Kotlin - 함수형 프로그래밍(2): 고차 함수, 리스트 조작, Map
in DEV on Kotlin, Tointornull(), Mapnotnull(), Zip(), Zipwithnext(), Flatten(), Flatmap(), Groupby(), Associatewith(), Associateby(), Getorelse(), Getorput(), Tomutablemap(), Filter(), Filterkeys(), Filtervalues(), Map(), Mapkeys(), Mapvalues(), Any(), All(), Maxbyornull()
코틀린 여러 함수 기능에 대해 알아본다.
소스는 github 에 있습니다.
목차
개발 환경
- 언어: kotlin 1.9.23
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Gradle 8.5
1. 고차 함수 (high-order function)
람다나 다른 함수를 인자로 받거나 반환값으로 돌려주는 함수를 고차 함수라고 한다.
예를 들어 filter(), map(), any() 등이 고차 함수이다.
<고차 함수의 장점>
- 기본 함수를 조합해서 새로운 연산을 정의하거나, 다른 고차 함수를 통해 조합된 함수를 또 조합하여 더 복잡한 연산을 쉽게 정의할 수 있음
- 고차 함수로 코드를 더 간결하게 만들 수 있음
- 코드 중복을 없애고 더 나은 추상화를 구축할 수 있음
이런 식으로 고차 함수와 단순한 함수를 조합하여 코드를 작성하는 기법을 컴비네이터 패턴 (Combinator Pattern) 이라고 부르며,
컴비네이터 패턴에서 복잡한 연산을 만들기 위해 값이나 함수를 조합할 때 사용하는 고차 함수를 컴비네이터 (Combinator) 라고 한다.
1.1. 함수 타입
고차 함수를 정의하려면 함수 타입을 먼저 알아야 한다.
람다를 인자로 받은 함수를 정의하려면 먼저 람다 인자 타입을 어떻게 선언할 수 있는지 알아야 한다.
인자 타입을 정의하기 전에 람다를 로컬 변수에 저장하는 예시를 먼저 보자.
val sum = { x: Int, y: Int -> x + y }
val action = { println(1) }
위의 경우 컴파일러는 sum, action 이 함수 타입임을 추론한다.
이제 각 변수에 구체적인 타입 선언을 저장해보자. (= 람다를 참조에 저장)
// Int 파라미터를 2개 받아서 Int 값을 반환하는 함수
val sum: (Int, Int) -> Int = { x, y -> x + y }
// 아무 인자도 받지 않고 아무 값도 반환하지 않는 함수
val action: () -> Unit = { println(1) }
// 람다를 저장한 변수의 타입이 함수 타입임
val isPlus: (Int) -> Boolean = { it > 0 }
val hello: () -> String = { "Hello~" }
fun main() {
// isPlus 는 함수를 반환값으로 돌려줌
val result = listOf(1, 2, -3).any(isPlus)
println(result) // true
println(hello()) // Hello~
println(sum(1, 2)) // 3
}
함수 타입을 정의하려면 함수 파라미터의 타입을 괄호 안에 넣고, 화살표 -> 를 추가한 후 함수의 반환 타입을 지정한다.
위에서 (Int) -> Boolean, () -> Unit 등 은 함수 타입이다.
Unit 타입은 의미 있는 값을 반환하지 않는 함수 반환 타입에 사용되는 특별한 타입이다.
그냥 함수를 정의할 때는 함수의 파라미터 목록 뒤에 오는 Unit 반환 타입 지정을 생략해도 되지만, 함수 타입을 선언할 때는 반환 타입을 반드시 명시해야 하므로 Unit 을 지정해주어야 한다.
변수 타입을 함수 타입으로 지정하면 함수 타입에 있는 파라미터로부터 람다의 파라미터 타입을 유추할 수 있으므로 람다 식 안에서 굳이 파라미터 타입을 적을 필요가 없다.
// x, y 의 타입 생략
val sum: (Int, Int) -> Int = { x, y -> x + y }
1.2. 함수 인자로 람다나 함수 참조 전달
함수가 함수 파라미터를 받는 경우 인자로 람다나 함수 참조를 전달할 수 있다.
아래는 간단한 고차 함수를 정의하는 예시이다.
package com.assu.study.kotlin2me.chap08
// 함수 타입인 파라미터를 선언
fun twoAndThree(operation: (Int, Int) -> Int) {
// 함수 타입인 파라미터를 호출
val result = operation(2, 3)
println("result: $result")
}
fun main() {
// result: 5
twoAndThree { a, b -> a + b }
// result: 6
twoAndThree { a, b -> a * b }
}
아래는 표준 라이브러리인 filter() 를 직접 구현하는 예시이다.
예시의 단순성을 위해 String 에 대한 filter() 를 구현해본다.
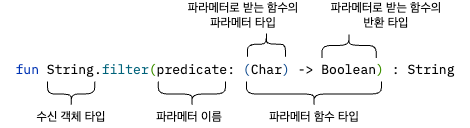
위의 filter 함수는 Predicate 를 술어로 받는다.
predicate 파라미터는 문자(Char) 를 파라미터로 받은 후 Boolean 을 반환한다.
Predicate 는 인자로 받은 문자가 filter 함수가 돌려주는 결과 문자열에 있으면 true 를 반환하고, 문자열에 없으면 false 를 반환한다.
package com.assu.study.kotlin2me.chap08
// 문자열의 각 문자를 Predicate 로 넘겨서 반환값이 true 이면 결과에 그 문자를 추가
fun String.filter(predicate: (Char) -> Boolean): String {
val sb = StringBuilder()
for (index in indices) {
val ele = get(index)
// predicate 파라미터로 전달받은 함수 호출
if (predicate(ele)) {
sb.append(ele)
}
}
return sb.toString()
}
fun main() {
// 람다를 predicate 파라미터로 전달
println("abcf".filter { it in 'a'..'z' }) // abcf
println("abcㄹ".filter { it in 'a'..'z' }) // abc
}
아래는 표준 라이브러리의 any() 를 직접 구현하는 예시이다.
// 여러 타입의 List 에 대해 호출할 수 있도록 제네릭 List<T> 타입의 확장 함수 정의
fun <T> List<T>.customAny(
customPredicate: (T) -> Boolean, // customPredicate 함수를 리스트의 원소에 적용할 수 있어야 하므로 이 함수는 파라미터 타입 T 를 인자로 받는 함수이어야 함
): Boolean {
for (ele in this) {
if (customPredicate(ele)) { // customPredicate 함수를 적용하면 선택 기준을 ele 가 만족하는지 알 수 있음
return true
}
}
return false
}
fun main() {
val ints = listOf(1, 2, 3)
val result1 = ints.customAny { it > 0 }
println(result1) // true
val strings = listOf("abc", " ")
// 함수 인자로 람다 전달
val result2 = strings.customAny { it.isBlank() }
// 함수 인자로 함수 참조 전달
val result3 = strings.customAny(String::isNotBlank)
println(result2) // true
println(result3) // true
}
아래는 repeat() 의 사용 예시이다.
fun main() {
val result = repeat(3) { println("hi") }
//hi
//hi
//hi
println(result)
}
위의 repeat() 을 직접 구현해본다.
fun customRepeat(
times: Int,
action: (Int) -> Unit, // (Int) -> Unit 타입의 함수를 action 파라미터로 받음
) {
for (index in 0 until times) {
action(index) // 현재의 반복 횟수를 index 를 사용하여 호출
}
}
fun main() {
val result = customRepeat(3, { println("#$it") })
val result2 = customRepeat(3) { println("#$it") }
// #0
// #1
// #2
println(result)
// #0
// #1
// #2
println(result2)
}
1.3. 디폴트 값을 지정한 함수 타입 파라미터
파라미터를 함수 타입으로 선언할 때도 디폴트 값을 정할 수 있다.
아래는 하드 코딩을 통해 toString() 사용 관례를 따르는 joinToString() 함수의 구현 예시이다.
package com.assu.study.kotlin2me.chap08
// Collection<T> 에 대한 확장 함수 선언
fun <T> Collection<T>.joinToString(
separator: String = ", ", // 디폴트 파라미터값들 선언
prefix: String = "",
postfix: String = "",
): String {
val result = StringBuilder(prefix)
// this 는 수신 객체를 가리킴
// 여기서는 T 타입의 원소로 이루어진 컬렉션
for ((index, ele) in this.withIndex()) {
if (index > 0) {
result.append(separator)
}
result.append(ele) // 각 원소의 분자열을 기본 toString() 메서드를 사용하여 객체를 문자열로 변환
}
result.append(postfix)
return result.toString()
}
fun main() {
val list = listOf(1, 2, 3)
// 1, 2, 3
println(list.joinToString())
// (1; 2; 3)
println(list.joinToString(separator = "; ", prefix = "(", postfix = ")"))
}
위의 구현은 유연하지만 컬렉션의 각 원소를 문자열로 변환하는 방법에 대해 제어할 수 없다는 단점이 있다.
코드는 StringBuilder.append(o: Any?) 를 사용하는데 이 함수는 객체를 항상 toString() 메서드를 통해 문자열로 바꾼다.
이런 경우 원소를 문자열로 바꾸는 방법을 람다로 전달하면 된다.
하지만 위의 joinToString() 를 호출할 때마다 매번 람다를 넘기게 되면 기본 동작으로도 충분한 대부분의 경우 함수 호출을 오히려 더 불편하게 만들 수 있으므로 람다를 전달하기보다 함수 타입의 파라미터에 대한 디폴트 값을 지정하는 것이 더 좋다.
아래는 함수 타입의 파라미터에 대한 디폴트 값으로 람다 식을 넣은 예시이다.
package com.assu.study.kotlin2me.chap08
// Collection<T> 에 대한 확장 함수 선언
fun <T> Collection<T>.joinToString2(
separator: String = ", ", // 디폴트 파라미터값들 선언
prefix: String = "",
postfix: String = "",
// 함수 타입 파라미터를 선언하면서 람다를 디폴트값으로 지정
transform: (T) -> String = { it.toString() },
): String {
val result = StringBuilder(prefix)
// this 는 수신 객체를 가리킴
// 여기서는 T 타입의 원소로 이루어진 컬렉션
for ((index, ele) in this.withIndex()) {
if (index > 0) {
result.append(separator)
}
result.append(transform(ele))
}
result.append(postfix)
return result.toString()
}
fun main() {
val list = listOf(1, 2, 3)
// 1, 2, 3
println(list.joinToString2())
// (1; 2; 3)
println(list.joinToString2(separator = "; ", prefix = "(", postfix = ")"))
val letters = listOf("Alpha", "Beta")
// 디폴트 변환 함수 사용
println(letters.joinToString2()) // Alpha, Beta
// 람다를 인자로 전달
println(letters.joinToString2 { it.lowercase() }) // alpha, beta
// 이름 붙인 인자 구문을 사용하여 람다를 포함하는 여러 인자 전달
println(letters.joinToString2(separator = "! ", postfix = "~ ", transform = { it.uppercase() })) // ALPHA! BETA~
}
위의 joinToString2() 는 제네릭 함수이다.
따라서 컬렉션의 원소 타입을 표현하는 T 를 타입 파라미터로 받고, transform 람다는 그 T 타입의 값을 인자로 받는다.
1.4. 함수의 반환 타입이 null 인 타입: toIntOrNull(), mapNotNull()
fun main() {
// 리턴값이 null 이 될 수도 있음
val trans: (String) -> Int? =
{ s: String -> s.toIntOrNull() }
val result1 = trans("123")
val result2 = trans("abc")
println(result1) // 123
println(result2) // null
val x = listOf("123", "abc")
val result3 = x.mapNotNull(trans)
val result4 = x.mapNotNull { it.toIntOrNull() }
println(result3) // [123]
println(result4) // [123]
}
toIntOrNull()- null 을 반환할 수 있음
mapNotNull()- List 의 각 원소를 null 이 될 수 있는 값으로 변환 후 변환 결과에서 null 을 제외시킴
map()을 호출하여 얻은 결과 리스트에서filterNotNull()을 호출한 것과 동일함
1.5. 반환 타입이 nullable 타입 vs 함수 전체의 타입이 nullable
다른 함수처럼 함수 타입에서도 반환 타입이 null 이 될 수 있는 타입으로 지정할 수 있다.
// 반환 타입이 null
val canReturnNull: (Int, Int) -> Int? = { x, y -> null }
함수 전체의 타입이 null 이 될 수 있는 타입 변수를 정의할 수도 있다.
// 함수 타입이 null 일 수 있음
val funOrNull: ((Int, Int) -> Int)? = null
fun main() {
// 반환 타입을 nullable 타입으로 만듦
val returnTypeNullable: (String) -> Int? = { null }
// 함수 전체의 타입을 nullable 타입으로 만듦
val mightBeNull: ((String) -> Int)? = null
val result1 = returnTypeNullable("abc")
// 컴파일 오류, Reference has a nullable type '((String) -> Int)?', use explicit '?.invoke()' to make a function-like call instead
// val result2 = mightBeNull("abc")
// if 문을 통해 명시적으로 null 검사를 한 것과 같음
// mightBeNull 에 저장된 함수를 호출하기 전에 함수 참조 자체가 null 이 아닌지 반드시 검사해야 함
val result2 = mightBeNull?.let { it("abc") }
println(result1) // null
println(result2) // null
}
null 이 될 수 있는 함수 타입으로 함수를 받으면 그 함수를 직접 호출할 수 없다.
아래처럼 null 여부를 명시적으로 검사하는 것도 방법이다.
package com.assu.study.kotlin2me.chap08
fun foo(callback: (() -> Unit)?) {
// ...
if (callback != null) {
callback()
}
}
하지만 함수 타입이 invoke() 메서드를 구현하는 인터페이스라는 점을 활용하면 위를 더 간결하게 만들 수 있다.
일반 메서드처럼 invoke() 도 안전한 호출 구문 ?. 을 사용하여 callback?.invoke() 처럼 호출할 수 있다.
package com.assu.study.kotlin2me.chap08
// Collection<T> 에 대한 확장 함수 선언
fun <T> Collection<T>.joinToString3(
separator: String = ", ", // 디폴트 파라미터값들 선언
prefix: String = "",
postfix: String = "",
// 함수 타입 파라미터를 선언하면서 람다를 디폴트값으로 지정
// null 이 될 수 있는 함수 타입의 파라미터 선언
transform: ((T) -> String)? = null,
): String {
val result = StringBuilder(prefix)
// this 는 수신 객체를 가리킴
// 여기서는 T 타입의 원소로 이루어진 컬렉션
for ((index, ele) in this.withIndex()) {
if (index > 0) {
result.append(separator)
}
// 안전한 호출을 사용하여 함수 호출
// 람다로 인자를 받지 않은 경우도 함께 처리
val str = transform?.invoke(ele) ?: ele.toString()
result.append(str)
}
result.append(postfix)
return result.toString()
}
fun main() {
val list = listOf(1, 2, 3)
// 1, 2, 3
println(list.joinToString3())
// (1; 2; 3)
println(list.joinToString3(separator = "; ", prefix = "(", postfix = ")"))
val letters = listOf("Alpha", "Beta")
// 디폴트 변환 함수 사용
println(letters.joinToString3()) // Alpha, Beta
// 람다를 인자로 전달
println(letters.joinToString3 { it.lowercase() }) // alpha, beta
// 이름 붙인 인자 구문을 사용하여 람다를 포함하는 여러 인자 전달
println(letters.joinToString3(separator = "! ", postfix = "~ ", transform = { it.uppercase() })) // ALPHA! BETA~
}
1.6. 함수를 함수에서 반환
함수가 함수를 반환하는 경우보다 함수가 함수를 인자로 받는 경우가 훨씬 더 많지만 그래도 함수를 반환하는 함수도 유용하다.
예를 들어 사용자가 선택한 배송 수단에 따라 배송비를 계산하는 방법이 달라지는 경우 적절한 로직을 선택해서 함수로 반환하는 함수를 정의하여 사용할 수 있다.
package com.assu.study.kotlin2me.chap08
enum class Delivery { STANDARD, EXPENDED }
data class Order(
val itemCount: Int,
)
// 함수를 반환하는 함수를 선언 (Order 를 받아서 Double 을 반환하는 함수를 반환)
fun getShippingCostCalculator(delivery: Delivery): (Order) -> Double {
if (delivery == Delivery.EXPENDED) {
return { order -> order.itemCount * 3.0 }
}
// 함수에서 람다를 반환
return { order -> order.itemCount * 2.0 }
}
fun main() {
// 반환받은 함수를 변수에 저장
val calculator = getShippingCostCalculator(Delivery.EXPENDED)
// 반환받은 함수 호출
// cost: 9.0
println("cost: ${calculator(Order(3))}")
}
함수를 반환하려면 return 식에 람다나 멤버 참조나 함수 타입의 값을 계산하는 식 등을 넣으면 된다.
package com.assu.study.kotlin2me.chap08
data class Person(
val firstName: String,
val lastName: String,
val phoneNumber: String?,
)
class ContactListFilters {
var prefix: String = ""
var onlyWithPhoneNumber: Boolean = false
// 함수를 반환하는 함수를 정의
fun getPredicate(): (Person) -> Boolean {
val startsWithPrefix = { p: Person ->
p.firstName.startsWith(prefix) ||
p.lastName.startsWith(prefix)
}
if (!onlyWithPhoneNumber) {
// 함수 타입의 변수 반환
return startsWithPrefix
}
// 람다 반환
return { startsWithPrefix(it) && it.phoneNumber != null }
}
}
fun main() {
val contacts =
listOf(
Person("AAA", "aaa", "123-4567"),
Person("BBB", "bbb", null),
)
val contactListFilters = ContactListFilters()
with(contactListFilters) {
prefix = "A"
onlyWithPhoneNumber = true
}
// getPredicate() 가 반환한 함수를 filter 에게 인자로 넘김
// [Person(firstName=AAA, lastName=aaa, phoneNumber=123-4567)]
println(contacts.filter(contactListFilters.getPredicate()))
}
위에서 getPredicate() 메서드는 filter() 함수에게 인자로 넘길 수 있는 함수를 반환한다.
with()영역 함수에 대한 내용은 2. 영역 함수 (Scope Function):let(),run(),with(),apply(),also()를 참고하세요.
2. 리스트 조작
zipping 과 flattening 은 List 를 조작할 때 흔히 쓰는 연산이다.
2.1. 묶기 (Zipping): zip(), zipWithNext()
zip() 은 두 List 의 원소를 하나씩 짝짓는 방식으로 묶는다.
fun main() {
val left = listOf('a', 'b', 'c', 'd')
val right = listOf('q', 'r', 's')
// left 와 right 를 zipping 하면 Pair 로 이루어진 List 가 반환됨
val result1 = left.zip(right)
// [(a, q), (b, r), (c, s)]
println(result1)
val result2 = left.zip(0..5)
// [(a, 0), (b, 1), (c, 2), (d, 3)]
println(result2)
val result3 = (10..100).zip(right)
// [(10, q), (11, r), (12, s)]
println(result3)
}
zip() 함수는 만들어진 Pair 에 대해 연산을 할 수도 있다.
data class Person(
val name: String,
val id: Int,
)
fun main() {
val names = listOf("Assu", "Silby")
val ids = listOf(777, 888)
val result1 = names.zip(ids)
// [(Assu, 777), (Silby, 888)]
println(result1)
val result2 =
// name.zip(ids) { ... } 는 name, id Pair 를 만든 후 람다를 각 Pair 에 적용
names.zip(ids) { name, id ->
Person(name, id)
}
// [Person(name=Assu, id=777), Person(name=Silby, id=888)]
println(result2)
}
한 List 에서 특정 원소와 그 원소에 인접한 다음 원소를 묶을 때는 zipWithNext() 를 사용한다.
fun main() {
val list = listOf('a', 'b', 'c', 'd')
val result1 = list.zipWithNext()
// [(a, b), (b, c), (c, d)]
println(result1)
// 원소를 zipping 한 후 연산을 추가로 적용함
val result2 = list.zipWithNext { a, b -> "$a$b" }
// [ab, bc, cd]
println(result2)
}
2.2. 평평하게 하기 (Flattening)
2.2.1. flatten()
flatten() 은 각 원소가 List 인 List 를 인자로 받아서 원소가 따로따로 들어있는 List 를 반환한다.
fun main() {
val list =
listOf(
listOf(1, 2),
listOf(3, 4),
listOf(5, 6),
)
val result = list.flatten()
// [1, 2, 3, 4, 5, 6]
println(result)
}
2.2.2. flatMap()
flatMap() 은 컬렉션에서 자주 사용되는 함수이다.
flatMap() 은 인자로 주어진 람다를 컬렉션의 모든 객체에 적용 후 람다를 적용한 결과로 얻어지는 여러 리스트를 하나의 리스트로 모으는 역할을 한다.
아래는 flatMap() 과 toSet() 을 이용하여 중복을 제거한 단일 리스트를 구하는 예시이다.
package com.assu.study.kotlin2me.chap05
data class Book(
val title: String,
val authors: List<String>,
)
fun main() {
val books = listOf(Book("A", listOf("AA")), Book("B", listOf("BB", "AA")), Book("C", listOf("CC", "BB")))
// [AA, BB, AA, CC, BB]
println(books.flatMap { it.authors })
// 컬렉션에 있는 모든 저자에 대해 중복 제거
// [AA, BB, CC]
println(books.flatMap { it.authors }.toSet())
val strings = listOf("abc", "def")
// map() 과 toList() 사용하면 문자열로 이루어진 리스트로 이루어진 리스트가 생성됨
// [[a, b, c], [d, e, f]]
println(strings.map { it.toList() })
// flatMap() 은 리스트의 리스트에 들어있던 모든 원소를 단일 리스트로 반환함
// [a, b, c, d, e, f]
println(strings.flatMap { it.toList() })
}
아래는 특정 범위에 속한 Int 로부터 가능한 모든 Pair 를 생성하는 예시이다.
fun main() {
val intRange = 1..3
// map() 은 intRange 에 속한 각 원소에 대응하는 3가지 List 의 정보를 유지
val result1 =
intRange.map { a ->
intRange.map { b -> a to b }
}
// [[(1, 1), (1, 2), (1, 3)], [(2, 1), (2, 2), (2, 3)], [(3, 1), (3, 2), (3, 3)]]
println(result1)
// flatten() 을 이용하여 결과를 펼처서 단일 List 생성
// 하지만 이런 작업을 해야 하는 경우가 빈번하므로 코틀린은 한번 호출하면 map() 과 flatten() 을 모두 수행해주는 flatMap() 이라는 합성 연산을 제공함
val result2 =
intRange.map { a ->
intRange.map { b -> a to b }
}.flatten()
// [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
println(result2)
// flatMap() 사용
val result3 =
intRange.flatMap { a ->
intRange.map { b -> a to b }
}
// [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
println(result3)
}
flatMap() 은 map() 에 flatten() 을 적용한 결과 (= 단일 List) 를 반환한다.
아래는 또 다른 예시이다.
class Book(
val title: String,
val author: List<String>,
)
fun main() {
val books =
listOf(
Book("Harry", listOf("aa", "bb")),
Book("Magic", listOf("cc", "dd")),
)
// map() 과 flatten() 사용
val result1 = books.map { it.author }.flatten()
// [aa, bb, cc, dd]
println(result1)
// flatMap() 사용
val result2 = books.flatMap { it.author }
// [aa, bb, cc, dd]
println(result2)
}
아래는 map(), flatMap() 을 사용하는 예시이다.
import kotlin.random.Random
enum class Suit {
Spade,
Club,
Hear,
Diamond,
}
enum class Rank(val faceValue: Int) {
Ace(1),
Two(2),
Three(3),
}
class Card(val rank: Rank, val suit: Suit) {
override fun toString() = "$rank of ${suit}s."
}
val deck: List<Card> =
// flatMap() 이 아닌 map() 으로 하면 아래와 같은 컴파일 오류남
// Type mismatch. Required: List<Card> Found: List<List<Card>>
// 따라서 deck 이 List<Card> 가 되기 위해서는 여기서 map() 이 아닌 flatMap() 을 사용해야 함
Suit.values().flatMap { suit ->
Rank.values().map { rank -> // map() 은 List 4개를 생성하며, 각 List 는 각 Suit 에 대응함
Card(rank, suit)
}
}
fun main() {
val rand = Random(26)
// 코틀린 Random 은 seed 가 같으면 항상 같은 난수 시퀀스를 내놓으므로 결과는 항상 동일함
// 'Three of Hears.'
// 'Ace of Diamonds.'
// 'Three of Clubs.'
// 'Two of Hears.'
// 'Ace of Diamonds.'
// 'Ace of Diamonds.'
// 'Ace of Hears.'
repeat(7) { println("'${deck.random(rand)}'") }
}
3. Map
Map 을 사용하면 key 를 사용하여 value 에 빠르게 접근할 수 있다.
3.1. groupBy()
컬렉션의 모든 원소를 어떤 특성에 따라 여러 그룹으로 나누고 싶을 때 groupBy() 를 사용하면 된다.
특성을 파라미터로 전달하면 해당 값을 key 로 갖고, List 를 value 로 갖는 Map 을 생성한다.
groupBy() 는 Map 을 생성하는 방법 중 하나이다.
groupBy() 의 파라미터는 원본 컬렉션의 원소를 분류하는 키를 반환하는 람다이다.
원본 컬렉션의 각 원소에 이 람다를 적용하여 key 값을 얻은 후 Map 에 넣어준다.
이 때 key 가 같은 값이 둘 이상 있을 수 있으므로 Map 의 value 는 원본 컬렉션의 원소 중 key 에 해당하는 값의 List 가 되어야 한다.
package com.assu.study.kotlin2me.chap05
data class Person9(
val name: String,
val age: Int,
)
fun main() {
val persons = listOf(Person9("assu", 20), Person9("silby", 2), Person9("ajaehun", 20))
// 나이별로 구분
// {20=[Person9(name=assu, age=20), Person9(name=ajaehun, age=20)], 2=[Person9(name=silby, age=2)]}
println(persons.groupBy { it.age })
// 멤버 참조인 :: 를 이용하여 첫 글자에 따라 분류
val list = listOf("a", "ab", "b")
// {a=[a, ab], b=[b]}
println(list.groupBy(String::first))
}
data class Person(
val name: String,
val age: Int,
)
val names = listOf("Assu", "Sibly", "JaeHoon")
val ages = listOf(20, 2, 20)
fun people(): List<Person> = names.zip(ages) { name, age -> Person(name, age) }
fun main() {
// groupBy() 로 Map 생성
val map: Map<Int, List<Person>> =
people().groupBy(Person::age)
// {20=[Person(name=Assu, age=20), Person(name=JaeHoon, age=20)], 2=[Person(name=Sibly, age=2)]}
println(map)
// [Person(name=Assu, age=20), Person(name=JaeHoon, age=20)]
println(map[20])
// null
println(map[9])
}
3.2. associateWith(), associateBy()
List 에 associateWith() 를 사용하면 List 원소를 key 로 하고, associateWith() 에 전달된 함수 (혹은 람다) 를 List 에 원소에 적용한 반환값을 value 로 하는 Map 을 생성한다.
associateBy() 는 associateWith() 가 생성하는 연관 관계를 반대 방향으로 하여 Map 을 생성한다.
즉, 셀렉터가 반환한 값이 key 가 된다.
associateBy() 의 셀렉터는 유일한 key 값을 만들어 내야 한다.
만일 key 값이 유일하지 않으면 원본값 중 일부가 사라진다.
만일 key 값이 유일하지 않으면 같은 key 를 가진 value 중 컬렉션에서 맨 나중에 나타나는 원소가 Map 에 포함된다.
data class Person1(
val name: String,
val age: Int,
)
val names1 = listOf("Assu", "Sibly", "JaeHoon")
val ages1 = listOf(20, 2, 20)
fun people1(): List<Person1> = names1.zip(ages1) { name, age -> Person1(name, age) }
fun main() {
// [Person1(name=Assu, age=20), Person1(name=Sibly, age=2), Person1(name=JaeHoon, age=20)]
println(people1())
// associateWith() 사용
val map: Map<Person1, String> = people1().associateWith { it.name }
// {Person1(name=Assu, age=20)=Assu, Person1(name=Sibly, age=2)=Sibly, Person1(name=JaeHoon, age=20)=JaeHoon}
println(map)
// associateBy() 사용, key 값이 유일함
val map2: Map<String, Person1> = people1().associateBy { it.name }
// {Assu=Person1(name=Assu, age=20), Sibly=Person1(name=Sibly, age=2), JaeHoon=Person1(name=JaeHoon, age=20)}
println(map2)
// associateBy() 사용, key 값이 중복되서 원본이 사라짐
val map3: Map<Int, Person1> = people1().associateBy { it.age }
// {20=Person1(name=JaeHoon, age=20), 2=Person1(name=Sibly, age=2)}
println(map3)
}
3.3. getOrElse(), getOrPut(), toMutableMap()
getOrElse() 는 Map 에서 value 를 찾는다.
key 가 없을 때 디폴트 value 를 계산하는 방법이 담긴 람다를 인자로 받는데, 이 파라미터가 람다이기 때문에 필요할 때만 디폴트 value 를 계산할 수 있다.
getOrPut() 은 MutableMap 에만 적용 가능하다.
getOrPut() 은 key 가 있으면 연관된 value 를 반환하고, key 가 없으면 value 를 계산한 후 그 value 를 key 와 연관시켜서 Map 에 저장한 후, 저장한 value 를 반환한다.
fun main() {
val map = mapOf(1 to "one", 2 to "two")
val result1 = map.getOrElse(0) { "zero" }
val result2 = map.getOrElse(1) { "zero" }
println(result1) // zero
println(result2) // one
// immutableMap 을 mutableMap 으로 변환
val mutableMap = map.toMutableMap()
// 0 이라는 key 가 없으므로 Map 에 {0=zero} 추가 후 zero 라는 value 반환
var result3 = mutableMap.getOrPut(0) { "zero" }
// 1 이라는 key 가 있으므로 1에 해당하는 value 인 one 반환
var result4 = mutableMap.getOrPut(1) { "zero" }
println(result3) // zero
println(result4) // one
println(mutableMap) // {1=one, 2=two, 0=zero}
}
3.4. filter(), filterKeys(), filterValues(), maxBy()
filter() 와 map() 은 컬렉션을 활용할 때 기반이 되는 함수이다.
filter() 는 컬렉션을 이터레이션하면서 주어진 람다에 각 원소를 넘겨서 람다가 true 를 반환하는 원소만 모아서 새로운 컬렉션을 만든다.
map() 은 주어진 람다를 컬렉션의 각 원소에 적용한 결과를 모아서 새로운 컬렉션을 만든다.
Map 의 여러 연산은 List 가 제공하는 연산과 겹친다.
fun main() {
val list = listOf(1,2,3,4)
// filter() 사용
// 짝수만 남음
val even = list.filter { it % 2 == 0 }
// [2,4]
println(even)
}
maxBy() 를 이용하여 나이가 가장 많은 사람의 정보 구하는 예시
package com.assu.study.kotlin2me.chap05
data class Person4(
val name: String,
val age: Int,
)
fun main() {
val persons = listOf(Person4("assu", 20), Person4("silby", 2))
// 목록에서 가장 나이가 많은 사람의 정보 구하기
// 아래 방법은 최대값을 구하는 작업을 계속 반복함 (100 명이 있다면 100번의 최대값 연산 수행)
val order = persons.filter { it.age == persons.maxBy(Person4::age).age }
// [Person4(name=assu, age=20)]
println(order)
// 최대값을 한번만 계산해서 나이가 가장 많은 사람의 정보 구하기
val maxAge = persons.maxBy(Person4::age).age
var order2 = persons.filter { it.age == maxAge }
// [Person4(name=assu, age=20)]
println(order2)
}
fun main() {
val map = mapOf(1 to "one", 2 to "two", 3 to "three", 4 to "four")
// filterKeys() 사용
val result1 = map.filterKeys { it % 2 == 1 }
// {1=one, 3=three}
println(result1)
// filterValues() 사용
val result2 = map.filterValues { it.contains('o') }
// {1=one, 2=two, 4=four}
println(result2)
// Map 에 filter() 사용
val result3 =
map.filter { entry ->
entry.key % 2 == 1 && entry.value.contains('o')
}
// {1=one}
println(result3)
}
3.5. map(), mapKeys(), mapValues()
Map 에 map() 을 적용한다는 말은 동어 반복인 듯 하지만 ‘map’ 은 두 가지를 뜻한다.
- 컬렉션 변환
- key-value 쌍을 저장하는 데이터 구조
map() 의 기본적인 사용
package com.assu.study.kotlin2me.chap05
data class Person3(val name: String, val age: Int)
fun main() {
val list = listOf(1,2,3,4)
// map() 을 이용하여 각 원소에 곱하기 2
val multiple = list.map { it * 2 }
// [2,4,6,8]
println(multiple)
// map() 을 이용하여 이름만 출력
val persons = listOf(Person3("assu", 20), Person3("silby", 2))
val names = persons.map { it.name }
// [assu, silby]
println(names)
// filter() 와 map() 을 이용하여 10살 이상인 사람의 이름만 출력
val tens = persons.filter { it.age >= 10 }.map(Person3::name)
// [assu]
println(tens)
}
mapValues() 를 이용하여 value 값 변환
package com.assu.study.kotlin2me.chap05
fun main() {
// mapValues() 을 이용하여 value 를 대문자로 변환
val numbers = mapOf(0 to "zero", 1 to "one")
// {0=ZERO, 1=ONE}
println(numbers.mapValues { it.value.uppercase() })
}
fun main() {
val even = mapOf(2 to "two", 4 to "four")
// map() 사용, List 반환
// map() 은 Map.Entry 인자를 받는 람다를 파라미터로 받음
// Map.Entry 의 내용을 it.key, it.value 로 접근 가능
val result1 = even.map { "${it.key}=${it.value}" }
// [2=two, 4=four]
println(result1)
// 구조 분해 사용
val result2 = even.map { (key1, value1) -> "$key1=$value1" }
// [2=two, 4=four]
println(result2)
// 파라미터를 사용하지 않을 때는 밑줄을 사용하여 컴파일러 경고를 막음
// mayKeys(), mapValues() 는 모든 key 나 value 가 변환된 새로운 Map 을 반환함
val result3 =
even.mapKeys { (num, _) -> -num }
.mapValues { (_, str) -> "minus $str" }
// {-2=minus two, -4=minus four}
println(result3)
// map() 사용
// map() 은 List 를 반환하므로 새로운 Map 을 생성하려면 명시적으로 toMap() 을 호출해야 함
val result4 =
even.map { (key, value) -> -key to "minus $value" }
.toMap()
// {-2=minus two, -4=minus four}
println(result4)
}
3.6. any(), all(), maxByOrNull()
any()- Map 의 원소 중 주어진 Predicate 를 만족하는 원소가 하나라도 있으면 true 반환
all()- Map 의 모든 원소가 Predicate 를 만족해야 true 반환
maxByOrNull()- 주어진 Predicate 에 따라 가장 큰 원소를 반환
- 가장 큰 원소가 없으면 null 반환
fun main() {
val map = mapOf(1 to "one", -2 to "minus two")
val result1 = map.any { (key, _) -> key < 0 }
val result2 = map.all { (key, _) -> key < 0 }
val result3 = map.maxByOrNull { it.key }?.value
println(result1) // true
println(result2) // false
println(result3) // one
}
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 브루스 에켈, 스베트라아 이사코바 저자의 아토믹 코틀린 과 드리트리 제메로프, 스베트라나 이사코바 저자의 Kotlin In Action 을 기반으로 스터디하며 정리한 내용들입니다.
- 아토믹 코틀린
- 아토믹 코틀린 예제 코드
- Kotlin In Action
- Kotlin In Action 예제 코드
- Kotlin Github
- 코틀린 doc
- 코틀린 lib doc
- 코틀린 스타일 가이드
