Spring Boot - Redis 와 스프링 캐시(1): Spring Data Redis, Lettuce
in DEV on Springboot, MSA(Spring), Redis, DB, Spring-data-redis, Lettuce, Redis-connection-factory
이 포스트에서는 Spring Data Redis 와 Lettuce 라이브러리로 스프링 애플리케이션에서 레디스를 사용하는 방법에 대해 알아본다.
레디스는 메모리 기반의 데이터 저장소로, key-value 데이터 구조에 기반하는 데이터 저장소이다.
최신 버전의 레디스는 PUB/SUB 형태의 데이터를 제공하여 메시지를 전달할 수 있다.
레디스를 다양한 목적으로 사용할 수 있다.
레디스는 메모리에 데이터를 저장하기 때문에 디스크에 데이터를 저장하는 데이터 저장소보다 저장 공간에 제약이 있어 주로 보조 데이터 저장소로 사용한다.
또한 저장된 데이터를 영구적으로 디스크에 저장할 수 있는 백업 기능을 제공하기 때문에 애플리케이션의 주 저장소로도 사용 가능하다.
레디스는 메모리에 데이터를 저장하므로 빠른 속도 처리가 장점이다.
레디스 내부에서 명령어를 처리하는 부분은 싱글 스레드 아키텍처로 구현되어 있다.
레디스 자바 클라이언트 라이브러리는 다양한데 대표적으로 Jedis, Lettuce, Redisson 등이 있다.
이 포스트에서는 Lettuce 와 Spring-Data-Redis 프로젝트를 사용하여 스프링 애플리케이션을 만드는 방법에 대해 알아본다.
쓰기 동작보다 읽기 동작이 많은 데이터가 있다면 Cache 를 도입하는 것이 유리하다.
Cache 는 메모리에 데이터를 미리 적재하고 이를 빠르게 읽어 응답하는 구조이므로, 읽기 동작이 많은 서비스에 Cache 를 사용하면 서비스 응답 속도를 향상시킬 수 있으며 시스템 리소스도 효율적으로 사용할 수 있다.
소스는 github 에 있습니다.
목차
개발 환경
- 언어: java
- Spring Boot ver: 3.1.5
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Maven
- Group: com.assu.study
- Artifact: chap10
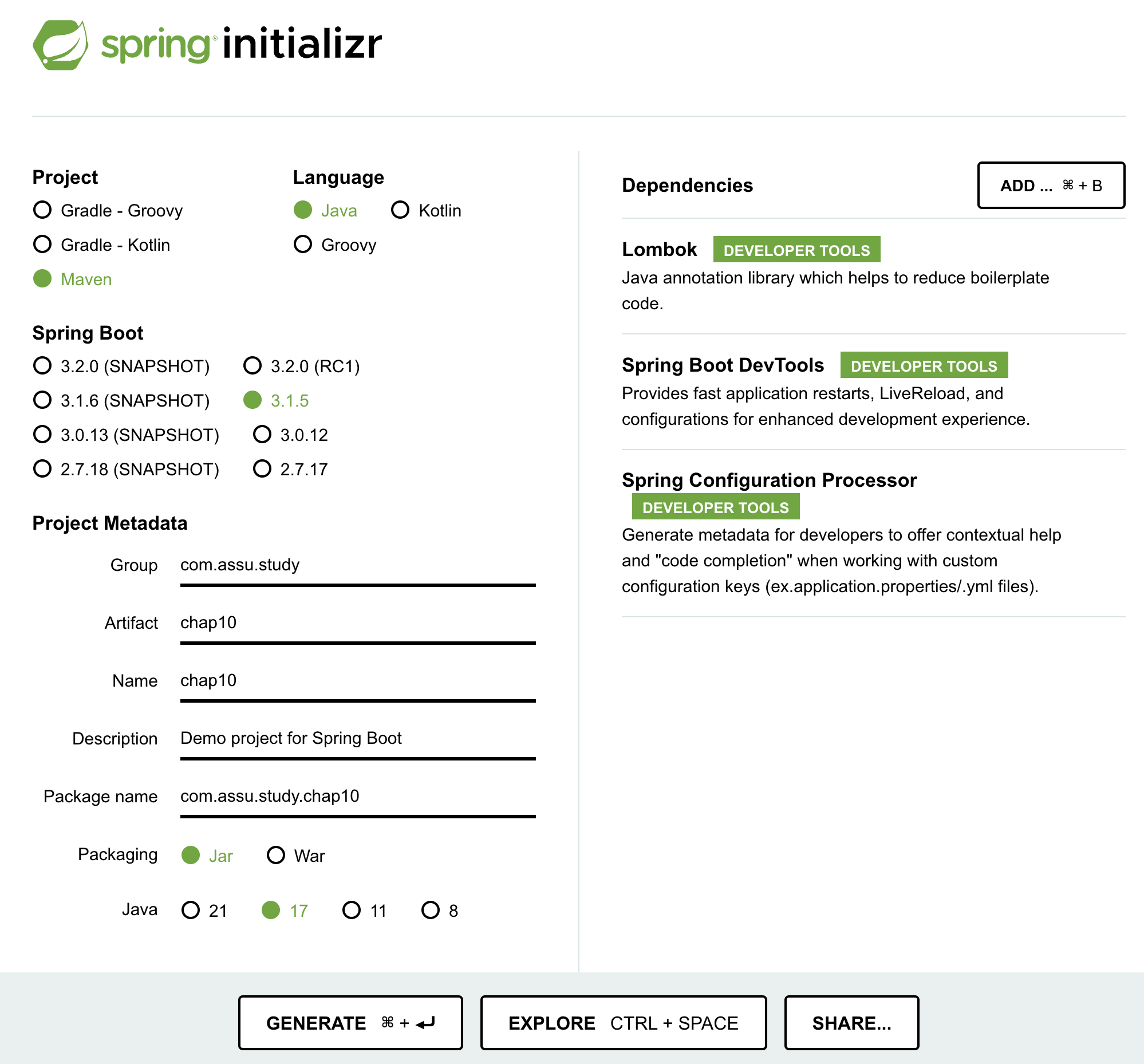
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.assu</groupId>
<artifactId>study</artifactId>
<version>1.1.0</version>
</parent>
<artifactId>chap10</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.1.5</version>
</dependency>
</dependencies>
</project>
1. 레디스
레디스의 대표 키워드는 메모리와 싱글 스레드이다.
메모리에 데이터를 관리하므로 매우 빠른 속도로 데이터를 저장/조회할 수 있다.
하지만 메모리 특성상 데이터가 사라지므로 이를 보완하고자 레디스는 관리하고 있는 데이터에 영속성을 제공한다.
즉, 메모리에 있는 데이터를 디스크에 백업하는 기능을 제공하여, RDB 방식이나 AOF 방식으로 백업 가능하다.
일반적으로 이 둘을 함께 설정하여 상호 보완한다.
- RDB (Redis DataBase)
- 메모리에 있는 데이터 전체에서 스냅샷을 작성하고 이를 디스크로 저장하는 방식
- 스냅샷을 생성하는 기능이므로 데이터 백업/복원이 간단
- 특정 시간마다 여러 개의 스냅샷을 생성하고, 복원 시 특정 시간의 스냅샷 파일 하나만 그대로 로딩하면 됨
- 단, 스냅샷 이후에 변경되는 데이터는 복구할 수 없다는 단점이 있음 (데이터 유실)
- AOF (Append Only File)
- 레디스에 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식
- 데이터를 생성/수정/삭제하는 이벤트들을 초 단위로 취합하여 로그 파일에 작성 (특정 데이터를 10번 수정하면 10개의 로그가 AOF 파일에 기록됨)
- 모든 데이터의 변경 기록들을 보관하므로 최신의 데이터 정보 백업 가능
- 따라서 서버 복구 시 RDB 방식에 비해 데이터 유실량이 적음
- 단, 로딩 속도가 느리고 파일 크기가 큼
- 데이터 복구 시 로그에 쌓인 변경 사항들을 다시 실행하므로 하나의 데이터에 같은 명령어가 여러 번 실행될 수 있음
- 그래서 스냅샷을 한 번에 로딩하는 RDB 방식보다 느리고, 저장 기간에 비례하여 로그가 누적되므로 RDB 방식에 비해 로그 크기가 큼
RDB, AOF 에 대한 간략한 설명은 5. 데이터 Persistence(저장) 을 참고하세요.
일반적으로 AOF 와 RDB 방식을 동시에 사용하여 데이터를 백업한다.
예를 들어 매일 XX 시마다 RDB 를 생성하고, RDB 생성 이후에 변경되는 데이터는 AOF 로 백업한다.
레디스 동작 방식
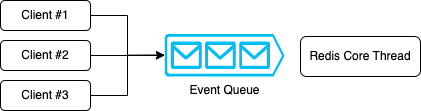
레디스는 명령어들을 Event Loop 방식으로 처리한다.
Event Loop 에 대한 좀 더 상세한 내용은 Event Loop 를 참고하세요.
Event Loop 방식은 클라이언트가 실행한 명령어들을 이벤트 큐에 적재하고 싱글 스레드로 하나씩 처리한다.
멀티 스레드 환경에서 발생할 수 있는 컨텍스트 스위칭이 없으므로 효율적으로 시스템 리소스를 사용할 수 있는 장점이 있다.
멀티 스레드 환경에서 공유 자원에 동시에 여러 스레드가 접근한다면 Dead Lock 이 발생할 수 있는데 레디스의 코어 스레드를 싱글 스레드로 구성되어 있기 때문에 Dead Lock 현상이 발생하지 않는다.
이러한 싱글 스레드 특성을 이용하여 분산락으로 레디스를 사용하기도 한다.
MSA 환경의 여러 컴포넌트는 공유 자원을 사용할 수 있으므로 Race Condition 이 될 수 있는데 이 때 레디스를 사용하면 공유 자원의 점유 여부를 저장할 수 있다.
분산락의 좀 더 상세한 내용은 Spring Boot - Redis 와 스프링 캐시(3): 분산락, CyclicBarrier 를 참고하세요.
레디스 명령어 중 전체 데이터를 스캔하는 명령어들이 있는데 이런 명령어의 처리 시간은 데이커 크기에 비례하므로 실행 시간이 길어질 수 있다.
레디스는 싱글 스레드이기 때문에 이 명령어를 처리하는 동안 다른 명령어를 처리할 수 없다.
따라서 다른 명령어들이 이벤트 큐에 저장되어 기다리는 시간이 길어질 수 있다.
레디스 아키텍처
레디스 서버를 구축할 때 단독 서버로 구성하면 장애에 적절한 대응이 어렵다.
그래서 기본적으로 한 대의 Master 와 한 대 이상의 Replica 서버를 한 세트로 구성한다.
쓰기/쑤정/삭제는 Master 에서 실행하고, Master 노드 데이터를 Replica 서버들에 복제하여 데이터를 동기화한다.
이러한 작업을 Replication 이라고 한다.
Master 서버에 장애가 발생하면 Replica 서버 중 한 대가 Master 역할을 대신하는 방식으로 고가용성을 유지한다.
데이터가 중요하여 유실되면 안되는 상황이라면 두 대 이상의 Replica 서버를 하나의 세트에 구성한다.
만일 Cache 데이터처럼 유실되어도 상관이 없다면 Replica 서버를 한 대만 유지해도 된다.
클라이언트들은 Master 서버에만 데이터를 생성/수정/삭제하는 작업을 해야 한다.
변경된 데이터들이 Replica 서버들에 복제되기 때문이다.
Replica 서버에 데이터를 수정해도 Master 서버에는 영향이 없다.
레디스는 서버 역할을 모니터링하고 상태를 관리하는 솔루션을 제공하는데 바로 레디스 센티넬(Sentinel) 과 레디스 클러스터이다.
이 둘은 Master 서버를 항상 모니터링하고 있으며, Master 서버에 장애가 발생하면 다른 Replica 서버를 Master 서버로 선출한다.
<레디스의 다양한 사용 목적>
- 주 데이터 저장소
- AOF, RDB 백업 기능과 레디스 아키텍처를 사용하여 주 저장소로 데이터 저장 가능
- 단, 메모리 특성상 용량이 큰 데이터 저장소로는 적합하지 않음
- 데이터 캐시
- 인메모리 데이터 저장소이므로 주 저장소의 데이터를 캐시하여 빠르게 데이터 읽음
- 캐시된 데이터는 한 곳에 저장되는 중앙 집중형 구조로 구성함
- 그래야 모든 애플리케이션이 레디스 한 곳만 바라보므로 데이터 일관성을 유지할 수 있음
- 분산락 (Distributed Lock)
- 분산 환경에서 여러 시스템이 동시에 데이터를 처리할 때는 특정 공유 자원의 사용 여부를 검증하여 Dead Lock 을 방지해야 하는데 이 때 레디스를 분산락으로 사용 가능
- 순위 계산
ZRANGE,ZREVRANGE,ZRANGEBYSCORE,ZREVRANGEBYSCORE는 ZSet (Sorted Set) 자료 구조를 사용함- 정렬 기능이 포함된 Set 자료 구조이므로 쉽고 빠르게 순위 계산 가능
ZSet (Sorted Set) 에 대한 상세한 내용은 Redis - Sorted Set 를 참고하세요.
1.1. 레디스 센티넬(Sentinel) 아키텍처
레디스 센티넬 아키텍쳐는 레디스 센티넬, 레디스 마스터, 레디스 레플리카 로 구성된다.
레디스 센티넬은 레디스 서버들(마스터와 레플리카) 을 관리하며, 마스터 서버가 서비스 할 수 없는 상태가 되면 다른 레플리카를 마스터 서버로 변경한다.
마스터 서버가 한 대이고, 레플리카 서버가 두 대 이상이면 새로 승급된 마스터 서버부터 생성된 데이터를 복제하도록 나머지 레플리카 서버들의 설정을 변경한다.
이러한 과정을 FailOver 라고 한다.
클라이언트는 마스터와 레플리카 서버 중에서 마스터 서버와 커넥션을 맺어야 하므로 서버 정보를 알아야 하는데, 레디스 센티넬 구조에서 클라이언트는 레디스 센티넬 서버들에 마스터 서버를 질의하고 마스터 서버에 명령어를 실행한다.
따라서 스프링 애플리케이션에서 레디스 커넥션을 설정할 때 마스터 주소가 아닌 센티넬 서버들의 주소로 설정해야 한다. (= 센티넬이 지정한 마스터 레디스와 커넥션을 맺을 수 있도록)
레디스 센티넬을 단독 서버로 구성한다면 센티넬에 장애 발생 시 레디스 서버들을 모니터링 할 수 없으므로 장애에 대응할 수 없다.
레디스 센티넬 서버는 3대 이상의 홀수로 구성하는 것이 좋은데 그 이유는 아래와 같다.
센티넬 서버들은 모니터링 결과를 공유 저장소에 저장하지 않고 각 서버에 각각 저장한다.
센티넬 서버들과 마스터 서버 사이의 네트워크 상태나 여러 변수에 의해 일부 센티넬 서버들은 마스터 서버 모니터링에 실패할 수 있다.
센티넬 서버가 마스터 서버 모니터링에 실패하면 센티넬 서버들은 동의 절차 작업을 실시하는데 일종의 다수결 투표 작업을 진행하여 장애 복구 절차를 실행한다.
이러한 다수결 투표 작업을 쿼럼 (Quorum) 이라고 한다.
센티넬이 3대이면 쿼럼 값을 2로 설정하고, 두 대 이상의 센티넬 서버가 마스터 서버를 장애로 판단하면 마스터 서버를 서비스에서 제외하고 장애 복구 절차를 진행한다.
만일 4 대의 센티넬을 설치하고 쿼럼 값을 2로 설정하면 2대는 장애, 2대는 정상이라고 판단할 수 있어서 장애 판단을 할 수 없는 경우가 발생한다.
따라서 이러한 쿼럼 과정 때문에 센티넬 서버 개수는 홀수를 유지하는 것이 좋다.
센티넬 아키텍처의 좀 더 상세한 내용은 2. Master & Slave & Sentinel 를 참고하세요.
1.2. 레디스 클러스터 아키텍처
레디스 3.0 버전 이후부터 레디스 클러스터 기능이 제공된다.
레디스 클러스터는 클러스터에 포함된 노드들이 서로 통신하면서 고가용성을 유지하며, 샤딩 기능도 기본 기능으로 사용할 수 있다.
클러스터 내부에는 마스터 노드와 레플리카 노드를 설정하여 운영할 수 있으며, 클러스터를 구성하려면 3 개의 마스터 노드는 반드시 필요하다.
설정에 따라 레플리카 노드의 개수는 0개 혹은 그 이상으로 설정할 수 있지만 고가용성을 위해 반 드시 한 개 이상의 레플리카를 설정하는 것이 좋다.
센티넬 구조와 비교했을 때 모니터링을 위한 별도의 센티넬 서버를 구축할 필요는 없다.
클러스터 내부의 모든 노드는 서로 연결되어 있는 mesh 구조로 되어 있으며, gossip 프로토콜을 사용하여 서로 모니터링한다.
그래서 마스터 노드에 장애가 발생하면 레플리카 노드가 마스터 노드로 대체된다.
클러스터에는 데이터를 마스터 노드들에 분배하는 샤딩 기능이 있다.
마스터 노드들에 균등하게 데이터를 분배할 수도 있고, 특정 마스터 노드가 다른 마스터 노드보다 많은 데이터를 저장하게 분배할 수도 있다.
이러한 정보는 클러스터의 모든 노드가 공유하고 있기 때문에 클라이언트는 별도의 샤딩 알고리즘을 구현할 필요 없이 레디스 클러스터의 알고리즘을 사용하면 된다.
레디스 클러스터의 샤딩 알고리즘은 해시 함수를 사용한 데이터 분배 방식을 이용한다.
해시 함수값은 항상 0~16383 값을 리턴한다.
그래서 클라이언트는 데이터의 키 값을 해시 함수로 실행한 함수값을 사용하여 어떤 마스터 노드에 저장할 지 결정한다.
클러스터의 각 마스터 노드는 해시 결과값 범위를 갖고 있다.
만일 3 대의 서버가 데이터를 균등하게 분배하기로 했다면 해시 함수값 0~5460 은 1번 마스터 노드에, 5461~10922 는 2번 마스터 노드에, 10923~16383 은 3번 마스터 노드에 분배된다.
클라이언트가 실행한 해시 함수의 결과값이 2321 이라면 1번 마스터 노드에 저장한다.
클러스터에 노드를 추가하거나 제거한다면 레디스 클러스터 명령어를 사용하여 해시 함수값 범위를 조정할 수 있는데 조정된 범위에 있는 레디스 데이터들은 자동으로 재분배되어 설정된 위치로 이동한다.
이러한 과정을 리밸런싱 혹은 리샤드라고 한다.
클라이언트는 리밸런싱 과정 중에 이동된 데이터 위치를 실시간으로 추적할 수 없다.
만약 1번 노드에 저장되었던 데이터가 2번 노드로 재분배중일 때 클라이언트가 1번 노드에 질의하면 노드는 (error) MOVED 결과와 함께 데이터를 관리하고 있는 레디스 노드의 주소를 응답한다.
클라이언트는 이 정보를 사용하여 다시 해당 서버에 질의하는데 이 과정을 (error) Moved Redirection 이라고 한다.
스프링 애플리케이션 클라이언트는 레디스 클러스터의의 노드 중 하나라도 연결되면 클러스터 전체 정보를 확인할 수 있다.
클러스터 내부의 노드는 전체 노드 정보를 알 수 있기 때문이다.
따라서 Prod 환경에서 운영 중 증설을 하더라도 스프링 애플리케이션의 설정을 변경할 필요는 없다.
레디스 클러스터의 좀 더 상세한 내용은 Redis - Redis Cluster & Monitoring (2) 를 참고하세요.
1.3. 레디스 자료구조
레디스는 기본적으로 key-value 형태의 구조를 띄며, value 가 사용하는 자료 구조에 따라 여러 기능을 사용할 수 있다.
레디스 value 의 자료 구조 종류는 아래와 같다.
- String
- 예) “This is plain text.”
- Hash
- 해시 필드와 해시 밸류로 구성
- 해시 밸류를 생성/조회하려면 레디스 키와 해시 필드를 동시에 사용해야 함
- 예) {name: “assu”, address: “seoul”}
- List
- 리스트 아이템은 Linked List 형태로 서로 연결되어 있음
- 예) [a -> b -> c]
- Set
- 아이템의 중복을 허용하지 않음
- 예) {a, b, c}
- Sorted Set
- 아이템의 중복을 허용하지 않으면서, 정렬 기능 제공
- 아이템은 score 와 함께 저장 가능
- score 값을 사용하여 정렬하고, score 값이 중복되면 아이템 값을 사용하여 정렬함
- 예) {a: 100.1, b: 0.5, c: 100}
- BitMap
- 비트 연산을 사용할 수 있는 자료 구조
- 예) 010000100000
- Hyperloglog
- 집합의 아이템 개수를 추정할 수 있는 아고리즘 이름이자 이를 사용할 수 있는 레디스 자료 구조
- 비트 패턴을 분석하여 비교적 정확한 추정값을 계산함
- 예를 들어 특정 상품의 조회 수를 10,125 라고 정확하게 계산할 때는 시스템 부하가 발생함
- 대신 추정값을 계산하는데 최적화되어 1만회 같은 근사값을 조회할 수 있음
- 중복값을 제거할 수 있고, 저장 공간이 작으므로 카운트에 적합함
- 예) 00110101 11001110 10101010
- Geospatial
- 지점과 위도와 경도를 사용할 수 있는 자료 구조
- 위도와 경도를 계산하여 두 지점의 거리를 계산할 수 있는 명령어 제공
- 예) {“서울”: (37.541,126.986), “대구”: (35.85,128.56)}
- Stream
- 레디스 5.0 버전부터 제공하는 기능
- 이벤트성 로그 처리 가능
- 일종의 메시지 서비스 기능
- 스트림 키 이름과 값, 필드를 사용할 수 있는 자료 구조 형태
- 예) {id1=time1.seq1(A:”abc”, B:”def”),…}
각 데이터 자료 구조에 대한 좀 더 상세한 내용은 아래를 참고하세요.
Redis 데이터 타입: 공홈
Redis 기본, 데이터 처리 명령어, String
Redis - Hash
Redis - List
Redis - Set
Redis - Sorted Set
Redis - Bit
Redis - Geo
Redis - HyperLogLog
1.4. 레디스 유효기간
레디스에 저장되는 모든 데이터는 유효 기간을 설정할 수 있으며, 2 가지 방법으로 유효 기간을 설정할 수 있다.
EXPIRE명령어를 사용하여 이미 생성된 데이터에 유효 기간 설정- 데이터 생성 시
EX옵션을 사용하여 생성과 동시에 유효 기간 설정- 자료 구조에 따라 지원하지 않는 경우도 있음
레디스는 메모리에 데이터를 저장하므로 저장 공간이 한정적이다. 따라서 레디스에 데이터를 저장할 때는 데이터의 유효 기간을 설정하는 것이 좋다.
유효 기간을 설정하지 않는다면 개발자가 직접 데이터를 삭제할 때까지 데이터가 영원히 유지된다.
애플리케이션에서 오래된 데이터를 직접 삭제해야 한다면 아래 상황을 고려해야 한다.
- 레디스는 싱글 스레드이므로 레디스의
DEL명령어를 사용하여 많은 데이터를 삭제한다면, 서비스에서 실행한 명령어들은 메시지 큐에서 대기하는 시간이 길어짐 - 데이터를 삭제하기 위해 레디스 키를 스캔하는 명령어(
SCAN,HSCAN) 는 고민해보고 사용하는 것이 좋음- 실행 시간이 긴 명령어여도 메시지 큐에 대기하고 있는 다른 명령어에 영향을 미치기 때문
- 삭제 기능을 포함한 애플리케이션이 장애 상황이라 데이터를 삭제하지 못한다면 레디스 데이터 사용량은 점점 증가함
2. Spring Data Redis
스프링 부트 프로젝트에서는 spring-boot-starter-data-redis 스타터를 제공한다.
이 스타터에는 Spring Data Redis 프로젝트 라이브러리와 레디스를 연결하는 드라이버, 레디스를 사용하는데 필요한 라이브러리를 모두 포함하고 있다.
사용할 수 있는 드라이버로는 Jedis, Lettuce 라이브러리를 기본으로 포함하여, 이를 스프링 부트 프로젝트에서 쉽게 사용할 수 있는 클래스들도 제공한다.
pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.1.5</version>
</dependency>
스프링 애플리케이션에서 Spring Data Redis 를 사용하여 레디스에 명령어를 실행하는 방법은 크게 2 가지가 있다.
- o.s.data.redis.core 의 RedisTemplate 클래스 사용
- Spring Data 프로젝트에서 제공하는 CrudRepository 를 확장한 RedisRepository 사용
- RedisRepository 를 사용하는 방식도 내부에서는 RedisTemplate 스프링 빈에 의존함
애플리케이션이 레디스를 어떤 목적의 데이터 저장소로 사용하는지에 따라서 어떤 방법을 사용할 지 결정하면 된다.
레디스를 주 데이터 저장소로 사용한다면 RedisRepository 방식을 권장한다.
이 포스트에서는 레디스를 데이터 저장소 뿐 아니라 여러 가지 목적으로 활용하므로 RedisTemplate 클래스를 사용할 예정이다.
2.1. RedisAutoConfiguration 자동 설정
이 포스트에서는
RedisAutoConfiguration을 사용하는 대신RedisTemplate스프링 빈을 직접 설정하는 방식으로 진행한다.
RedisTemplate를 직업 설정하면 개발자가 원하는 클래스 타입의 데이터를 직렬화/역직렬화가 가능하다.그러므로 아래 내용은 참고만 하자.
RedisTemplate스프링 빈을 직접 설정하는 방식은 1.3.RedisTemplate스프링 빈 직접 설정 를 참고하세요.
스프링 부트의 spring-boot-autoconfigure 프로젝트에는 레디스를 사용할 수 있는 RedisTemplate 스프링 빈을 자동 설정하는 org.springframework.boot.autoconfigure.data.redis 의 RedisAutoConfiguration 자동 설정 클래스를 제공한다.
spring-boot-autoconfigure프로젝트는 Reactive 프로그래밍을 위한RedisReactiveAutoConfiguration자동 설정 클래스도 제공함
아래 RedisAutoConfiguration 자동 설정 클래스가 어떤 스프링 빈을 생성하는지 보자.
RedisAutoConfiguration.java
package org.springframework.boot.autoconfigure.data.redis;
// ...
public class RedisAutoConfiguration {
// ...
@Bean
// BeanFactory 에 redisTemplate 이름을 갖는 스프링 빈이 없고,
@ConditionalOnMissingBean(
name = {"redisTemplate"}
)
// RedisConnectionFactory 클래스 타입의 스프링 빈이 BeanFactory 에 단독으로 존재하는 후보자라면 스프링 빈 생성
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
// 자동 설정 클래스에서 생성하는 스프링 빈은 RedisTemplate 클래스 타입이고,
// 제네릭 타입을 사용하여 설정한 레디스 키와 밸류 타입은 둘 다 Object 클래스 타입임
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
// BeanFactory 에 StringRedisTemplate 클래스 타입의 스프링 빈이 없고,
// RedisConnectionFactory 클래스 타입의 스프링 빈이 BeanFactory 에 단독으로 존재하는 후보자라면 스프링 빈 생성
@Bean
@ConditionalOnMissingBean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
// 자동 설정 클래스에서 생성하는 스프링 빈은 StringRedisTemplate 클래스 타입이고,
// 제네릭 타입을 사용하여 설정한 레디스 키와 밸류 타입은 둘 다 String 클래스 타입임
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
return new StringRedisTemplate(redisConnectionFactory);
}
}
RedisAutoConfiguration 자동 설정 클래스에서는 RedisTemplate 과 StringRedisTemplate 스프링 빈을 모두 생성한다.
RedisTemplate 과 StringRedisTemplate 의 차이는 설정된 RedisSerializer 구현체이다.
RedisSerializer 는 레디스 데이터인 key-value 데이터를 직렬화/역직렬화하는 기능을 담당한다.
RedisTemplate 는 o.s.data.redis.serializer 패키지의 JdkSerializationRedisSerializer 를 사용하여 JDK 의 기본 직렬화/역직렬화 방식을 사용하여 Object 를 byte[] 로 직렬화하고, byte[] 를 Object 로 역직렬화한다.
StringRedisTemplate 는 StringRedisSerializer 를 사용하므로 String 을 byte[] 로 직렬화하고, byte[] 를 String 으로 역직렬화한다.
RedisAutoConfiguration 를 사용하려면 application.properties 설정이 필요하다.
설정은 레디스 한 대만 연결하는 케이스, 레디스 클러스터에 연결하는 케이스, 센티넬에 연결하는 케이스, 이렇게 총 3 가지로 나뉜다.
application.properties
## 레디스 한 대만 연결하는 케이스
spring.data.redis.url=127.0.0.1
spring.data.redis.port=1111
# 레디스 서버에 명령어 전달 후 결과를 받을 때까지 최대 시간
spring.data.redis.timeout=1s
# 레디스 서버와 클라이언트 사이에 커넥션 생성 시 걸리는 최대 시간
spring.data.redis.connect-timeout=3s
## 레디스 클러스터에 연결하는 케이스
# 레디스 클러스터의 노드 주소 입력
spring.data.redis.cluster.nodes=127.0.0.1:1111,127.0.0.1:1112,127.0.0.1:1113
# 레디스 클러스터 데이터를 샤딩하고 있어 전체 데이터의 일부분만 각 노드에 저장
# 이 때 잘못된 노드에 데이터를 조회할 때 데이터를 저장한 노드로 리다이렉션하는 횟수
spring.data.redis.cluster.max-redirects=3
## 센티넬에 연결하는 케이스
# 레디스 센티넬이 모니터링할 레디스 서버 중 마스터 서버 이름 설정
spring.data.redis.sentinel.master=REDIS_MASTER_NAME
# 레디스 센티넬들의 노드 주소
spring.data.redis.sentinel.nodes=127.0.0.1:1111,127.0.0.1:1112,127.0.0.1:1113
위와 같이 설정하면 아래와 같이 RedisTemplate 과 StringRedisTemplate 스프링 빈을 주입받을 수 있다.
@Component
public class RedisAdapter {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private StringRedisTemplate redisStringTemplate;
}
2.2. 레디스 도커 설정
# 레디스 최신 버전 이미지를 로컬 호스트에 내려받음
$ docker pull redis
# 도커 이미지 리스트 조회
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
redis latest e579380d4317 3 days ago 138MB
# 컨테이너 실행, 이름은 spring-tour-redis
# 레디스 컨테이너 6379 번 포트와 로컬 호스트의 6379 번 포트 연결
$ docker run --name spring-tour-redis -p 6379:6379 redis
1:C 22 Oct 2023 04:08:48.334 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 22 Oct 2023 04:08:48.334 * Redis version=7.2.2, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 22 Oct 2023 04:08:48.335 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
1:M 22 Oct 2023 04:08:48.336 * monotonic clock: POSIX clock_gettime
1:M 22 Oct 2023 04:08:48.340 * Running mode=standalone, port=6379.
1:M 22 Oct 2023 04:08:48.346 * Server initialized
1:M 22 Oct 2023 04:08:48.348 * Ready to accept connections tcp
# spring-tour-redis 실행
$ docker start spring-tour-redis
# 실행 중인 도커 확인
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cd367c349449 redis "docker-entrypoint.s…" 44 seconds ago Up 41 seconds 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp spring-tour-redis
# 도커 내부에서 레디스 커맨드 모드로 접속하는 redis-cli 명령어를 사용하여 127.0.0.1 호스트에 접속
$ docker exec -it spring-tour-redis /bin/bash
root@cd367c349449:/data# redis-cli -h 127.0.0.1
127.0.0.1:6379>
127.0.0.1:6379> SET hotel:billing-code:1 "11111"
OK
127.0.0.1:6379> GET hotel:billing-code:1
"11111"
127.0.0.1:6379> KEYS *
1) "backup2"
2) "backup4"
3) "backup3"
4) "hotel:billing-code:1"
5) "backup1"
127.0.0.1:6379> quit
도커 명령어들은 Redis Commands 공홈 를 참고하세요.
3. Lettuce 라이브러리와 커넥션 설정
스프링 부트 애플리케이션은 Lettuce 라이브러리를 기본으로 사용한다.
Lettuce 는 내부에 Netty 프레임워크를 포함하고 있어서 비동기 논블로킹으로 구현되어 있다.
그래서 스프링 애플리케이션과 레디스 사이에 커넥션 풀이 필요없다. 즉, 하나의 커넥션을 맺고 사용하면 된다.
비동기 논블로킹이므로 스프링 부트 애플리케이션이 멀티 스레디를 사용하더라도 멀티 스레드에 안전한 프로그래밍을 할 수 있다.
Lettuce 공식 문서에도 하나의 커넥션을 만들고, 만든 커넥션들을 공유해서 사용하는 방식으로 가이드하고 있다.
Redis 자체가 싱글 스레드 기반이기 때문에 여러 커넥션을 사용한다고 해서 성능이 좋아지지 않기 때문이다.
단, 레디스의 트랜잭션 기능을 사용한다면 커넥션 풀을 설정해서 사용하는 것이 좋다.
7.10.1. Is connection pooling necessary?
Lettuce is thread-safe by design which is sufficient for most cases.
All Redis user operations are executed single-threaded.
Using multiple connections does not impact the performance of an application in a positive way.
The use of blocking operations usually goes hand in hand with worker threads that get their dedicated connection.
The use of Redis Transactions is the typical use case for dynamic connection pooling as the number of threads requiring a dedicated connection tends to be dynamic.
That said, the requirement for dynamic connection pooling is limited.
Connection pooling always comes with a cost of complexity and maintenance.참고 사이트: Lettuce reference
3.1. RedisConnectionFactory 설정
RedisTemplate 는 레디스에 명령어를 실행하는 기능을 제공하는 클래스이다.
레디스와 애플리케이션 사이에 커넥션을 맺고 관리하는 기능을 o.s.data.redis.connection 패키지의 RedisConnectionFactory 구현체에 위임하는데, RedisConnectionFactory 객체를 생성한 후 RedisTemplate 의 setConnectionFactory() 메서드 인자로 설정하면 된다.
Spring Data Redis 에서는 RedisConnectionFactory 인터페이스를 구현한 구현체로 JedisConnectionFactory 와 LettuceConnectionFactory 클래스를 기본으로 제공한다.
애플리케이션에서 사용할 레디스 드라이버 라이브러리에 따라 구현체를 선택하면 되며, 이 포스트에서는 LettuceConnectionFactory 를 스프링 빈으로 설정하는 방법에 대해 알아본다.
레디스 서버는 아키텍처에 따라 레디스 서버 단독 구성, 레디스 센티넬 구성, 레디스 클러스터 구성으로 구분할 수 있는데, 사용하는 아키텍처에 따라 LettuceConnectionFactory 객체를 설정하면 된다.
스프링 프레임워크는 o.s.data.redis.connection 패키지의 RedisConfiguration 인터페이스를 제공하는데, 이 인터페이스는 레디스 설정 정보를 포함하며 아키텍처에 따른 구현체들을 제공한다.
적절한 구현체를 생성/설정한 후 LettuceConnectionFactory 생성자의 인자로 전달하면 된다.
<RedisConfiguration 인터페이스가 제공하는 구현 클래스>
RedisStandaloneConfiguration- 단독으로 구성된 레디스 서버에 커넥션 맺을 때 사용
RedisSentinelConfiguration- 레디스 센티넬 구조로 구성된 레디스 센티넬 서버에 커넥션 맺을 때 사용
RedisClusterConfiguration- 레디스 클러스터 구조로 구성된 레디스 서버에 커넥션 맺을 때 사용
RedisStaticMasterReplicaConfiguration- 레디스 Master-Replica 구조로 구성된 레디스 서버에 커넥션 맺을 때 사용
RedisSocketConfiguration- 유닉스 도메인 소켓을 이용하여 애플리케이션과 같은 로컬 호스트에 설치된 레디스 서버에 커넥션 맺을 때 사용
- TCP 소켓을 사용하는 것보다 빠르며, 메모리 사용량이 적은 장점이 있음
이 포스트에서는 RedisStandaloneConfiguration, RedisSentinelConfiguration, RedisClusterConfiguration 을 사용하여 RedisConnectionFactory 스프링 빈을 생성하는 법에 대해 알아본다.
3.1.1. RedisStandaloneConfiguration 을 사용하여 RedisConnectionFactory 스프링 빈 생성
/config/CacheConfig.java
package com.assu.study.chap10.config;
import io.lettuce.core.ClientOptions;
import io.lettuce.core.SocketOptions;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceClientConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import java.time.Duration;
// RedisConnectionFactory 스프링 빈 생성
@Slf4j
@Configuration
public class CacheConfig {
@Bean
public RedisConnectionFactory cacheRedisConnectionFactory() {
// 레디스 서버의 IP, 포트 설정
RedisStandaloneConfiguration configuration = new RedisStandaloneConfiguration("127.0.0.1", 6379);
// 레디스의 데이터베이스 번호 설정
// 레디스 서버는 내부에서 16개의 데이터베이스를 구분해서 운영 가능하며, 0~15번까지의 데이터베이스를 가짐
// 개발 환경에서 장비를 효츌적으로 사용하기 위해 데이터베이스를 구분하여 각 컴포넌트에 할당해서 운영 가능
configuration.setDatabase(0);
configuration.setUsername("username");
configuration.setPassword("password");
// 레디스와 클라이언트 사이에 커넥션을 생성할 때 소요되는 최대 시간 설정
// 설정한 SocketOptions 객체는 ClientOptions 객체에 다시 랩핑함
// 랩핑한 ClientOptions 는 LettuceClientConfigurationBuilder 의 clientOptions() 메서드를 사용하여 설정 가능
final SocketOptions socketOptions = SocketOptions.builder().connectTimeout(Duration.ofSeconds(10)).build();
final ClientOptions clientOptions = ClientOptions.builder().socketOptions(socketOptions).build();
LettuceClientConfiguration lettuceClientConfiguration = LettuceClientConfiguration.builder()
.clientOptions(clientOptions)
.commandTimeout(Duration.ofSeconds(5)) // 레디스 명령어를 실행하고 응답받는 시간 설정
.shutdownTimeout(Duration.ZERO) // 레디스 클라이언트가 안전하게 종료하려고 애플리케이션이 종료될 때까지 기다리는 최대 시간
.build();
return new LettuceConnectionFactory(configuration, lettuceClientConfiguration);
}
}
3.1.2. RedisSentinelConfiguration 을 사용하여 RedisConnectionFactory 스프링 빈 생성
/config/CacheConfig.java
package com.assu.study.chap10.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.RedisSentinelConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
// RedisConnectionFactory 스프링 빈 생성
@Slf4j
@Configuration
public class CacheConfig {
// RedisSentinelConfiguration 으로 RedisConnectionFactory 스프링 빈 생성
@Bean
public RedisConnectionFactory cacheConnectionFactory() {
RedisSentinelConfiguration configuration = new RedisSentinelConfiguration();
// 레디스 센티넬이 모니터링할 레디스 서버 중 마스터 서버 이름 설정
configuration.setMaster("REDIS_MASTER_NAME");
// 레디스 센티넬 서버들 설정
configuration.sentinel("127.0.0.1", 1111);
configuration.sentinel("127.0.0.1", 1112);
configuration.sentinel("127.0.0.1", 1113);
// 센티넬 암호 설정
configuration.setPassword("password");
return new LettuceConnectionFactory(configuration);
}
}
3.1.3. RedisClusterConfiguration 을 사용하여 RedisConnectionFactory 스프링 빈 생성
/config/CacheConfig.java
package com.assu.study.chap10.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisClusterConfiguration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.RedisNode;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import java.util.List;
// RedisConnectionFactory 스프링 빈 생성
@Slf4j
@Configuration
public class CacheConfig {
// RedisClusterConfiguration 으로 RedisConnectionFactory 스프링 빈 생성
@Bean
public RedisConnectionFactory cacheConnectionFactory() {
RedisClusterConfiguration configuration = new RedisClusterConfiguration();
// (error) Moved Redirection 처리 횟수 설정
configuration.setMaxRedirects(3);
// 레디스 클러스터에 포함된 레디스 서버 설정
// 클러스터에 포함된 일부 노드 정보만 입력해도 클러스터의 모든 정보가 클라이언트에 동기화되므로 일부만 입력해도 사용 가능함
configuration.setClusterNodes(List.of(
new RedisNode("127.0.0.1", 1111),
new RedisNode("127.0.0.1", 1112),
new RedisNode("127.0.0.1", 1113)
));
return new LettuceConnectionFactory(configuration);
}
}
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 스프링 부트로 개발하는 MSA 컴포넌트를 기반으로 스터디하며 정리한 내용들입니다.
- 스프링 부트로 개발하는 MSA 컴포넌트
- Spring Boot 공홈
- Redis 데이터 타입: 공홈
- Redis Commands 공홈
- Lettuce reference
- Event Loop
- Redis - Sorted Set
- 2. Master & Slave & Sentinel
- Redis - Redis Cluster & Monitoring (2)
- Redis 커넥션 풀
