Java8 - Stream 으로 병렬 데이터 처리 (1): 병렬 스트림, 포크/조인 프레임워크
in DEV on Java, Java8, Stream, Parallel-stream, Fork-join-framework, Recursivetask
Stream 을 사용하여 외부 반복을 내부 반복으로 바꾸면 자바 라이브러리가 Stream 요소를 처리를 제어하기 때문에 개발자는 컬렉션 데이터 처리 속도를 높이기 위해 따로 고민할 필요가 없다.
Java7 이전에는 데이터 컬렉션을 병렬로 처리하기 힘들었기 때문에 Java7 은 병렬화를 쉽게 수행할 수 있는 포크/조인 프레임워크 기능을 제공했다.
이 포스트에서는 Stream 으로 데이터 컬렉션 관련 동작을 얼마나 쉽게 병렬화할 수 있는지와 Java7 에 추가된 포크/조인 프레임워크가 내부적인 병렬 스트림 처리와 어떤 관계가 있는지 알아본다.
소스는 github 에 있습니다.
목차
1. 병렬 스트림
컬렉션에 stream() 대신 parallelStream() 사용 시 병렬 스트림이 생성된다.
병렬 스트림 사용 시 모든 멀티코어 프로세서가 각각의 chunk 를 처리하도록 할당할 수 있다.
병렬 스트림
각 스레드에서 처리할 수 있도록 스트림 요소를 여러 chunk 로 분할한 스트림
n 을 입력받아 1~n 까지의 합계를 구할 때 순차 리듀싱 방법과 반복형으로 구현할 수 있다.
순차 리듀싱 (Stream.iterate())
// 순차 리듀싱으로 합계 구하기 (with Stream.iterate())
public static long sequentialSum(long n) {
return Stream.iterate(1L, i -> i+1) // 무한 자연수 스트림 생성
.limit(n) // n 개 이하로 제한
.reduce(0L, Long::sum); // 모든 숫자를 더함
// return Stream.iterate(1L, i -> i + 1).limit(n).reduce(Long::sum).get();
}
Stream.iterate() 는 Java8 - Stream 활용 (2): 리듀싱, 숫자형 스트림, 스트림 생성 의 3.4.1.
Stream.iterate()를 참고하세요.
반복형
// 반복형으로 합계 구하기
public static long iterativeSum(long n) {
long result = 0;
for (long i=1L; i<=n; i++) {
result += i;
}
return result;
}
만일 n 이 커지면 병렬로 처리하는 것이 좋다.
병렬로 처리하기 위해선 아래와 같은 사항을 고려해야 한다.
- 결과 변수를 어떻게 동기화할 것인지?
- 몇 개의 스레드를 사용할 것인지?
- 숫자는 어떻게 생성하고, 생성된 숫자는 누가 더할 것인지?
만일 병렬 스트림을 사용하게 되면 위 문제들을 신경쓰지 않아도 된다.
1.1. 순차 스트림을 병렬 스트림으로 변환
병렬 리듀싱 (Stream.iterate())
// 병렬 리듀싱으로 합계 구하기 (with Stream.iterate())
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i+1) // 무한 자연수 스트림 생성
.limit(n) // n 개 이하로 제한
.parallel() // 스트림을 병렬 스트림으로 변환
.reduce(0L, Long::sum); // 모든 숫자를 더함
// return Stream.iterate(1L, i -> i + 1).limit(n).parallel().reduce(Long::sum).get();
}
위 코드는 스트림이 여러 chunk 로 분할되어 있다.
순차 스트림에 parallel 을 호출할 경우 스트림 자체엔 아무런 변화가 없고, 내부적으로 parallel 호출 이후 연산이 병렬로 수행되어야 함을 의미하는 boolean flag 가 설정된다.
parallel() 대신 sequential() 을 호출하면 병렬 스트림을 순차 스트림으로 변경할 수 있다.
만일 parallel() 과 sequential() 을 번갈아 사용할 경우 최종적으로 호출된 메서드가 전체 파이프라인에 영향을 미치기 때문에 만일 마지막으로 호출된 메서드가 parallel() 이라면 파이프라인을 전체적으로 병렬로 실행된다.
병렬 스트림에서 사용하는 스레드 풀 설정
병렬 스트림은 내부적으로 ForkJoinPool 을 사용한다.
기본적으로 ForkJoinPool 은 프로세서 개수(=Runtime.getRuntime().availableProcessors()) 가 반환하는 값에 상용하는 스레드를 갖는다.
만약 ForkJoinPool 의 개수를 수정하려면 아래와 같이 하면 된다.
System.setProperties("java.util.concurrent.ForkJoinPool.common.parallelism", "10");하지만 위 코드는 전역 설정 코드이므로 이후 모든 병렬 스트림 연산에 영향을 준다. (= 하나의 병렬 스트림에 사용할 수 있는 특정한 값 지정 불가)
따라서 특별한 이유가 없다면 ForkJoinPool 의 기본값을 그대로 사용하는 것을 권장한다.
1.2. 스트림 성능 측정
이제 순차 리듀싱 방법과 반복형, 병렬 리듀싱 방법의 성능을 각각 측정해본다.
// Function<T,R> 은 T -> R
// 메서드로 전달된 함수를 10번 반복수행하면서 시간을 ms 단위로 측정하고, 그 중 가장 짧은 시간을 리턴
public static long measureSumPerf_old(Function<Long, Long> adder, long n) {
long fastest = Long.MAX_VALUE;
for (int i=0; i<10; i++) {
long start = System.nanoTime();
long sum = adder.apply(n);
long duration = (System.nanoTime() - start) / 1_000_000;
System.out.println("result: " + sum);
if (duration < fastest) {
fastest = duration;
}
}
return fastest;
}
위 코드를 단순히 합이 아닌 범용적으로 표현해보면 아래와 같다.
// Function<T,R> 은 T -> R
// 메서드로 전달된 함수를 10번 반복수행하면서 시간을 ms 단위로 측정하고, 그 중 가장 짧은 시간을 리턴
public static <T,R> long measureSumPerf(Function<T, R> f, T input) {
long fastest = Long.MAX_VALUE;
for (int i=0; i<10; i++) {
long start = System.nanoTime();
R result = f.apply(input);
long duration = (System.nanoTime() - start) / 1_000_000;
System.out.println("result: " + result);
if (duration < fastest) {
fastest = duration;
}
}
return fastest;
}
반복형, 순차형 리듀싱, 반복형 리듀싱 함수 모두 ParallelStreams 라는 클래스에 작성이 되었을 경우 아래와 같이 측정 결과를 얻을 수 있다.
// 반복형 성능 측정: 2 ms
System.out.println("Iterative Sum done in: " + measureSumPerf(ParallelStreams::iterativeSum, 10_000_000L) + " ms");
// 순차형 리듀싱 성능 측정: 75 ms
System.out.println("Sequential Sum done in: " + measureSumPerf(ParallelStreams::sequentialSum, 10_000_000L) + " ms");
// 병렬형 리듀싱 성능 측정: 111 ms
System.out.println("Parallel Sum done in: " + measureSumPerf(ParallelStreams::parallelSum, 10_000_000L) + " ms");
- 반복형 성능 측정: 2 ms
- 순차형 리듀싱 성능 측정: 75 ms
- 병렬형 리듀싱 성능 측정: 111 ms
for 루프는 저수준으로 작동하며, 기본값을 박싱/언박싱할 필요가 없기 때문에 수행 속도가 빠르다.
병렬형 리듀싱이 더 빠를 것으로 예상했지만 결과는 병렬형 리듀싱이 제일 낮은 성능을 보인 이유는 아래와 같다.
- iterate() 가 박싱된 객체를 생성하기 때문에 이를 다시 언박싱(참조형을 기본형으로 변환)하는 과정이 필요
- iterate() 는 병렬로 실행될 수 있도록 독립적인 chunk 로 분할하기 어려움
- iterate() 는 본질적으로 순차적임
- 이전 연산 결과에 따라 다음 함수의 입력이 달라지기 때문에 iterate() 연산을 chunk 로 분할하기 어려움
- 따라서 병렬로 수행될 수 있는 스트림 모델이 필요함!
Stream.iterate() 는 Java8 - Stream 활용 (2): 리듀싱, 숫자형 스트림, 스트림 생성 의 3.4.1.
Stream.iterate()를 참고하세요.
boxing/unboxing 에 대한 내용은 2.4. 기본형(primitive type) 특화 를 참고하세요.
리듀싱 과정을 시작하는 시점에 전체 숫자 리스트가 준비되지 않았기 때문에 스트림을 병렬 처리하도록 chunk 로 분할할 수 없다.
따라서 스레드를 병렬로 처리하도록 설정해서 각각의 합계가 다른 스레드에서 수행되었지만 결국 순차 처리와 크게 다른 점이 없어 스레드를 할당하는 오버헤드만 증가하게 되었다.
Stream.iterate() 는 병렬 처리하면 오히려 성능 저하!!
병렬 프로그래밍 시 오히려 성능이 더 나빠질 수도 있기 때문에 parallel() 호출 시 내부적으로 어떤 일이 일어나는지 반드시 이해해야 한다.
위 상황을 해결하기 위해 특화된 메서드를 사용하는 방법이 있다.
LongStream.rangeClosed() 는 Stream.iterate() 와 비교했을 때 아래와 같은 장점이 있다.
- 기본형 long 을 직접 사용하기 때문에 박싱/언박싱 오버헤드가 없음
- 쉽게 chunk 로 분할할 수 있는 숫자 범위 생산
LongStream.rangeClosed()에 대한 내용은 Java8 - Stream 활용 (2): 리듀싱, 숫자형 스트림, 스트림 생성 의 2.5. 숫자 범위:range(),rangeClosed()를 참고하세요.
순차 리듀싱 (LongStream.rangeClosed())
// 순차 리듀싱으로 합계 구하기 (with LongStream.rangeClosed())
public static long sequentialSumWithRangeClosed(long n) {
return LongStream.rangeClosed(1, n)
.reduce(0L, Long::sum);
// return LongStream.rangeClosed(1, n).reduce(Long::sum).getAsLong();
}
병렬 리듀싱 (LongStream.rangeClosed())
// 병렬 리듀싱으로 합계 구하기 (with LongStream.rangeClosed())
public static long parallelSumWithRangeClosed(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.reduce(0L, Long::sum);
// return LongStream.rangeClosed(1, n)..parallel().reduce(Long::sum).getAsLong();
}
// 순차형 리듀싱 (LongStream.rangeClosed()) 성능 측정: 2 ms
System.out.println("Range forkJoinSum done in: " + measureSumPerf(ParallelStreams::sequentialSumWithRangeClosed, 10_000_000L) + " ms");
// 병렬형 리듀싱 (LongStream.rangeClosed()) 성능 측정: 0ms
System.out.println("Parallel range forkJoinSum done in: " + measureSumPerf(ParallelStreams::parallelSumWithRangeClosed, 10_000_000L) + " ms");
이제 모든 결과를 비교해보자.
- 반복형 성능 측정: 2 ms
- 순차형 리듀싱 성능 측정: 75 ms
- 병렬형 리듀싱 성능 측정: 111 ms
- 순차형 리듀싱 (rangeClosed())성능 측정: 2 ms
- 병렬형 리듀싱 (rangeClosed())성능 측정: 0 ms
특화되지 않은 스트림을 처리할 때는 오토박싱 등의 오버헤드가 수반되는데 특화된 스트림 처리시엔 오토박싱 오버헤드가 없어 훨씬 성능이 개선된 것을 확인할 수 있다.
병렬형 리듀싱 (rangeClosed())성능의 경우 오버헤드도 없고 실질적으로 리듀싱 연산이 병렬로 수행되어 최적의 성능을 발휘하였다.
어떤 알고리즘을 병렬화하는 것보다 적절한 자료구조를 선택하는 것이 더 중요하다!!
1.3. 병렬 스트림의 올바른 사용
병렬 스트림을 잘못 사용하면서 발생하는 대부분의 문제는 공유된 상태를 바꾸는 알고리즘을 사용하기 때문에 발생한다.
아래는 n 까지의 자연수를 더하면서 공유된 누적자를 바꾸는 알고리즘이다.
public static long sideEffectSum(long n) {
CustomAccumulator accu = new CustomAccumulator();
LongStream.rangeClosed(1, n).forEach(accu::add);
return accu.total;
}
public static class CustomAccumulator {
private long total = 0;
public void add(long value) {
total += value;
}
}
위 코드는 본질적으로 순차 실행할 수 있도록 구현되어 있기 때문에 병렬로 실행하면 올바른 결과가 나오지 않는다.
total 을 접근할 때마다 다수의 스레드에서 동시에 데이터에 접근하는 데이터 레이스 문제가 발생하는데, 동기화 문제를 해결하다보면 결국 병렬화라는 특성이 없어져버린다.
위 코드를 병렬로 실행했을 때 어떤 결과가 나오는지 확인해보자.
public static long sideEffectParallelSum(long n) {
CustomAccumulator accu = new CustomAccumulator();
LongStream.rangeClosed(1, n).parallel().forEach(accu::add);
return accu.total;
}
System.out.println("SideEffect parallel sum done in: " + measureSumPerf(ParallelStreams::sideEffectParallelSum, 10_000_000L) + " ms");
result: 10901587998101
result: 8475200856267
result: 8942643830260
result: 8664621321704
result: 9364311372880
result: 11710442390424
result: 7181707439691
result: 10181629835424
result: 7661764935767
result: 8910549898444
SideEffect prallel sum done in: 0 ms
성능은 둘째치고 정상적인 결과인 50000005000000 이 나오지 않는다.
여러 스레드에서 동시에 누적자인 total += value 를 실행하기 때문이다.
병렬 스트림과 병렬 계산에서는 공유된 가변 상태를 피해야 한다!
이러한 상태 변화를 피하는 방법은 2.1. RecursiveTask<V>> 를 참고하세요.
1.4. 병렬 스트림 사용 시 고려할 점
병렬 스트림 사용 시 어느 상황에서 사용할 지 아래의 내용을 고려하면 도움이 된다.
- 확신이 없다면 직접 측정
- 언제나 병렬 스트림이 순차 스트림보다 빠른 것은 아니므로 어떤 것이 더 좋을지 모르겠으면 직접 성능 측정
- 박싱 연산 주의
- 자동 박싱과 언박싱은 성능을 크게 저하시킴
- Java8 은 박싱 동작을 피할 수 있도록 기본형 특화 스트림 (IntStream, LongStream, DoubleStream) 을 제공하므로 되도록이면 기본형 특화 스트림 사용
- 순차 스트림보다 병렬 스트림에서 성능이 떨어지는 연산 주의
- Stream.limit(), Stream.findFirst() 처럼 순서에 의존하는 연산을 병렬 스트림에서 수행하려면 비싼 비용을 치러야 함
- Stream.findAny() 는 요소의 순서에 상관없이 연산하므로 findFirst() 보다 성능이 좋음
- 정렬된 스트림에 unordered() 를 호출하면 비정렬된 스트림을 얻을 수 있는데 스트림에 N 개 요소가 있을 때 요소의 순서가 상관없다면 (리스트처럼) 비정렬된 스트림에 limit() 을 호출하는 것이 효율적임
- 전체 파이프라인의 연산 비용
- 처리할 요소의 개수 N, 하나의 요소 처리 시 드는 비용 Q 인 경우 전체 스트림 파이프라인 처리 비용은 N*Q 임
- Q 가 높다는 건 병렬 스트림으로 성능을 개선할 수 있는 가능성이 있음을 의미
- 소량의 데이터는 병렬 스트림이 도움되지 않음
- 병렬화 과정에서 생기는 부가 비용을 상쇄할 수 있을만큼의 이득을 얻지 못함
- 자료구조가 적절한 지 확인
- ArrayList 는 LinkedList 보다 효율적으로 분할 가능
- LinkedList 는 분할 시 모든 요소를 탐색해야 하지만, ArrayList 는 요소를 탐색하지 않고도 리스트 분할 가능
- range() factory 메서드로 만든 기본형 스트림도 쉽게 분해 가능
- 뒤에 설명할 커스텀 Spliterator 를 구현해서 분해 과정을 완벽히 제어 가능
- 파이프라인의 중간 연산이 스트림의 특성을 어떻게 바꾸는지에 따라 분해 과정의 성능이 달라짐
- map, SIZED 스트림은 크기를 알고 있기 때문에 정확히 같은 크기의 두 스트림으로 분할할 수 있어서 효과적으로 스트림 병렬 처리 가능
- 필터 연산같은 경우 스트림의 길이를 예측할 수 없으므로 효과적으로 스트림을 병렬 처리할 수 있을 지 알 수 없음
- 최종 연산의 병합 과정 (Collector 의 combiner() 같은) 비용
- 병합 과정의 비용이 비싸다면 병렬 스트림으로 얻은 성능의 이익이 서브 스트림의 부분 결과를 합치는 과정에서 상쇄됨
스트림 소스와 분해성
| 소스 | 분해성 |
|---|---|
| ArrayList | 훌륭함 |
| LinkedList | 나쁨 |
| IntStream.range() | 훌륭함 |
| Stream.iterate() | 나쁨 |
| HashSet | 좋음 |
| TreeSet | 좋음 |
2. 포크/조인 프레임워크
병렬 스트림은 Java7 에서 추가된 포크/조인 프레임워크로 처리된다. 이제 포크/조인 프레임워크에 대해 알아보자.
포크/조인 프레임워크
- 병렬화할 수 있는 작업을 재귀적으로 작은 작업으로 분할한 다음 서브태스크 각각의 결과를 합쳐서 전체 결과를 만듦
- 서브태스크를 스레드 풀(ForkJoinPool) 의 작업자 스레드에 분산 할당하는
ExecutorService 인터페이스를 구현함
2.1. RecursiveTask<V>>
스레드 풀을 이용하기위해선 RecursiveTask<V> 의 서브 클래스를 만들어야 한다.
여기서 V 는 병렬화된 태스트가 생성하는 결과, 혹은 결과가 없을 경우(결과가 없어도 다른 비지역 구조를 바꿀 수 있음)는 RecursiveAction 의 형식이다.
RecursiveTask 를 구현하려면 추상 메서드인 compute() 를 구현해야 한다.
protected abstract V compute();
compute() 메서드는 태스크를 서브 태스크로 분할하는 로직과 더 이상 분할할 수 없을 때 개별 서브 태스크의 결과를 생산할 알고리즘을 정의한다.
따라서 대부분의 compute() 메서드 구현은 아래의 sudo 코드 형식을 갖는다.
if (태스크가 충분히 작거나 더 이상 분할할 수 없는 경우) {
순차적으로 태스크 계산
} else {
태스크를 두 개의 서브 태스크로 분할
태스크가 다시 서브 태스크로 분할되도록 이 메서드를 재귀적으로 호출
모든 서브 태스크의 연산이 완료될 때까지 기다림
각 서브 태스크의 결과를 합침
}
위 알고리즘은 분할 정복 알고리즘 의 병렬화 버전이다.
분할 후 정복 알고리즘
하나의 문제를 작은 문제로 분할해서 해결하는 방식
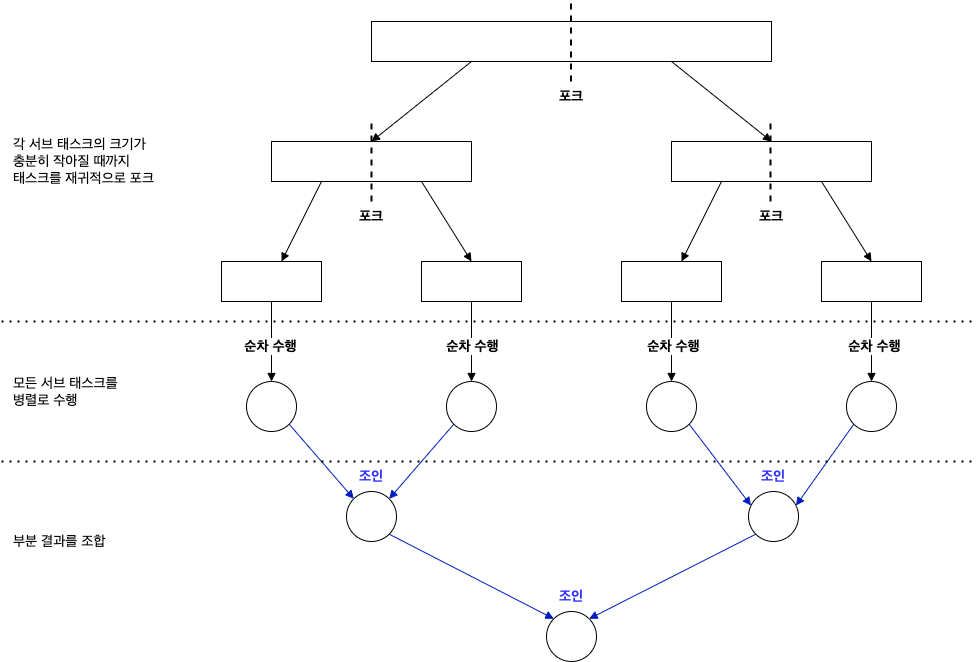
이제 포크/조인 프레임워크를 이용해서 병렬로 범위의 숫자를 더하는 로직을 구현해본다.
먼저 RecursiveTask<V> 를 상속받는 클래스를 구현한다.
import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
*
*/
public class ForkJoinSumCalculator
extends RecursiveTask<Long> { // RecursiveTask 를 상속받아 포크/조인 프레임워크에서 사용할 태스크를 생성
// 이 값 이하의 서브 태스크는 더 이상 분할할 수 없음
//private static final long THRESHOLD = 10_000;
private static final long THRESHOLD = 2;
// 더할 숫자 배열
private final long[] numbers;
// 이 서브 태스크에서 처리할 배열의 초기 위치
private final int start;
// 이 서브 태스크에서 처리할 배열의 최종 위치
private final int end;
// 메인 태스크 생성 시 사용할 공개 생성자
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
// 메인 태스크의 서브 태스크를 재귀적으로 만들 때 사용할 비공개 생성자
private ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
/**
* The main computation performed by this task.
*
* @return the result of the computation
*/
@Override
protected Long compute() {
// 이 태스크에서 더할 배열의 길이
int length = end - start;
System.out.println("[compute()]- length: " + length + ", start: " + start + ", end: " + end);
System.out.println();
// 기준값과 같거나 작으면 순차적으로 결과 계산
if (length <= THRESHOLD) {
System.out.println("call computeSequentially()- length: " + length + ", start: " + start + ", end: " + end);
System.out.println();
return computeSequentially();
} else {
System.out.println("not call computeSequentially()- length: " + length + ", start: " + start + ", end: " + end);
System.out.println();
}
//System.out.println("numbers: " + Arrays.toString(numbers));
System.out.println("start: " + start + ", (start + length/2): " + (start + length/2) + ", end: " + end);
System.out.println();
// 배열의 첫 번째 절반을 더하도록 서브 태스크 생성
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
// ForkJoinPool 의 다른 스레드로 새로 생성한 태스크를 비동기로 실행
// 왼쪽 절반 서브 태스크에 대해 다른 스레드에서 compute() 실행
leftTask.fork();
// 배열의 나머지 절반을 더하도록 서브 태스크 생성
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
// 두 번째 서브 태스크를 동기 실행, 이 때 추가로 분할이 일어날 수 있음
Long rightResult = rightTask.compute();
// 첫 번째 서브 태스크의 결과를 읽거나 아직 결과가 없으면 기다림
Long leftResult = leftTask.join();
// 두 서브 태스크의 결과를 조합한 값이 이 태스크의 결과
System.out.println("(leftResult + rightResult): " + (leftResult + rightResult));
System.out.println();
return leftResult + rightResult;
}
// 더 분할할 수 없을 때 서브 태스크의 결과를 계산
private long computeSequentially() {
System.out.println("[computeSequentially()]- start: " + start + ", end: " + end);
System.out.println();
long sum = 0;
for (int i=start; i < end; i++) {
sum += numbers[i];
}
System.out.println("sum: " + sum);
System.out.println();
return sum;
}
// 생성자로 원하는 수의 배열을 넘겨줌
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1,n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
// 생성한 태스크를 새로운 ForkJoinPool 의 invoke() 메서드로 전달
// ForkJoinPool 에서 실행되는 마지막 invoke() 의 반환값은 ForkJoinSumCalculator 에서 정의한 태스크의 결과가 됨
return new ForkJoinPool().invoke(task);
}
}
호출
public static <T,R> R resultSum(Function<T,R> f, T input) {
R result = f.apply(input);
return result;
}
System.out.println("ForkJoin sum result in: " + resultSum(ForkJoinSumCalculator::forkJoinSum, 8L));
결과
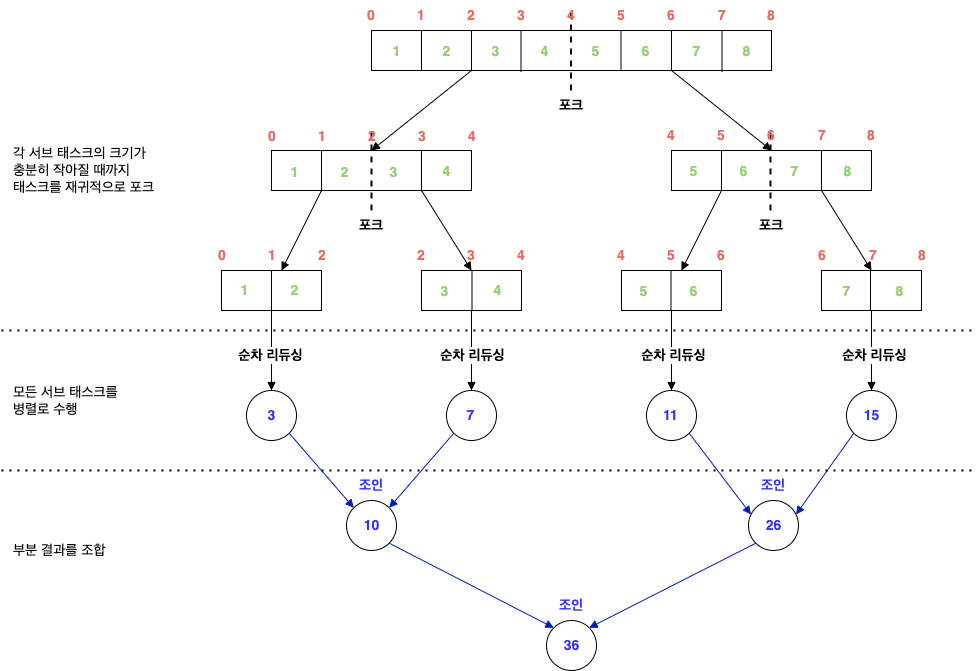
[compute()]- length: 8, start: 0, end: 8
not call computeSequentially()- length: 8, start: 0, end: 8
start: 0, (start + length/2): 4, end: 8
[compute()]- length: 4, start: 4, end: 8
not call computeSequentially()- length: 4, start: 4, end: 8
start: 4, (start + length/2): 6, end: 8
[compute()]- length: 2, start: 6, end: 8
call computeSequentially()- length: 2, start: 6, end: 8
[compute()]- length: 4, start: 0, end: 4
not call computeSequentially()- length: 4, start: 0, end: 4
start: 0, (start + length/2): 2, end: 4
[compute()]- length: 2, start: 4, end: 6
call computeSequentially()- length: 2, start: 4, end: 6
[compute()]- length: 2, start: 2, end: 4
call computeSequentially()- length: 2, start: 2, end: 4
[computeSequentially()]- start: 6, end: 8
[compute()]- length: 2, start: 0, end: 2
call computeSequentially()- length: 2, start: 0, end: 2
[computeSequentially()]- start: 2, end: 4
[computeSequentially()]- start: 0, end: 2
[computeSequentially()]- start: 4, end: 6
sum: 11
sum: 7
sum: 3
sum: 15
(leftResult + rightResult): 10
(leftResult + rightResult): 26
(leftResult + rightResult): 36
ForkJoin sum result in: 36
Process finished with exit code 0
위 코드는 분할/조인되는 과정을 좀 더 살펴보기 위해 THRESHOLD: 2, 전체 배열: 8 로 로그를 찍어본 것이다.
forkJoinSum() 의 new ForkJoinPool().invoke(task) 를 통해 생성한 태스크를 새로운 ForkJoinPool 의 invoke() 메서드로 전달한다. ForkJoinPool 에서 실행되는 마지막 invoke() 의 반환값은 ForkJoinSumCalculator 에서 정의한 태스크의 결과가 된다.
이 ForkJoinSumCalculator 의 흐름은 아래와 같다.
- LongStream.rangeClosed() 으로 1 ~ n (8) 까지의 배열 생성
- 생성한 배열을 ForkJoinSumCalculator 로 전달하여 태스크 생성
- 생성한 태스크를 ForkJoinPool 로 전달 (invoke())
- compute() 메서드는 병렬로 실행할 수 있을 만큼 태스크가 작아졌는지 확인하며, 태스크가 아직 크다고 판단되면 숫자를 반으로 분할하여 새로운 새로운 ForkJoinSumCalculator 로 할당
- 다시 ForkJoinPool 은 생성된 ForkJoinSumCalculator 를 실행, 주어진 조건인 THRESHOLD 를 만족할 때까지 이 과정이 재귀적으로 반복되어 태스크 분할
- 각 서브 태스크는 순차적으로 처리되어 포킹 프로세스으로 만들어진 이진 트리의 태스크를 루트에서 역순으로 방문하여 부분 결과를 합쳐 최종 결과를 계산 후 반환
THRESHOLD: 10_000, 전체 배열: 10,000,000 으로 (위의 순차형 리듀싱, 반복형 리듀싱, 반복형과 동일 조건) 으로 했을 경우 결과는 아래와 같다.
System.out.println("ForkJoin sum done in: " + measureSumPerf(ForkJoinSumCalculator::forkJoinSum, 10_000_000L) + " ms");
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
result: 50000005000000
ForkJoin sum done in: 18 ms
병렬형 리듀싱보다 성능이 나빠졌지만 이는 ForkJoinSumCalculator 태스크에서 사용할 수 있도록 전체 스트림을 long[] 으로 변환했기 때문이다.
다시 모든 결과를 비교해보자.
- 반복형 성능 측정: 2 ms
- 순차형 리듀싱 성능 측정: 75 ms
- 병렬형 리듀싱 성능 측정: 111 ms
- 순차형 리듀싱 (rangeClosed())성능 측정: 2 ms
- 병렬형 리듀싱 (rangeClosed())성능 측정: 0 ms
- 포크/조인 프레임워크 성능 측정: 18 ms
2.2. 포크/조인 프레임워크 사용 시 주의점
- join() 메서드는 두 서브 태스크가 모두 시작된 다음 호출해야 함
- join() 메서드를 태스크에 호출하면 태스크가 생산하는 결과가 준비될때까지 호출자를 블록시킴
- 만일 두 서브 태스크가 모두 시작되기 전에 join() 을 호출하면 각 서브 태스크가 다른 태스크가 끝나길 기다리는 일이 발생하여 순차 알고리즘보다 느리고 복잡해질 수 있음
- RecursiveTask 내에서는 ForkJoinPool 의 invoke() 메서드를 사용하지 말아야 함
- 대신 compute() 나 fork() 메서드를 직접 호출함
- invoke() 는 순차 코드에서 병렬 계산을 시작할 때만 사용
- 서브 태스크에서 한 쪽 서브 태스크는 fork(), 나머지 한 쪽 서브 태스크는 compute() 를 호출
- 서브 태스크에서 fork() 메서드를 호출하여 ForkJoinPool 의 일정 조정 가능
- 왼쪽/오른쪽 작업 모두 fork() 를 호출하는 것이 자연스러울 것 같지만 한쪽에는 fork() 보다는 compute() 를 호출하는 것이 효율적임
- 그러면 두 서브 태스크 중 한 태스크에는 같은 스레드를 재사용할 수 있으므로 ForkJoinPool 에서 불필요한 태스크를 할당하는 오버헤드를 피할 수 있음
- 각 서브 태스크의 실행 시간은 새로운 태스크를 포킹하는데 드는 시간보다 길어야 함
- 병렬 처리로 성능을 개선하려면 태스크를 여러 독립적인 서브 태스크로 분할할 수 있어야 함
- 이 각 서브 태스크의 실행 시간이 새로운 태스크를 포킹하는데 드는 시간보다 길어야 함
- 다른 자바 코드처럼 JIT (바이트코드를 기계어 코드로 번역하는 과정) 컴파일러에 의해 최적화되려면 warmed up 또는 실행과정을 거쳐야 하기 때문에 성능 측정 시엔 여러 번 프로그램을 실행한 결과를 측정해야 함 (지금까지 구현한 Harness 에서도 여러 번 실행한 후 최적의 성능을 리턴함)
- 포크/조인 프레임워크를 이용한 병렬 계산은 디버깅이 어려움
- IDE 로 디버깅 시 스택 트레이스로 이슈가 발생하는 과정을 확인하는데 포크/조인 프레임워크에서는 fork 라 불리는 다른 스레드에서 compute() 를 호출하기 때문에 스택 트레이스가 도움이 되지 않음
2.3. Work stealing (작업 훔치기)
포크/조인 분할 시 주어진 서브 태스크를 더 분할할 것인지 결정한 기준을 정해야 하는데 이 분할 기준과 관련된 내용을 살펴본다.
위의 ForkJoinSumCalculator 에서 배열 크기가 10,000 개 이하면 서브 태스크 분할을 중단했다. 만일 배열의 크기가 100,000,000 이면 100,000 개의 서브 태스크가 포크될 것이다.
만일 core 가 12개면 100,000 개의 각 서브 태스크가 CPU 로 할당된다고 생각하면 자원을 낭비하는 것처럼 보인다.
하지만 포크/조인 프레임워크는 작업 훔치기(Work Stealing) 기법으로 이러한 문제를 해결한다.
작업 훔치기 기법의 흐름은 아래와 같다.
- ForkJoinPool 의 모든 스레드를 거의 공정하게 분할
- 각 스레드는 자신에게 할당된 태스크를 이중 연결 리스트를 참조하여 작업이 끝날 때마다 큐의 head 에서 다른 태스크를 가져와서 작업을 처리함
- 따라서 먼저 작업이 끝난 스레드는 유휴 상태로 변경되는 것이 아닌 다른 스레드 큐의 tail 에서 작업을 훔쳐옴
- 모든 태스크가 작업을 끝낼 때까지 (= 모든 큐가 빌 때까지) 이 과정을 반복함
- 따라서 태스크의 크기를 작게 나누어야 작업자 스레드 간의 작업 부하를 비슷한 수준으로 유지 가능
즉, 100,000 개의 태스크를 분할하는 것이 자원을 낭비하는 것이 결코 아니다.
그런데 1.2. 스트림 성능 측정 에서는 ForkJoinXXX 같은 분할 로직을 개발하지 않고도 parallel() 을 통해 병렬 스트림을 이용하였는데 그게 가능했던 이유는 스트림을 자동으로 분할해주는 기법인 Spliterator 가 있기 때문인데 이 부분은 Java8 - Stream 으로 병렬 데이터 처리 (2): Spliterator 인터페이스 에서 알아보도록 한다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 라울-게이브리얼 우르마, 마리오 푸스코, 앨런 마이크로프트 저자의 Java 8 in Action을 기반으로 스터디하며 정리한 내용들입니다.
