Spring Boot - 스케쥴링 태스크
in DEV on Springboot, MSA(Spring), Scheduled, Enable-scheduling, Task-scheduler, Cron, Fixed-delay, Fixed-rate, Batch
이 포스트에서는 스프링 프레임워크에서 제공하는 스케쥴링 기능을 설정하는 법과 스케쥴을 설정하여 태스크를 실행하는 법, 그리고 배치 서버를 구성하는 법에 대해 알아본다.
배치 프로세스는 스케쥴링, 트리거, 태스크로 구성된다.
- 스케쥴링
- 특정 시간을 예약하는 것
- 트리거
- 스케쥴에 맞추어 태스크를 실행하는 것
- 태스크
- 실행할 작업
배치 프로세스 중 처리하는 데이터 크기가 작고, 처리 주기가 비교적 짧은 배치를 마이크로 배치라고 하는데 해당 포스트에서는 마이크로 배치에 대해 집중하여 알아본다.
소스는 github 에 있습니다.
목차
개발 환경
- 언어: java
- Spring Boot ver: 3.1.5
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Maven
- Group: com.assu.study
- Artifact: chap11
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.assu</groupId>
<artifactId>study</artifactId>
<version>1.1.0</version>
</parent>
<artifactId>chap11</artifactId>
</project>
웹 관련 스프링 빈이나 컴포넌트들을 생성하지 않기 위해 아래와 같이 설정한다. application.properties
# 웹 관련 스프링 빈이나 컴포넌트들을 생성하지 않음
spring.main.web-application-type=none
1. 스케쥴링 설정: @EnableScheduling
스프링 프레임워크는 스케쥴링 기능을 쉽게 사용할 수 있는 2 개의 애너테이션을 정의한다.
@EnableScheduling- 스프링 애플리케이션에서 스케쥴링 기능을 사용할 수 있도록 함
@Scheduled- 태스크의 실행 주기를 설정하고, 태스크를 실행
자바 설정 클래스에 @EnableScheduling 애너테이션을 정의하면 스케쥴링 기능을 사용할 수 있다.
상세 코드는 1.1.
SchedulingConfigurer를 사용한TaskScheduler설정 에 있습니다.
스케쥴링 태스크는 별도의 스레드에서 실행되는데, 태스크는 스케쥴링 기능에 미리 설정된 o.s.scheduling.TaskScheduler 의 스레드에서 실행된다.
이 TaskScheduler 는 @EnableScheduling 애너테이션이 애플리케이션을 설정하는 클래스 중 o.s.scheduling.config.ScheduledTaskRegistrar 로 설정된다.
별도의 taskScheduler 설정이 없다면 Executors.newSingleThreadScheduledExecutor() 메서드를 사용하여 싱글 스레드 TaskScheduler 를 생성한다. 따라서 @EnableScheduling 의 기본값으로 설정된 TaskScheduler 는 스레드 개수가 1 개 이다. 즉, 2개 이상의 태스크는 동시에 실행할 수 없다.
만약에 애플리케이션에서 2 개 이상의 태스크를 동시에 실행해야 한다면 별도의 TaskScheduler 스프링 빈을 생성한 후 설정해야 한다.
이 포스트에서 사용하는 TaskScheduler 구현체는 o.s.scheduling.concurrent.ThreadPoolTaskScheduler 클래스이다.
이 구현체 내부에는 한 개 이상의 스레드를 포함하는 스레드 풀을 설정할 수 있기 때문에 필요한 만큼 스레드 풀을 설정하면 된다.
스프링 프레임워크에서 스케쥴이 사용하는 TaskScheduler 를 재설정하는 방법은 2 가지가 있다.
- 스케쥴링 기능을 확장할 수 있는 o.s.scheduling.annotation.
SchedulingConfigurer인터페이스를 사용하여 재설정 - 스프링 프레임워크 내부 관례에 따른 스프링 빈을 정의
1.1. SchedulingConfigurer 를 사용한 TaskScheduler 설정
스프링 프레임워크에서는 스케쥴링 기능을 확장하는 SchedulingConfigurer 인터페이스를 제공한다.
이 인터페이스의 configureTasks() 메서드는 ScheduledTaskRegistrar 를 인자로 받는데, 이 ScheduledTaskRegistrar 는 TaskScheduler 를 설정하는 헬퍼 클래스이다.
스프링 프레임워크가 스케쥴링 기능을 활성화할 때 SchedulingConfigurer 에 설정된 TaskScheduler 객체를 확인하고, 설정된 TaskScheduler 가 있다면 이를 사용하여 스케쥴링 기능을 활성화한다.
따라서 자바 설정 클래스는 SchedulingConfigurer 인터페이스를 구현하도록 설계하고, 인터페이스의 configureTasks() 메서드를 구현한다.
이 때 메서드의 인자인 ScheduledTaskRegistrar 객체에 TaskScheduler 구현체를 설정하면 구현체의 스레드를 사용하여 스케쥴링 태스크를 실행한다.
아래는 SchedulingConfig 자바 설정 클래스이다.
/config/SchedulingConfig.java
package com.assu.study.chap11.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.SchedulingConfigurer;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
import org.springframework.scheduling.config.ScheduledTaskRegistrar;
@EnableScheduling
@Configuration
public class SchedulingConfig implements SchedulingConfigurer {
// 스케쥴링 기능을 확장할 수 있는 o.s.scheduling.annotation.`SchedulingConfigurer` 인터페이스를 사용하여 재설정
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
// 2 개 이상의 태스크를 동시에 실행하려면 ThreadPoolTaskScheduler 구현 클래스 사용
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(10); // 스레드 갯수 설정
taskScheduler.setThreadNamePrefix("TaskScheduler-");
taskScheduler.initialize(); // 설정을 마치면 객체 초기화 필요
taskRegistrar.setTaskScheduler(taskScheduler);
}
}
1.2. ScheduledAnnotationBeanPostProcessor 와 TaskScheduler 설정
@EnableScheduling 애너테이션은 @Configuration 애너테이션이 정의된 SchedulingConfiguration.class 자바 설정 클래스를 포함한다.
이 자바 설정 클래스는 o.s.scheduling.annotation.ScheduledAnnotationBeanPostProcessor 를 사용하여 스프링 프레임워크의 스케쥴링 기능을 설정한다.
ScheduledAnnotationBeanPostProcessor 일부
public class ScheduledAnnotationBeanPostProcessor implements ...{
public static final String DEFAULT_TASK_SCHEDULER_BEAN_NAME="taskScheduler";
// ...
}
위의 DEFAULT_TASK_SCHEDULER_BEAN_NAME 상수는 ScheduledAnnotationBeanPostProcessor 클래스 내부에서 TaskScheduler 스프링 빈의 유무를 조회하는 resolveScheduleBean() 에서 스프링 빈 이름으로 사용한다.
즉, 스프링 빈 이름이 taskScheduler 이고, 클래스 타입이 TaskScheduler 인 스프링 빈이 있으면 이를 사용한다.
따라서 아래처럼 TaskScheduler 스프링 빈을 정의하면 ScheduledAnnotationBeanPostProcessor 가 초기화되면서 사용한다.
아래에서 정의하는 스프링 빈의 타입은 TaskScheduler 이고, 스프링 빈 이름은 taskScheduler 이다.
/config/SchedulingConfig.java
package com.assu.study.chap11.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.TaskScheduler;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.SchedulingConfigurer;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
@EnableScheduling
@Configuration
public class SchedulingConfig {
// 스프링 프레임워크 내부 관례에 따른 스프링 빈을 정의 (`ScheduledAnnotationBeanPostProcessor` 와 `TaskScheduler` 설정)
@Bean
public TaskScheduler taskScheduler() {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(10);
taskScheduler.setThreadNamePrefix("TaskScheduler-");
taskScheduler.initialize();
return taskScheduler;
}
}
2. 스케쥴링 태스크 정의: @Scheduled
위에서 스케쥴링 기능을 설정하는 방법에 대해 보았고, 이제 작업 주기를 설정하고 주기적으로 작업하는 태스크를 정의하는 방법에 대해 알아본다.
/schedule/ScheduleTask.java
package com.assu.study.chap11.schedule;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class ScheduleTask {
@Scheduled(fixedRate = 1000L) // 1초 간격으로 태스크 실행
public void triggerEvent() {
log.info("Triggered Event.");
}
}
@Scheduled 애너테이션을 사용하는 규칙은 아래와 같다.
- 스케쥴 태스크를 실행하려면 스프링 빈의 메서드에 정의해야 함
- 정의된 메서드의 리턴 타입은 void 이어야 하고, 인자를 정의하면 안됨
- 해당 메서드의 접근 제어자는 public 이어야 함
만일 위의 triggerEvent() 메서드 내용이 복잡해지면 비즈니스 로직을 실행하는 클래스에 기능을 위임할 수 있다. 이 때 ScheduledTask 클래스도 스프링 빈이므로 다른 스프링 빈을 주입받아서 사용할 수 있다.
위에선 fixedRate 를 이용하여 스케쥴링하는데 이 외에도 cron, fixedDelay 속성이 있다.
cronfixedDelay- 태스크와 태스크 사이의 지연 시간 설정
- 실행한 태스크가 ‘종료’된 후 설정된 시간만큼 쉬고 다음 태스크 실행
fixedRate- 태스크와 태스크 사이의 실행 주기 설정
- 태스크 실행 후 설정된 시간 후에 다시 태스크 실행
cron은 정해진 시각에 태스크를 실행하는 방면fixedRate는 애플리케이션이 시작한 후 정해진 간격으로 태스크 실행
@Scheduled 애너테이션
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Repeatable(Schedules.class)
@Reflective
public @interface Scheduled {
String CRON_DISABLED = "-";
// 크론 표현식을 사용하여 스케쥴링 설정
String cron() default "";
// 스케쥴링할 수 있는 타임존 값 설정
// 설정하지 않으면 서버에 설정된 타임존 값을 사용
// 한국의 타임존 값은 Asia/Seoul 이며, 설정된 타임존 값은 java.util.TimeZone 클래스의 getTimeZone() 을 사용하여 변경할 수 있음
String zone() default "";
// fixedDelay() 에 설정된 시간만큼 태스크와 태스크 사이의 지연 시간 설정
// 실행한 태스크가 '종료'된 후 설정된 시간만큼 쉬고 다음 태스크 실행
// long 값으로 설정할 때는 fixedDelay() 를 사용하고, String 값으로 설정할 때는 fixedDelayString() 사용
long fixedDelay() default -1L;
String fixedDelayString() default "";
// fixedRate() 에 설정된 시간만큼 태스트와 태스크 사이의 실행 주기 설정
// 태스크 실행 후 설정된 시간 후에 다시 태스크 실행
// long 값으로 설정할 때는 fixedRate() 를 사용하고, String 값으로 설정할 때는 fixedRateString() 사용
long fixedRate() default -1L;
String fixedRateString() default "";
// 스케쥴링 기능이 초기화된 후 initialDelay() 에 설정된 시간만큼 쉰 후에 첫 태스크 실행
// 초기 지연값이므로 두 번째 실행하는 태스크부터는 영향이 없음
// fixedDelay() 와 fixedRate() 를 조합하여 사용함
long initialDelay() default -1L;
String initialDelayString() default "";
// @Scheduled 에 설정된 시간 시간 단위는 ms 로, 이를 변경할 때 사용하는 속성
// TimeUnit 에 설정된 상수를 사용하여 설정함
TimeUnit timeUnit() default TimeUnit.MILLISECONDS;
}
2.1. cron 속성과 클론 표현식
크론 표현식은 6 자리로 표현 가능하다.
@Scheduled(cron=”초 분 시 일 달 요일”)
| 자리 | 사용가능한 값 | 사용가능한 크론 표현식 |
|---|---|---|
| 초 | 0~59 | *, /, ,, - |
| 분 | 0~59 | *, /, ,, - |
| 시 | 0~23 | *, /, ,, - |
| 일 | 1~31 | *, /, ,, -, L, W |
| 달 | 1~12 또는 JAN~DEC | *, /, ,, - |
| 요일 | 0~7 또는 SUN~SAT | *, /, ,, -, L, W, # |
숫자 대신 크론 표현식으로 문자를 설정할 수 있다.
| 크론 표현식 | 설명 | 예시 |
|---|---|---|
* | 모든 값 | |
? | 어떤 값이든 상관없음 | |
, | 배열 설정 | 0,1,2,3 |
- | 범위 설정 | 10-20 (10 부터 20 사이) |
/ | 초기값과 증분값 설정 | 0/10 (초기값 0, 증분값 10) |
# | 요일과 몇 번째 설정 | 5#2 (목요일#두번째) |
L | 마지막 날 의미 | |
W | 스테쥴링된 날로부터 가까운 평일 의미 |
크론 표현식 예시는 아래와 같다.
@Scheduled(cron="* 0/10 * * * ?")- 10분마다 태스크 실행
@Schedlued(cron="0 0 2 * * ?")- 매일 새벽 2시 정각마다 태스크 실행
@Schedlued(cron="0 0 6 * * SUN")- 매주 일요일 오전 6시 정각마다 태스크 실행
@Schedlued(cron="0 0 1,2,3 ? * MON")- 매주 월요일 새벽 1시, 2시, 3시에 태스크 실행
크론 표현식은 스프링 프레임워크 내부에서 o.s.scheduling.support.CronExpression 클래스의 parse() 를 사용하여 파싱한다.
아래는 크론 표현식을 확인하는 테스트케이스이다.
test > CronExepressionTest.java
package com.assu.study.chap11;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.scheduling.support.CronExpression;
import java.time.LocalDateTime;
public class CronExpressionTest {
@Test
void testParse() {
// 크론 표현식을 파싱하여 CronExpression 객체 생성
CronExpression expression = CronExpression.parse("0/5 * * * * ?");
// next() 는 인자로 받은 시간의 다음 스케쥴링 시간을 응답
LocalDateTime nextScheduled = expression.next(LocalDateTime.of(2023, 1, 1, 0, 0, 0));
Assertions.assertEquals("2023-01-01T00:00:05", nextScheduled.toString());
Assertions.assertEquals("2023-01-01T00:00:10", expression.next(nextScheduled).toString());
}
}
크론 표현식 “0/5 * * * * ?” 은 5초마다 태스크를 실행한다.
태스크 실행 시간이 3~4초면 5초마다 태스크가 실행되겠지만, 만일 태스트 실행 시간이 6초가 되면 이미 이전에 진행되고 있던 태스크가 있기 때문에 두 번째 태스크가 생략된다.
즉, 태스트 실행 시간이 스케쥴링 주기보다 짧은 때는 매번 태스크가 실행되지만, 태스크 실행 시간이 스케쥴링 시간을 초과하면 다음 스케쥴의 태스크가 실행되지 않는다. (= 중첩된 시간의 태스크는 실행하지 않음)
태스크 실행 시간은 항상 정해진 시간에 끝나지 않는다.
항상 장애 상황이나 시스템에 부하가 커져 있을 상황을 대비해야 한다. 서비스 규모가 커지면 데이터 크기가 커지므로 태스크 실행 시간도 점점 늘어날 수 있다.
예를 들어 아래와 같은 상황을 보자.
@Scheduled(cron="0 0/5 * * * ?") 5분 간격으로 태스크를 실행하며 가입 유저들에게 쿠폰을 발송하는 상황을 가정해본다.
// 장애에 취약한 코드
LocalDateTime from = LocalDateTime.now().withSecond(0).minusMinutes(5);
LocalDateTime to = LocalDateTime.now().withSecond(0);
userRepository.findByCreatedAtBetween(from, to);
위 코드는 지난 5분간 데이터만 조회하는 로직으로 구성되어 있다.
만일 00:10:00 에 실행되어야 하는 태스크가 생략이 되었다고 하면 00:05:00~00:10:00 사이에 가입한 유저들은 쿠폰을 받지 못하게 된다.
다음 스케쥴인 00:15:00 에 실행되는 태스크는 00:10:00~00:15:00 사이에 가입한 유저들에게만 쿠폰을 보내므로 결국 쿠폰을 받지 못하는 유저들이 발생하게 된다.
// 장애에 견고한 코드
LocalDateTime to = LocalDateTime.now().withSeconds(0);
CouponFlag flag = CouponFlag.UNSET;
Integer fetchCount = 1000;
userRepository.findByCreatedBeforeCouponFlagAndSize(to, flgs, fetchCount);
위 코드는 현재 시간보다 과거이고, CouponFlag 가 UNSET 인 유저들만 조회한다.
만일 시스템 장애가 1시간 동안 발생하고, 그 시간동안 가입한 유저가 1만명일 경우 fetchCount 가 없으면 1만명을 한 번에 쿼리할 것이다.
1만명의 데이터를 동시에 처리하면 다시 장애가 발생할 수 있으므로 5분동안 처리할 수 있는 임의의 숫자를 적절히 처리하는 것이 중요하다.
3. 배치 서버 아키텍처
태스크들이 복합적으로 결합해서 데이터를 가공할 때는 태스크 간 의존성이 있는 경우이다.
즉, 앞선 태스크가 처리한 데이터를 재가공하여 새로운 데이터를 뽑아내는 태스크는 태스크 사이에 의존성이 있다고 한다.
이때는 일반 스프링 프레임워크보다는 배치 프로세싱에 적합한 애플리케이션 구조와 기능들을 제공하는 스프링 배치 프레임워크를 사용하는 것이 좋다.
별도의 서버군을 구축하는 것이 오히려 시스템 낭비가 될 정도로 작은 배치 프로세스는 REST-API 서버군에서 실행해도 된다.
한 코드베이스에서 API 와 배치 프로세스가 모두 포함되어 있으므로 전체 비즈니스 로직을 파악하기에 유리한 장점이 있다.
배치 서버를 독립적으로 구성하던, API 서버에서 구성하던 장애에 대비하여 2 대 이상의 서버를 두어 고가용성을 유지하는 것이 좋다.
2 대 이상의 배치 서버를 구성할 때 주의할 점은 중복 실행이다. 또한 동시에 실행한 배치 프로세스는 공유 자원에 DeadLock 을 발생시킬 수 있다.
아래와 같은 방법으로 DeadLock 을 회피할 수 있다.
- 모든 서버군의 서버는 NTPD 를 사용하여 서버 시간을 동기화
- 배치 프로세스의 스케쥴링은
@Scheduled애너테이션의cron속성을 사용하여 실행함으로써 서버군에 포함된 모든 서버의 배치 프로세스가 같은 시간에 실행되도록 함 - 중복 실행을 막고자 레디스의 분산락을 사용하여 가장 먼저 실행된 배치 프로세스가 데이터를 처리
- 장애에 견고한 코드를 작성하여 실행되지 못한 태스크는 자동으로 복구할 수 있도록 작성
- 짧은 주기의 배치 프로세스가 아니라면 수동으로 복구할 수 있는 기능 개발
3.1. 단독 배치 서버 구성
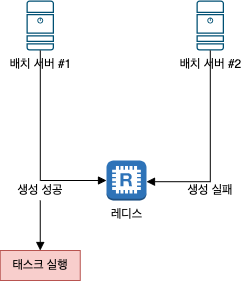
@Scheduled 애너테이션을 사용하여 태스크 스케쥴링을 설정하고 실행하며, 이 때 @Scheduled 의 cron 속성을 사용하여 두 서버 모두 같은 시간, 같은 주기, 같은 태스크를 실행한다.
중복 실행을 막고자 레디스의 분산락을 사용한다.
레디스 분산락을 사용 시 아래 코드를 참고한다.
@Scheduled(cron="0 0/5 * * * ?")
public void sendCoupon() {
// 분산락에 사용할 시간값이므로 초와 나노초값 초기화
// 00:00:05 에 실행 예정인 태스크는 시스템 상황에 따라 00:00:06 에 코드가 실행될 수 있으므로 초기화함
LocalDateTime localDateTime = LocalDateTime.now().withSeconds(0).withNano(0);
DateTimeFormatter fmt = DateTimeFormatter.ofPattern("yyyyMMddhhmmss");
// 분산락 key 를 생성한 후 레디스에 저장
// 분산락 key 는 시간 기반 값이므로 다음 주기에 실행되는 태스크에서 생성한 key 와 다름
// 이 때 key 와 같은 값이 레디스에 이미 있으면 false 를 응답하고, 같은 값이 없으면 key 생성 후 true 응답
String lock = "LOCK::" + fmt.format(localDateTime);
boolean isMine = redisAdapter.createLock(lock);
// 같은 key 가 이미 있으면 다른 태스크가 이미 실행중이므로 분산락을 생성하는데 실패한 태스크는 종료함
if (!isMine) {
return;
}
userService.sendCouponByTime(localDateTime);
}
레디스 분산락을 생성할 때는 반드시 유효 기간을 설정해야 한다. 그래서 위 코드에서 분산락을 삭제하는 별도의 코드가 없다.
아무리 두 서버가 NTPD 를 사용하여 시간을 보정해도 두 서버의 시간이 다를 수 있으므로 분산락의 유효 기간이 짧으면 중복 실행 방지를 막을 수 없기 때문에 유효 기간 시간은 충분히 길게 설정할 필요가 있다.
어차피 분산락은 유효 기간 때문에 자동 삭제되므로 넉넉하게 설정하는 것이 좋다. 저장 공간이 넉넉하면 1~2로 설정해도 무방하다.
5분 주기로 설정한 태스크의 분산락의 유효 기간을 2일로 설정해도 최대 576 개까지 저장됨
매 주기마다 생성되는 분산락의 key 값은 달라야 한다. 그렇지 않으면 다음 주기에 실행되는 태스크는 이전 주기의 태스크가 생성한 분산락과 비교할 때 잘못된 판단을 할 수 있다.
배치 서버에는 웹 서버 기능이 필요없으므로 아래와 같이 웹 서버 기능을 사용하지 않도록 설정해준다.
application.properties
# 웹 관련 스프링 빈이나 컴포넌트들을 생성하지 않음
spring.main.web-application-type=none
설정 가능한 값은 아래와 같다.
- NONE
- 웹 서버를 사용하지 않음
- SERVLET
- 서블릿 스타일의 웹 서버를 설정
- REACTIVE
- 비동기 리액티브 스타일의 웹 서버 설정
3.2. 젠킨스와 REST-API 서버군 구성
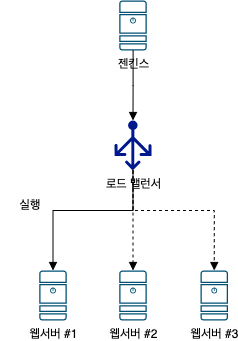
젠킨스는 CI/CD 툴로 알려져있지만 스케쥴링 기능도 제공한다.
젠킨스를 이용하면 @Scheduled 기능없이 쉽게 배치 프로세싱을 구현할 수 있다.
위 그림에서 모든 웹서버는 REST-API 를 제공하고, 해당 REST-API 를 호출하면 특정 태스크를 실행한다.
젠킨스는 REST-API 를 호출할 수 있는 기능을 제공하며, REST-API 를 호출하는 스케쥴을 설정할 수 있다.
이 외에도 REST-API 의 실행 결과를 저장/조회할 수 있다.
따라서 젠킨스를 사용하면 @Scheduled 애너테이션 기능처럼 원하는 주기에 원하는 기능을 실행할 수 있다.
웹서버 #1 에 장애가 발생하면 다른 웹서버들이 요청을 처리하므로 로드 밸런서로 고가용성을 확보할 수 있으며, API 서버 외 별도의 배치 서버를 구성하지 않아도 된다.
하지만 젠킨스 서버도 장애가 발생할 수 있으므로 2 대 이상의 젠킨스 서버를 구축하여 고가용성을 확보해야 한다.
이 구성에는 분산락을 생성할 필요가 없으므로 레디스 서버가 없어도 된다.
3.3. @Scheduled 와 REST-API 서버군 구성
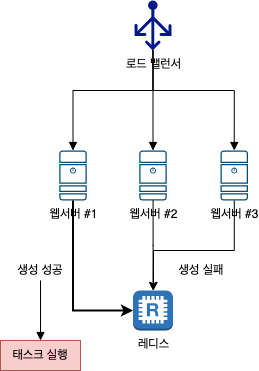
위 그림은 REST-API 서버에 @Scheduled 애너테이션을 사용하여 배치 프로세싱을 실행하는 구조이다.
모든 웹서버에 같은 주기, 같은 시간, 같은 태스크를 실행하므로 분산락이 필요하다.
3.1. 단독 배치 서버 구성 처럼 코드를 작성하면 되며, REST-API 코드베이스에 배치 프로프로세싱 기능을 개발하여 배포하는 것만 다르다.
별도의 젠킨스 서버나 배치 서버가 필요하지는 않지만 배치 프로세싱 작업 크기가 커지면 특정 REST-API 서버에 부하가 갈 수 있으므로 언제든지 별도의 배치 서버로 분리할 수 있도록 해야한다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 스프링 부트로 개발하는 MSA 컴포넌트를 기반으로 스터디하며 정리한 내용들입니다.
