Kotlin - 함수형 프로그래밍(3): Sequence, Local 함수, 확장 함수, 익명 함수, fold(), 재귀
in DEV on Kotlin Sequence As-sequence() Substring-before() Generate-sequence() Take() Take-if() Local-function Label Fold() Reduce Running-fold() Recursion Tail-recursion Tailrec
코틀린 여러 함수 기능에 대해 알아본다.
소스는 github 에 있습니다.
개발 환경
- 언어: kotlin 1.9.23
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Gradle 8.5
1. 시퀀스 (Sequence): constrainOnce()
코틀린의 Sequence 는 List 와 비슷하지만, Sequence 를 대상으로 해서는 이터레이션만 수행할 수 있다. 즉, 인덱스를 써서 Sequence 의 원소에 접근할 수는 없다.
코틀린의 Sequence 를 다른 함수형 언어에서는 Stream 이라고 한다.
Java8 의 Stream 라이브러리와 호환성을 유지하기 위해 코틀린은 Sequence 라고 이름을 정함
Sequence 는 한 번만 이터레이션이 가능하기 때문에 Sequence 를 여러 번 처리하고 싶다면 Sequence 를 먼저 Collection 타입 중 하나로 변환해야 한다.
사용 중인 Sequence 종류에 따라 반복 이터레이션이 가능한 경우도 있지만, 반복 이터레이션을 사용하는 시퀀스의 경우 처음부터 모든 연산을 다시 실행할 가능성이 있으므로 반복 계산을 피하기 위해서는 Sequence 를 Collection 으로 변환하여 저장해두어야 한다.
Sequence 에 대해 constrainOnce() 를 호출하면 단 한번만 이터레이션을 허용하는 Sequence 을 얻을 수 있다.
constrainOnce() 는 Sequence 를 두 번 순회하는 로직의 오류를 방지하기 위해 사용한다.
1.1. 즉시 계산(수평적 평가) vs 지연 계산(수직적 평가): asSequence()
List 에 대한 연산은 즉시 계산된다. 함수를 호출하자마자 모든 원소에 대해 바로 계산이 이루어진다.
List 연산을 연쇄시키면 첫 번째 연산의 결과가 나온 후에야 다음 연산을 적용할 수 있다.
즉, 컬렉션 함수를 연쇄하면 매 단계마다 계산 중간 결과를 새로운 컬렉션에 임시로 담는다는 말이다.
asSequence() 를 사용하면 중간 임시 컬렉션을 사용하지 않고도 컬렉션 연산을 연쇄할 수 있다.
List 에 filter(), map(), any() 연산을 적용시킨 예시를 보자.
fun main() {
val list = listOf(1, 2, 3, 4)
// List 에 filter(), map(), any() 를 연쇄 적용함
val result =
list.filter { it % 2 == 0 }
.map { it * it }
.any { it < 10 }
println(result) // true
// 위의 연쇄 적용한 것은 아래와 같음
val mid1 = list.filter { it % 2 == 0 }
println(mid1) // [2, 4]
val mid2 = mid1.map { it * it }
println(mid2) // [4, 16]
val mid3 = mid2.any { it < 10 }
println(mid3) // true
}
즉시 계산은 직관적이고 단순하지만 최적은 아니다.
any() 를 만족하는 첫 번째 원소를 만나서 적용한 뒤 연쇄적인 연산을 멈출 수 있다면 좀 더 최적화될 것이다.
따라서 Sequence 가 길 때는 모든 원소에 대해 연산을 적용한 다음 일치하는 원소를 하나 찾아내는 것은 비효율적이다.
이러한 즉시 계산을 수평적 평가라고 한다.
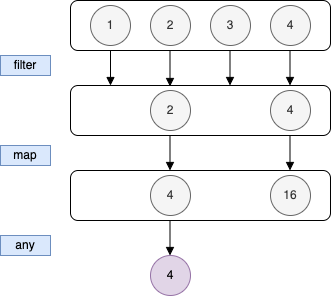
위 그림을 보면 다음 연산을 수행하기 전에 이전의 연산이 처리되어야 한다.
이러한 즉시 계산의 대안은 지연 계산인데 이를 수직적 평가라고도 한다.
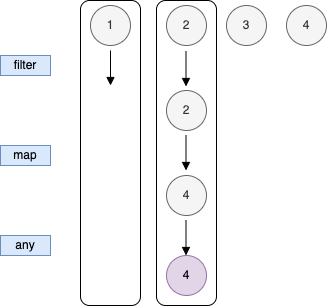
지연 계산을 사용하면 원본 컬렉션의 마지막 원소를 처리하기 전에 최종 결과를 찾아내면 나머지 원소는 처리되지 않는다.
(= 어떤 원소와 연관된 값이 진짜 필요할 때만 그 원소와 관련된 연산을 수행함)
Sequence 는 (중간) 연산을 저장해두기 때문에 각 연산을 원하는 순서로 호출할 수 있고, 그에 따라 지연 계산이 발생하는 원리이다.
List 에 asSequence() 를 사용하여 Sequence 로 변경하면 지연 계산이 활성화되고, 인덱싱을 제외한 모든 List 연산을 Sequence 에도 사용할 수 있다.
아래는 동일한 연산을 List 와 Sequence 를 사용하여 비교하는 예시이다.
fun Int.isEven(): Boolean {
println("$this - isEven(): $this%2")
return this % 2 == 0
}
fun Int.square(): Int {
println("$this - square(): $this*$this")
return this * this
}
fun Int.lessThenTen(): Boolean {
println("$this - lessThenTen(): $this<10")
return this < 10
}
fun main() {
val list = listOf(1, 2, 3, 4)
// List 를 이용하여 filter(), map(), any() 사용
list.filter(Int::isEven)
.map(Int::square)
.any(Int::lessThenTen)
// 1 - isEven(): 1%2
// 2 - isEven(): 2%2
// 3 - isEven(): 3%2
// 4 - isEven(): 4%2
// 2 - square(): 2*2
// 4 - square(): 4*4
// 4 - lessThenTen(): 4<10
// Sequence 를 이용하여 filter(), map(), any() 사용
list.asSequence()
.filter(Int::isEven)
.map(Int::square)
.any(Int::lessThenTen)
// 1 - isEven(): 1%2
// 2 - isEven(): 2%2
// 2 - square(): 2*2
// 4 - lessThenTen(): 4<10
}
List 보다 Sequence 를 사용한 쪽이 훨씬 적은 원소에 대해 연산을 수행한 것을 알 수 있다.
원본 리스트에 원소 갯수가 적다면 큰 문제가 되지 않지만, 원소가 수백만개가 되면 Sequence 보다 List 연산은 훨씬 효율이 떨어지게 된다.
따라서 이를 효율적으로 하기 위해선 각 연산이 컬렉션을 직접 사용하는 대신 Sequence 를 사용하게 만들어야 한다.
크기가 큰 컬렉션에 대해서 연산을 연쇄할 때는 Sequence 를 사용하는 것을 규칙으로 삼는 것이 좋다.
컬렉션에 들어있는 원소가 많으면 중간 원소를 재배열하는 비용이 커지기 때문에 Sequence 를 사용하여 지연 계산을 사용하는 것이 좋다.
1.3. 컬렉션 연산 인라이닝 과 함께 보면 도움이 됩니다.
중간 컬렉션을 생성함에도 불구하고 즉시 계산 컬렉션에 대한 연산이 더 효율적인 경우가 있는데 1.3. 컬렉션 연산 인라이닝 을 참고하세요.
1.2. 중간 연산(intermediate), 최종 연산(terminal): substringBefore()
Sequence 연산에는 중간 연산과 최종 연산이 있다.
- 중간 연산
- 결과로 다른 Sequence 를 반환
filter(),map()은 중간 연산
- 최종 연산
- 결과로 Sequence 가 아닌 “값”을 반환
- 결과값을 얻기 위해 최종 연산은 저장된 모든 계산을 수행함
toList()는 최종 연산
중간 연산은 항상 지연 계산된다.
최종 연산을 호출하면 연기되었던 모든 계산이 수행된다.
filter(), map() 을 Sequence 에 대해 호출하면 다른 Sequence 가 생기고, 계산 결과를 요청할 때까지는 아무런 일도 발생하지 않는다.
새 Sequence 는 지연된 모든 연산에 대한 정보를 저장해두고 필요할 때만 저장해 둔 연산을 실행한다.
fun Int.isEven2(): Boolean {
println("$this - isEven2(): $this%2")
return this % 2 == 0
}
fun Int.square2(): Int {
println("$this - square2(): $this*$this")
return this * this
}
fun main() {
val r =
listOf(1, 2, 3, 4)
.asSequence()
.filter(Int::isEven2)
.map(Int::square2)
// r 을 String 으로 변환해도 최종 결과는 나오지 않음
// 객체의 식별자만 나옴
println(r) // kotlin.sequences.TransformingSequence@42110406
// 객체의 식별자를 제거해서 보기 위해 내부 객체의 메모리 주소를 표현하는 @를 자르고 봄
println(r.toString().substringBefore("@")) // kotlin.sequences.TransformingSequence
}
위에서의 TransformingSequence 은 연산을 저장만 할 뿐 수행하지는 않는다.
아래는 toList() 최종 연산을 사용하여 시퀀스를 처리하는 과정에서 저장된 모든 연산을 실행하는 예시이다.
fun Int.isEven3(): Boolean {
println("$this - isEven3(): $this%2")
return this % 2 == 0
}
fun Int.square3(): Int {
println("$this - square3(): $this*$this")
return this * this
}
fun main() {
val list = listOf(1, 2, 3, 4)
println(
list.asSequence()
.filter(Int::isEven3)
.map(Int::square3)
.toList(),
)
// 1 - isEven3(): 1%2
// 2 - isEven3(): 2%2
// 2 - square3(): 2*2
// 3 - isEven3(): 3%2
// 4 - isEven3(): 4%2
// 4 - square3(): 4*4
// [4, 16]
}
컬렉션에 대해 수행하는 연산의 순서도 성능에 영향을 미친다.
아래는 filter(), map() 을 각각 순서를 바꿔서 실행했을 때의 예시이다.
package com.assu.study.kotlin2me.chap05
data class Person10(
val name: String,
val age: Int,
)
fun main() {
val persons = listOf(Person10("assu", 20), Person10("silby", 2), Person10("jaehun", 22))
// map() -> filter()
// 모든 원소에 대해 이름을 가져온 후 길이 필터
// [assu]
println(
persons
.asSequence()
.map(Person10::name)
.filter { it.length < 5 }
.toList(),
)
// filter() -> map()
// 이름 길이를 먼저 필터한 후 필터된 원소에 대해 이름을 가져오므로 변환되는 크기의 개수가 다름
// [assu]
println(
persons
.asSequence()
.filter { it.name.length < 5 }
.map(Person10::name)
.toList(),
)
}
1.3. generateSequence(), take(), removeAt(), takeIf(), takeWhile()
generateSequence() 는 자연수로 이루어진 무한 시퀀스를 생성한다.
generateSequence() 의 첫 번째 인자는 시퀀스의 첫 번째 원소이고, 두 번째 인자는 이전 원소로부터 다음 원소를 만들어내는 방법을 정의하는 람다이다.
만일 람다가 null 을 반환하면 시퀀스는 종료된다.
fun main() {
val naturalNumbers = generateSequence(1) { it + 1 }
// take() 를 통해 원하는 개수만큼 얻은 후 최종 연산 (toList(), sum()) 수행
val result1 = naturalNumbers.take(3).toList()
val result2 = naturalNumbers.take(3).sum()
println(result1) // [1, 2, 3]
println(result2) // 6
}
아래는 0~100 까지의 자연수의 합을 구하는 예시이다.
package com.assu.study.kotlin2me.chap05
fun main() {
// 0~100 까지의 자연수의 합
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it <= 100 }
// 5050
println(numbersTo100.sum())
}
Collection 은 size 프로퍼티를 통해 미리 크기를 알 수 있지만, Sequence 는 무한이므로 take() 를 통해 원하는 개수만큼 원소를 얻은 후 최종 연산을 수행한다.
시퀀스의 첫 번째 원소인 첫 번째 인자를 요구하지 않고 Sequence 의 다음 원소를 반환하는 람다만 받는 generateSequence() 오버로딩 버전도 있다.
람다는 더 이상 원소가 없으면 null 을 반환한다.
아래는 END 가 나타날때까지 Sequence 원소를 생성하는 예시이다.
fun main() {
val list = mutableListOf("aaa", "bbb", "END", "ccc")
// removeAt(0) 은 List 의 첫 번째 원소를 제거한 후 제거한 원소를 반환함
// takeIf() 는 수신 객체(removeAt(0) 이 반환한 String) 가 Predicate 를 만족하면 수신 객체를 반환하고,
// 만족하지 않으면 null 반환
val seq = generateSequence { list.removeAt(0).takeIf { it != "END" } }
println(seq) // kotlin.sequences.ConstrainedOnceSequence@2e0fa5d3
println(seq.toList()) // [aaa, bbb]
}
상위 디렉터리를 뒤지면서 숨김 속성을 가진 디렉터리가 있는지 검사하는 예시 코드
package com.assu.study.kotlin2me.chap05
import java.io.File
// 상위 디렉터리를 뒤지면서 숨김 속성을 가진 디렉터리가 있는지 검사
// any() 를 find() 로 변경하면 원하는 디렉터리를 찾을 수 있음
// 이렇게 시퀀스를 사용하면 조건을 만족하는 디렉터리를 찾은 뒤에는 더 이상 상위 디렉터리를 뒤지지 않음
fun File.isInsideHiddenDir() = generateSequence(this) { it.parentFile }.any { it.isHidden }
fun main() {
val file = File("/Users/assu/.HiddenDir/a.txt")
// true
println(file.isInsideHiddenDir())
}
1.4. 제네릭 takeIf() 구현
아래는 타입 파라미터 T 를 사용하여 임의의 타입에 적용할 수 있는 제네릭 takeIf() 의 구현이다.
fun <T> T.takeIf(predicate: (T) -> Boolean): T? {
return if (predicate(this)) this else null
}
fun main() {
println("aaa".takeIf { it != "bbb" }) // aaa
println("aaa".takeIf { it != "aaa" }) // null
}
감소하는 수열 생성
fun main() {
// 감소하는 수열 생성
val seq = generateSequence(5) { (it - 1).takeIf { it > 0 } }.toList()
println(seq) // [5, 4, 3, 2, 1]
}
takeIf() 대신 if 문을 사용할 수도 있지만 식별자가 추가로 필요하기 때문에 takeIf() 가 가독성이 더 좋다.
또한 takeIf() 가 좀 더 함수형 표현이며, 호출 연쇄 중간에 자연스럽게 사용할 수 있다.
2. Local 함수
다른 함수 안에 정의된 이름 붙은 함수를 Local 함수라고 한다.
반복되는 코드를 Local 함수로 추출하여 코드의 중복을 줄일 수 있다.
아래는 main() 안에 내포되어 있는 log() 의 예시이다.
fun main() {
val logMsg = StringBuilder()
// main() 안에 내포되어 있는 log()
fun log(message: String) = logMsg.appendLine(message)
log("Starting~")
val x = 11
log("Compute result: $x")
// Starting~
// Compute result: 11
println(logMsg.toString())
}
Local 함수는 Closure 이다.
따라서 Local 함수는 자신을 둘러싼 환경의 var, val 를 capture 한다.
위의 예시에서는 log() 가 자신의 외부 환경의 logMsg 를 사용한다. 이러면 log() 를 호출할 때마다 반복적으로 logMsg 를 전달하지 않아도 된다.
2.1. Local 확장 함수
fun main() {
// main() 안에 있는 Local 확장 함수
// 이 Local 확장 함수는 main() 안에서만 사용 가능
fun String.exclaim() = "$this!"
println("Hi".exclaim())
}
2.2. 함수 참조를 사용하여 Local 함수 참조
아래는 Local 함수에 대한 설명 시 계속 사용할 클래스이다.
class Session(
val title: String,
val speaker: String,
)
val sessions = listOf(Session("Happy", "Assu"))
val favoriteSpeakers = setOf("Assu")
아래는 함수 참조를 사용하여 Local 함수를 참조하는 예시이다.
fun main() {
fun interesting(session: Session): Boolean {
return session.title.contains("Hap") && session.speaker in favoriteSpeakers
}
// 함수 참조를 사용하여 Local 함수 참조
println(sessions.any(::interesting)) // true
}
::interesting 구문에 대한 설명은 3.2. 함수 참조 를 참고하세요.
2.3. 익명 함수 (Anonymous Function, 무명 함수)
2.2. 함수 참조를 사용하여 Local 함수 참조 코드를 보면 interesting() 은 한번만 사용되기 때문에 함수가 아닌 람다로 정의하는 게 나을 것 같지만, interesting() 안에 사용된 return 식 때문에 이 함수를 람다로 정의하기 어렵다.
익명 함수에 대한 좀 더 자세한 설명은 1.10.3. 무명 함수(Anonymous Function): 기본적으로 로컬
return을 참고하세요.
이럴 땐 익명 함수를 사용하는 것이 좋다.
익명 함수는 람다처럼 이름이 없다.
익명 함수는 Local 함수와 비슷하지만 fun 키워드를 사용하여 정의한다.
아래는 위의 코드를 익명 함수로 재작성한 예시이다.
fun main() {
// Local 함수를 익명 함수로 변경
val result =
sessions.any(
fun(session: Session): Boolean { // 익명 함수는 이름이 없는 함수처럼 보임, 이 익명 함수를 sessions.any() 의 인자로 전달
return session.title.contains("Hap") && session.speaker in favoriteSpeakers
},
)
println(result) // true
}
람다가 너무 복잡해서 가독성이 떨어진다면 Local 함수나 익명 함수로 대신하는 것이 좋다.
2.4. Label (레이블)
아래는 return 을 포함하는 람다에 대해 적용한 forEach() 이다.
fun main() {
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
list.forEach {
// return 을 포함하는 람다
result += it
if (it == value) {
return // main() 을 끝낸다는 의미
}
}
println(result) // 위에서 main() 을 끝내기 때문에 아무런 출력이 되지 않음
}
return 은 fun 을 사용해 정의한 함수(따라서 람다는 제외됨)를 끝내기 때문에 위 코드에서는 return 을 만나게 되면 main() 이 끝난다.
람다안에서의 return
코틀린 람다 안에서는 return 을 쓸 수 없지만 인라인 함수가 람다를 인자로 받는 경우 해당 람다도 함께 인라인하게 되어 있으며, 이 때 함께 인라인되는 람다 안에서 return 을 쓸 수 있도록 허용한다.
인라인을 사용하면
forEach()함수와 그 함수에 전달된 람다의 본문은 모두forEach()를 호출한 위치 (위에서는 main()) 에 소스 코드를 복사한 것과 같이 컴파일이 된다.
따라서 람다 안에서 return 을 써도 컴파일된 코드에서는 main() 함수 본문 안에 쓴 return 과 구분되지 않아서 똑같이 main() 이 반환된다.
따라서 람다를 둘러싼 함수가 아니라 람다에서만 반환해야 한다면 Label 이 붙은 return 을 사용한다.
fun main() {
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
list.forEach {
// return 을 포함하는 람다
result += it
if (it == value) {
return@forEach // 레이블이 붙은 return
}
}
println(result) // 12345
}
위 코드에서 Label 은 람다를 호출한 함수 이름이다.
return@forEach 라는 Label 이 붙은 return 문은 람다를 Label 인 forEach 까지만 반환시키라고 지정한다.
람다 앞에 레이블@ 을 넣으면 새 Label 을 만들 수 있으며, Label 이름은 아무 이름이나 사용 가능하다.
fun main() {
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
// 람다 앞에 커스텀 레이블을 붙임
list.forEach customTag@{
result += it
println("$it, $value, $result")
if (it == value) {
println("haha")
return@customTag // main() 이 아닌 람다를 반환함
}
}
// 1, 3, 1
// 2, 3, 12
// 3, 3, 123
// haha
// 4, 3, 1234
// 5, 3, 12345
// 12345
println(result)
}
2.3. 익명 함수 (Anonymous Function, 무명 함수) 에서 익명 함수를 람다로 바꾸면 아래와 같다.
익명 함수일 때
fun main() {
// Local 함수를 익명 함수로 변경
val result =
sessions.any(
fun(session: Session): Boolean { // 익명 함수는 이름이 없는 함수처럼 보임, 이 익명 함수를 sessions.any() 의 인자로 전달
return session.title.contains("Hap") && session.speaker in favoriteSpeakers
},
)
println(result) // true
}
익명 함수를 람다로 했을 때
fun main() {
val result =
sessions.any { session ->
// 람다가 main() 을 반환시키면 안되므로 반드시 Label 을 붙여서 람다만 반환시켜야 함
return@any session.title.contains("Hap") && session.speaker in favoriteSpeakers
}
println(result) // true
}
2.5. Local 함수 조작
var, val 를 사용하여 람다나 익명 함수를 저장할 수 있고, 람다를 가리키게 된 식별자를 사용하여 해당 함수를 호출할 수 있다.
아래는 익명 함수, 람다, 지역함수에 대한 참조에 대한 예시이다.
// 익명 함수 반환
fun first(): (Int) -> Int {
val func = fun(i: Int) = i + 1
return func
}
// 람다 반환
fun second(): (String) -> String {
val func2 = { s: String -> "$s!!" }
return func2
}
// Local 함수에 대한 참조 반환
fun third(): () -> String {
fun func3() = "Hi!"
return ::func3
}
// third() 와 같은 효과를 내지만 식 본문을 써서 더 간결하게 표현
fun forth() = fun() = "Hi!"
// 람다를 식 본문 함수에 사용하여 같은 효과를 냄
fun fifth() = { "Hi!" }
fun main() {
val funRef1: (Int) -> Int = first()
val funRef2: (String) -> String = second()
val funRef3: () -> String = third()
val funRef4: () -> String = forth()
val funRef5: () -> String = fifth()
println(funRef1(11)) // 12
println(funRef2("aaa")) // aaa!!
println(funRef3()) // Hi!
println(funRef4()) // Hi!
println(funRef5()) // Hi!
println(first()) // (kotlin.Int) -> kotlin.Int
println(first()(22)) // 23
println(second()) // (kotlin.String) -> kotlin.String
println(second()("bbb")) // bbb!!
// 컴파일 오류
// Function 'func3' (JVM signature: third$func3()Ljava/lang/String;) not resolved in class kotlin.jvm.internal.Intrinsics$Kotlin: no members found
// println(third())
println(third()()) // Hi!
println(forth()) // () -> kotlin.String
println(forth()()) // Hi!
println(fifth()) // () -> kotlin.String
println(fifth()()) // Hi!
}
main() 은 각 함수가 원하는 타입의 함수에 대한 참조를 반환하는지 검증 후 적절한 인자를 사용하여 각 funRef 를 호출한다.
각 함수를 호출하여 반환되는 함수 참조 뒤에 인자 목록을 붙이는 방식으로 함수를 호출한다.
위에서 first() 를 호출하면 함수가 반환되기 때문에 뒤에 인자 목록인 (22) 를 추가하여 반환된 함수를 호출한다.
3. fold()
fold() 는 리스트의 모든 원소를 순서대로 조합하여 결과값을 하나로 만들어낸다.
sum(), reverse() 등도 fold() 를 통해 구현하는 것이다.
아래는 fold() 를 사용하여 Collection 의 합계를 구하는 예시이다.
fun main() {
val list = listOf(1, 2, 3)
val result = list.fold(0) { acc, i -> acc + i }
println(result) // 6
}
fold() 는 첫 번째 인자로 초기값을 받고, 두 번째 인자로는 지금까지 누적된 값과 현재 원소에 대한 연산을 연속적으로 적용시킨다.
fold() 를 for 문으로 구현하면 아래와 같다.
fun main() {
val list = listOf(1, 2, 3)
var acc = 0
var operation = { sum: Int, i: Int -> sum + i }
for (i in list) {
acc = operation(acc, i)
}
println(acc) // 6
}
3.1. fold() vs foldRight()
fold() 는 원소를 왼쪽에서 오른쪽으로 처리하고, foldRight() 는 오른쪽에서 왼쪽으로 처리한다.
이 둘 함수에 전달되는 람다에서 누적값이 전달되는 위치도 다르다.
fun main() {
var list = listOf('a', 'b', 'c', 'd')
// fold() 사용
val result = list.fold("*") { acc, ele -> "($acc) + $ele" }
// ((((*) + a) + b) + c) + d
println(result)
// foldRight() 사용
val result1 = list.foldRight("*") { elem, acc -> "($acc) + $elem" }
// ((((*) + d) + c) + b) + a
println(result1)
}
위 코드를 보면 fold() 는 “a” 를 처음으로 연산에 적용하고, foldRight() 는 “d” 를 처음으로 연산에 적용하는 것을 알 수 있다.
3.2. reduce(), reduceRight()
fold() 와 foldRight() 는 첫 번째 파라미터를 통해 명시적으로 누적값을 받는다.
하지만 첫 번째 원소가 누적값의 초기값이 될 수 있는 경우도 있는데 reduce() 와 reduceRight() 는 각각 첫 번째 원소와 마지막 원소를 초기값으로 사용한다.
fun main() {
val chars = "a b c d e".split(" ")
// fold() 사용
val result1 = chars.fold("*") { acc, e -> "$acc, $e" }
// *, a, b, c, d, e
println(result1)
// foldRight() 사용
val result2 = chars.foldRight("*") { e, acc -> "$acc, $e" }
// *, e, d, c, b, a
println(result2)
// reduce() 사용
val result3 = chars.reduce { acc, e -> "$acc, $e" }
// a, b, c, d, e
println(result3)
// reduceRight() 사용
val result4 = chars.reduceRight { e, acc -> "$acc, $e" }
// e, d, c, b, a
println(result4)
}
3.3. runningFold(), runningReduce()
runningFold() 와 runningReduce() 는 이 과정에서 계산되는 모든 중간 단계 값을 포함하는 List 를 생성한다.
결과 List 의 마지막 값은 fold() 와 reduce() 의 결과값과 동일하다.
fun main() {
val list = listOf(11, 13, 17, 19)
// fold() 사용
val result1 = list.fold(7) { acc, n -> acc + n }
println(result1) // 67
// runningFold() 사용
val result2 = list.runningFold(7) { acc, n -> acc + n }
println(result2) // [7, 18, 31, 48, 67]
// reduce() 사용
val result3 = list.reduce { acc, n -> acc + n }
println(result3) // 60
// runningReduce() 사용
val result4 = list.runningReduce { acc, n -> acc + n }
println(result4) // [11, 24, 41, 60]
}
4. 재귀 (Recursion)
재귀는 함수 안에서 함수 자신을 호출하는 기법으로, tail recursion (꼬리 재귀) 는 일부 재귀 함수에 명시적으로 적용할 수 있는 최적화 방법이다.
재귀 함수는 이전 재귀 호출의 결과를 활용하는데 팩토리얼이 일반적인 예시이다.
- factorial(1) 은 1임
- factorial(n) 은 n * factorial(n-1) 임
factorial() 이 재귀적인 이유는 자신에게 전달된 인자값을 변경한 값으로 자기 자신을 호출한 결과를 사용하기 때문이다.
아래는 factorial() 을 재귀로 구현하는 예시이다.
fun factorial(n: Long): Long {
if (n <= 1) return 1
return n * factorial(n - 1)
}
fun main() {
println(factorial(5)) // 120
println(factorial(17)) // 355687428096000
}
위의 코드는 가독성은 좋지만 처리 비용이 많이 든다.
함수를 호출하면 함수와 인자에 대한 정보가 호출 스택(Call Stack)에 저장된다.
예외가 던져지면 아래와 같은 스택 트레이스가 표시되어 호출 스택을 볼 수 있다.
fun illegalFunc() {
throw IllegalStateException()
}
fun failFunc() = illegalFunc()
fun main() {
failFunc()
}
Exception in thread "main" java.lang.IllegalStateException
at assu.study.kotlinme.chap04.recursion.CallStackKt.illegalFunc(CallStack.kt:4)
at assu.study.kotlinme.chap04.recursion.CallStackKt.failFunc(CallStack.kt:7)
at assu.study.kotlinme.chap04.recursion.CallStackKt.main(CallStack.kt:10)
at assu.study.kotlinme.chap04.recursion.CallStackKt.main(CallStack.kt)
스택 트레이스는 예외가 던져진 순간의 호출 스택 상태를 보여주는데 위의 경우 호출 스택은 main(), failFunc(), illegalFunc() 총 3개의 함수로 구성된다.
main() 에서 시작하여 main() 은 failFunc() 를 호출한다.
failFunc() 의 호출은 호출 스택에 인자와 함수에 대한 필요한 정보를 추가한다.
호출 스택에 인자와 함수에 대한 필요한 정보 추가
함수를 호출할 때마다 스택에 쌓는 정보를 활성 레코드라고 하며, 스택에 쌓이기 때문에 스택 프레임이라고도 함.
함수가 반환될 때 돌아가야 할 주소, 프레임 크기나 이전 프레임 포인터(함수마다 스택 프레임 크기가 달라서 함수 반환 시 스택에서 프레임을 제거할 때 필요함)가 필수로 들어감
이 후 failFunc() 는 illegalFunc() 를 호출하며, 이 호출에 대한 정보도 Call Stack 에 추가된다.
재귀 함수를 호출하면 매 재귀 호출이 호출 스택에 프레임을 추가하는데 이로 인해 호출 스택을 너무 많이 써서 더 이상 스택에 쓸 수 있는 메모리가 없다는 StackOverFlowError 가 발생하기 쉽다.
아래는 무한 재귀의 예시이다.
fun recurse(i: Int): Int = recurse(i + 1)
fun main() {
println(recurse(1))
}
위를 실행하면 아래와 같은 스택 트레이스를 확인할 수 있다.
Exception in thread "main" java.lang.StackOverflowError
at assu.study.kotlinme.chap04.recursion.InfiniteRecursionKt.recurse(InfiniteRecursion.kt:3)
at assu.study.kotlinme.chap04.recursion.InfiniteRecursionKt.recurse(InfiniteRecursion.kt:3)
at assu.study.kotlinme.chap04.recursion.InfiniteRecursionKt.recurse(InfiniteRecursion.kt:3)
재귀 함수가 계속 자신을 호출하면서 스택을 채우기 때문에 StackOverflowError 가 발생하는 것이다.
무한 재귀는 항상 StackOverflowError 로 끝나고, 무한 재귀 없이 그냥 재귀 호출을 아주 많이 해도 동일하게 StackOverflowError 가 발생한다.
예를 들어 아래와 같은 경우이다.
fun customSum(n: Long): Long {
if (n == 0L) return 0
return n + customSum(n - 1)
}
fun main() {
println(customSum(3)) // 6
println(customSum(1_000)) // 500500
// Exception in thread "main" java.lang.StackOverflowError
// at assu.study.kotlinme.chap04.recursion.RecursionLimitsKt.customSum(RecursionLimits.kt:5)
// at assu.study.kotlinme.chap04.recursion.RecursionLimitsKt.customSum(RecursionLimits.kt:5)
// println(customSum(100_000))
// 위와 비교하기 위해 범위의 합계를 구해주는 표준 라이브러리 함수 sum() 사용, 이 때는 정상적인 값을 내놓음
println((1..100_000L).sum()) // 5000050000
}
4.1. 재귀로 인한 StackOverflowError 대응
StackOverflowError 을 피하기 위해서는 재귀 대신 이터레이션을 사용해야 한다.
재귀가 아닌 이터레이션 사용
fun customSum2(n: Long): Long {
var acc = 0L
for (i in 1..n) {
acc += i
}
return acc
}
fun main() {
println(customSum2(10_000L)) // 50005000
println(customSum2(100_000L)) // 5000050000
}
customSum2() 의 호출은 한 번만 이뤄지고 나머지는 for 루프를 통해 계산되기 때문에 StackOverflowError 가 발생할 위험은 없다.
하지만 가변 상태 변수 (var) 를 사용해 변하는 값을 저장해야 하는데 함수형 프로그래밍에서는 가변 상태를 가능하면 피하는 것이 좋다.
4.2. tail recursion (꼬리 재귀): tailrec
StackOverflowError 를 막기 위해 함수형 언어들은 tail recursion 기법을 사용한다.
tail recursion 의 목표는 호출 스택의 크기를 줄이는 것이다.
아래는 일반 재귀와 꼬리 재귀의 차이이다.
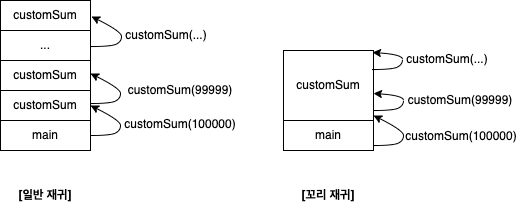
tail recursion 은 tailrec 키워드를 사용해서 만든다.
tailrec 키워드는 올바른 조건하에서 재귀 호출을 이터레이션으로 변환하여 호출 스택 비용을 줄여주지만 모든 재귀 함수에 적용할 수 있는 것은 아니다.
tailrec 을 사용하려면 재귀가 마지막 연산이어야 한다. 즉, 재귀 함수가 자기 자신을 호출하여 얻은 결과값을 아무 연산도 하지 않고 즉시 반환해야 한다는 의미이다.
4. 재귀 (Recursion) 에서 본 아래 코드에 tailrec 키워드를 붙여보자.
tailrec fun customSum(n: Long): Long {
if (n == 0L) return 0
return n + customSum(n - 1)
}
fun main() {
println(customSum(3)) // 6
println(customSum(1_000)) // 500500
// Exception in thread "main" java.lang.StackOverflowError
// at assu.study.kotlinme.chap04.recursion.RecursionLimitsKt.customSum(RecursionLimits.kt:5)
// at assu.study.kotlinme.chap04.recursion.RecursionLimitsKt.customSum(RecursionLimits.kt:5)
// println(customSum(100_000))
// 위와 비교하기 위해 범위의 합계를 구해주는 표준 라이브러리 함수 sum() 사용, 이 때는 정상적인 값을 내놓음
println((1..100_000L).sum()) // 5000050000
}
customSum() 을 호출한 결과를 반환하기 전에 n 을 더해서 아래와 같은 오류가 난다는데 실제로는 나지 않음…
- A function is marked as tail-recursive but no tail calls are found.
- 함수를 tail recursion 으로 표시했지만 실제 함수 본문에는 tail recursion 이 없다는 의미
- Recursive call is not a tail call
- 재귀 호출이 tail recursion 이 아니라는 의미
tailrec 이 성공하려면 재귀 호출 결과를 아무런 연산도 하지 말고 바로 반환해야 한다.
아래는 tailrec 의 예시이다.
// acc 파라미터를 추가하면 재귀 호출 중에 (인자 계산 시) 덧셈 가능
// 결과를 받으면 그냥 반환하는 일 말고는 또다른 연산이 없음
// 모든 연산을 재귀 함수 호출에 위임하기 때문에 tailrec 가능
// acc 가 불변값이 되므로 가변 상태의 변수도 사라짐
private tailrec fun customSum4(
n: Long,
acc: Long,
): Long =
if (n == 0L) {
acc
} else {
customSum4(n - 1, acc + n)
}
fun customSum5(n: Long) = customSum4(n, 0)
fun main() {
println(customSum5(2)) // 3
println(customSum5(10_000)) // 50005000
println(customSum5(100_000)) // 5000050000
}
4.3. 피보나치 수열을 이용한 일반 재귀와 꼬리 재귀의 차이
각 피보나치 수는 이전 두 피보나치 수의 합이다.
처음 2개의 피보나치 수는 0과 1 이므로 수열은 0, 1, 1, 2, 3, 5, 8 … 이다.
이 수열을 일반 재귀로 표현하면 아래와 같다.
// 일반 재귀로 표현한 피보나치
fun fibonacci(n: Long): Long {
return when (n) {
0L -> 0
1L -> 1
else -> fibonacci(n - 1) + fibonacci(n - 2)
}
}
fun main() {
println(fibonacci(0)) // 0
println(fibonacci(22)) // 17711
}
위 코드는 이전에 계산한 값을 재사용하지 않기 때문에 연산 횟수가 기하급수적으로 늘어나서 굉장히 비효율적이다.
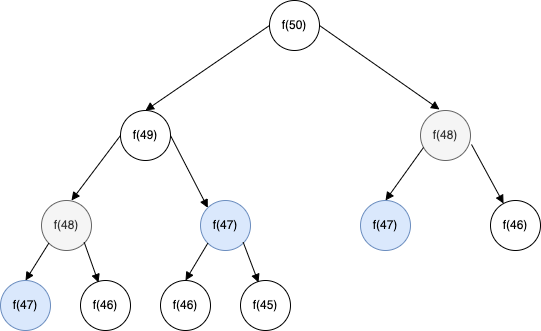
50번째 피보나치 수를 계산하려면 49번째와 48번째를 따로따로 계산해야 한다, 즉, 48번째 수를 2번 계산하게 된다.
47번째 수는 3번 계산해야 하고, 그 이전의 수는 더 많은 횟수를 계산해야 한다.
이 때 tail recursion 을 사용하면 계산 효율이 극적으로 좋아진다.
// fibonacci2(n) 가 Local 함수로 선언된 tail recursion 함수인 fibonacciRec() 을 가려주기 때문에
// 외부에서는 오직 fibonacci2(n) 만 호출 가능
fun fibonacci2(n: Int): Long {
tailrec fun fibonacciRec(
n: Int,
current: Long,
next: Long,
): Long {
if (n == 0) return current
return fibonacciRec(n - 1, next, current + next)
}
return fibonacciRec(n, 0L, 1L)
}
fun main() {
val result1 = (0..8).map { fibonacci2(it) }
// [0, 1, 1, 2, 3, 5, 8, 13, 21]
println(result1)
println(fibonacci2(22)) // 17711
println(fibonacci2(50)) // 12586269025
}
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 브루스 에켈, 스베트라아 이사코바 저자의 아토믹 코틀린 과 드리트리 제메로프, 스베트라나 이사코바 저자의 Kotlin In Action 을 기반으로 스터디하며 정리한 내용들입니다.
- 아토믹 코틀린
- 아토믹 코틀린 예제 코드
- Kotlin In Action
- Kotlin In Action 예제 코드
- Kotlin Github
- 코틀린 doc
- 코틀린 lib doc
- 코틀린 스타일 가이드
