp_no 1111 payment_type 'credit'
(integer) 3
127.0.0.1:6379> hgetall order:20220802
1) "customer_name"
2) "assu"
3) "emp_no"
4) "1111"
5) "payment_type"
6) "credit"
# Detail(주문상세)
127.0.0.1:6379> lpush order_detail:20220802 '<product_id>1</product_id><product_name>mirror</product_name><price>2,000</price>' '<product_id>2</product_id><product_name>apple</product_name><price>5,000</price>'
(integer) 2
127.0.0.1:6379> lrange order_detail:20220802 0 -1
1) "<product_id>2</product_id><product_name>apple</product_name><price>5,000</price>"
2) "<product_id>1</product_id><product_name>mirror</product_name><price>2,000</price>"
2.3. Set/Sorted Set-List 데이터 모델
- RDBMS 의 Tree Structure(계층 구조) 와 유사 (Self-reference 관계)
Tree Structure 구조
댓글 테이블처럼 하나의 테이블과 관계되는 상대 테이블이 자신이 되는 경우

127.0.0.1:6379> sadd reply 'id:1, upper_id:0, content:test111' 'id:2, upper_id:1, content:test111-1'
(integer) 2
127.0.0.1:6379> smembers reply
1) "id:1, upper_id:0, content:test111"
2) "id:2, upper_id:1, content:test111-1"
2.4. List-List 데이터 모델
- N:M 관계
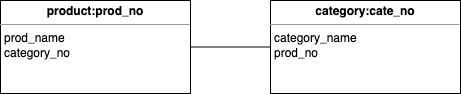
127.0.0.1:6379> lpush product:p111 '{prod_name: apple, cate_no: c111}'
(integer) 1
127.0.0.1:6379> lrange product:p111 0 -1
1) "{prod_name: apple, cate_no: c111}"
127.0.0.1:6379> lpush category:c111 '{category_name: fruit, prod_no: p111}'
(integer) 1
127.0.0.1:6379> lrange category:c111 0 -1
1) "{category_name: fruit, prod_no: p111}"
3. 논리적 DB 설계
- Striping 기법 (분산 저장)
- 수많은 테이블은 데이터 성격, 관리 방안, 성능 이슈등이 모두 다르기 때문에 여러 개의 논리적 DB 에 분산저장하는 것이 원칙
- 하나의 데이터베이스에 모든 테이블과 인덱스를 생성하여 관리하면 장애 발생 시 장애 범위가 너무 넓어서 빠른 복구가 쉽지 않고,
장애로 인한 서비스 지연문제 발생 - 데이터 입력, 수정, 삭제, 조회 시 발생하는 lock 으로 성능 이슈 발생할 수 있으므로 이를 최소화하기 위해 논리적으로 여러 개의 데이터베이스로 분산 설계
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 주종면 저자의 빅데이터 저장 및 분석을 위한 NoSQL & Redis를 기반으로 스터디하며 정리한 내용들입니다.
