Kotlin - 제네릭스(2): ‘reified’, 타입 변성 ‘in’/’out’, 공변과 무공변, 타입 프로젝션, 스타 프로젝션
이 포스트에서는 제네릭스에 대해 알아본다.
소스는 github 에 있습니다.
- 1. 함수의 타입 인자에 대한 실체화:
reified,KClass - 2. 타입 변성 (type variance)
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- 언어: kotlin 1.9.23
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Gradle 8.5
1. 함수의 타입 인자에 대한 실체화: reified, KClass
코틀린은 제네릭 함수의 본문에서 그 함수의 타입 인자를 가리킬 수 없지만, inline 함수 안에서는 타입 인자를 사용할 수 있다.
코틀린 제네릭 타입의 타입 인자 정보는 실행 시점에 지워지기 때문에 제네릭 클래스의 인스턴스가 있어도 그 인스턴스를 만들 때 사용한 타입 인자를 알아낼 수 없다.
제네릭 함수의 타입 인자도 마찬가지이다.
제네릭 함수가 호출되어도 그 함수의 본문에서는 호출 시 사용된 타입 인자를 알 수 없다.
package com.assu.study.kotlin2me.chap09
// 컴파일 오류
// Cannot check for instance of erased type: T
fun <T> isA(value: Any) = value is T
제네릭 함수를 호출할 때도 타입 정보가 소거되기 때문에 함수 안에서는 제네릭 타입 파라미터를 사용해서 할 수 있는 일이 별로 없다.
함수 인자의 타입 정보를 보존하려면 reified 키워드를 추가하면 된다.
아래는 reified 키워드를 추가하지 않은 상태로 제네릭 함수에서 제네릭 함수를 호출하는 예시이다.
// 코를린 클래스를 표현하는 클래스
import kotlin.reflect.KClass
// 제네릭 함수
fun <T: Any> a(kClass: KClass<T>): T {
// KClass<T>를 사용함
return kClass.createInstance()
}
// 제네릭 함수 b() 에서 a() 호출 시 제네릭 인자의 타입 정보를 전달하려고 시도
// 하지만 타입 소거로 인해 컴파일되지 않음
// 아래와 같은 오류
// Cannot use 'T' as reified type parameter. Use a class instead.
//fun <T:Any> b() = a(T::class)
KClass 는 자바 java.lang.Class 타입과 같은 역할을 하는 코틀린 타입이다.
코틀린 클래스에 대한 참조를 저장할 때 KClass 타입을 사용한다.
KClass에 대한 좀 더 상세한 내용은 2.1.KClass를 참고하세요.
제네릭 함수 b() 에서 제네릭 함수 a() 를 호출할 때 제네릭 인자의 타입 정보도 전달하려고 하지만 타입 소거로 인해 컴파일이 되지 않는다.
Cannot use 'T' as reified type parameter. Use a class instead.
타입 정보 T 가 소거되기 때문에 b() 가 컴파일되지 않는 것이다.
즉, 함수 본문에서 함수의 제네릭 타입 파라미터의 클래스를 사용할 수 없다.
아래와 같이 타입 정보를 전달하여 해결할 수는 있다.
// 제네릭 함수
fun <T: Any> a1(kClass: KClass<T>): T {
// KClass<T>를 사용함
return kClass.createInstance()
}
fun <T: Any> c1(kClass: KClass<T>) = a1(kClass)
class A
// 명시적으로 타입 정보 전달
val kc = c1(A::class)
하지만 컴파일러가 이미 T 의 타입을 알고 있는데 이렇게 명시적으로 타입 정보를 전달하는 것은 불필요한 중복이다.
이를 해결해주는 것이 reified 키워드이다.
reified 는 제네릭 함수를 inline 으로 선언해야 한다.
KClass<T> 와 reified 를 각각 사용한 예시
import kotlin.reflect.KClass
import kotlin.reflect.full.createInstance
// 제네릭 함수
fun <T : Any> a2(kClass: KClass<T>): T {
// KClass<T>를 사용함
return kClass.createInstance()
}
// reified 키워드 사용
// 클래스 참조를 인자로 요구하지 않음
inline fun <reified T: Any> d() = a2(T::class)
class A1
val kd = d<A1>()
reified 는 reified 가 붙은 타입 인자의 타입 정보를 유지시키라고 컴파일러에 명령한다.
따라서 이제 실행 시점에도 타입 정보를 사용할 수 있기 때문에 함수 본문안에서 함수의 제네릭 타입 파라미터의 클래스를 사용할 수 있다.
1.1. reified 를 사용하여 is 를 제네릭 파라미터에 적용
is키워드에 대한 좀 더 상세한 내용은 2.1. 스마트 캐스트:is를 참고하세요.
인라인 함수의 타입 파라미터는 실체화되므로 실행 시점에 인라인 함수의 타입 인자를 알 수 있다.
인라인 함수에 대해 간단히 설명하면 어떤 함수에 inline 키워드를 붙이면 컴파일러는 그 함수를 호출한 식을 모두 함수 본문으로 바꾼다.
함수가 람다를 인자로 사용하는 경우 그 함수를 인라인 함수로 만들면 람다 코드도 함께 인라이닝되고, 그에 따라 무명 클래스 (익명 클래스, Anonymous Class) 와 객체가 생성되지 않아서 성능이 더 좋아질 수 있다.
inline에 대한 좀 더 상세한 내용은 Kotlin - ‘inline’ 를 참고하세요.
이제 인라인 함수가 유용한 다른 이유인 타입 인자 실체화에 대해 알아본다.
1. 함수의 타입 인자에 대한 실체화: reified, KClass 에 나왔던 코드를 보자.
package com.assu.study.kotlin2me.chap09
// 컴파일 오류
// Cannot check for instance of erased type: T
fun <T> isA(value: Any) = value is T
위 코드에서 isA() 함수를 인라인 함수로 만들고 타입 파라미터를 reified 로 지정하면 value 의 타입이 T 의 인스턴스인지 실행 시점에 검사할 수 있다.
package com.assu.study.kotlin2me.chap09
// inline 과 reified 사용
inline fun <reified T> isB(value: Any) = value is T
fun main() {
println(isB<String>("ab")) // true
println(isB<String>(123)) // false
}
// 타입 정보를 유지하여 어떤 객체가 특정 타입인지 검사 가능
inline fun <reified T> check(t: Any) = t is T
// 컴파일 오류
// reified 가 없으면 타입 정보가 소거되기 때문에 실행 시점에 어떤 객체가 T 의 인스턴스인지 검사 불가
// Cannot check for instance of erased type: T
// fun <T> check2(t: Any) = t is T
fun main() {
val result1 = check<String>("1")
val result2 = check<String>(1)
println(result1) // true
println(result2) // false
}
1.2. 실체화한 타입 파라미터 활용: filterIsInstance()
1.5. 타입 파라미터 제약:
filterIsInstance()에서 사용한 타입 계층 코드와 함께 보세요.
실체화한 타입 파라미터를 사용하는 간단한 예시 중 하나는 표준 라이브러리 함수인 filterIsInstance() 이다.
filterIsInstance() 는 인자로 받은 컬렉션의 원소 중에서 타입 인자로 지정한 클래스의 인스턴스만을 모아서 만든 리스트를 반환한다.
package com.assu.study.kotlin2me.chap09
fun main() {
val items = listOf("one", 2, "three")
// [one, three]
println(items.filterIsInstance<String>())
}
filterIsInstance() 의 타입 인자로 String 을 지정함으로써 문자열만 필요하다는 사실을 기술하였다.
따라서 위 함수의 반환 타입은 List<String> 이다.
여기서는 타입 인자를 실행 시점에 알 수 있고, filterIsInstance() 는 그 타입 인자를 사용하여 리스트의 원소 중 타입 인자와 타입이 일치하는 원소만을 추려낸다.
아래는 filterIsInstance() 의 시그니처이다.
public inline fun <reified R> Iterable<*>.filterIsInstance(): List<@kotlin.internal.NoInfer R> {
return filterIsInstanceTo(ArrayList<R>())
}
filterIsInstance() 가 inline 과 reified 키워드를 사용하여 정의되어 있는 것을 알 수 있다.
아래는 특정 하위 타입 Disposable 원소의 name 을 반환하는 예시이다.
inline fun <reified T : Disposable> select() = items.filterIsInstance<T>().map { it.name }
fun main() {
val result1 = select<Compost>()
val result2 = select<Donation>()
println(result1) // [AAA, BBB]
println(result2) // [CCC, DDD]
}
인라인 함수에는 실체화한 타입 파라미터가 여러 개 있거나, 실체화한 타입 파라미터와 실체화하지 않은 타입 파라미터가 함께 있을수도 있다.
1.4. 함수를 inline 으로 선언해야 하는 경우 에서 함수의 파라미터 중 함수 타입인 파라미터가 있고 그 파라미터에 해당하는 인자(람다)를 함께 인라이닝함으로써 얻는 이익이 더 큰 경우에만 함수를 인라인 함수로 만들라고 하였다.
하지만 이 경우 함수를 인라인 함수로 만드는 이유는 성능 향상이 아닌 실체화한 타입 파라미터를 사용하기 위함이다.
성능을 좋게 하려면 인라인 함수의 크기를 계속 관찰하여 함수가 커지면 실체화한 타입에 의존하지 않는 부분을 별도의 일반 함수로 뽑아내는 것이 좋다.
1.3. 인라인 함수에서만 reified 키워드를 사용할 수 있는 이유
인라인 함수의 경우 컴파일러는 인라인 함수의 본문을 구현한 바이트코드를 그 함수가 호출되는 모든 지점에 삽입한다.
컴파일러는 실체화한 타입 인자를 사용하여 인라인 함수를 호출하는 각 부분의 정확한 타입 인자를 알 수 있다.
따라서 컴파일러는 타입 인자로 쓰인 구체적인 클래스를 참조하는 바이트코드를 생성하여 삽입할 수 있다.
아래 코드를 다시 보자.
package com.assu.study.kotlin2me.chap09
fun main() {
val items = listOf("one", 2, "three")
// [one, three]
println(items.filterIsInstance<String>())
}
위 코드의 filterIsInstance<String>() 은 결과적으로 아래와 같은 코드를 만들어낸다.
for (ele in this) {
if (ele is String) { // 특정 클래스 참조
dest.add(ele)
}
}
타입 파라미터가 아니라 구체적인 타입을 사용하므로 만들어진 바이트코드는 실행 시점에 벌어지는 타입 소거의 영향을 받지 않는다.
자바 코드에서는 reified 타입 파라미터를 사용하는 인라인 함수를 호출할 수 없다.
자바에서는 코틀린 인라인 함수를 다른 보통 함수처럼 호출하는데 그런 경우 인라인 함수를 호출해도 실제로 인라이닝되지는 않는다.
1.4. 클래스 참조 대신 실체화한 타입 파라미터 사용: ServiceLoader, ::class.java
java.lang.Class 타입 인자를 파라미터로 받는 API 에 대한 코틀린 Adapter 를 구현하는 경우 실체화한 타입 파라미터를 자주 사용한다.
java.lang.Class 를 사용하는 API 의 예로 JDK 의 ServiceLoader 가 있다.
ServiceLoader 는 어떤 추상 클래스나 인터페이스를 표현하는 java.lang.Class 를 받아서 그 클래스나 인스턴스를 구현한 인스턴스를 반환한다.
실체화한 타입 파라미터를 활용해서 이런 API 를 쉽게 호출하는 방법에 대해 알아본다.
표준 자바 API 인 ServiceLoader 를 사용하여 서비스를 읽어들이는 예시
package com.assu.study.kotlin2me.chap09
import java.security.Provider.Service
import java.util.ServiceLoader
fun main() {
val serviceImpl = ServiceLoader.load(Service::class.java)
// java.util.ServiceLoader[java.security.Provider$Service]
println(serviceImpl)
}
위 코드에서 ::class.java 구문은 코틀린 클래스에 대응하는 java.lang.Class 참조를 얻는 방법이다.
코틀린의 Service::class.java 는 자바의 Service.class 와 같다.
위 내용에 대해서는 6. 애너테이션 파라미터로 클래스 사용:
KClass과 함께 보세요.
위 예시를 구체화한 타입 파라미터를 사용하여 작성하면 아래와 같다.
package com.assu.study.kotlin2me.chap09
import java.security.Provider.Service
import java.util.ServiceLoader
// 읽어들일 서비스 클래스를 함수의 타입 인자로 지정
// 타입 파라미터를 reified 로 지정
inline fun <reified T> loadService(): ServiceLoader<T> {
// T::class 로 타입 파라미터의 클래스를 가져옴
return ServiceLoader.load(T::class.java)
}
fun main() {
val serviceImpl2 = loadService<Service>()
println(serviceImpl2)
}
ServiceLoader.load(Service::class.java) 를 _loadService
loadService() 에서 읽어들일 서비스 클래스를 타입 인자로 지정하였다.
클래스를 타입 인자로 지정하면 ::class.java 라고 쓰는 경우보다 가독성이 더 좋다.
1.5. 실체화한 타입 파라미터의 제약
실체화한 타입 파라미터는 몇 가지 제약이 있다.
<실체화한 타입 파라미터를 사용할 수 있는 경우>
- 타입 검사와 캐스팅
is,!is,as,as?- 1.1.
reified를 사용하여is를 제네릭 파라미터에 적용
- 코틀린 리플렉션 API
::class해당 내용은 6. 애너테이션 파라미터로 클래스 사용:
KClass를 참고하세요
- 코틀린 타입에 대응하는
java.lang.Class얻기 - 다른 함수를 호출할 때 타입 인자로 사용
<실체화한 타입 파라미터를 사용할 수 없는 경우>
- 타입 파라미터 클래스의 인스턴스 생성
- 타입 파라미터 클래스의 동반 객체 메서드 호출
- 실체화한 타입 파라미터를 요구하는 함수를 호출하면서 실체화하지 않은 타입 파라미터로 받은 타입을 타입 인자로 넘기기
- 클래스, 프로퍼티, 인라인 함수가 아닌 함수의 타입 파라미터를
reified로 지정
2. 타입 변성 (type variance)
변성은 List<String> 과 List<Any> 와 같이 기반 타입이 같고, 타입 인자가 다른 여러 타입이 서로 어떤 관계가 있는지 설명하는 개념이다.
제네릭 클래스나 함수를 정의하는 경우 변경에 대해 꼭 알고 있어야 하며, 변성을 잘 활용하면 불편하지 않으면서도 타입 안정성을 보장하는 API 를 만들 수 있다.
제네릭스와 상속을 조합하면 변화가 2차원이 된다.
만일 T 와 U 사이에 상속 관계가 있을 때 Container<T> 라는 제네릭 타입 객체를 Container<U> 라는 제네릭 타입 컨테이너 객체에 대입하려 한다고 해보자.
이런 경우 Container 타입을 어떤 식으로 쓸 지에 따라 Container 의 타입 파라미터에 in 혹은 out 변성 애너테이션(variance annotation)을 붙여서 타입 파라미터를 적용한 Container 타입의 상하위 타입 관계를 제한해야 한다.
2.1. 타입 변성: in/out 변성 애너테이션
아래는 기본 제네릭 타입, in T, out T 를 사용한 예시이다.
// 기본 제네릭 클래스
class Box<T>(private var contents: T) {
fun put(item: T) {
contents = item
}
fun get(): T = contents
}
class InBox<in T>(private var contents: T) {
fun put(item: T) {
contents = item
}
// 컴파일 오류
// Type parameter T is declared as 'in' but occurs in 'out' position in type T
//fun get(): T = contents
}
class OutBox<out T>(private var contents: T) {
// 컴파일 오류
// Type parameter T is declared as 'out' but occurs in 'in' position in type T
// fun put(item: T) {
// contents = item
// }
fun get(): T = contents
}
in T 는 이 클래스의 멤버 함수가 T 타입의 값을 인자로만 받고, T 타입 값을 반환하지 않는다는 의미이다.
out T 는 이 클래스의 멤버 함수가 T 타입의 값을 반환하기만 하고, T 타입의 값을 인자로는 받지 않는다는 의미이다.
2.2. 타입 변성을 사용하는 이유
List<Any> 타입의 파라미터를 받는 함수에 List<String> 을 넘기는 경우 아래와 같은 오류가 발생한다.
아래는 리스트의 내용을 출력하는 함수 예시이다.
package com.assu.study.kotlin2me.chap09
fun printContents(list: List<Any>) {
println(list)
}
fun main() {
// 컴파일 오류
// Type mismatch.
// Required: com.assu.study.kotlin2me.chap09.List<Any>
// Found:kotlin. collections. List<String>
printContents(listOf("a", "b"))
}
리스트를 변경하는 예시
package com.assu.study.kotlin2me.chap09
fun addAnswer(list: MutableList<Any>) {
list.add(1)
}
fun main() {
// MutableList<String> 타입의 변수 선언
val strings = mutableListOf("a", "b")
// 컴파일 오류
// Type mismatch.
// Required: MutableList<Any>
// Found: MutableList<String>
addAnswer(strings)
}
위 예시는 MutableList<Any> 가 필요한 곳에 MutableList<String> 을 넘기면 안된다는 사실을 보여준다.
즉, 어떤 함수가 리스트의 원소를 추가하거나 변경한다면 타입 불일치가 생길 수 있어서 List<Any> 대신 List<String> 을 넘길 수 없다.
변경이 아닌 단순 조회 시에도 똑같이 컴파일 오류가 남
in, out 과 같은 제약이 필요한 이유를 알아보기 위해 아래 타입 계층을 보자.
open class Pet
class Rabbit : Pet()
class Cat : Pet()
2.1. 타입 변성:
in/out변성 애너테이션 에서 사용된 코드와 함께 보세요.
Rabbit 과 Cat 은 모두 Pet 의 하위 타입이다.
Box<Pet> 타입의 변수에 Box<Rabbit> 객체를 대입할 수 있을 것처럼 보인다.
혹은 Any 는 모든 타입의 상위 타입이므로 Box<Rabbit> 의 객체를 Box<Any> 에 대입하는 것이 가능해야할 것 같다.
하지만 실제 코드를 작성해보면 그렇지 않다.
val rabbitBox = Box<Rabbit>(Rabbit())
// 컴파일 오류
// Type mismatch.
// Required: Box<Pet>
// Found: Box<Rabbit>
//val petBox: Box<Pet> = rabbitBox
// 컴파일 오류
// Type mismatch.
// Required: Box<Any>
// Found: Box<Rabbit>
//val anyBox: Box<Any> = rabbitBox
Type mismatch.
Required: Box<Pet>
Found: Box<Rabbit>
petBox 에는 put(item: Pet) 이 있다.
만약 코틀린이 위와 같은 상황에서 오류를 내지 않고 허용한다면 Cat 도 Pet 이므로 Cat 을 rabbitBox 에 넣을 수 있게 되는데 이는 rabbitBox 가 ‘토끼스러운’ 이라는 점을 위반한다.
나아가 anyBox 에도 put(item: Any) 가 있을텐데 rabbitBox 에 Any 타입 객체를 넣으면 이 rabbitBox 컨테이너는 아무런 타입 안전성도 제공하지 못한다.
하지만 out <T> 애너테이션을 사용하면 클래스의 멤버 함수가 값을 반환하기만 하고, T 타입의 값을 인자로는 받지 않으므로 put() 을 사용하여 Cat 을 OutBox<Rabbit> 에 넣을 수 없다.
따라서 rabbitBox 를 petBox 나 anyBox 에 대입하는 대입문이 안전해진다.
OutBox<out T> 에 붙은 out 애너테이션이 put() 함수 사용을 허용하지 않으므로 컴파일러는 OutBox<out Rabbit> 을 OutBox<out Pet> 이나 OutBox<out Any> 에 대입하도록 허용한다.
2.2.1. 클래스, 타입과 하위 타입
타입과 클래스의 차이에 대해 알아보자.
제네릭 클래스가 아닌 클래스에서는 클래스 이름을 바로 타입으로 사용할 수 있다.
// String 클래스의 인스턴스를 저장하는 변수
val x: String
// String 클래스 이름을 null 이 될 수 있는 타입에도 사용 가능
val x: String?
위 코드처럼 모든 코틀린 클래스는 적어도 둘 이상의 타입을 구성할 수 있다.
제네릭 클래스의 경우 올바른 타입을 얻으려면 제네릭 타입의 타입 파라미터를 구체적인 타입 인자로 바꿔주어야 한다.
예를 들어 List 는 클래스이지만 타입은 아니다.
하지만 타입 인자를 치환한 List<Int>, List<String?> .. 등은 모두 제대로 된 타입이다.
하위 타입(subtype) 은 타입 A 의 값이 필요한 모든 장소에 타입 B 를 넣어도 아무런 문제가 없을 경우 ‘타입 B 는 타입 A 의 하위 타입’이라고 할 수 있다.
이는 모든 타입은 자신의 하위 타입이기도 하다는 뜻이다.
예를 들어 Int 는 Number 의 하위 타입이지만 String 의 하위 타입은 아니다.
상위 타입(supertype) 은 하위 타입의 반대이다.
A 타입이 B 타입의 하위 타입이라면 B 는 A 의 상위 타입이다.
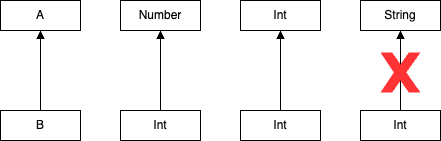
컴파일러는 변수 대입이나 함수 인자 전달 시 매번 하위 타입 검사를 수행한다.
package com.assu.study.kotlin2me.chap09
fun test(i: Int) {
// Int 는 Number 의 하위 타입이므로 정상적으로 컴파일됨
val n: Number = i
fun f(s: String) {
println("f()~")
}
// 컴파일 오류
// Int 가 String 의 하위 타입이 아니므로 컴파일되지 않음
f(i)
}
간단한 경우 하위 타입은 하위 클래스와 근본적으로 같다.
Int 클래스는 Number 클래스의 파생 클래스이므로 Int 는 Number 의 하위 타입이다.
String 은 CharSequence 인터페이스의 하위 타입인 것처럼 어떤 인터페이스를 구현하는 클래스의 타입은 그 인터페이스 타입의 하위 타입이다.
아래는 null 이 될 수 없는 타입은 하위 타입과 하위 클래스가 같지 않는 경우를 보여준다.
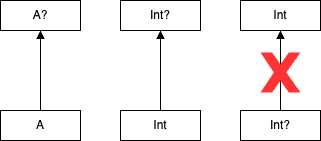
null 이 될 수 없는 타입 A 는 null 이 될 수 있는 타입 A? 의 하위 타입이지만, A? 는 A 의 하위 타입이 아니다.
null 이 될 수 있는 타입은 null 이 될 수 없는 타입의 하위 타입이 아니지만 두 타입은 같은 클래스에 해당한다.
제네릭 타입에 대해 다룰 때 특히 하위 클래스와 하위 타입의 차이는 중요해진다.
List<String> 타입의 값을 List<Any> 를 파라미터로 받는 함수에 전달해도 되는가? 에 대한 질문을 하위 타입 관계를 써서 다시 보면 List<String> 은 List<Any> 의 하위 타입인가? 이다.
2.2. 타입 변성을 사용하는 이유 에서 본 것처럼 MutableList<String> 을 MutableList<Any> 의 하위 타입으로 다루면 안되고, 그 반대도 마찬가지이다.
즉, MutableList<String> 과 MutableList<Any> 은 서로 하위 타입이 아니다.
제네릭 타입을 인스턴스화할 때 타입 인자로 서로 다른 타입이 들어가서 인스턴스 타입 사이의 하위 타입 관계가 성립하지 않으면 그 제네릭 타입을 무공변(invariant) 라고 한다.
예를 들어 MutableList 의 경우 A 와 B 가 서로 다르기만 하면 MutableList<A> 는 항상 MutableList<B> 의 하위 타입이 아니므로 MutableList 는 무공변이다.
예를 들어 List 의 경우 A 가 B 의 하위 타입일 때 List<A> 가 List<B> 의 하위 타입인데 이런 클래스나 인터페이스를 공변적(covariant) 이라고 한다.
2.2.2. 공변성(covariant): 하위 타입 관계 유지 (out)
타입 파라미터 T 에 붙은 out 키워드는 아래를 의미한다.
- 공변성
- 하위 타입 관계가 유지됨 (Producer<Cat> 은 Producer<Animal> 의 하위 타입)
- 사용 제한
T를out위치에서만 사용 가능
2.1. 타입 변성: in/out 변성 애너테이션 에서 out T 는 이 클래스의 멤버 함수가 T 타입의 값을 반환하기만 하고, T 타입의 값을 인자로는 받지 않는다는 의미 라고 하였다.
A 가 B 의 하위 타입일 때 Producer<A> 가 Producer<B> 의 하위 타입이면 Producer 는 공변적이다.
예) Producer<Cat> 은 Producer<Animal> 의 하위 타입
코틀린에서 제네릭 클래스가 타입 파라미터에 대해 공변적임을 표시하려면 타입 파라미터 이름 앞에 out 애너테이션을 넣으면 된다.
// 클래스가 T 에 대해 공변적이라고 선언
interface Producer<out T> {
fun produce(): T
}
클래스 타입 파라미터를 공변적으로 만들면 함수 정의에 사용한 파라미터 타입과 타입 인자의 타입이 정확히 일치하지 않더라도 그 클래스의 인스턴스를 함수 인자나 반환값으로 사용할 수 있다.
아래는 무공변 컬렉션 역할을 하는 클래스를 정의하는 예시이다.
// 무공변 컬렉션 역할을 하는 클래스 정의
open class Animal {
fun feed() = println("feed~")
}
class Herd<T : Animal> { // 이 타입 파라미터를 무공변성으로 지정
val size: Int
get() = 1
operator fun get(i: Int): T {
// ...
}
}
fun feedAll(animals: Herd<Animal>) {
for (i in 0 until animals.size) {
animals[i].feed()
}
}
아래는 무공변 컬렉션 역할을 하는 클래스를 사용하는 예시이다.
// 무공변 컬렉션 역할을 하는 클래스 사용
// Cat 은 Animal 임
open class Cat : Animal() {
fun cleanLitter() = println("clean litter~")
}
fun takeCareOfCats(cats: Herd<Cat>) {
for (i in 0 until cats.size) {
cats[i].cleanLitter()
// 컴파일 오류
// Type mismatch.
// Required:Herd<Animal>
// Found:Herd<Cat>
//feedAll(cats)
}
}
Herd 클래스의 T 타입 파라미터에 아무 변성도 지정하지 않았기 때문에 Cat 은 Animal 의 하위 타입이 아니다.
명시적으로 타입 캐스팅을 사용해서 컴파일 오류를 해결할 수도 있지만 그러면 코드가 장황해지고 실수를 하기 쉽다.
또한 타입 불일치를 해결하기 위해 강제 캐스팅을 하는 것을 올바른 방법이 아니다.
Herd 클래스는 List 와 비슷한 API 를 제공하며, 동물을 그 클래스에 추가하거나 변경할 수 없다.
따라서 Herd 를 공변적인 클래스로 만들어서 위 문제를 해결할 수 있다.
아래는 공변적 컬렉션 역할을 하는 클래스에 대한 예시이다.
package com.assu.study.kotlin2me.chap09
// 무공변 컬렉션 역할을 하는 클래스 정의
open class Animal2 {
fun feed() = println("feed~")
}
class Herd2<out T : Animal2> { // T 는 이제 공변적임
val size: Int
get() = 1
operator fun get(i: Int): T {
// ...
}
}
fun feedAll2(animals: Herd2<Animal2>) {
for (i in 0 until animals.size) {
animals[i].feed()
}
}
// 무공변 컬렉션 역할을 하는 클래스 사용
// Cat 은 Animal 임
open class Cat2 : Animal2() {
fun cleanLitter() = println("clean litter~")
}
fun takeCareOfCats2(cats: Herd2<Cat2>) {
for (i in 0 until cats.size) {
cats[i].cleanLitter()
// 캐스팅을 할 필요가 없음
feedAll2(cats)
}
}
모든 클래스를 공변적으로 만들 수는 없다.
공변적으로 만들면 안전하지 못한 클래스도 있기 때문에 타입 파라미터를 공변적으로 지정하면 클래스 내부에서 그 파라미터를 사용하는 방법을 제한한다.
타입 안전성을 보장하기 위해 공변적 파라미터는 항상 out 위치에 있어야 한다.
즉, 클래스가 T 타입의 값을 생산할 수는 있지만 T 타입의 값을 소비할 수는 없다는 의미이다.
(= 이 클래스의 멤버 함수가 T 타입의 값을 반환하기만 하고, T 타입의 값을 인자로는 받지 않는다는 의미)
클래스 멤버를 선언할 때 타입 파라미터를 사용할 수 있는 지점은 모두 in 과 out 위치로 나뉜다.
T 라는 타입 파라미터를 선언하고 T 를 사용하는 함수가 멤버로 있는 클래스를 생각해보자.
T 가 함수의 반환 타입으로 쓰인다면 T 는 out 위치에 있다. (= T 타입의 값을 생산함)
T 가 함수의 파라미터 타입에 쓰인다면 T 는 in 위치에 있다. (= T 타입의 값을 소비함)
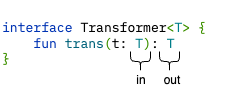
클래스 타입 파라미터 T 앞에 out 키워드를 붙이면 클래스 안에서 T 를 사용하는 메서드가 out 위치에서만 T 를 사용하도록 허용한다.
out 키워드는 T 의 사용법을 제한하며, T 로 인해 생기는 하위 타입 관계의 타입 안전성을 보장한다.
바로 위의 코드에서 Herd 클래스를 보자.
class Herd2<out T : Animal2> { // T 는 이제 공변적임
val size: Int
get() = 1
operator fun get(i: Int): T { // T 를 반환 타입으로 사용
// ...
}
}
Herd 에서 타입 파라미터 T 를 사용하는 곳은 오직 get() 메서드의 반환 타입 뿐이다.
함수의 반환 타입은 out 위치이다.
따라서 이 클래스를 공변적으로 선언해도 안전하다.
Cat 이 Animal 의 하위 타입이므로 Herd<Animal> 의 get() 을 호출하는 모든 코드는 get() 이 Cat 을 반환해도 아무 문제없다.
이제 List<T> 인터페이스를 보자.
코틀린 List 는 읽기 전용이므로 T 타입의 원소를 반환하는 get() 메서드는 있지만 리스트에 T 타입의 값을 추가하거나 변경하는 메서드는 없다.
따라서 List 는 공변적이다.
List<T> 시그니처
public interface List<out E> : Collection<E> {
// ...
// 읽기 전용 메서드로 E 를 반환하는 메서드만 정의함
// 따라서 E 는 항상 out 위치에 사용됨
public operator fun get(index: Int): E
// 여기서도 E 는 out 위치에 있음
public fun subList(fromIndex: Int, toIndex: Int): List<E>
}
타입 파라미터를 함수의 파라미터 타입이나 반환 타입 뿐 아니라 다른 타입의 타입 인자로도 사용할 수 있다.
예를 들어 위의 subList() 에서 사용된 T 도 out 위치에 있다.
MutableList<T> 는 타입 파라미터 T 에 대해 공변적인 클래스로 선언할 수 없다.
MutableList<T> 에는 T 를 인자로 받아서 그 타입의 값을 반환하는 메서드가 있다.
따라서 T 가 in 과 out 위치에 동시에 사용된다.
MutableList<T> 의 시그니처
// MutableList 는 E 에 대해 공변적일 수 없음
public interface MutableList<E> : List<E>, MutableCollection<E> {
// ...
// 이유는 E 가 in 위치에 쓰이기 때문임
override fun add(element: E): Boolean
}
생성자 파라미터는 in, out 어느 쪽도 아니다.
타입 파라미터가 out 이라 해도 그 타입을 여전히 생성자 파라미터 선언에 사용할 수 있다.
// 생성자 파라미터는 in, out 어느 쪽도 아님
// 파라미터 타입이 out 이어도 생성자 파라미터에 선언 가능
class Herd3<out T: Animal2>(vararg animals: T) {
// ...
}
변성은 코드에서 위험할 여지가 있는 메서드를 호출할 수 없게 만듦으로써 제네릭 타입의 인스턴스 역할을 하는 클래스 인스턴스를 잘못 사용하는 일이 없도록 방지하는 역할을 한다.
생성자는 인스턴스를 생성한 뒤 나중에 호출할 수 있는 메서드가 아니므로 생성자는 위험할 여지가 없다.
하지만 val, var 키워드를 생성자 파라미터에 적는다면 getter 나 setter 를 정의하는 것과 같다.
따라서 읽기 전용 프로퍼티는 out 위치, 변경 가능 프로퍼티는 in/out 위치 모두에 해당한다.
class Herd4<T: Animal2>(var animal1: T, vararg animals: T) {
// ...
}
위 코드에서 T 타입인 animal1 프로퍼티가 in 위치에 사용되었기 때문에 T 를 out 으로 표시할 수 없다.
변성 규칙 in, out 은 오직 외부에서 볼 수 있는 public, protected, internal 클래스 API 에만 적용할 수 있다.
private 메서드의 파라미터는 in 도 아니고 out 도 아닌 위치이다.
변성 규칙은 클래스 외부의 사용자가 클래스를 잘못 사용하는 일을 막기 위한 것이므로 클래스 내부 구현에는 적용되지 않는다.
가시성 변경자에 대한 내용은 10. 가시성 변경자 (access modifier, 접근 제어 변경자):
public,private,protected,internal를 참고하세요.
따라서 2.2. 타입 변성을 사용하는 이유 의 코드를 아래와 같이 수정할 수 있다.
val outRabbitBox: OutBox<Rabbit> = OutBox(Rabbit())
// OutBox<Rabbit> 의 객체를 상위 타입에 대입 가능
val outPetBox: OutBox<Pet> = outRabbitBox
val outAnyBox: OutBox<Any> = outRabbitBox
// 같은 수준의 타입으로는 대입 불가
// val outCatBox: OutBox<Cat> = outRabbitBox
fun main() {
val rabbit: Rabbit = outRabbitBox.get()
val pet: Pet = outPetBox.get()
val any: Any = outAnyBox.get()
println(rabbit) // assu.study.kotlinme.chap07.creatingGenerics.Rabbit@7ef20235
println(pet) // assu.study.kotlinme.chap07.creatingGenerics.Rabbit@7ef20235
println(any) // assu.study.kotlinme.chap07.creatingGenerics.Rabbit@7ef20235
}
2.2.3. 반공변성(contravariant): 뒤집힌 하위 타입 관계 (in)
2.1. 타입 변성: in/out 변성 애너테이션 에서 in T 는 이 클래스의 멤버 함수가 T 타입의 값을 인자로만 받고, T 타입 값을 반환하지 않는다는 의미 라고 하였다.
in애너테이션은 상위 타입을 하위 타입에 대입 가능하게 해주고,out애너테이션은 하위 타입을 상위 타입에 대입 가능하게 해줌
Comparator 인터페이스에는 compare() 메서드가 있다.
Comparator 인터페이스 시그니처
interface Comparator<in T> {
// ...
// T 를 in 위치에 사용
fun compare(o1: T, o2: T): Int
}
위 인터페이스의 메서드는 T 타입의 값을 소비하기만 한다.
이는 T 가 in 위치에서는 사용된다는 의미이므로 T 앞에 in 키워드를 붙여야만 한다.
물론 Comparator 를 구현하면 그 타입의 하위 타입에 속하는 모든 값을 비교할 수 있다.
Comparator<Any> 를 이용하여 모든 타입의 값을 비교하는 예시
package com.assu.study.kotlin2me.chap09
import kotlin.collections.List
fun main() {
val anyComparator = Comparator<Any> { o1, o2 -> o1.hashCode() - o2.hashCode() }
val strings: List<String> = listOf("bbb", "aaa", "ccc")
// [aaa, bbb, ccc]
println(strings.sortedWith(anyComparator))
}
위 코드에서 sortedWith() 는 Comparator<String> 을 요구하므로 String 보다 더 일반적인 타입을 비교할 수 있는 Comparator<Any> 타입을 넘겨도 안전하다.
어떤 타입의 객체를 Comparator 로 비교할 때 그 타입이나 그 타입의 조상 타입을 비교할 수 있는 Comparator 를 사용할 수 있다.
이는 Comparator<Any> 가 Comparator<String> 의 하위 타입이라는 의미이다.
그런데 여기서 Any 는 String 의 상위 타입이다.
따라서 서로 다른 타입 인자에 대해 Comparator 의 하위 타입 관계는 타입 인자의 하위 타입 관계와는 정반대 방향이다.
이제 Consumer<T> 를 예시로 하여 반공변성에 대해 알아본다.
타입 B 가 타입 A 의 하위 타입인 경우 Consumer<A> 가 Consumer<B> 의 하위 타입인 관계가 성립하면 제네릭 클래스 Consumer<T> 는 타입 인자 T 에 대해 반공변이다.
A 와 B 의 위치가 서로 바뀐다는 점에 유의하자.
즉, 하위 타입 관계가 뒤집힌다고 말한다.
예) Consumer<Animal> 은 Consumer<Cat> 의 하위 타입
아래는 타입 파라미터에 대해 공변성인 클래스와 반공변성인 클래스의 하위 타입 관계이다.
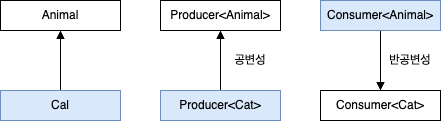
위 그림을 보면 공변성 타입 Producer<T> 에서는 타입 인자의 하위 타입 관계가 제네릭 타입에서도 유지되지만, 반공변성 타입인 Consumer<T> 에서는 타입 인자의 하위 타입 관계가 제네릭 타입으로 오면서 반대로 뒤집힌다.
in 키워드가 붙은 타입은 이 클래스의 메서드 안으로 전달되어 메서드에 의해 소비된다.
클래스나 인터페이스가 어떤 파라미터에 대해서는 공변적이면서 다른 타입 파라미터에 대해서는 반공변적일 수도 있다.
Function 인터페이스가 바로 그 예이다.
interface Function<in P, out R> {
operator fun invoke(p: P): R
}
위 함수 Function 의 하위 타입 관계는 첫 번째 타입 인자인 P 와는 반대 관계이지만, 두 번째 타입 인자인 R 의 하위 타입 관계와는 같다.
2.1. 타입 변성: in/out 변성 애너테이션 의 InBox<in T> 에는 get() 이 없기 때문에 InBox<Any> 를 InBox<Pet> 이나 InBox<Pet> 등 하위 타입에 대입할 수 있다.
// InBox<Any> 의 객체를 하위 타입에 대입 가능
val inBoxAny: InBox<Any> = InBox(Any())
val inBoxPet: InBox<Pet> = inBoxAny
val inBoxCat: InBox<Cat> = inBoxAny
val inBoxRabbit: InBox<Rabbit> = inBoxAny
// 같은 수준의 타입으로는 대입 불가
// val inBoxRabbit2: InBox<Rabbit> = inBoxCat
fun main() {
inBoxAny.put(Any())
inBoxAny.put(Pet())
inBoxAny.put(Cat())
inBoxAny.put(Rabbit())
// inBoxPet.put(Any())
inBoxPet.put(Pet())
inBoxPet.put(Cat())
inBoxPet.put(Rabbit())
// inBoxRabbit.put(Any())
// inBoxRabbit.put(Pet())
// inBoxRabbit.put(Cat())
inBoxRabbit.put(Rabbit())
inBoxCat.put(Cat())
}
아래는 Box, OutBox, InBox 의 하위 타입 관계이다.
// 기본 제네릭 클래스
class Box<T>(private var contents: T) {
fun put(item: T) {
contents = item
}
fun get(): T = contents
}
class InBox<in T>(private var contents: T) {
fun put(item: T) {
contents = item
}
// 컴파일 오류
// Type parameter T is declared as 'in' but occurs in 'out' position in type T
//fun get(): T = contents
}
class OutBox<out T>(private var contents: T) {
// 컴파일 오류
// Type parameter T is declared as 'out' but occurs in 'in' position in type T
// fun put(item: T) {
// contents = item
// }
fun get(): T = contents
}
2.2.4. 무공변(invariant), 공변(covariant), 반공변(contravariant)
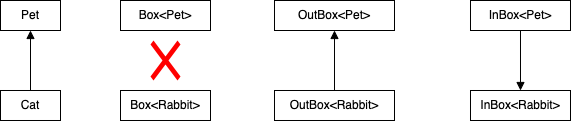
- Box<T>
- 무공변(invariant) 임
- Box<Cat> 과 Box<Rabbit> 은 아무런 하위 타입 관계가 없으므로 둘 중 어느 쪽도 반대쪽에 대입 불가
- OutBox<out T>
- 공변(covariant) 임
- Outbox<Rabbit> 을 OutBox<Pet> 으로 업캐스트하는 방향이 Rabbit 을 Pet 으로 업캐스트하는 방향과 같은 방향으로 변함
- InBox<in T>
- 반공변(contravariant) 임
- InBox<Pet> 이 InBox<Rabbit> 의 하위 타입임
- InBox<Pet> 을 InBox<Rabbit> 으로 업캐스트하는 방향이 Rabbit 을 Pet 으로 업캐스트 하는 방향과 반대 방향으로 변함
2.3. 공변(covariant)과 무공변(invariant)
코틀린 표준 라이브러리의 읽기 전용 List 는 공변이므로 List<Rabbit> 을 List<Pet> 에 대입할 수 있다.
반면 MutableList 는 읽기 전용 리스트의 기능에 add() 를 추가했기 때문에 무공변이다.
fun main() {
val rabbitList: List<Rabbit> = listOf(Rabbit())
// 읽기 전용 리스트는 공변이므로 List<Rabbit> 을 List<Pet> 에 대입 가능
val petList: List<Pet> = rabbitList
var mutablePetList: MutableList<Pet> = mutableListOf(Rabbit())
mutablePetList.add(Cat())
// 가변 리스트는 무공변이므로 같은 타입만 대입 가능
// Type mismatch.
// Required: MutableList<Pet>
// Found: MutableList<Cat>
// mutablePetList = mutableListOf<Cat>(Cat())
}
2.4. 함수의 공변적인 반환 타입
함수는 공변적인 반환 타입을 가지기 때문에 오버라이드 하는 함수가 오버라이드 대상 함수보다 더 구체적인 반환 타입을 돌려줘도 된다.
interface Parent
interface Child: Parent
interface X {
fun f(): Parent
}
interface Y: X {
// X 의 f() 보다 더 하위 타입을 반환함
override fun f(): Child
}
2.5. 사용 지점 변성: 타입이 언급되는 지점에서 변성 지정
클래스 정의 시점에 변성을 직접 기술하면 그 클래스를 사용하는 모든 장소에 그 변성이 적용되어 편하지만 자바는 이를 지원하지 않는다.
대신 클래스를 사용하는 위치에서 와일드카드 ? 를 이용하여 그때그때 변성을 지정해야 한다.
여기서는 이런 두 접근 방법에 대한 차이를 알아보고 코틀린에서 자바와 같은 변성 지정 방법을 어떻게 사용하는지 알아본다.
클래스를 선언하면서 변성을 지정하는 방식을 선언 지점 변성(declaration site variance) 라고 한다.
자바의 와일드카드 타입(? extends 혹은 ? super) 처럼 자바는 변성을 다른 방식으로 다룬다.
자바에서는 타입 파라미터가 있는 타입을 사용할 때마다 해당 타입 파라미터를 하위 타입이나 상위 타입 중 어떤 타입으로 대치할 수 있는지 명시해야 한다.
이런 방식을 사용 지점 변성(use-site variance) 라고 한다.
코틀린의 선언 지점 변성 vs 자바 와일드카드
선언 지점 변성을 사용하면 변성 변경자를 단 한번만 표시하고, 클래스를 사용하는 쪽에서 변성에 대해 신경쓸 필요가 없으므로 코드가 더 간결해짐
자바에서는 항상Function<? super T, ? extends R>처럼 와일드카드를 사용해야 함클래스 선언 지점 변성을 사용하면 훨씬 더 간결하고 우아한 코드를 작성할 수 있음
코틀린도 사용 지점 변성을 지원하므로 클래스 안에서 어떤 타입 파라미터가 공변적 혹은 반공변적인지 선언할 수 없는 경우에는 특정 타입 파라미터가 나타나는 지점에서 변성을 지정할 수 있다.
이제 코틀린에서 사용 지점 변성이 어떻게 작동하는지 보자.
MutableList 와 같은 많은 인터페이스는 타입 파라미터로 지정된 타입을 소비하는 동시에 생산할 수 있기 때문에 일반적으로 공변적이지도 않고 반공변적이지도 않다.
하지만 그런 인터페이스 타입의 변수가 한 함수 안에서 생산자나 소비자 중 단 한가지 역할만을 담당하는 경우가 있다.
무공변 파라미터 타입을 사용하는 데이터 복사 함수
// 무공변 파라미터 타입을 사용하는 데이터 복사 함수
fun <T> copyData(source: MutableList<T>, dest: MutableList<T>) {
for (item in source) {
dest.add(item)
}
}
위 함수는 컬렉션의 원소를 다른 컬렉션으로 복사한다.
두 컬렉션 모두 무공변 타입이지만 원본 컬렉션에서는 읽기만 하고, 대상 컬렉션을 쓰기만 한다.
이 경우 두 컬렉션의 원소 타입이 정확하게 일치할 필요는 없다.
따라서 이 함수가 다른 리스트 타입에 대해서도 작동하게 하려면 두 번째 제네릭 파라미터 타입을 도입하면 된다.
타입 파라미터가 두 개인 데이터 복사 함수 (변성을 사용하여 더 우아하게 표현할 수 있으므로 참고만 할 것)
package com.assu.study.kotlin2me.chap09
// 타입 파라미터가 두 개인 데이터 복사 함수
// source 의 원소타입 T 는 dest 의 원소타입 R 의 하위 타입이어야 함
fun <T: R, R> copyData2(source: MutableList<T>, dest: MutableList<R>) {
for (item in source) {
dest.add(item)
}
}
fun main() {
val ints = mutableListOf(1, 2)
val anyItems = mutableListOf<Any>()
// Int 는 Any 의 하위 타입이므로 함수 호출 가능
copyData2(ints, anyItems)
// [1, 2]
println(anyItems)
}
위 코드에서 두 타입 파라미터는 원본과 대상 리스트의 원소 타입을 표현한다.
한 리스트에서 다른 리스트로 원소를 복사하려면 원본 리스트 원소 타입은 대상 리스트 원소 타입의 하위 타입이어야 한다.
2.5.1. 타입 프로젝션
코틀린은 바로 위 코드를 더 우아하게 표현할 수 있다.
out 프로젝션 타입 파라미터를 사용하는 데이터 복사 함수
package com.assu.study.kotlin2me.chap09
// out 프로젝션 타입 파라미터를 사용하는 데이터 복사 함수
fun <T> copyData3(source: MutableList<out T>, dest: MutableList<T>) {
for (item in source) {
dest.add(item)
}
}
위의 copyDataX() 를 제대로 구현하는 방법은
List<T>를 source 의 인자 타입으로 정하는 것이지만 (읽기만 하므로) 개념 이해를 위해MutableList<T>를 사용함
타입 선언에서 타입 파라미터를 사용하는 위치라면 파라미터 타입, 로컬 변수 타입, 함수 반환 타입 등 어느 곳에나 in, out 변성 변경자를 붙일 수 있다.
이 때 타입 프로젝션(type projection) 이 일어난다.
즉, source 를 일반적인 MutableList 가 아닌 MutableList 를 프로젝션한 (= 제약을 가한) 타입으로 만든다.
컴파일러는 out 변성 변경자가 붙은 타입 파라미터를 함수 인자 타입(= in 위치에 있는 타입) 으로 사용하지 못하게 막는다.
프로젝션 타입의 메서드 중 일부를 호출하지 못하는 경우라면 프로젝션 타입 대신 2.5. 사용 지점 변성: 타입이 언급되는 지점에서 변성 지정 에서 본 타입 파라미터가 두 개인 데이터 복사 함수 예시처럼 일반 타입을 사용하면 된다.
List<out T> 처럼 out 변경자가 이미 지정된 타입 파라미터를 다시 out 프로젝션 하는 것은 의미없다.
List 는 이미 class List<out T> 라고 정의되어 있으므로 List<out T> 는 List<T> 와 동일하다.
in 도 비슷한 방식으로 사용 가능하다.
in 을 붙이면 그 파라미터를 더 상위 타입으로 대치할 수 있다.
이제 위 함수를 다시 작성해본다.
// in,out 프로젝션 타입 파라미터를 사용하는 데이터 복사 함수
// in 프로젝션을 하여 원본 리스트 원소 타입의 상위 타입을 대상 리스트 원소 타입으로 허용함
fun <T> copyData4(source: MutableList<out T>, dest: MutableList<in T>) {
for (item in source) {
dest.add(item)
}
}
코틀린의 사용 지점 변성은 자바의 한정 와일드카드(bounded wildcard) 와 동일하다.
즉, 코틀린의 MutableList<out T> 는 자바의 MutableList<? extends T> 와 같고, 코틀린의 MutableList<in T> 는 자바의 MutableList<? super T> 와 같다.
2.6. 스타 프로젝션
6.3. 스타 프로젝션(star projection):
*과 함께 보면 도움이 됩니다.
제네릭 타입 인자 정보가 없음을 표현할 때 스타 프로젝션을 사용한다.
예) 원소 타입이 알려지지 않은 리스트는 List<*> 로 표현
MutableList<*> 는 MutableList<Any?> 와 같지 않다.
(MutableList<T> 가 T 에 대해 무공변성이라는 점을 기억하고 있자.)
MutableList<Any?>- 모든 타입의 원소를 담을 수 있는 리스트라는 것을 표현
MutableList<*>- 어떤 정해진 구체적인 타입의 원소만을 담는 리스트이지만 그 원소의 타입을 정확히 모른다는 사실을 표현
- 원소 타입이 어떤 타입인지 모른다고 해서 그 안에 아무 원소나 다 담아도 된다는 의미는 아님
- 그 리스트에 담는 값의 타입에 따라서 넘겨준 쪽이 바라는 조건을 깰 수도 있기 때문
- 하지만
MutableList<*>타입의 리스트에서 원소를 얻을 수는 있음 - 이 때 진짜 원소 타입은 알 수 없지만 어쨌든 그 원소 타입이
Any?의 하위 타입이라는 사실은 분명함 (Any?는 모든 타입의 상위 타입이므로)
package com.assu.study.kotlin2me.chap09
import kotlin.random.Random
fun main() {
val list: MutableList<Any?> = mutableListOf('a', 1, "bbb")
val chars = mutableListOf('a', 'b', 'c')
// MutableList<*> 과 MutableList<Any?> 는 다름
val unknownElements: MutableList<*> =
if (Random.nextBoolean()) { // list 와 chars 중 랜덤으로 할당
list
} else {
chars
}
// 컴파일 오류
// unknownElements.add(3)
// bb 는 Any? 타입임
// 원소를 가져와도 안전함
val bb = unknownElements.first()
// a
println(bb)
}
위에서 unknownElements.add(3) 은 컴파일 오류가 발생한다.
위에서 컴파일러는 MutableList<*> 를 아웃 프로젝션 타입으로 인식해서 MutableList<*> 는 MutableList<out Any?> 처럼 동작한다.
어떤 리스트의 원소 타입을 모르더라도 그 리스트에서 안전하게 Any? 타입의 원소를 꺼내올 수는 있지만 (Any? 는 모든 타입의 상위 타입), 타입을 모르는 리스트에 원소를 마음대로 넣을수는 없다.
자바의 와일드카드와 비교하면 코틀린의 MyType<*> 은 자바의 MyType<?> 에 대응함
반공변 타입 파라미터에 대한 스타 프로젝션
Consumer<in T> 와 같은 반공변 타입 파라미터에 대한 스타 프로젝션은 Consumer<in Nothing> 과 동등함
결과적으로 이런 스타 프로젝션에서는 T 가 시그니처에 들어가 있는 메서드를 호출할 수 없음타입 파라미터가 반공변이라면 제네릭 클래스는 소비자 역할을 하는데 그 클래스가 정확히 T 의 어떤 부분을 사용할 지 알 수 없으므로 반공변 클래스에 무언가를 소비하게 넘길 수 없음
타입 파라미터를 시그니처에서 전혀 언급하지 않거나 데이터를 읽기는 하지만 그 타입에 대해서는 관심이 없는 경우와 같이 타입 인자 정보가 중요하지 않을 때도 스타 프로젝션을 사용할 수 있다.
package com.assu.study.kotlin2me.chap09
import kotlin.collections.List
// 모든 리스트를 인자로 받을 수 있음
fun printFirst(list: List<*>) {
if (list.isNotEmpty()) { // 제네릭 타입 파라미터를 사용하지 않음
// tmp 는 Any? 타입이지만 여기서는 그 타입만으로 충분함
val tmp = list.first()
println(tmp)
}
}
fun main() {
// aaa
printFirst(listOf("aaa", 222))
}
2.5. 사용 지점 변성: 타입이 언급되는 지점에서 변성 지정 에서 본 타입 파라미터가 두 개인 데이터 복사 함수 예시처럼 스타 프로젝션도 제네릭 파라미터를 도입하여 구현할 수 있다.
package com.assu.study.kotlin2me.chap09
import kotlin.collections.List
fun <T> printFirst2(list: List<T>) {
if (list.isNotEmpty()) {
// tmp 는 T 타입
val tmp = list.first()
println(tmp)
}
}
fun main() {
// 222
printFirst2(listOf(222, "aaa"))
}
스타 프로젝션을 쓰는 쪽이 더 간결하지만 제네릭 타입 파라미터가 어떤 타입인지 굳이 알 필요가 없을 때만 스타 프로젝션을 사용해야 한다.
스타 프로젝션을 사용할 때는 값을 만들어내는 메서드만 호출할 수 있고, 그 값의 타입에는 신경쓰면 안된다.
2.6.1. 스타 프로젝션 주의점
스타 프로젝션 사용 방법과 스타 프로젝션 사용 시 주의할 점에 대해 알아본다.
사용자 입력을 검증하는 FieldValidator 인터페이스를 정의하는데 이 인터페이스에는 in 위치에서만 사용되는 타입 파라미터가 있다.
따라서 FieldValidator 는 반공변성이다.
(String 타입의 필드를 검증하기 위해 Any 타입을 검증하는 FieldValidator 사용 가능, 이는 반공변성이기 때문임)
아래는 String 과 Int 를 검증하는 FieldValidator 인터페이스 정의이다.
package com.assu.study.kotlin2me.chap09
// T 에 대해 반공변인 인터페이스 정의
interface FieldValidator<in T> {
// T 를 in 위치에서만 사용 (이 메서드는 T 타입의 값은 소비함)
fun validate(input: T): Boolean
}
object DefaultStringValidator : FieldValidator<String> {
override fun validate(input: String): Boolean = input.isNotEmpty()
}
object DefaultIntValidator : FieldValidator<Int> {
override fun validate(input: Int): Boolean = input >= 0
}
object에 대한 내용은 1.object을 참고하세요.
이제 모든 검증기를 한 컨테이너에 넣고 입력 필드 타입에 따라 적절한 검증기를 사용하는 경우를 생각해보자.
이 경우 Map 에 검증기를 담으면 된다.
모든 타입의 검증기를 Map 에 넣을 수 있어야 하므로 코틀린 클래스를 표현하는 KClass 를 key 로 하고, FieldValidator<*> 를 value 로 하는 Map 을 선언한다.
(FieldValidator<*> 는 모든 타입의 검증기를 표현함)
fun main() {
val validators = mutableMapOf<KClass<*>, FieldValidator<*>>()
validators[String::class] = DefaultStringValidator
validators[Int::class] = DefaultIntValidator
}
이제 검증기를 사용해보자.
// 컴파일 오류
validators[String::class]!!.validate("Abc")
String 타입의 필드를 FieldValidator<*> 타입의 검증기로 검증할 수 없다.
컴파일러는 FieldValidator<*> 가 어떤 타입을 검증하는 검증기인지 모르기 때문에 String 을 검증하기 위해 그 검증기를 사용하면 위험하다고 판단한다.
위의 컴파일 오류는 알 수 없는 타입의 검증기에 구체적인 값을 넘기면 안전하지 못하기 때문에 발생하는 오류이다.
검증기를 원하는 타입으로 캐스팅하면 오류를 해결할 수 있지만 그런 타입 캐스팅은 안전하지 못하고 권장하지도 않는다.
하지만 일단 시도는 해보자.
검증기를 가져오면서 명시적으로 타입 캐스팅 사용 (권장하지 않음)
// 강제 캐스팅
// Warning- Unchecked cast: FieldValidator<*>? to FieldValidator<String>
val stringValidator = validators[String::class] as FieldValidator<String>
println(stringValidator.validate("aa")) // true
println(stringValidator.validate("")) // false
위와 같이 하면 타입 캐스팅 부분에서 실패하지 않고 값을 검증하는 메서드 안에서 실패하게 된다.
실행 시점에 모든 제네릭 타입 정보는 사라지므로 타입 캐스팅은 문제가 없지만 검증 메서드 안에서 문제가 발생한다.
명시적으로 타입 캐스팅 시 검증기를 잘못 가져온 경우
// 검증기를 잘못 가져왔지만 컴파일과 타입 캐스팅 시엔 아무런 문제가 발생하지 않음
val stringValidator2 = validators[Int::class] as FieldValidator<String>
// 런타임 오류
// class java.lang.String cannot be cast to class java.lang.Number
println(stringValidator2.validate(""))
위처럼 명시적으로 강제 캐스팅을 하는 방법은 타입 안전성을 보장할 수도 없고, 실수도 하기 쉽다.
한 변수에 여러 타입의 검증기를 보관할 다른 방법을 찾아야 한다.
아래는 똑같이 validators Map 을 사용하지만 검증기를 등록하거나 가져오는 작업을 할 때 타입을 제대로 검사할 수 있도록 캡슐화한다.
위의 코드처럼 안전하지 않은 캐스팅 as 오류를 발생시키지만 Validators 객체가 Map 에 대한 접근을 통제하기 때문에 Map 에 잘못된 값이 들어가지 못하게 제어할 수 있다.
검증기 컬렉션에 대한 접근 캡슐화 (타입 안전성 보장)
package com.assu.study.kotlin2me.chap09
import kotlin.reflect.KClass
// T 에 대해 반공변인 인터페이스 정의
interface FieldValidator2<in T> {
// T 를 in 위치에서만 사용 (이 메서드는 T 타입의 값은 소비함)
fun validate(input: T): Boolean
}
object DefaultStringValidator2 : FieldValidator2<String> {
override fun validate(input: String): Boolean = input.isNotEmpty()
}
object DefaultIntValidator2 : FieldValidator2<Int> {
override fun validate(input: Int): Boolean = input >= 0
}
object Validators {
// 외부에서 이 Map 에 접근할 수 없음
private val validators = mutableMapOf<KClass<*>, FieldValidator2<*>>()
fun <T : Any> registerValidator(
kClass: KClass<T>,
fieldValidator2: FieldValidator2<T>,
) {
// 어떤 클래스와 검증기가 타입이 맞아 떨어지는 경우에만 그 클래스와 검증기 정보를 Map 에 넣음
validators[kClass] = fieldValidator2
}
// FieldValidator2<T> 캐스팅이 안전하지 않다는 경고를 무시하게 함
@Suppress("UNCHECKED_CAST")
operator fun <T : Any> get(kClass: KClass<T>): FieldValidator2<T> =
validators[kClass] as? FieldValidator2<T>
?: throw IllegalArgumentException("No Validator for ${kClass.simpleName}")
}
fun main() {
Validators.registerValidator(String::class, DefaultStringValidator2)
Validators.registerValidator(Int::class, DefaultIntValidator2)
// 컴파일 오류
// Type mismatch.
// Required:String
// Found:Int
// Validators.registerValidator(Int::class, DefaultStringValidator2)
println(Validators[String::class].validate("aaa")) // true
println(Validators[String::class].validate("")) // false
println(Validators[Int::class].validate(3)) // true
// 컴파일 오류
// Type mismatch.
// Required:Int
// Found:String
// println(Validators[Int::class].validate("bb"))
}
위 코드에서 안전하지 못한 모든 로직은 클래스 내부로 숨기고, 이렇게 안전하지 못한 부분을 숨김으로써 이제 외부에서 그 부분을 잘못 사용하지 않음을 보장할 수 있다.
이런 패턴은 모든 커스텀 제네릭 클래스를 저장할 때 사용할 수 있다.
안전하지 못한 코드를 별도로 분리하면 그 코드를 잘못 사용하지 못하게 방지할 수 있고, 안전하게 컨테이너를 사용하게 만들 수 있다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 브루스 에켈, 스베트라나 이사코바 저자의 아토믹 코틀린 과 드미트리 제메로프, 스베트라나 이사코바 저자의 Kotlin In Action 을 기반으로 스터디하며 정리한 내용들입니다.
- 아토믹 코틀린
- 아토믹 코틀린 예제 코드
- Kotlin In Action
- Kotlin In Action 예제 코드
- Kotlin Github
- 코틀린 doc
- 코틀린 lib doc
- 코틀린 스타일 가이드
