Kafka - 카프카 기본
이 포스트에서는 카프카의 기본 개념에 대해 알아본다.
목차
1. 카프카 용어
카프카는 메시지 발생/구독 시스템으로 카프카에 저장된 데이터는 순서를 유지한채로 지속성있게 보관되며, 확장 시 성능을 향상시키고 실패가 발생해도 데이터 사용에는 문제가 없도록 데이터를 분산시켜 저장할 수 있다.
1.1. 메시지, 배치
- 메시지
- 데이터의 기본 단위
- key 라고 불리는 메타 데이터를 포함할 수 있음
- key 는 메시지를 저장할 파티션을 결정하기 위해 사용됨
(키 값에서 일정한 해시값을 생성한 후 이 값을 토픽의 파티션 수로 나눴을 때 나오는 나머지 값에 해당하는 파티션에 메시지 저장, 그러면 같은 키 값을 가진 메시지는 파티션 수가 변하지 않는 이상 항상 같은 파티션에 저장됨)
- 배치
- 메시지를 저장하는 단위로, 같은 토픽의 파티션에 쓰여지는 메시지들의 집합
- 메시지를 쓸 때마다 네크워크 상에서 신호가 오가는 불필요한 오버헤드를 줄이기 위해 메시지를 배치 단위로 모아서 씀 (latency 와 처리량 사이에 트레이드 오프는 발생됨)
- 즉, 배치 크기가 커질수록 시간당 처리되는 메시지 수는 늘어나지만 각 메시지가 전달되는데 걸리는 시간도 함께 늘어남
key, value 에 대한 좀 더 상세한 내용은 1. 프로듀서 를 참고하세요.
1.2. 스키마
메시지는 단순한 바이트의 배열일 뿐이지만 내용을 이해하기 쉽도록 일정한 구조(스키마)를 부여하는 것이 좋다.
스키마는 JSON, XML 을 이용할 수도 있지만 이 방식들은 타입 처리나 스키마 버전 간 호환성 유지 기능이 떨어지기 때문에 아파치 아브로(Avro) 를 권장한다.
아브로는 세밀한 직렬화 형식 제공 및 메시지 본체와 스키마를 분리하기 때문에 스키마가 변경되도 코드를 생성할 필요가 없다.
스키마와 직렬화에 대한 좀 더 상세한 내용은 1. 시리얼라이저 를 참고하세요.
1.3. 토픽, 파티션
- 토픽
- 카프카에 저장되는 메시지는 토픽 단위로 분류됨 (DB 의 테이블이나, 파일 시스템의 폴더 개념)
- 파티션
- 토픽은 여러 개의 파티션으로 구성됨 (커밋 로그로 보았을 때 파티션은 하나의 로그에 해당)
- 파티션에 메시지가 쓰여질때는 추가만 가능하고, 읽을 때는 맨 앞에서부터 제일 끝까지 순서대로 읽힘
토픽 안의 메시지 전체에 대해서는 순서가 보장되지 않으며, 단일 파티션 안에서만 순서가 보장된다.
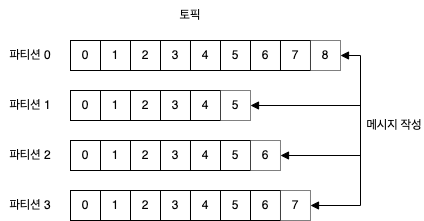
메시지가 쓰여질 때 각 파티션의 끝에 추가가 된다.
파티션은 카프카가 데이터 중복과 확장설을 제공하는 방법이기도 하다.
각 파티션이 서로 다른 서버에 저장될 수 있기 때문에 하나의 토픽이 여러 개의 서버로 수평적으로 확장되어 하나의 서버의 용량을 넘어가는 성능을 보여줄 수 있다.
또한, 파티션은 복제될 수 있다. 즉, 서로 다른 서버들이 동일한 파티션의 복제본을 저장하고 있기 때문에 서버 중 하나에 장애가 발생하더라도 읽거나 쓸 수 없는 상황이 벌어지지 않는다.
스트림은 하나의 토픽에 저장된 데이터로 간주되며, 프로듀서~컨슈머로의 하나의 데이터 흐름을 의미한다.
스트림 처리의 좀 더 상세한 내용은 추후 다룰 예정입니다.
1.4. 프로듀서, 컨슈머
카프카 클라이언트는 기본적으로 프로듀서와 컨슈머, 두 종류가 있다.
이 외에 데이터 통합에 사용되는 카프카 커넥트 API 와 스트림 처리에 사용되는 카프카 스트림즈도 있는데 이 클라이언트들은 프로듀서와 컨슈머를 기본 요소로 사용하며, 좀 더 고급 기능을 제공한다.
- 프로듀서
- 새로운 메시지 생성
- 메시지는 특정 토픽에 쓰여지는데, 기본적으로 프로듀서는 메시지를 쓸 때 토픽에 속한 파티션들 사이에 고르게 나눠서 쓰도록 되어 있음
- 상황에 따라서 프로듀서가 특정 파티션을 지정하여 메시지를 쓰기도 하는데 이는 보통 메시지 키와 키 값의 해시를 특정 파티션으로 대응시켜주는 파티셔너를 사용하여 구현함
- 이렇게 함으로써 동일한 키 값을 가진 모든 메시지는 같은 파티션에 저장됨
프로듀서의 좀 더 상세한 내용은 Kafka - 카프카 프로듀서(1): 프로듀서, 메시지 전달, 프로듀서 설정 와 Kafka - 카프카 프로듀서(2): 시리얼라이저, 파티션, 헤더, 인터셉터, 쿼터/스로틀링 를 참고하세요.
- 컨슈머
- 메시지를 읽음
- 1개 이상의 토픽을 구독해서 여기에 저장된 메시지들을 각 파티션에 쓰여진 순서대로 읽어옴
- 컨슈머는 오프셋을 기록하여 어느 메시지까지 읽었는지는 유지함
- 오프셋
- 정수값으로 카프카가 메시지를 저장할 때 각각의 메시지에 부여하는 메타 데이터
- 파티션의 각 메시지는 고유한 오프셋을 가짐
- 파티션별로 다음 번에 사용 가능한 오프셋 값을 저장함으로써 컨슈머는 읽기 작업을 정지했다가 다시 시작해도 마지막으로 읽었던 메시지의 바로 다음 메시지부터 읽을 수 있음
- 컨슈머 그룹
- 토픽에 저장된 데이터를 읽어오기 위해 하나 이상의 컨슈머로 이루어짐
- 컨슈머 그룹은 각 파티션이 하나의 컨슈머에 의해서만 읽히도록 함
- 컨슈머에서 파티션으로의 대응 관계를 컨슈머의 파티션 소유권 이라고 함
- 이렇게 함으로써 대량의 메시지를 갖는 토픽들을 읽기 위해 컨슈머들을 수평 확장할 수 있고, 컨슈머 중 하나가 장애가 발생하면 그룹 안의 다른 컨슈머들이 장애가 발생한 컨슈머가 읽고 있던 파티션을 재할당받아서 데이터를 읽어옴
컨슈머와 컨슈머 그룹에 대한 좀 더 상세한 내용은 추후 다룰 예정입니다.
1.5. 브로커, 클러스터
- 브로커
- 하나의 카프카 서버를 브로커라고 함
- 프로듀서로부터 메시지를 전달받아 오프셋을 할당한 뒤 디스크 저장소에 쓰는 역할
- 컨슈머의 파티션 읽기(fetch) 요청 처리 후 발행된 메시지를 보내줌
- 보통 하나의 브로커는 초당 수천 개의 파티션과 수백만 개의 메시지 처리 가능
- 클러스터
- 하나의 클러스터 안에 여러 개의 브로커가 포함될 수 있으며, 그 중 하나의 브로커가 클러스터 컨트롤러의 역할을 함
- 컨트롤러
- 파티션을 브로커에 할당해주거나, 장애가 발생한 브로커는 모니터링 하는 등의 관리 기능 담당
- 파티션 리더
- 파티션은 클러스터 안의 브로커 중 하나가 담당하며, 그 브로커를 파티션 리더라고 함
- 팔로워
- 복제된 파티션이 여러 브로커에 할당될 수도 있는데, 이들을 파티션의 팔로워라고 함
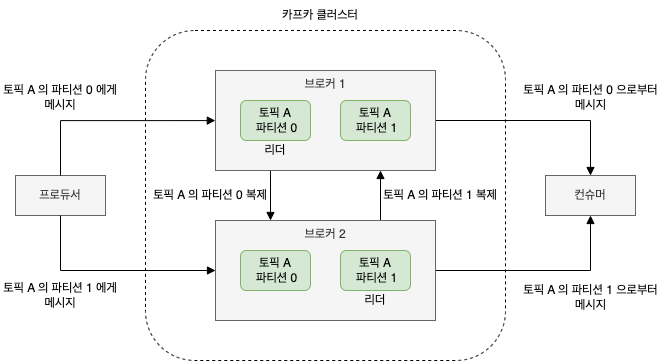
파티션 복제는 파티션의 메시지를 중복 저장함으로써 리더 브로커에 장애가 발생했을 경우 팔로워 중 하나가 리더 역할을 이어받을 수 있도록 한다.
모든 프로듀서는 리더 브로커에게 발행해야 하지만, 컨슈머는 리더나 팔로워 중 하나로부터 데이터를 읽어올 수 있다.
파티션 복제를 포함한 클러스터 기능에 대한 좀 더 상세한 내용은 추후 다룰 예정입니다.
카프카는 일정 기간 동안 메시지를 지속성있게 보관할 수 있다.
브로커는 토픽에 대해 기본적인 보존 설정이 되어 있는데 특정 기간 혹은 파티션의 크기가 특정 사이즈에 도달할 때까지 데이터를 보존하도록 설정할 수 있으며, 한도값에 도달하면 메시지는 만료되어 삭제된다.
토픽에는 로그 압착 (log compaction) 기능을 설정할 수 있는데, 로그 압착은 같은 키를 갖는 메시지 중 가장 최신의 것만 보존하는 기능이다.
로그 압착은 마지막 변경값만 중요한 체인지 로그 형태의 데이터에 사용하면 좋다.
1.6. 다중 클러스터
다중 클러스터를 사용하면 아래와 같은 장점이 있다.
- 데이터 유형별 분리
- 보안 측면에서의 격리
- 재해 복구(Disaster Recovery, DR) 대비
카프카 클러스터의 복제 매커니즘은 다중 클러스터 사이가 아닌 하나의 클러스터 안에서만 작동하도록 설계되었기 때문에 다중 클러스터로 운영 시 클러스터 간 메시지를 복제해주어야 한다.
카프카 프로젝트는 데이터를 다른 클러스터로 복제하는데 사용되는 미러메이커 툴을 포함한다.
미러메이커는 하나의 카프카 클러스터에서 메시지를 읽은 후 다른 클러스터에 쓴다.
미러메이커의 데이터 파이프라인 구축에 관한 좀 더 상세한 내용은 추후 다룰 예정입니다.
2. 카프카 장점
- 다중 프로듀서
- 카프카의 다중 프로듀서 기능때문에 많은 프론트엔드에서 데이터를 수집/일관성 유지하는데 적격임
- 예) 다수의 마이크로서비스를 통해 유저에게 컨텐츠를 서비스할 때 모든 서비스가 공통의 형식으로 쓸 수 있는 페이지 뷰 용 토픽을ㅇ 가질 수 있음
- 컨슈머 애플리케이션은 애플리케이션별로 하나씩, 여러 개의 토픽에서 데이터를 읽어올 필요없이 페이지 뷰 스트림 하나만 읽어오면 됨
- 다중 컨슈머
- 카프카는 많은 컨슈머가 간섭없이 메시지 스트림을 읽을 수 있음
- 이것이 하나의 메시지를 하나의 클라이언트에서만 소비할 수 있도록 되어있는 다른 큐 시스템과의 결정적인 차이점
- 다수의 컨슈머는 컨슈머 그룹을 일원으로 하나의 스트림을 나눠서 읽을 수 있는데 이 때 메시지는 전체 컨슈머 그룹에 대해 한번만 처리됨
- 디스크 기반 보존
- 카프카는 메시지를 지속성있게 저장할 수 있음 (= 컨슈머들이 항상 실시간으로 데이터를 읽어올 필요없음)
- 메시지가 저장될 때 보존 규칙과 함께 저장되는데 이 옵션들은 토픽별로 설정이 가능하기 때문에 서로 다른 메시지 스트림이 서로 다른 기간동안 보존 가능
- 따라서 컨슈머가 트래픽 폭주로 느려질 때도 데이터 유실의 위험이 없음
- 컨슈머를 정지하더라도 메시지는 카프카에 남아있기 때문에 프로듀서가 메시지를 백업하거나 메시지가 유실될 격정없이 애플리케이션을 내리고 컨슈머 유지 보수가 가능_
- 컨슈머를 재시작하면 작업을 멈춘 지점부터 유실없이 데이터 처리 가능
- 확장성
- 카프카는 어떠한 크기의 데이터도 쉽게 처리 가능
- 카프카 클러스터는 작동 중에도 시스템 전체의 가용성에 영향을 주지 않으면서 확장이 가능 (= 여러 대의 브로커로 구성된 클러스터가 개별 브로커의 장애를 처리)
- 동시다발적인 장애를 견뎌야 하는 클러스터의 경우 복제 팩터(Replication Factor, RF) 를 설정해주는 것이 가능
복제에 대한 좀 더 상세한 내용은 추후 다룰 예정입니다.
- 고성능
- 발행된 메시지가 컨슈머에게 전달되기까지 1초도 안 걸리면서 프로듀서, 컨슈머, 브로커 모두 매우 큰 메시지 스트림을 쉽게 다룰 수 있도록 수평확장 가능
- 플랫폼 기능
- 카프카 코어 프로젝트에는 자주 사용하는 작업이 플랫폼화되어 있음
- 카프카 커넥트는 소스 데이터 시스템으로부터 카프카로 데이터를 가져오거나, 카프카의 데이터를 싱크 시스템으로 내보내는 작업을 함
- 카프카 스트림즈는 규모 가변성과 내고장성(fault tolerance) 을 갖춘 스트림 처리 애플리케이션을 쉽게 개발할 수 있도록 해줌
카프카 커넥트에 대한 좀 더 상세한 내용은 추후 다룰 예정입니다.
카프카 스트림즈에 대한 좀 더 상세한 내용은 추후 다룰 예정입니다.
3. 카프카 이용 사례
- 사용자 활동 추적
- 사용자 활동에 대한 메시지들은 하나 이상의 토픽으로 발생되어 백엔드에서 작동 중인 애플리케이션에 전달됨
- 이 애플리케이션들은 보고서를 생성하거나, 사용자 경험을 위한 다른 작업 수행 가능
- 메시지 교환
- 유저에게 이메일 같은 알림을 보내야하는 애플리케이션에서 활용
- 애플리케이션들은 메시지 형식이나 전송 방법에 대해 신경쓰지 않고 메시지 생성 가능
- 지표, 로그 수집
- 여러 애플리케이션이 같은 유형으로 생성한 메시지를 활용하는 대표적인 사례
- 애플리케이션이 정기적으로 지표값을 카프카 토픽에 발행하면, 모니터링 시스템이 이 지표값들을 가져다 사용하는 방식
- 지표, 로그 수집에 카프카를 사용하면 목적 시스템(예- 로그 저장 시스템 변경) 변경 시에도 프론트엔드 애플리케이션이나 메시지 수집 방법 변경 필요없음
- 커밋 로그
- 카프카가 DB 의 커밋 로그 개념을 기반으로 해서 만들어진만큼 DB 의 변경점들이 스트림 형태로 카프카로 발행될 수 있으며, 이 스트림을 이용하여 쉽게 실시간 업데이트를 받아볼 수 있음
- 이 체인지로그 스트림은 DB 에 가해진 업데이트를 원격 시스템으로 복제하거나, 여러 애플리케이션에서 발생한 변경점을 하나의 DB 뷰로 통합하는데 사용 가능
- 토픽에 키 별로 마지막 값 하나만을 보존하는 로그 압착 기능을 사용함으로써 더 오랫동안 보존 가능
- 스트림 처리
- 카프카를 사용하는 거의 모든 경우가 스트림 처리임
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
