Spring Boot - 데이터 영속성(1): JPA, Spring Data JPA
in DEV on Springboot MSA(Spring) Database Jpa Spring-data-jpa Hibernate Datasource Connection-pool Entity-manager
이 포스트에서는 JPA, Spring Data JPA, Hibernate 에 대해 알아본다.
JPA(Java Persistence API) 는 자바 ORM 표준 스펙이고,
Hibernate 는 JPA 표준 스펙을 따르는 구현 프레임워크로 ORM 프레임워크 중 보편적으로 사용된다.
Spring Data JPA 는 데이터를 저장/처리하는 Spring Data 프로젝트의 하위 프로젝트이다.
소스는 github 에 있습니다.
개발 환경
- 언어: java
- Spring Boot ver: 3.1.4
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Maven
- Group: com.assu.study
- Artifact: chap08
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.assu</groupId>
<artifactId>study</artifactId>
<version>1.1.0</version>
</parent>
<artifactId>chap08</artifactId>
<dependencies>
<!-- Spring Data JPA, Hibernate, aop, jdbc -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- mysql 관련 jdbc 드라이버와 클래스들 -->
<!-- https://mvnrepository.com/artifact/com.mysql/mysql-connector-j -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
</project>
애플리케이션의 데이터를 저장할 수 있는 매체는 애플리케이션 내부 변수에 데이터를 선언하여 메모리에 저장할 수도 있고, 외부 저장소에 저장할 수도 있다.
메모리에 저장된 데이터는 애플리케이션이 종료되면 메모리에서 지워지기 때문에 휘발성 저장소라고 한다.
영속성(persistence) 은 데이터가 영구적으로 유지되는 성질을 말하며, 비휘발성 저장소에 데이터를 저장하는 것을 의미한다.
1. JPA
JPA(Java Persistence API) 는 Java 애플리케이션이 데이터를 영속할 수 있는 기능을 제공하는 API 이다.
영속성을 지원하므로 데이터의 저장/조회/수정/삭제 기능을 제공한다.
자바의 ORM 표준 스펙으로, 표준 스펙이기 때문에 실제 구현체를 제공하는 것은 아니고 스펙에 따른 인터페이스들을 제공한다.
JPA 표준을 구현한 대표적인 프레임워크는 Hibernate 이다.
모든 Java 애플리케이션은 관계형 데이터베이스에 데이터를 저장하기 위해 JDBC(Java DataBase Connectivity) API 를 사용한다.
JDBC 는 자바의 데이터 접근 표준 API 로, 애플리케이션이 여러 관계형 데이터베이스에 연결될 수 있도록 드라이버와 API 인터페이스를 분리하여 설계되었다.
데이터베이스에 따라 적합한 JDBC 드라이버를 제공하여, 개발자는 데이터베이스 종류에 상관없이 동일한 JDBC API 를 사용하여 개발할 수 있다.
이 때 애플리케이션과 데이터베이스가 커넥션을 맺고, 명령을 실행 후 그 결과를 받아오는데 그 모든 과정은 JDBC 의 커넥션 객체 java.sql.Connection 에서 진행된다.
커넥션을 맺는 과정은 시스템 리소스가 많이 소요되므로 애플리케이션 성능 향상을 위해 커넥션 풀을 사용한다.
애플리케이션이 시작할 때 여러 개의 커넥션 객체를 만들어 커넥션 풀에 저장하고, 애플리케이션이 데이터베이스와 연결이 필요할 때마다 꺼내서 사용한다.
아래 그림은 JDBC 를 사용하여 데이터를 영속하는 애플리케이션의 구조이다. 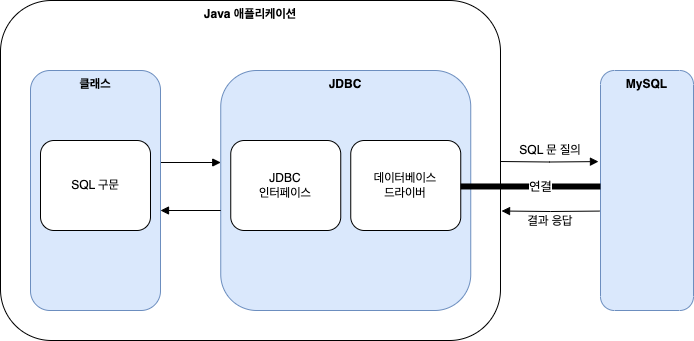
JDBC 를 사용하여 데이터를 영속하면 아래와 같은 단점이 발생한다.
- SQL 구문에 애플리케이션이 의존하게 되어 애플리케이션과 SQL 구문이 서로 강하게 결합됨
- 데이터베이스마다 SQL 문법과 함수가 다르므로 애플리케이션이 특정 데이터베이스에 강하게 결합됨
- SQL 을 실행하고 결과를 다시 자바 객체로 변환하는 비기능적 요구 사항과 관련된 코드가 많아짐
- SQL 에 의존하다 보니 비즈니스 로직이 데이터베이스에 집중될 수 있음
이러한 문제점들을 극복하고자 SQL 과 자바 코드를 분리하는 영속성 프레임워크들이 등장하였다.
아래 그림은 ORM 프레임워크를 사용하여 데이터를 영속하는 애플리케이션의 구조이다. 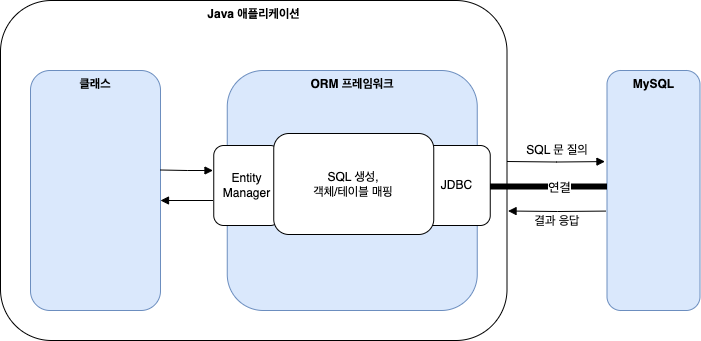
ORM 프레임워크를 사용하면 데이터를 영속하기 위해 SQL 구문을 직접 생성하지 않으므로 클래스는 더 이상 SQL 구문에 의존하지 않는다.
클래스는 Hibernate 프레임워크에서 제공하는 EntityManager 와 같은 자바 클래스의 메서드를 사용하여 데이터를 영속한다.
SQL 을 실행한 후 실행 결과를 다시 객체로 매핑하는 모든 작업을 ORM 프레임워크가 진행한다.
ORM (Object Relation Mapping) 은 자바 객체와 관계형 데이터베이스의 데이터를 서로 매핑하는 기능을 제공한다.
엔티티 클래스는 데이터베이스의 테이블 정보를 자바 클래스에 매핑한 것이다.
ORM 프레임워크가 실행되면 엔티티 클래스 정보를 로딩하고, 사용자 요청에 따라 데이터를 변환한다.
ORM 프레임워크를 Spring Data JPA 와 함께 사용하면 더 쉽게 SQL 구문을 생성할 수 있다.
Spring Data JPA 프레임워크는 메서드 이름을 사용하여 자동으로 SQL 구문을 생성한다.
프레임워크에서 제공하는 규칙에 맞게 메서드명을 작성해야 하는데 이를 쿼리 메서드 라고 한다.
1.1. ORM 과 SQL Mapper 비교
데이터 영속성 프레임워크의 종류는 다양하지만 그 중 Hibernate, MyBatis 가 많이 사용된다.
이 프레임워크들은 설계 방식에 따라 ORM 프레임워크와 SQL Mapper 프레임워크로 분류할 수 있다.
ORM 프레임워크의 대표적인 구현체는 Hibernate 이고, SQL Mapper 의 대표적인 구현체는 MyBatis 이다.
<ORM 프레임워크>
- 개발자가 설정한 클래스와 테이블 사이의 매핑 정보를 참조하여 SQL 구문을 생성하여 데이터 영속
- 개발자가 작성해야 할 부분은 크게 2 부분
- HotelEntity.java
- 테이블과 자바 클래스를 매핑하는 정보
- HotelRepository.java 인터페이스
- 데이터를 조회하거나 생성/삭제하는 메서드 정의
- 인터페이스이므로 실제 구현은 확인할 수 없으나 Spring Data JPA 에서 제공하는 네이밍 전략에 맞게 메서드명을 선언하면 쿼리가 자동으로 생성됨 (= 쿼리 메서드)
- HotelEntity.java
<SQL Mapper>
- 개발자가 작성한 SQL 구문을 실행하여 그 결과인 ResultSet 을 다시 자바 클래스로 매핑하는 역할
- 개발자가 작성해야 할 부분은 크게 3 부분
- Mapper.xml
- 쿼리 정보
- Hotel.java
- select 의 결과를 포함하는 클래스
- 만약 쿼리가 여러 테이블을 조인하여 특정 필드들만 select 한다면 새로운 값 객체 클래스 생성 필요
- 즉, Hotel.java 테이블을 대표하는 것이 아니라 단순히 데이터베이스의 데이터를 저장하는 값 객체일 뿐임
- HotelDaoImpl.java
- 쿼리를 실행할 수 있는 메서드 포함
- Mapper.xml
- 반복되는 코드와 SQL 존재
위에서 보는 것처럼 ORM 프레임워크 사용 시 코드 베이스에 SQL 구문은 없으며, 코드양이 줄어들게 된다.
SQL Mapper 는 select 쿼리 결과를 객체로 받아오는 매핑 설정과 SQL 쿼리에 파라미터를 설정하는 작업이 필요하지만 ORM 은 HotelEntity.java 에 애너테이션을 사용하여 매핑 정보만 설정해주면 된다.
Spring Data JPA 가 HotelRepository 인터페이스의 메서드명을 사용하여 SQL 을 생성한다.
결과적으로 데이터베이스에서 사용하는 테이블이나 메서드가 많아지면 SQL Mapper 보다 Hibernate 의 코드가 훨씬 간결하다.
1.2. JPA 장단점
<JPA 단점>
- 구현 난이도가 높음
- JPA 의 내부 동작을 잘 알지 못하면 어떤 쿼리가 실행되고, 얼마나 많은 쿼리가 실행되는지 알 수 없음
- JPA 프레임워크에 대한 높은 이해도 필요
- JPA 는 객체와 관계형 데이터베이스를 매핑하는 프레임워크로 개발자는 Hibernate 나 Spring Data JPA 를 사용하여 개발
- 이 때 Hibernate 내부에서는 매핑 정보를 사용하여 쿼리를 생성하는데 한 단계 추상화된 레이어이기 때문에 직접 쿼리를 작성하여 실행하는 것보다는 성능상 불리함
- 그래서 Hibernate 에서는 성능 향상을 위한 여러 가지 방법을 제공하고 있으며, 개발자는 이에 대한 이해가 필요
- JPA 는 OLTP(OnLine Transaction Processing) 에 적합
- 일반 API 처럼 실시간 트랜잭션 처리를 OLTP 라고 하며, 통계를 위한 쿼리 처리를 OLAP (OnLine Analytical Processing) 라고 함
- 통계 쿼리는 원하는 데이터를 추출하기 위해 대량의 데이터를 사용하기 때문에 쿼리를 세밀하게 튜닝하거나 복잡한 쿼리를 사용하게 됨
- 이 때는 SQL 쿼리를 직접 코딩할 수 있는 MyBatis 같은 SQL Mapper 가 적합함
<JPA 장점>
- 높은 생산성
- 코드를 중복해서 선언하지 않아도 됨
- 예를 들어 select, update 같은 SQL 구문들을 반복적으로 작성하지 않아도 됨
- 데이터베이스에 독립적인 개발
- JPA 를 사용하면 데이터베이스 종류와 상관없이 JPA 의 API 를 사용하여 개발 가능
- 즉, 하나의 코드 베이스를 사용하여 여러 데이터베이스와 연동 가능
- 예를 들어 Dev 환경에서는 H2 같은 메모리 데이터베이스를 사용하고, Prod 는 MySQL 사용
- 객체 지향적인 프로그래밍
- 데이터를 처리하는 로직이 클래스로 추상화되어 있어서 데이터 처리 작업이 테이블이 아닌 엔티티 클래스를 기준으로 진행됨
2. 도커를 사용한 MySQL 실행 환경 설정
로컬에 DB 를 띄우는 방법은 아래를 참고하세요.
Spring Boot - 웹 애플리케이션 구축 (5): 국제화 메시지 처리, 로그 설정, 애플리케이션 패키징과 실행
Rancher Desktop (Docker Desktop 유료화 대응)
로컬에 DB 를 띄웠으면 아래처럼 테이블을 생성한다.
/scheme/create_table.sql
-- MySQL Script generated by MySQL Workbench
-- Thu Nov 4 22:37:47 2021
-- Model: New Model Version: 1.0
-- MySQL Workbench Forward Engineering
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0;
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0;
SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
-- -----------------------------------------------------
-- Schema tour
-- -----------------------------------------------------
DROP SCHEMA IF EXISTS `tour` ;
-- -----------------------------------------------------
-- Schema tour
-- -----------------------------------------------------
CREATE SCHEMA IF NOT EXISTS `tour` DEFAULT CHARACTER SET utf8 ;
USE `tour` ;
-- -----------------------------------------------------
-- Table `tour`.`hotels`
-- -----------------------------------------------------
DROP TABLE IF EXISTS `tour`.`hotels` ;
CREATE TABLE IF NOT EXISTS `tour`.`hotels` (
`hotel_id` BIGINT NOT NULL AUTO_INCREMENT,
`status` TINYINT NOT NULL DEFAULT 0 COMMENT '호텔 상태 (1: 영업중, -1: 휴업중, 0: 오픈예정)',
`name` VARCHAR(300) NOT NULL,
`address` VARCHAR(100) NOT NULL,
`phone_number` VARCHAR(100) NOT NULL,
`room_count` INT NOT NULL DEFAULT 0,
`created_by` VARCHAR(45) NULL,
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
`modified_by` VARCHAR(45) NULL,
`modified_at` DATETIME NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`hotel_id`),
INDEX `INDEX_NAME_STATUS` (`name` ASC, `status` ASC) VISIBLE)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `tour`.`hotel_rooms`
-- -----------------------------------------------------
DROP TABLE IF EXISTS `tour`.`hotel_rooms` ;
CREATE TABLE IF NOT EXISTS `tour`.`hotel_rooms` (
`hotel_room_id` BIGINT NOT NULL AUTO_INCREMENT,
`hotels_hotel_id` BIGINT NULL,
`room_number` VARCHAR(100) NOT NULL,
`room_type` SMALLINT UNSIGNED NOT NULL COMMENT '0: 기본타입, 1: 커넥티드룸, 100: 스위트룸',
`original_price` DECIMAL(18,2) NOT NULL,
`created_by` VARCHAR(45) NULL,
`created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
`modified_by` VARCHAR(45) NULL,
`modified_at` DATETIME NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`hotel_room_id`),
INDEX `fk_hotel_rooms_hotels_idx` (`hotels_hotel_id` ASC) VISIBLE,
CONSTRAINT `fk_hotel_rooms_hotels`
FOREIGN KEY (`hotels_hotel_id`)
REFERENCES `tour`.`hotels` (`hotel_id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
SET SQL_MODE=@OLD_SQL_MODE;
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
3. Spring Data JPA
Spring Data JPA 와 Hibernate 를 사용하기 위해 아래 의존성을 추가한다.
pom.xml
<dependencies>
<!-- Spring Data JPA, Hibernate, aop, jdbc -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- mysql 관련 jdbc 드라이버와 클래스들 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
spring-boot-starter-data-jpa 를 추가하면 영속성 프레임워크와 자동 설정도 같이 추가된다.
MySQL 을 사용하므로 mysql-connector-j 를 추가한다.
mysql-connector-j 는 MySQL JDBC 드라이버와 클래스들을 포함한다.
springboot 2.7.8 부터 dependency management 에서 더 이상 mysql-connector-java 는 관리하지 않음
따라서 mysql-connector-java 가 아닌 mysql-connector-j 사용 권장
spring-projects/spring-boot
데이터베이스와 관련된 라이브러리 버전은 별도로 관리하는 것이 좋다.
pom.xml 에 버전을 명시하지 않으면 스프링 부트 프레임워크에서 설정한 버전으로 의존성이 추가되는데, 버전이 숨겨져 있어 알기 어렵고 스프링 부트 프레임워크의 버전을 올리면 같이 변경될 가능성이 있다.
spring-boot-starter-data-jpa 에는 아래 라이브러리들이 포함되어 있다.
spring-boot-starter-aop- 스프링 AOP 를 사용하는 스프링 부트 스타터
spring-boot-starter-jdbchibernate-core- JPA/Hibernate 프레임워크의 핵심 기능이 있는 라이브러리
spring-data-jpa- JPA/Hibernate 를 한 단계 더 추상화한 스프링 프레임워크 모듈
3.1. Spring Data JPA 기능
아래는 JPA/Hibernate 만 사용하여 구성했을 경우와 Spring Data JPA + JPA/Hibernate 를 같이 사용하여 구성했을 때의 비교 그림이다.
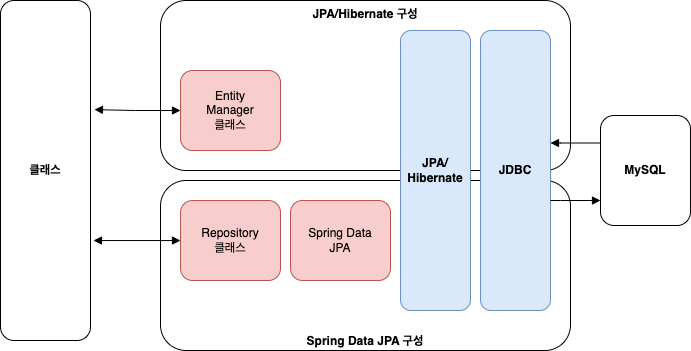
두 구성 모두 JPA/Hibernate 와 JDBC 를 포함한다.
하지만 데이터베이스의 데이터를 처리할 때 사용하는 클래스는 다르다.
- JPA/Hibernate 구성
- Hibernate 에서 제공하는 EntityManager 클래스의 메서드를 사용하여 데이터 처리
- Spring Data JPA + JPA/Hibernate 구성
- 추상화된 Repository 인터페이스를 사용하여 데이터 처리
(Spring Data JPA 를 사용해도 EntityManager 의 메서드를 이용하여 데이터 처리는 가능)
- 추상화된 Repository 인터페이스를 사용하여 데이터 처리
Spring Data JPA + JPA/Hibernate 구성의 경우 구현 클래스가 아닌 인터페이스만 호출해도 데이터 처리가 가능한데 이는 Spring Data JPA 에서 제공하는 쿼리 메서드 기능 덕분이다.
또한 빠르게 개발할 수 있는 여러 기능도 제공하기 때문에 일반적으로 스프링 애플리케이션에 JPA/Hibernate 를 영속성 프레임워크로 사용하는 경우 Spring Data JPA 를 함께 사용한다.
<Spring Data JPA 에서 제공하는 기능들>
- CRUD 기본 기능 제공
- CRUD 를 위한 공통 인터페이스인
JpaRepository와 구현 클래스인SimpleJpaRepository제공 JpaRepository인터페이스는 Entity 객체를 처리할 수 있는 몇 가지 CRUD 관련 기본 메서드 제공- 때문에 개발자는 JpaRepository 를 상속한 후 Repository 인터페이스를 확장하면 됨
- 확장된 인터페이스에는 JpaRepository 의 디폴트 메서드가 상속되므로 매번 반복해서 디폴트 메서드를 구현할 필요 없음
- CRUD 를 위한 공통 인터페이스인
- 쿼리 생성 기능 제공
- Repository 인터페이스에 선언된 메서드명으로 쿼리 생성
- 프레임워크에서 만든 규칙에 따라 메서드를 만들어서 쿼리를 생성할 수 있으며, 애플리케이션이 시작할 때 메서드를 분석하여 생성함
- 간단한 쿼리는 직접 구현하지 않고 이 기능을 사용하여 쉽게 데이터 처리 가능
- 감사 기능 제공
- 데이터 생성/수정 시 누가 언제 했는지 추적할 수 있는 애너테이션과 기능 제공
- Spring Boot - 데이터 영속성(2): 엔티티 클래스 설계 참고
- Spring Boot - 데이터 영속성(6): 엔티티 상태 이벤트 처리, 트랜잭션 생명주기 동기화 작업 참고
- 페이징과 정렬 같은 부가 기능 제공
- o.s.data.domain.Pageable 인터페이스와 o.s.data.jpa.repository.PagingAndSortingRepository 인터페이스 제공
- PagingAndSortingRepository 는 JpaRepository 의 부모 인터페이스이므로 JpaRepository 를 사용하는 모든 커스텀 Repository 클래스들은 이용 가능
3.2. Spring Data JPA 자동 설정과 필수 스프링 빈
spring-boot-starter-data-jpa 는 JPA/Hibernate 를 설정할 수 있는 자동 설정 기능을 제공하며, 이것은 pom.xml 에 spring-boot-starter-data-jpa 의존성만 추가하면 자동 설정된다.
데이터베이스 연결을 위한 주소, 암호같은 설정은 application.properties 파일에 설정한다.
데이터베이스에서 데이터를 처리하는데 반드시 필요한 컴포넌트들은 아래와 같다.
DataSourceEntityManagerTransactionManager
3.2.1. javax.sql.DataSource
MySQL 과 애플리케이션 사이에 위치한 javax.sql.DataSource 인터페이스는 javax.sql.Connection 객체를 생성하는 팩토리 클래스이다.
일반적으로 Connection 객체 생성 시 시스템 리소스가 많이 소요되므로 애플리케이션 성능 향상을 위해 Connection 객체를 미리 생성하고, 필요할 때는 idle 상태인 Connection 객체를 할당받아 사용한다. 이러한 커넥션 관리 메커니즘을 커넥션 풀 이라고 하며, DataSource 의 getConnection() 메서드를 통해 Connection 객체를 받을 수 있다.
DataSource 는 Connection 객체를 제공하는 인터페이스이며, 여러 구현체를 사용할 수 있다.
커넥션 풀 기능을 제공하는 DataSource 의 구현체라면 내부에 커넥션 풀을 생성하고 관리하며, getConnection() 메서드를 호출하면 커넥션 풀에서 관리하는 Connection 객체를 리턴한다.
스프링 부트 프레임워크에 별도 설정을 하지 않으면 Hikari DBCP 가 기본으로 사용된다.
DataSource 자동 설정 클래스는 o.s.boot.autoconfigure.jdbc 패키지에 있는 DataSourceAutoConfiguration 이며, 자세한 설정을 보고 싶으면 확인해보면 된다.
3.2.2. EntityManager
위 그림에서 JPA/Hibernate 프레임워크만 구성한 구조를 보면 클래스는 EntityManager 를 통해 데이터를 영속하는 것을 알 수 있다.
EntityManager 는 엔티티 클래스를 영속할 수 있는 메서드들을 제공하기 때문에 Hibernate 에서 제공하는 클래스 중 가장 중요한 역할을 하는 클래스이다.
스프링 부트 프레임워크는 o.s.boot.autoconfiguration.orm.jpa 패키지에 포함된 HibernateJpaAutoConfiguration 자동 설정 클래스를 제공하며, 이 클래스는 애플리케이션이 JPA/Hibernate 를 사용할 수 있도록 필요한 기능들을 자동 설정 해준다.
이 중에서 LocalContainerEntityManagerFactoryBean 이 EntityManager 를 생성하고 설정한다.
3.2.3. TransactionManager
스프링 프레임워크는 트랜잭션을 처리하는 TransactionManager 인터페이스를 제공하여, 다양한 구현체를 정의해서 사용할 수 있다.
JPA/Hibernate 프레임워크에서 제공하는 트랜잭션 구현체는 JpaTransactionManager 이다.
EntityManager 는 트랜잭션 시작부터 종료까지 엔티티 객체를 관리한다.
그리고 트랜잭션을 종료할 때 변경된 데이터를 SQL 구문으로 실행한다.
이러한 방식 때문에 트랜잭션과 EntityManager 는 매우 긴밀하게 동작한다.
3.3. Spring Data JPA 설정
Spring Data JPA 를 설정하는 부분은 JPA/Hibernate 설정, Hikari DataSource 설정 이렇게 크게 두 가지로 나눌 수 있다.
3.3.1. JPA/Hibernate 설정
application.properties
## JPA/Hibernate configurations
# 쿼리를 로그로 남길 지 여부
spring.jpa.show-sql=true
# 로그에 출력되는 쿼리 포메팅
spring.jpa.properties.hibernate.format_sql=true
# 데이터베이스에 따라 적절한 dialect 적용
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQLDialect
# database 초기화 여부
spring.jpa.hibernate.ddl-auto=none
spring.jpa.show-sql- JPA/Hibernate 가 생성한 쿼리를 로그로 남길지 여부
spring.jpa.properties.hibernate.format_sql- 로그에 출력되는 쿼리를 포매팅할지 여부
- 이 때 JPA/Hibernate 의 클래스에서 생성하는 로그 레벨은 INFO 보다 낮음
- 따라서 로그를 생성하는 클래스와 로그 레벨은 별도로 설정하여 기존 애플리케이션의 로그 레벨 설정에 영향이 없도록 하는 것이 좋음
spring.jpa.properties.hibernate.dialect- 데이터베이스마다 SQL 문법과 함수가 다르므로 JPA/Hibernate 프레임워크가 사용할 데이터베이스에 맞게 SQL 을 생성하도록 설정
- dialect 구현체 종류는 org.hibernate.dialect 패키지나 hibernate 6.2 공홈: MySQL8Dialect Deprecated를 확인하면 됨
- hibernate 6.2 기준으로 MySQL8Dialect 는 Deprecated 되었고, MySQLDialect 사용하도록 권장함
spring.jpa.hibernate.ddl-auto- Hibernate 가
@Entity애너테이션이 선언된 엔티티 클래스를 스캔하여 설정 확인 후 이를 바탕으로 DDL 쿼리 작성할지 여부 - Prod 환경에서는 none 이나 validate 설정까지 사용하는 것이 좋다.
- none: 디폴트, DDL 설정하지 않음
- validate: 엔티티 클래스의 설정과 데이터베이스의 스키마를 비교하여 다른 점이 있다면 예외 발생 후 애플리케이션 종료
- update: 엔티티 클래스의 설정과 데이터베이스의 스키마를 비교하여 다른 점이 있다면 엔티티 클래스의 설정을 데이터베이스에 업데이트
- create: 애플리케이션이 시작하면 기존에 생성된 테이블을 drop 하고 테이블 생성
- create-drop: 애플리케이션이 시작하면 기존에 생성된 테이블을 drop 하고 테이블 생성, 애플리케이션 종료 시 생성한 테이블 다시 drop
- Hibernate 가
/resources/logback-spring.xml
<!-- sql -->
<logger name="org.hibernate.SQL" level="DEBUG"/>
<logger name="org.hibernate.type" level="TRACE"/>
<logger name="org.hibernate.type.descriptor.jdbc.BasicBinder" level="DEBUG"/>
3.3.2. Hikari DataSource 설정
커넥션 풀의 핵심 기능은 Connection 객체의 재활용이다.
데이터베이스와 애플리케이션이 커넥션을 맺기 위해서는 TCP 프로토콜의 3-way-handshake 과정을 거쳐서 TCP 소켓 생성이 되어야 Connection 객체가 생성되는데 이 과정은 두 서버 사이에 리소스와 처리 시간이 필요하다.
따라서 애플리케이션이 쿼리를 실행할 때마다 Connection 객체를 매번 생성/폐기한다면 애플리케이션 성능이 저하되고, 서버 부하가 증가된다.
Connection 객체들을 미리 생성하고 필요할 때마다 미리 생성한 Connection 객체를 사용한다면 3-way-handshakes 과정을 생략한 채 쿼리 실행이 가능하다.
DataSource 가 바로 커넥션 풀 역할을 하며, 애플리케이션은 DataSource 에서 생성한 커넥션 객체를 빌려서 사용한다.
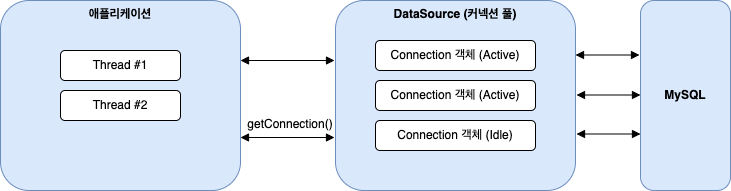
애플리케이션은 DataSource 의 getConnection() 메서드를 호출하여 사용할 수 있는 Connection 객체를 요청하고, 커넥션 풀은 idle 상태의 Connection 객체를 찾아 리턴한다.
Connection 객체를 할당받은 스레드는 쿼리를 실행하는데 이 때 할당받은 Connection 객체는 idle 상태에서 active 상태가 된다.
쿼리 실행을 마친 스레드는 Connection 객체를 반환하며, 반환된 Connection 객체는 다시 idle 상태가 된다.
idle 상태의 Connection 이 고갈되어 스레드에 할당할 수 없다면 해당 스레드는 Timeout 설정 시간까지 기다리는데, 쿼리 시간이 길어서 idle Connection 객체가 없거나 커넥션 풀의 Connection 개수가 너무 작다면 애플리케이션이 Connection 객체를 할당받는 대기 시간이 길어진다.
Hikari DataSource 를 설정할 때는 최대 몇 개의 Connection 객체를 생성할지, idle 상태의 Connection 객체는 언제까지 보관할지, 스레드는 Connection 객체를 받을 때까지 얼마나 기다릴지 등을 설정한다.
application.properties
## DataSource type Configuration
# DataSource 구현체 명시적으로 설정
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
# MySQL 서버의 시간대 설정 (기준시: UTC, 한국: Asia/Seoul)
spring.datasource.url=jdbc:mysql://localhost:13306/tour?serverTimezone=UTC
## Hikari DataSource Configurations
spring.datasource.hikari.jdbc-url=jdbc:mysql://localhost:13306/tour?serverTimezone=UTC
spring.datasource.hikari.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.hikari.username=root
spring.datasource.hikari.password=password
# HikariDataSource 에서 Connection 객체를 받아오는 최대 대기 시간 (ms)
spring.datasource.hikari.connection-timeout=5000
# 커넥션 풀에서 관리할 수 있는 최대 커넥션 개수
spring.datasource.hikari.maximum-pool-size=5
# 커넥션 풀에서 Connection 객체의 최대 유지 시간 (s), 아래는 20일
spring.datasource.hikari.max-lifetime=1728000
# idle 상태로 유지될 수 있는 최대 시간 (s), 아래는 7일
spring.datasource.hikari.idle-timeout=604800
#spring.datasource.hikari.connection-test-query=select 1
spring.datasource.type- 어떤 DataSource 구현체를 사용할지 명시적으로 설정
- javax.sql.DataSource 인터페이스를 구현하는 구현 클래스의 경로 설정
- 여기선 Hikari DBCP 를 사용하므로 Hikari 라이브러리에서 제공하는 HikariDataSource 클래스의 이름과 전체 경로 설정
spring.datasource.urlspring.datasource.hikari.jdbc-url- DataSource 가 Connection 객체 생성 시 연결할 데이터 베이스의 URL 설정
- JDBC URL 형식으로 입력
- serverTimezone 속성은 MySQL 서버의 시간 대역을 설정하는 것으로 기준시는 UTC, 한국 시간을 사용하려면 Asia/Seoul 입력
spring.datasource.hikari.driver-class-name- DataSource 가 Connection 객체 생성 시 연결할 데이터 베이스의 드라이버 클래스명 설정
spring.datasource.hikari.usernamespring.datasource.hikari.passwordspring.datasource.hikari.connection-timeout- HikariDataSource 가 Connection 객체를 받아오는 최대 대기 시간 (ms)
- 스프링 트랜잭션 모듈이 이 시간 동안 Connection 객체를 받지 못하면 SQLException 발생
spring.datasource.hikari.maximum-pool-size- HikariDataSource 커넥션 풀에서 관리할 수 있는 최대 커넥션 개수
spring.datasource.hikari.max-lifetime- 커넥션 풀에서 Connection 객체의 최대 유지 시간 (s)
- 이 시간을 초과하면 해당 Connection 객체는 재사용되지 않고 폐기됨
spring.datasource.hikari.idle-timeout- idle 상태로 유지될 수 있는 최대 시간 (s)
- idle 상태로 이 시간을 초과하면 커넥션 객체는 폐기됨
spring.datasource.hikari.connection-test-query- DataSource 에서 Connection 객체를 받아올 때 Connection 객체의 유효 여부를 판단하기 위해 실행하는 테스트 쿼리
- 공식 문서에 따르면 이 설정은 HikariDataSource 성능에 영향을 미치므로 JDBC4 를 사용하고 있다면 설정하지 않기를 권고하고 있음
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 스프링 부트로 개발하는 MSA 컴포넌트를 기반으로 스터디하며 정리한 내용들입니다.
- 스프링 부트로 개발하는 MSA 컴포넌트
- Spring Boot 공홈
- hibernate 6.2 공홈
- Spring boot 3.0.0 SQL Basic Binder 로깅 안되는 문제 해결기
- Spring Boot SQL 설정(hibernate, logging)
- hibernate 6.2 공홈: MySQL8Dialect Deprecated
- mysql:mysql-connector-java -> com.mysql:mysql-connector-j 변경 및 Spring Boot 2.7.8 이후 mysql-connector-java 의존성 관리 제거
- spring-projects/spring-boot: mysql-connector-j
