Kafka - 카프카 브로커 설치, 브로커 설정
이 포스트에서는 카프카 설치, 설정 및 카프카를 실행하는데 적합한 하드웨어를 선택하는 방법과 프로덕션 작업을 카프카로 옮길 때 고려할 사항들에 대해 알아본다.
- 카프카 브로커 설치
- 브로커의 메타데이터를 저장하기 위해 사용되는 아파키 주키퍼 설치
- 브로커를 실행하는데 적합한 하드웨어 선택 기준
- 여러 개의 카프카 브로커를 하나의 클러스터로 구성하는 방법
- 카프카를 프로덕션 환경에서 사용할 때 알아두어야 할 것들
목차
- 1. 환경 설정
- 2. 카프카 브로커 설치
- 3. 브로커 설정
- 4. 하드웨어 선택
- 5. 클라우드에서 카프카 사용
- 6. 카프카 클러스터 설정
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
1. 환경 설정
아파치 카프카는 다양한 운영체제에서 실행 가능한 자바 애플리케이션이다.
주키퍼나 카프카를 설치하기 전에 사용 가능한 자바환경을 먼저 설치해야 한다.
여기선 openjdk 17.0.12 이 설치되어 있다고 가정한다.
1.1. 주키퍼 설치
아파치 주키퍼는 분산 환경 운영 지원 서비스를 제공하는 코디네이션 엔진으로 카프카 클러스터의 메타데이터와 컨슈머 클러스터에 대한 정보를 저장하기 위해 사용되며, 설정 정보 관리, 이름 부여, 분산 동기화, 그룹 서비스를 제공하는 중앙화된 서비스이다.
분산 애플리케이션 구현 시 각 분산 노드 설정 등의 작업을 제공하는 중앙 집중식 코디네이션 서비스로 간단한 인터페이스를 제공한다.
<주키퍼의 주요 특징>
- 높은 처리량/낮은 대기시간
- 주키퍼가 관리하는 데이터는 스토리지가 아닌 메모리에 보관되므로 높은 처리량과 낮은 지연 제공
- 액세스가 읽기 주체인 경우 특히 고속으로 동작 가능
- 고가용성
- 주키퍼를 여러 서버에 설치하여 사용 가능
- 주키퍼를 여러 개 시작하면 마스터가 자동으로 선택되어 각종 통괄 관리 실행
- 마스터 노드가 중지되면 각 노드 간에 선거가 이루어지고, 새로운 마스터 노드가 선택됨
- 노드 간 불일치 제거
- 데이터 갱신은 마스터 노드만이 실시하므로 노드 간에 데이터가 일치함
카프카 배포판에 포함된 스크립트를 이용하여 주키퍼 서버를 띄울 수도 있고, 주키퍼 배포판 풀버전을 설치할 수도 있다.
이 포스트에선 주키퍼 3.9.2 를 사용한다.
tar -zxvf apache-zookeeper-3.9.2-bin.tar.gz
압축이 해제되면 apache-zookeeper-3.9.2-bin 폴더가 생성된다.
1.1.1. 독립 실행 서버
주키퍼는 기본적인 설정 파일을 제공한다.
$ pwd
/Users/Developer/zookeeper/apache-zookeeper-3.9.2-bin/conf
$ vi zoo_sample.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
각 항목의 상세 항목은 1.1.2. 주키퍼 앙상블 에 나옵니다.
주키퍼 시작
$ pwd
/Users/Developer/zookeeper/apache-zookeeper-3.9.2-bin/conf
$ mv zoo_sample.cfg zoo.cfg
$ pwd
/Users/Developer/zookeeper/apache-zookeeper-3.9.2-bin/bin
$ ./zKServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /Users/Developer/zookeeper/apache-zookeeper-3.9.2-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
이제 독립 실행 모드 주키퍼가 정상 작동하는지 확인해본다.
클라이언트 포트인 2181 로 접속하여 srvr 명령을 실행시키면 작동 중인 서버로부터 기본적인 주키퍼 정보가 리턴된다.
$ telnet localhost 2181
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
srvr
Zookeeper version: 3.9.2-e454e8c7283100c7caec6dcae2bc82aaecb63023, built on 2024-02-12 20:59 UTC
Latency min/avg/max: 0/0.0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 5
Connection closed by foreign host.
주키퍼 정지
$ pwd
/Users/Developer/zookeeper/apache-zookeeper-3.9.2-bin/bin
$ ./zKServer.sh stop
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /Users/Developer/zookeeper/apache-zookeeper-3.9.2-bin/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
1.1.2. 주키퍼 앙상블
주키퍼는 고가용성을 보장하기 위해 앙상블 (ensemble) 이라 불리는 클러스터 단위로 동작하도록 설계되었다.
주키퍼가 사용하는 부하 분산 알고리즘 때문에 앙상블은 홀수 개의 서버를 가지는 것이 권장된다.
주키퍼가 요청에 응답하려면 앙상블 멤버 (쿼럼, Quorum) 의 과반 이상이 작동하고 있어야 하기 때문이다.
예) 5노드 짜리 앙상블의 경우 2대가 정지하더라도 문제없음
주키퍼 앙상블 크기
주키퍼 앙상블을 구성할 때는 5개 노드로 구성하는 것이 좋음
앙상블 설정을 변경하려면 한 번에 한 대의 노드를 정지시켰다가 설정을 변경한 뒤 재시작해야 하는데 만일 앙상블이 2대 이상의 노드 정지를 받아낼 수 없다면 정비 작업 수행 시 리스크가 있음9대 이상의 노드도 권장하지 않는데 합의 (consensus) 프로토콜 특성 상 성능이 저하될 수 있기 때문임
또한 클라이언트 연결이 너무 많아서 5대 혹은 7대의 노드가 부하를 감당하기에 모자라면 옵저버 노드를 추가하여 읽기 전용 트래픽을 분산시키는 것이 좋음
주키퍼 서버를 앙상블로 구성하려면 아래 2가지가 필요하다.
- 각 서버는 공통된 설정 파일을 사용해야 함
- 이 설정 파일에는 앙상블에 포함된 모든 서버의 목록이 포함되ㅣ어 있음
- 각 서버는 데이터 디렉토리에 자신의 ID 번호를 지정하는
myid파일이 있어야 함
3대로 구성된 앙상블에 포함된 서버의 호스트명이 zoo1.example.com, zoo2.example.com, zoo3.example.com 이라면 공통 설정 파일은 아래와 같다.
공통 설정 파일 (/conf/zoo.cfg)
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper
clientPort=2181
server.1=zoo1.example.com:2888:3888
server.2=zoo2.example.com:2888:3888
server.3=zoo3.example.com:2888:3888
위에서 server.1, 2, 3 은 예시이고 로컬에서 테스트할 때는 주석처리해야 함
tickTime- ms 단위의 heartbeat 시간
initLimit- 팔로워가 리더와의 연결할 수 있는 최대 초기화 제한 시간
- 이 시간동안 리더와 연결이 안되면 초기화에 실패
syncLimit- 팔로워가 리더와 연결할 수 있는 최대 동기화 제한 시간
- 이 시간동안 리더와 연결이 안되면 동기화가 풀림
clientPort- 클라이언트의 커넥션을 listen 하는 포트
dataDir- in-memory DB 스냅샷을 저장하기 위한 경로
- DB 갱신 시 작성되는 로그가 저장되는 경로
initLimit, syncLimit 모두 tickTime 단위로 정의되는데 이 설정 파일의 경우 초기화 제한 시간은 20 * 2,000 ms 즉, 40초가 된다.
공통 설정 파일은 앙상블 안의 모든 서버 내역을 정의하는데 server.{x}={hostname}:{peerPort}:{leaderPort} 의 형식이다.
- x
- 서버의 ID
- 정수값이어야 하지만 0부터 시작할 필요는 없고, 순차적으로 부여될 필요도 없음
- hostname
- 서버의 호스트명 또는 IP 주소
- peerPort
- 앙상블 안의 서버들이 서로 통신할 때 사용하는 TCP 포트 번호
- leaderPort
- 리더 선출 시 사용되는 TCP 포트 번호
클라이언트는 공통 설정 파일(zoo.cfg) 내의 clientPort 로 앙상블에 연결할 수만 있으면 되지만, 앙상블 내의 멤버들은 3개의 포트를 사용하여 서로 모두 통신할 수 있어야 한다.
공통 설정 파일 외 각 서버는 dataDir 디렉토리에 myid 라는 파일을 갖고 있어야 하며, 이 파일은 공통 설정 파일에 지정된 것과 일치하는 서버 ID 번호를 포함해야 한다.
2. 카프카 브로커 설치
java 와 주키퍼 설정이 끝나면 아파치 카프카를 설치할 수 있다.
이 포스트에선 3.8.0 버전을 설치한다.
카프카는 여기에서 source 타입이 아닌 binary 타입으로 다운로드 받는다.
$ pwd
/Users/Developer/kafka
$ tar -zxvf kafka_2.13-3.8.0.tgz
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0
# 메시지 로그 세그먼트는 kafka-logs 에 저장
$ mkdir tmp
$ cd mkdir tmp
$mkdir kafka-logs
카프카 브로커 시작
$ pwd
/Users/Developer/kafka
$ kafka_2.13-3.8.0/bin/kafka-server-start.sh -daemon \
kafka_2.13-3.8.0/config/server.properties
카프카 브로커가 시작되었으면 클러스터에 토픽 생성, 메시지 쓰기/읽기 등의 명령어를 실행시켜서 동작을 확인해보자.
1. 토픽 작업:
kafka-topics.sh와 함께 보면 도움이 됩니다.
토픽 생성
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0
$ kafka_2.13-3.8.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 \
--create --replication-factor 1 --partitions 1 --topic test
Created topic test.
WARN [AdminClient clientId=adminclient-1] Connection to node -1 (localhost/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)이런 오류가 발생한다면 Kafka - could not be established. Broker may not be available. 를 참고하세요.
토픽 조회
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
test
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic test
[2024-08-10 20:46:19,573] WARN [AdminClient clientId=adminclient-1] The DescribeTopicPartitions API is not supported, using Metadata API to describe topics. (org.apache.kafka.clients.admin.KafkaAdminClient)
Topic: test TopicId: XiG6Yf9mQXO4waWr0Rbsow PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Elr: N/A LastKnownElr: N/A
토픽에 메시지 쓰기
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 \
localhost:9092 --topic test
>Test message 01
>Test message 02
>^C%
토픽에서 메시지 읽기
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0
$ bin/kafka-console-consumer.sh --bootstrap-server \
localhost:9092 --topic test --from-beginning
Test message 01
Test message 02
^CProcessed a total of 2 messages
토픽 삭제
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0
$ bin/kafka-topics.sh --delete --topic test --bootstrap-server localhost:9092
# 토픽 삭제 확인
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
__consumer_offsets
카프카 CLI 유틸리티에서 주키퍼 연결 시
--bootstrap-server를 사용하여 카프카 브로커에 연결
만일 클러스터를 이미 운영중이라면 클러스터에 속한 특정 브로커의 {hostname}:{port} 를 사용해도 됨
3. 브로커 설정
Kafka 3.3.0 부터 추가된
KRaft모드 설정에 관한 내용은 2. 컨트롤러 를 참고하세요.
3. 브로커 설정 에서 설명하는 옵션들은 kafka_2.13-3.8.0/config/server.properties 파일 안에 있는 설정 옵션들임
카프카에는 거의 모든 구성을 제어하고 튜닝할 수 있는 많은 설정 옵션이 있다.
이들 대부분은 특정한 활용 사례가 아닌 한 바꿀 일이 없는 튜닝 관련 옵션들이기 때문에 기본값을 그대로 사용해도 상관없다.
3.1. 핵심 브로커 매개변수
브로거 설정 매개변수들 중 대부분은 다른 브로커들과 함께 클러스터 모드로 작동하려면 기본값이 아닌 다른 값으로 변경해주어야 한다.
$ pwd
/Users/Developer/kafka/kafka_2.13-3.8.0/config
$cat server.properties
# 핵심 브로커 매개변수
broker.id=0
advertised.listeners=PLAINTEXT://127.0.0.1:9092
zookeeper.connect=localhost:2181
log.dirs=/tmp/kafka-logs
num.recovery.threads.per.data.dir=1
# 토픽별 기본값
num.partitions=1
log.retention.hours=168
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.check.interval.ms=300000
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
3.1.1. broker.id
모든 카프카 브로커는 정수값의 식별자는 갖는데 이 값은 broker.id 로 설정 가능하다.
이 정수값은 클러스터 안의 각 브로커별로 전부 달라야 한다.
운영 시 브로커 ID 에 해당하는 호스트명을 찾는 것도 부담이 되기 때문에 호스트별로 고정된 값을 사용하는 것이 좋다.
예) 호스트명에 고유한 번포가 포함(host1.test.com) 되어 있다면 broker.id 를 1 로 할당
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
3.1.2. listeners
listeners 설정은 쉼표로 구분된 리스너 이름과 URI 목록이다.
리스너명이 일반적인 보안 프로토콜이 아니라면 반드시 listener.security.protocol.map 설정을 잡아주어야 한다.
리스너는 {protocol}://{hostname}:{port} 의 형태이다.
예) PLAINTEXT://localhost:9092, SSL://:9091
호스트명을 0.0.0.0 으로 잡아줄 경우 모든 네트워크 인터페이스로부터 연결을 받게 되며, 이 값을 비워주면 기본 인터페이스에 대해서만 연결을 받는다.
1024 미만의 포트 번호를 사용할 경우 루트 권한으로 카프카를 실행시켜야 하므로 바람직하지 않다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# The address the socket server listens on. If not configured, the host name will be equal to the value of
# java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://your.host.name:9092
advertised.listeners=PLAINTEXT://127.0.0.1:9092
3.1.3. zookeeper.connect
브로커의 메타데이터가 저장되는 주키퍼의 위치로 로컬 호스트의 2181번 포트에서 작동 중인 주키퍼를 사용할 경우 localhost:2181 로 설정하면 된다.
세미콜론으로 연결된 {hostname}:{port}/{path} 의 목록 형식으로 지정할 수도 있다.
- hostname
- 주키퍼 서버의 호스트명이나 IP 주소
- port
- 주키퍼의 클라이언트 포트 번호
- path
- 선택 사항
- 카프카 클러스터의 chroot 환경으로 사용될 주키퍼의 경로
- 지정하지 않으면 루트 디렉토리가 사용됨
만일 chroot 경로 (= 주어진 애플리케이션에 대해 루트 디렉토리로 사용되는 경로) 가 존재하지 않는 경로로 지정될 경우 브로커가 시작될 때 자동으로 생성된다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
chroot경로는 사용하는 이유다른 카프카 클러스터를 포함한 애플리케이션과 충돌할 일 없이 주키퍼 앙상블을 공유해서 사용할 수 있기 때문에 대체로 카프카 클러스터에는 chroot 경로를 사용하는 것이 좋음
또한 특정 서버에 장애가 생기더라도 카프카 브로커가 같은 주키퍼 앙상블의 다른 서버에 연결할 수 있도록 같은 앙상블에 속하는 다수의 주키퍼 서버를 지정하는 것이 좋음
3.1.4. log.dirs
카프카는 모든 메시지를 로그 세그먼트 단위로 묶어서 log.dir 설정에 지정된 디렉터리에 저장한다.
여러 개의 디렉터리를 지정할 경우 log.dirs 를 사용하며, log.dirs 가 설정되어 있지 않을 경우 log.dir 이 사용된다.
log.dirs 는 쉼표로 구분된 디렉터리 목록이다.
1개 이상의 경로가 지정되었을 경우 브로커는 가장 적은 수의 파티션이 저장된 디렉터리에 새 파티션을 저장한다.
(같은 파티션에 속하는 로그 세그먼트는 동일한 경로에 저장)
사용된 디스크 용량 기준이 아닌 저장된 파티션 수를 기준으로 새 파티션의 저장 위치를 배정한다는 점에 유의해야 한다.
이러한 이유 때문에 다수의 디렉터리에 대해 균등한 양의 데이터가 저장되지 않는다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
3.1.5. num.recovery.thread.per.data.dir
카프카는 설정 가능한 스레드 풀을 사용하여 로그 세그먼트를 관리한다.
이 스레드 풀은 아래와 같은 작업을 수행한다.
- 브로커가 정상적으로 시작되었을 때 각 파티션의 로그 세그먼트 파일을 엶
- 브로커가 장애 발생 후 재시작되었을 때 각 파티션의 로그 세그먼트를 검사하고 잘못된 부분은 삭제
- 브로커가 종료할 때 로그 세그먼트를 정상적으로 닫음
기본적으로 하나의 로그 디렉토리에 대해 하나의 스레드만이 사용된다.
이 스레드들은 브로커가 시작/종료될 때만 사용되기 때문에 작업 병렬화를 위해 많은 수의 스레드를 할당해주는 것이 좋다.
특히 브로커에 많은 파티션이 저장되어 있는 경우 이 설정에 따라 언클린 셧다운 이후 복구를 위한 재시작 시간이 몇 시간씩 차이가 날 수도 있다.
언클린 셧다운 (unclean shutdown)
서버가 정상적으로 종료되지 않아 프로세스를 잡고 있는 경우
이 설정값은 log.dirs 에 지정된 로그 디렉터리별 스레드 수이다.
예) num.recovery.threads.per.data.dir 이 8 이고, log.dirs 에 지정된 경로수가 3개일 경우 전체 스레드 수는 24개이다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
3.1.6. auto.create.topics.enable
카프카 기본 설정에는 아래와 같은 상황에서 브로커가 토픽을 자동으로 생성하도록 되어있다.
- 프로듀서가 토픽에 메시지를 쓰기 시작할 때
- 컨슈머가 토픽응로부터 메시지를 읽기 시작할 때
- 클라이언트가 토픽에 대한 메타데이터를 요청할 때
하지만 카프카에 토픽을 생성하지 않고 존재 여부만 확인할 방법이 없다는 점에서 auto.create.topics.enable 를 true 로 설정하는 것은 바람직하지 않다.
토픽 생성을 명시적으로 관리하고자 할 경우 auto.create.topics.enable 을 false 로 설정하자.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
3.1.7. auto.leader.rebalance.enable
모든 토픽의 리더 역할이 하나의 브로커에 집중됨으로써 카프카 틀러스터의 균형이 깨지는 경우가 있다.
auto.leader.rebalance.enable 을 활성화해주면 한 리더 역할이 균등하게 분산된다.
해당 설정을 활성화하면 파티션의 분포 상태를 주기적으로 확인하는 백그라운드 스레드가 시작되며, 이 주기는 leader.imbalance.check.interval.seconds 로 설정 가능하다.
전체 파티션 중 특정 브로커에 리더 역할이 할당된 파티션의 비율이 leader.imbalnace.per.broker.percentage 에 설정된 값을 넘어가면 파티션의 선호 리더 (preferred leader) 리밸런싱이 발생한다.
파티션의 선호 리더의 좀 더 상세한 내용은
3.3. 리더 선출:elecLeader(),
3.3. 선호 리더(Preferred leader) 를 참고하세요.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
3.1.8. delete.topic.enable
데이터 보존 가이드라인에 따라 클러스터의 토픽을 임의로 삭제하지 못하게 할 때 해당 설정값을 false 로 설정하면 토픽 삭제 기능이 막힌다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
3.2. 토픽별 기본값
카프카 브로커 설정 중 새로 생성되는 토픽에 적용되는 기본값도 있다.
이 매개변수 중 일부 (파티션 수나 메시지 보존 등) 는 관리용 툴을 사용하여 토픽 단위로 설정이 가능하다.
관리용 툴에 대한 내용은
Kafka - 운영(1): 토픽 작업, 컨슈머 그룹 작업, 동적 설정 변경,
Kafka - 운영(2): 파티션 관리
를 참고하세요.
토픽 단위 설정값 재정의 사용
카프카 구버전에서는
log.retention.{hours | bytes}.per.topic,log.segment.bytes.per.topic과 같은 매개변수를 사용하여 토픽별로 설정 가능했음이제 이러한 매개 변수들은 더 이상 지원되지 않으며, 토픽별 설정값을 재정의하려면 관리툴을 사용해야 함
3.2.1. num.partitions
새로운 토픽이 생성될 때 몇 개의 파티션을 갖게되는지 결정하며, 주로 자동 토픽 생성 기능 (auto.create.topics.enable) 이 활성화되어 있을 때 (= 기본값) 사용된다.
토픽의 파티션 개수는 늘릴수만 있지 줄일 수는 없다는 점에 유의해야 한다.
즉, 만일 토픽이 num.partitions 에 지정된 것보다 더 적은 수의 파티션을 가져야 한다면 직접 토픽을 생성해야 한다.
위 내용에 대한 상세한 내용은 1.5. 파티션 개수 줄이기 를 참고하세요.
파티션은 카프카 클러스터 안에서 토픽의 크기가 확장되는 방법이기도 하므로 브로커가 추가될 때 클러스터 전체에 걸쳐 메시지 부하가 고르게 분산되도록 파티션 개수를 잡아주는 것이 중요하다.
위 내용은 2.3. 토픽, 파티션, 스트림, 레플리카 을 참고하세요.
대부분 토픽 당 파티션 개수를 클러스터 내의 브로커의 수와 맞추거나 아니면 배수로 설정한다.
그러면 파티션이 브로커들 사이에 고르게 분산되도록 할 수 있으며, 결과적으로 메시지 부하 역시 고르게 분산된다.
예) 10개의 파티션으로 이루어진 토픽이 10개의 호스트로 구성된 카프카 클러스터에서 작동중이고, 각 파티션의 리더 역할이 이 10개의 호스트에 고르게 분산되어 있다면 최적의 처리량이 나옴
파티션이 너무 많아도 성능에 이슈가 발생할 수 있다.
위 내용은 3.2.2. 파티션 개수를 정할 때 고려할 사항 을 참고하세요.
토픽의 목표 처리량과 컨슈머의 예상 처리량에 대해 어느 정도 추정값이 있다면 토픽의 목표 처리량 / 컨슈머의 예상 처리량 으로 필요한 파티션 수를 계산할 수 있다.
예) 주어진 토픽에 초당 1GB 를 읽거나 쓰고자 하고, 컨슈머 하나는 초당 50MB 만 처리가 가능하다고 하면
최소한 1GB / 50MB = 20, 즉, 20개의 컨슈머가 동시에 하나의 토픽을 읽게 함으로써 초당 1GB 를 읽을 수 있음
만일 이러한 정보가 없다면 매일 디스크 안에 저장되어 있는 파티션의 용량을 6GB 미만으로 유지하는 것을 권장하나다.
일단 작은 크기로 시작해서 나중에 필요할 때 확장하는 것이 처음부터 너무 크게 시작하는 것보다 쉽다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
3.2.2. 파티션 개수를 정할 때 고려할 사항
- 토픽의 목표 처리량
- 예) 쓰기 속도가 초당 100KB 이어야 하는지, 1GB 이어야 하는지?
- 단일 파티션에 대해 달성하고자 하는 최대 읽기 처리량
- 하나의 파티션은 항상 하나의 컨슈머만 읽을 수 있음 (컨슈머 그룹 기능을 사용하지 않더라도 컨슈머는 해당 파티션의 모든 메시지를 읽도록 되어 있음)
- 만일 컨슈머 애플리케이션이 DB 에 데이터를 쓰는데 이 DB 의 쓰기 스레드 각각이 초당 50MB 이상 처리할 수 없다면 하나의 파티션에서 읽어올 수 있는 속도는 초당 50MB 로 제한됨
- 각 프로듀서가 단일 파티션에 쓸 수 있는 최대 속도
- 위의 단일 파티션에 대해 달성하고자 하는 최대 읽기 처리량 과 비슷한 추정을 할 수 있지만 보통 프로듀서는 컨슈머에 비해 훨씬 더 빠르므로 생략해도 좋음
만일 key 값을 기준으로 선택된 파티션에 메시지를 전송하고 있을 경우 나중에 파티션 추가 시 매우 복잡하므로 현재 사용량이 아닌 미래의 사용량 예측값을 기준으로 처리량을 계산해야 한다.
- 각 브로커에 배치할 파티션 수 뿐 아니라 브로커별로 사용 가능한 디스크 공간, 네트워크 대역폭도 고려
- 과대 예측은 피할 것
- 각 파티션은 브로커의 메모리와 다른 자원들을 사용할 뿐 아니라 메타데이터 업데이트나 리더 역할 변경에 걸리는 시간 역시 증가시킴
- 데이터 미러링 여부
- 데이터 미러링을 사용할 예정이라면 미러링 설정의 처리량도 고려해야 함
- 미러링 구성에서 큰 파티션이 병목이 되는 경우가 많음
- 클라우드 서비스 사용 시 가상 머신이나 디스크에 초당 입출력(IOPS, Input/output Operations Per Seconds) 제한이 걸려있는지 확인
- 사용중인 클라우드 서비스나 가상 머신 설정에 따라 허용되는 IOPS 상한선이 설정되어 있을 수 있음
- 파티션 수가 너무 많으면 병렬 처리 때문에 IOPS 양이 증가할 수 있음
3.2.3. default.replication.factor
auto.create.topics.enable (자동 토픽 생성 기능) 이 활성화되어 있을 경우 이 설정은 새로 생성되는 토픽의 복제 팩터를 결정한다.
아래는 하드웨어 장애와 같은 카프카 외부 요인으로 인한 장애가 발생하지 않아야 하는 카프카 클러스터는 운영하는 상황에서의 대략적인 권장사항이다.
- 복제 팩터값은
min.insync.replicas설정값보다 최소한 1 이상 크게 잡아줄 것- 좀 더 내고장성 (fault tolerance) 이 있는 설정을 위해서는
min.insync.replicas설정값보다 2 큰 값으로 복제 팩터를 설정하는 것이 좋음 (이것을 보통RF++라고 줄여씀) - 이유는 레플리카 set 안에 일부러 정지시킨 레플리카와 예상치 않게 정지된 레플리카가 동시에 하나씩 발생해도 장애가 발생하지 않기 때문임
- 즉, 일반적인 클러스터의 경우 파티션 별로 최소한 3개의 레플리카를 가져야 한다는 의미임
예) 디스크 장애가 발생하거나 카프카 혹은 운영체제를 롤링 업데이트 하는 와중에 예기치 못한 문제가 발생할 경우에도 적어도 1개의 레플리카는 여전시 정상 작동 중이라는 걸 보장함 위 부분에 대한 좀 더 상세한 내용은 3.3. 최소 ISR(In-Sync Replica):
min.insync.replicas를 참고하세요.
- 좀 더 내고장성 (fault tolerance) 이 있는 설정을 위해서는
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
3.2.4. log.retention.{hours | minutes | ms}
카프카의 메시지 보존 기간을 지정할 때 가장 많이 사용되는 설정이 시간 기준 보존 주기 설정이며, 메시지가 만료되어 삭제되기 시작할 때까지 걸리는 시간을 지정한다. (= 시간 기준 보존 설정에 의해 닫힌 로그 세그먼트가 보존되는 기한)
hours, minutes, ms 모두 동일한 역할을 하지만 1개 이상의 설정이 정의되었을 경우 더 작은 단위의 설정값이 우선권을 가지므로 log.retention.ms 를 사용하는 것을 권장한다.
시간 기준 보존과 마지막 수정 시각
시간 기준 보존은 디스크에 저장된 각 로그 세그먼트 파일의 마지막 수정 시각(minute) 을 기준으로 동작함
정상적으로 작동 중이라는 가정 하에 이 값은 해당 로그 세그먼트가 닫힌 시각이며, 해당 파일에 저장된 마지막 메시지의 타임스탬프이기도 함
하지만 관리툴을 사용하여 브로커 간에 파티션을 이동시켰을 경우 이 값은 정확하지 않으며 해당 파티션이 지나치게 오래 보존되는 결과를 초래할 수 있음위 내용의 좀 더 상세한 내용은 Kafka - 운영(2): 파티션 관리 를 참고하세요.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
3.2.5. log.retention.bytes
메시지 만료의 또 다른 기준인 보존되는 메시지의 용량으로 파티션 단위로 적용된다.
만일 8개의 파티션을 가진 토픽에 log.retention.bytes 가 1GB 로 설정되어 있다면 토픽의 최대 저장 용량은 8GB 이다.
모든 보존 기능은 토픽 단위가 아닌 파티션 단위로 동작한다.
따라서 log.retention.bytes 설정을 사용중인 상태에서 토픽의 파티션 수를 증가시키면 보존되는 데이터의 양도 함께 늘어난다.
log.retention.bytes 를 -1 로 설정하면 데이터가 영구 보존된다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
3.2.6. 크기와 시간을 기준으로 메시지 보존 설정
log.retention.bytes 와 log.retention.ms 를 동시에 설정한다면 두 조건 중 하나만 성립해도 메시지가 삭제된다.
따라서 의도치않은 데이터 유실 방지를 위해 둘 중 하나만 설정하는 것이 좋다.
3.2.7. log.segment.bytes
로그 보존 설정은 메시지 각각이 아닌 로그 세그먼트에 적용된다.
카프카 브로커에 쓰여진 메시지는 해당 파티션의 현재 로그세그먼트 끝에 추가되는데, 로그 세그먼트의 크기가 log.segment.bytes 에 지정된 크기에 다다르면 브로커는 기존 로그 세그먼트를 닫고 새로운 세그먼트를 연다.
로그 세그먼트는 닫히기 전까지는 만료와 삭제의 대상이 되지 않는다.
(= 작은 로그 세그먼트의 크기는 파일을 더 자주 닫고 새로 할당하므로 디스크 쓰기의 효율성을 감소시킴)
토픽에 메시지가 뜸하게 주어지는 상황에서는 로그 세그먼트의 크기를 조절해주는 것이 중요하다.
예를 들어 토픽에 들어오는 메시지가 하루에 100MB 인 상황에서 log.segment.bytes 가 기본값인 1GB 로 잡혀있다면 세그먼트 하나를 채울 때까지 10일이 걸린다.
로그 세그먼트가 닫히기 전까진 메시지는 만료되지 않으므로 log.retiontions.ms 가 604,800,000 (7일) 로 잡혀있을 경우 닫힌 로그 세그먼트가 만료될 때까지 실제로는 최대 17일치의 메시지가 저장될 수도 있다. (로그 세그먼트가 닫히는 데 10일, 시간 기준 보존 설정 때문에 닫힌 세그먼트가 보존되는 기간 7일)
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정값
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=1073741824
timestamp 기준으로 오프셋 찾기
로그 세그먼트의 크기는 timestamp 기준으로 오프셋을 찾는 기능에도 영향을 미침
클라이언트가 특정 timestamp 를 기준으로 파티션의 오프셋을 요청하면 카프카는 해당 시각에 쓰여진 로그 세그먼트를 찾음
이 작업은 로그 세그먼트 파일의 생성 시각과 마지막 수정 시각을 이용하여 이루어짐
(= 즉, 주어진 timestamp 보다 생성된 시간은 더 이르고 마지막으로 수정된 시각은 더 늦은 파일을 찾음)
로그 세그먼트의 맨 앞에 있는 오프셋(= 로그 세그먼트 파일명)이 응답으로 리턴됨
3.2.8. log.roll.ms
log.segment.bytes 외에 로그 세그먼트 파일이 닫히는 시점을 제어하는 또 다른 방법은 파일이 닫혀야 할 때까지 기다리는 시간을 지정하는 것이다.
log.retention.bytes 와 log.retention.ms 처럼 log.segment.bytes 와 log.roll.ms 도 상호 배타적인 속성이 아니다.
카프카는 크기 제한이든 시간 제한이든 하나라도 도달할 경우 로그 세그먼트를 닫는다.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
시간 기준 로그 세그먼트 사용 시 디스크 성능
시간 기준 로그 세그먼트 제한은 브로커가 시작되는 시점부터 계산되기 때문에 크기가 작은 파티션을 닫는 작업 역시 한꺼번에 이루어지므로 시간 기준 로그 세그먼트 제한을 사용할 경우에는 다수의 로그 세그먼트가 동시에 닫힐 때의 디스크 성능에 대한 영향을 고려해야 함
이런 상황은 여러 개의 파티션이 로그 세그먼트 크기 제한에 도달하지 못하는 경우에 발생할 수 있음
3.2.9. min.insync.replicas
데이터 지속성 위주로 클러스터를 설정할 때 min.insync.replicas 를 2로 잡아주면 최소한 2개의 레플리카가 최신 상태로 프로듀서와 동기화되도록 할 수 있다.
이것은 프로듀서의 ack 설정을 all 로 잡아주는 것과 함께 사용된다.
이렇게 하면 최소 2개의 레플리카(= 리더 1, 팔로워 중 1) 가 응답해야만 프로듀서의 쓰기 작업이 성공하므로 아래와 같은 상황에서 데이터 유실을 방지할 수 있다.
리더가 쓰기 작업에 응답 → 리더에 장애가 발생 → 리더 역할이 최근의 성공한 쓰기 작업 내역을 복제하기 전의 다른 레플리카로 옮겨짐
만일 이런 설정이 되어 있지 않을 경우 프로듀서는 쓰기 작업이 성공했다고 판단하지만 실제로는 메시지가 유실되는 상황이 발생할 수 있다.
지속성을 높이기 위해 min.insync.replicas 값을 크게 잡으면 추가적인 오버헤드가 발생하여 성능이 떨어지므로, 어느 정도의 메시지 유실 정도는 상관없고 높은 처리량을 받아내야 하는 클러스터의 경우 이 설정값을 기본값인 1 로 유지하는 것을 권장한다.
위 내용에 대한 좀 더 상세한 설명은 3.3. 최소 ISR(In-Sync Replica):
min.insync.replicas을 참고하세요.
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
3.2.10. message.max.bytes
카프카 브로커는 쓸 수 있는 메시지의 최대 크기를 제한하는데 기본값은 1,000,000 (1GB) 이다.
프로듀서가 이 값보다 더 큰 크기의 메시지를 보내려고 시도하면 브로커는 메시지를 거부하고 에러를 리턴한다.
브로커에 설정된 모든 바이트 크기와 마찬가지로, 이 설정 역시 압축된 메시지의 크기를 기준으로 한다.
즉, 프로듀서는 압축된 결과물이 message.max.bytes 보다 작기만 하면 압축 전 기준으로는 이 값보다 훨씬 큰 메시지를 보낼 수 있다.
메시지가 커지는 만큼 네트워크 연결과 요청을 처리하는 브로커 스레드의 요청 당 작업 시간도 증가하고, 디스크에 써야하는 크기 역시 증가하므로 I/O 처리량에 영향을 미친다.
해당 값은 프로듀서의
max.request.size와 맞춰주는 것이 좋은데 이 부분은 4.9.max.request.size를 참고하세요.
메시지 크기 설정 조정
카프카 브로커에 설정되는 메시지 크기는 컨슈머 클라이언트의
fetch.message.bytes설정과 맞아야 함
만일fetch.message.bytes가message.max.bytes보다 작을 경우 컨슈머는fetch.message.bytes에 지정된 것보다 더 큰 메시지를 읽는 데 실패하면서 읽기 작업 진행이 멈출 수 있음이 내용은 클러스터 브로커의
replica.fetch.max.bytes설정에도 똑같이 적용됨
/Users/Developer/kafka/kafka_2.13-3.8.0/config/server.properties 기본 설정에 없음
4. 하드웨어 선택
카프카 브로커의 성능을 고려하여 하드웨어 선택 시 디스크 처리량, 디스크 용량, 메모리, 네트워크, CPU 를 고려해야 한다.
카프카를 매우 크게 확장할 경우 업데이트되어야 하는 메타데이터 양 때문에 하나의 브로커가 처리할 수 있는 파티션의 수에도 제한이 생길 수 있다.
4.1. 디스크 처리량
로그 세그먼트를 저장하는 브로커 디스크의 처리량은 프로듀서 클라이언트의 성능에 가장 큰 영향을 미친다.
카프카에 메시지를 쓸 때 메시지는 브로커의 로컬 저장소에 커밋되어야 하며, 대부분의 프로듀서 클라이언트는 메시지 전송이 성공했다고 결론을 내리기 전에 최소한 1개 이상의 브로커가 메시지가 커밋되었다고 응답을 보낼 때까지 대기하게 된다.
즉, 디스크 쓰기 속도가 빨라진 다는 것은 곧 쓰기 지연이 줄어드는 것이다.
대체로 많은 수의 클라이언트 연결을 받아내야 하는 경우에는 SSD 가 권장되고, 자주 쓸 일이 없는 데이터를 많이 저장해야 하는 클러스터의 경우 HDD 가 권장된다.
4.2. 디스크 용량
필요한 디스크 용량은 특정한 시점에 얼마나 많은 메시지들이 보존되어야 하는지에 따라 결정된다.
만일 브로커가 하루에 1TB 의 트래픽을 받은 것으로 예상되고, 받은 메시지를 1주일간 보존해야 한다면 브로커는 로그 세그먼트를 저장하기 위한 공간이 최소한 7TB 필요하다.
여기에 트래픽 변동이나 증가를 대비한 예비 공간, 저장해야 할 다른 파일도 감안하여 최소 10% 의 오버헤드를 고려해야 한다.
저장 용량은 카프카 클러스터의 크기를 변경하거나 확장 시점을 결정할 때 고려해야 할 요소중 하나이다.
클러스터에 들어오는 전체 트래픽은 토픽별로 다수의 파티션을 잡아줌으로써 클러스터 전체에 균형있게 분산되므로 단일 브로커의 용량이 충분하지 않은 경우 브로커를 추가하여
전체 용량을 증대시킬 수 있다.
필요한 디스크 용량은 클러스터에 설정된 복제 방식에 따라서도 달라질 수 있는데 이에 대한 내용은 3.1. 복제 팩터(레플리카 개수):
replication.factor,default.replication.factor를 참고하세요.
4.3. 메모리
시스템에 페이지 캐시에 저장되어 있는 메시지들을 컨슈커들이 읽어오므로 페이지 캐시로 사용할 수 있는 메모리를 더 할당해주는 것은 컨슈머 클라이언트의 성능을 향상시킬 수 있다.
시스템 메모리의 남는 영역을 페이지 캐시로 사용하여 시스템이 사용중인 로그 세그먼트를 캐시하도록 함으로써 카프카의 성능을 향상시킬 수 있는데 다른 애플리케이션과 함께 카프카를 사용할 경우 케이지 캐시를 나눠서 쓰게 되고 이는 카프카의 컨슈머 성능을 저하시키므로 카프카를 하나의 시스템에서 다른 애플리케이션과 함께 운영하지 않는 것을 권장한다.
4.4. 네트워크
사용 가능한 네크워크 대역폭은 카프카가 처리할 수 있는 트래픽의 최대량을 결정한다.
네트워크는 디스크 용량과 함께 클러스터의 크기를 결정하는 가장 결정적인 요인이다.
문제는 카프카 특유의 네트워크 불균형때문에 복잡해지는데 카프카가 다수의 컨슈머를 동시에 지원하기 때문에 인입되는 네크워크 사용량과 유출되는 사용량 사이에 불균형이 생길 수 밖에 없는 것이다.
예를 들어서 프로듀서는 주어진 토픽에 초당 1MB 를 쓰는데 해당 토픽에 컨슈머가 다수 붙음으로써 유출되는 네트워크 사용량이 훨씬 많아질 수 있다.
다른 작업들, 즉 클러스터 내부에서의 복제나 미러링 역시 요구 조건을 증대시킨다.
클러스터 내부에서의 복제에 대한 내용은 2. 복제 를 참고하세요.
미러링에 대한 내용은
Kafka - 데이터 미러링(1): 다중 클러스터 아키텍처,
Kafka - 데이터 미러링(2): 미러메이커
를 참고하세요.
네트워크 인터페이스가 포화 상태에 빠질 경우 클러스터 내부의 복제 작업이 밀려서 클러스터가 취약한 상태로 빠지는 상태는 드물지 않다.
네트워크 문제가 발생하는 것을 방지하기 위해서는 최소한 10GB 이상을 처리할 수 있는 네트워크 인터페이스 카드 (NIC, Network Interface Card) 를 사용할 것을 권장한다.
4.5. CPU
카프카 클러스터를 매우 크게 확장하지 않는 한 처리 능력은 디스크나 메모리만큼 중요하지 않다.
하지만 브로커의 전체적인 성능에는 어느 정도 영향을 미친다.
이상적으로는 네트워크와 디스크 사용량을 최적화하기 위해 클라이언트가 메시지를 압축해서 보내야하는데 카프카 브로커는 각 메시지의 체크섬을 확인하고 오프셋을 부여하기 위해 모든 메시지 배치의 압축을 해제해야 하기 때문이다.
브로커는 이 작업이 끝난 뒤에야 디스크에 저장하기 위해 메시지를 다시 압축하게 된다.
바로 이 부분이 카프카에서 처리 능력이 가장 중요해지는 순간이다.
5. 클라우드에서 카프카 사용
5.1. MS Azure
디스크를 VM 과 분리하여 관리할 수 있다. (= 저장 장치 선택 시 사용할 VM 을 고려할 필요 없음)
즉, 장비 스펙을 고를 때 데이터를 보존하기 위해 필요한 데이터의 양을 먼저 고려한 뒤 프로듀서에 필요한 성능을 다음으로 고려하는 것이 좋다.
만일 지연이 매우 낮아야 한다면 프리미엄 SSD 가 장착된 I/O 최적화 인스턴스가 필요하다.
그게 아니라면 애저 매니지드 디스크 (Azure Managed Disks) 나 애저 개체 저장소 (Azure Blob Storage) 와 같은 매니지드 저장소 서비스로도 충분하다.
Standard D16s v3 인스턴스가 작은 클러스터용으로 알맞고, 좀 더 고성능 하드웨어와 CPU 가 필요하면 D64s v4 인스턴스가 클러스터의 크기를 확장할 때 더 좋은 성능을 보인다.
임시 디스크를 사용하다가 VM 이 다른 곳으로 이동할 경우 브로커의 모든 데이터가 유실될 위험이 있기 때문에 임시 디스크보다는 애저 매니지드 디스크를 사용할 것을 강력히 권장한다.
5.2. AWS
지연이 매우 낮아야 한다면 로컬 SSD 저장소가 장착된 I/O 최적화 인스턴스가 필요하고, 그게 아니라면 아마존 EBS (Elastic Block Store) 와 같은 임시 저장소만으로도 충분하다.
AWS 에서 가장 일반적으로 사용되는 인스턴스 유형은 m4 혹은 r3 이다.
m4 는 보존 기한은 더 늘려 잡을 수 있지만 EBS 를 쓰는 만큼 디스크 처리량은 줄어든다.
r3 는 로컬 SSD 드라이브를 쓰는 만큼 처리량은 좋지만 보존 가능한 데이터 양에 제한이 걸리게 된다.
둘 다 커버하고 싶으면 i2 혹은 d2 인스턴스 유형을 사용하면 된다.
6. 카프카 클러스터 설정
개발용이나 PoC (Proof of Concept) 용으로는 단일 카프카 브로커도 잘 동작하지만 여러 대의 브로커를 하나의 클러스터로 구성하면 아래와 같은 이점이 있다.
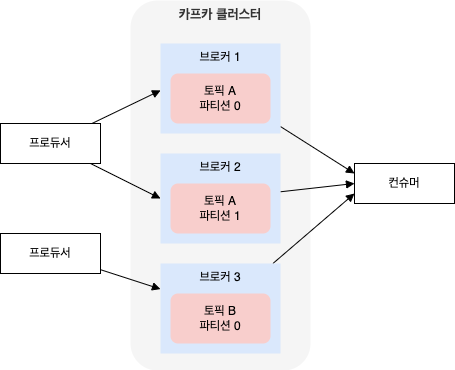
- 부하 분산
- 복제를 사용함으로써 단일 시스템 장애에서 발생할 수 있는 데이터 유실 방지
- 클라이언트 요청을 처리하면서 카프카 클러스터나 그 하단 시스템의 유지 관리 작업 수행 가능
데이터 복제와 지속성에 관한 부분은 3. 신뢰성 있는 브로커 설정 을 참고하세요.
6.1. 브로커 갯수
카프카 클러스터 크기 결정 시 아래와 같은 요소를 고려해야 한다.
- 디스크 용량
- 브로커 당 레플리카용량
- CPU 용량
- 네트워크 용량
6.1.1. 디스크 용량
필요한 메시지를 저장하는데 필요한 디스크 용량과 단일 브로커가 사용할 수 있는 저장소 용량을 생각해보자.
만약 클러스터에 10TB 의 데이터를 저장하고 있어야 하는데 하나의 브로커가 저장할 수 있는 용량이 2TB 라면 클러스터의 최소 크기는 브로커 5 대이다.
만일 복제 팩터를 증가시킬 경우 필요한 저장 용량은 최소 100% 이상 증가하게 된다.
이 경우 레플리카는 하나의 파티션이 복제되는 서로 다른 브로커의 수를 의미한다.
바로 위의 예시처럼 최소 5대의 브로커가 필요한 상황에서 복제 팩터를 2로 잡아주면 최소 10대의 브로커가 필요하다.
복제 팩터 증가에 대한 부분은 3.1. 복제 팩터(레플리카 개수):
replication.factor,default.replication.factor를 참고하세요.
6.1.2. 브로커 당 레플리카 용량
10개의 브로커를 가진 카프카 클러스터가 있는데 레플리카수는 백만 개(= 즉, 복제 팩터가 2인 파티션이 50만개)가 넘는 다면 분산이 매우 이상적으로 된 상황을 가정하더라도 각 브로커가 대략 10개의 레플리카를 보유하게 된다.
이것은 쓰기, 읽기, 컨트롤러 큐 전체에 걸쳐 병목 현상을 발생시킬 수 있다.
파티션 레플리카개수는 브로커 당 14,000 개, 클러스터 당 100만개 이하로 유지할 것을 권장한다.
6.1.3. CPU 용량
CPU 는 대게 주요한 병목 지점이 되지 않지만 브로커 하나에 감당할 수 없는 수준의 클라이언트 연결이나 요청이 들어오면 그렇게 될 수 있다.
6.1.4. 네크워크 용량
네트워크 용량은 아래의 내용을 고려하면 좋다.
- 네트워크 인터페이스의 전체 용량이 얼마인지?
- 데이터를 읽어가는 컨슈머가 여럿이거나, 데이터가 보존되는 동안 트래픽이 일정하지 않을 경우에도 클라이언트 트래픽을 받아낼 수 있는지?
- 예) 피크 시간대에 단일 브로커에 대해 네트워크 인터페이스 전체 용량의 80% 정도가 사용되고, 이 데이터를 읽어가는 컨슈머가 2개라면 2대 이상의 브로커가 있지 않는 한 컨슈머는 피크 시간대 처리량을 제대로 받아낼 수 없음
- 클러스터에 복제 기능이 설정되어 있다면 이 또한 추가로 고려해야 할 데이터 컨슈머가 됨
- 디스크 처리량이나 시스템 메모리가 부족하여 발생하는 성능 문제를 해결하려면 클러스터에 브로커를 추가 투입하여 확장해주어야 함
- 예) 피크 시간대에 단일 브로커에 대해 네트워크 인터페이스 전체 용량의 80% 정도가 사용되고, 이 데이터를 읽어가는 컨슈머가 2개라면 2대 이상의 브로커가 있지 않는 한 컨슈머는 피크 시간대 처리량을 제대로 받아낼 수 없음
6.2. 브로커 설정
여러 개의 카프카 브로커를 하나의 클러스터로 구성할 때는 아래 2가지를 설정해주면 된다.
- 모든 브로커들이 동일한
zookeeper.connect설정값을 가져야 함- 이 설정값은 클러스터가 메타데이터를 저장하는 주키퍼 앙상블과 경로를 지정함
- 클러스터 안의 모든 브로커가 유일한
broker.id설정값을 가져야 함- 만일 동일한
broker.id를 가지는 2개의 브로커가 같은 클러스터에 들어오려고 하면 늦게 들어온 쪽에 에러가 났다는 로그가 찍히면서 실행 실패함
- 만일 동일한
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
- 카프카 핵심 가이드
- 예제 코드 & 오탈자
- Kafka Doc
- Git:: Kafka
- Apache Kafka Zookeeper 제거 이유
- Zookeeper 없이 Kafka 시작하기
- zookeeper download
- kafka download
