Kafka - 프로듀서(1): 프로듀서 생성, 프로듀서 설정
이 포스트에서는 카프카에 메시지를 쓰기 위한 클라이언트에 대해 알아본다.
- 프로듀서의 주요 요소
KafkaProducer,ProducerRecord객체 생성법과 카프카에 레코드 전송법- 카프카가 리턴하는 에러에 대한 처리
- 프로듀서 설정 옵션들
카프카를 큐로 사용하든, 메시지 버스로 사용하든, 데이터 저장 플랫폼으로 사용하든 카프카를 사용할 때는 카프카에 데이터를 쓸 때 사용하는 프로듀서와 데이터를 읽어올 때 사용하는 컨슈머, 혹은 두 가지 기능 모두를 수행하는 애플리케이션을 생성해야 한다.
서드 파티 클라이언트
카프카는 정식 배포판과 함께 제공되는 공식 클라이언트 외에 공식 클라이언트가 사용하는 TCP/IP 패킷의 명세를 공개하고 있음
이를 사용하면 java 외 언어로도 쉽게 Kafka 를 사용하는 애플리케이션 개발이 가능이 클라이언트들은 아파치 카프카 프로젝트 위키 에서 확인 가능함
TCP 패킷의 명세는 아파치 카프카 프로토콜 에서 확인 가능함
소스는 github 에 있습니다.
목차
- 1. 프로듀서
- 2. 프로듀서 생성
- 3. 카프카로 메시지 전달
- 4. 프로듀서 설정
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
pom.xml (parent)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<packaging>pom</packaging>
<modules>
<module>chap03</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.assu.study</groupId>
<artifactId>kafka_me</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka_me</name>
<description>kafka_me</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
pom.xml (chap03)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.assu.study</groupId>
<artifactId>kafka_me</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>chap03</artifactId>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<kafka.version>3.8.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
1. 프로듀서
애플리케이션이 카프카에 메시지를 써야하는 상황은 다양하다.
- 다른 애플리케이션과의 비동기적 통신 수행
- 데이터를 DB 에 저장하기 전 버퍼링
- 로그 메시지 저장
- 감사, 분석을 위한 사용자 행동 기록
- 성능 메트릭 기록
목적이 다양한 만큼 요구 조건도 다양하다.
- 모든 메시지가 중요해서 메시지 유실이 용납되지 않는지? 아니면 유실이 허용되는지?
- 중복이 허용되는지?
- 반드시 지켜야 할 지연 (latency) 나 처리율 (throughput) 이 있는지?
예를 들면 결제 트랜잭션 처리의 경우 메시지의 유실이나 중복은 허용되지 않는다.
지연 시간은 낮아야 하지만 500ms 정도까지는 허용 가능하고, 처리율은 매우 높아야 한다. (초당 백만개의 메시지리르 처리할 정도로)
반면, 사용자의 클릭 정보를 수집하는 경우 메시지가 조금 유실되거나 중복이 되어도 문제가 되지 않는다.
사용자 경험이 영향을 주지 않는 한 지연 또한 높아도 된다.
이러한 다양한 요구 조건은 카프카에 메시지를 쓰기 위해 프로듀서 API 를 사용하는 방식과 설정에 영향을 미친다.
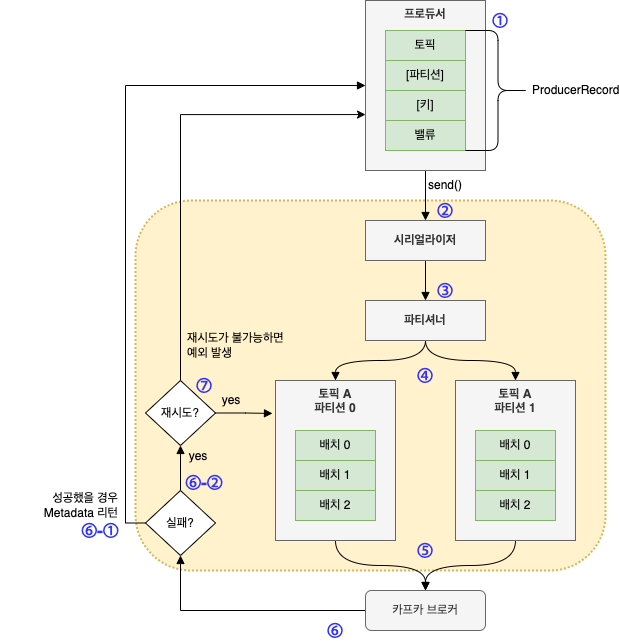
① 카프카에 메시지를 쓰는 작업은 ProducerRecord 객체를 생성함으로써 시작됨
이 때 레코드가 저장될 토픽과 밸류는 필수값이고, 키와 파티션 지정은 선택사항임
② ProducerRecord 를 전송하는 API 를 호출하면 프로듀서는 키와 밸류 객체가 네트워크 상에서 전송될 수 있도록 직렬화하여 바이트 배열로 변환함
③ 파티션을 명시적으로 지정하지 않았다면 해당 데이터를 파티셔너에게 보냄
파티셔너는 파티션을 결정하는 역할을 하는데 그 기준은 보통 ProducerRecord 객체의 키 값임
④ 파티션이 결정되어 메시지가 전송될 토픽과 파티션이 확정되면 프로듀서는 이 레코드를 같은 토픽 파티션으로 전송될 레코드들은 모은 레코드 배치에 추가함
⑤ 그러면 별도의 스레드가 이 레코드 배치를 적절한 카프카 브로커에게 전송함
⑥ 브로커가 메시지를 받으면 응답을 돌려줌
⑥-① 메시지가 성공적으로 저장된 경우 브로커는 토픽, 파티션, 해당 파티션 안에서의 레코드 오프셋을 담은 RecordMetadata 객체 리턴
⑥-② 메시지 저장에 실패한 경우 에러 리턴
⑦ 프로듀서가 에러를 수신한 경우 메시지 쓰기를 포기하고 사용자에게 에러를 리턴하기 까지 몇 번 더 재전송 시도 가능
2. 프로듀서 생성
카프카에 메시지를 쓰려면 먼저 원하는 속성을 지정해서 프로듀서 객체를 생성해야 한다.
<카프카 프로듀서 필수 속성값>
bootstrap.servers- 카프카 클러스터와 첫 연결을 생성하기 위해 프로듀서가 사용할 브로커의
host:post목록 - 프로듀서가 첫 연결을 생성한 뒤 추가 정보를 받아오기 때문에 모든 브로커를 연결할 필요는 없음
- 단, 브로커 중 하나가 작동을 정지하는 경우에도 프로듀서가 클러스터에 연결할 수 있도록 최소 2개 이상을 지정할 것을 권장함
- 카프카 클러스터와 첫 연결을 생성하기 위해 프로듀서가 사용할 브로커의
key.serializer- 카프카에 쓸 레코드의 key 값을 직렬화하기 위해 사용하는 시리얼라이저 클래스명
- 카프카 브로커는 메시지의 key, value 값으로 바이트 배열을 받는데 프로듀서 인터페이스는 임의의 자바 객체를 key 혹은 value 로 전송할 수 있도록 매개변수화된 타입 (parameterized type) 을 사용할 수 있도록 함
- 따라서 프로듀서 입장에서는 이 객체를 어떻게 바이트 배열로 바꿔야하는지 알아야 함
key.serialier에는org.apache.kafka.common.serialization.Serializer인터페이스를 구현하는 클래스명이 지정되어야 함- 카프카의 client 패키지에는
ByteArraySericalizer,StringSerializer,IntegerSerializer등이 포함되어 있어서 자주 사용되는 타입을 사용할 경우 시리얼라이저를 직접 구현할 필요는 없음 - key 값 없이 value 값만 보낼때는
key.serializer에VoidSerializer를 사용하여 key 타입을 Void 타입으로 설정할 수 있음
value.serializer- 카프카에 쓸 레코드의 value 값을 직렬화하기 위해 사용하는 시리얼라이저 클래스명
- value 값으로 쓰일 객체를 직렬화하는 클래스명을 지정함
필수 속성만을 지정하고 나머지는 기본 설정값을 사용하는 방식으로 새로운 프로듀서를 생성하는 예시
// Properties 객체 생성
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "broker1:9092,broker2:9092");
// 메시지의 key, value 로 문자열 타입 사용
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// key, value 타입 설정 후 Properties 객체를 넘겨줌으로써 새로운 프로듀서 생성
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(kafkaProps);
위에서 프로듀서 설정 시 key 이름을 상수값으로 사용하고 있는데 이는 카프카 클라이언트 1.x 버전이고, 2.x 버전부터는 관련 클래스에 정의된 정적 상수를 사용한다.
- 프로듀서: org.apache.kafka.clients.producer.ProducerConfig
- 컨슈커: org.apache.kafka.clients.consumer.ConsumerConfig
- AdminClient: org.apache.kafka.clients.admin.AdminClientConfig
// Producer 의 bootstrap.servers 속성 지정
kafkaProps.put(ProducerConfig.BOOTSTRAT_SERVERS_CONFIG, "broker1:9092,broker2:9092");
// Consumer 의 auto.offset.reset 속성 지정
kafkaProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
프로듀서 필수 설정값 외의 항목들에 대해서는 4. 프로듀서 설정 에서 다룬다.
프로듀서 객체를 생성했으면 메시지를 전송할 수 있다.
<메시지 전송 방법>
- 파이어 앤 포겟 (Fire and forget)
- 메시지를 서버에 전송만 하고 성공, 실패 여부에는 신경쓰지 않음
- 카프카는 가용성이 높고 프로듀서는 자동으로 전송 실패한 메시지를 재전송 시도하기 때문에 대부분 메시지는 성공적으로 전달됨
- 단, 재시도를 할 수 없는 에러가 발생하거나 타임아웃이 발생한 경우 메시지는 유실되며, 애플리케이션은 아무런 정보나 예외를 전달받지 못함
- 동기적 전송 (Synchronous send)
- 카프카 프로듀서는 언제나 비동기적으로 작동함
- 즉, 메시지를 보내면
send()메서드는Future객체를 리턴함 - 하지만 다음 메시지를 전송하기 전
get()메서드를 호출해서 작업이 완료될 때까지 기다렸다가 실제 성공 여부를 확인해야 함
- 비동기적 전송 (Asynchronous send)
- 콜백 함수와 함께
send()메서드 호출 시 카프카 브로커로부터 응답을 받는 시점에서 자동으로 콜백 함수가 호출됨
- 콜백 함수와 함께
이 포스트에서 모든 예시들은 단일 스레드를 사용하지만 프로듀서 객체는 메시지를 전송하려는 다수의 스레드를 동시에 사용할 수 있다.
3. 카프카로 메시지 전달
아래는 메시지를 전송하는 간단한 코드이다.
ProducerSample.java
package com.assu.study.chap03;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
public class ProducerSample {
// 메시지를 전송하는 간단한 예시
public void simpleMessageSend() {
Properties kafkaProp = new Properties();
kafkaProp.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
kafkaProp.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
kafkaProp.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
Producer<String, String> producer = new KafkaProducer<>(kafkaProp);
// ProducerRecord 객체 생성
ProducerRecord<String, String> record =
new ProducerRecord<>("Topic_Country", "Key_Product", "Value_France");
try {
// ProducerRecord 를 전송하기 위해 프로듀서 객체의 send() 사용
// 메시지는 버퍼에 저장되었다가 별도 스레드에 의해 브로커로 보내짐
// send() 메서드는 Future<RecordMetadata> 를 리턴하지만 여기선 리턴값을 무시하기 때문에 메시지 전송의 성공 여부를 모름
// 따라서 이런 식으로는 잘 사용하지 않음
producer.send(record);
} catch (Exception e) {
// 프로듀서가 카프카로 메시지를 보내기 전 발생하는 에러 캐치
e.printStackTrace();
}
}
}
위 코드는 카프카 브로커에 메시지를 전송할 때 발생하는 에러나 브로커 자체에서 발생한 에러를 무시한다.
단, 프로듀서가 메시지를 보내기 전에 에러가 발생할 경우 예외가 발생할 수 있다.
예) 메시지 직렬화 실패 시 SerializationException, 버퍼가 가득찰 경우 TimeoutException, 실제로 전송 작업을 수행하는 스레드에 인터럽트가 걸리면 InterruptException 발생
3.1. 동기적으로 메시지 전달
동기적으로 메시지를 전달하는 방식은 성능이 크게 낮아지기 때문에 실제 잘 사용하지 않음
카프카 클러스터에 얼마나 작업이 몰리느냐에 따라서 브로커는 쓰기 요청에 응답하기까지 최소 2ms~몇 초까지 지연될 수 있다.
동기적으로 메시지 전송 시 전송을 요청하는 스레드는 그 시간 동안 다른 메시지 전송도 못하고 아무것도 못하는채로 기다려야 한다.
결국 동기적으로 메시지를 전달하게 되면 성능이 크게 낮아져서 실제로는 잘 쓰이지 않는다.
아래는 동기적으로 메시지를 전송하는 간단한 예시이다.
ProducerSample.java
package com.assu.study.chap03;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
public class ProducerSample {
// ...
// 동기적으로 메시지 전송
public void syncMessageSend() {
Properties kafkaProp = new Properties();
kafkaProp.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
kafkaProp.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
kafkaProp.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
Producer<String, String> producer = new KafkaProducer<>(kafkaProp);
// ProducerRecord 객체 생성
ProducerRecord<String, String> record =
new ProducerRecord<>("Topic_Country", "Key_Product", "Value_France");
try {
// 카프카로부터 응답이 올 때까지 대기하기 위해 Future.get() 메서드 사용
// Future.get() 메서드는 레코드가 카프카로 성공적으로 전송되지 않았을 경우 예외 발생시킴
// 에러가 발생하지 않으면 RecordMetadata 객체 리턴
// 리턴되는 RecordMetadata 로부터 메시지가 쓰여진 오프셋과 다른 메타데이터 조회 가능
producer.send(record).get();
} catch (Exception e) {
// 프로듀서가 카프카로 메시지를 보내기 전이나 전송하는 도중 발생하는 에러 캐치
e.printStackTrace();
}
}
}
3.1.1. KafkaProducer 에러 종류
- 재시도 가능한 에러
- 메시지를 재전송하여 해결할 수 있는 에러
- 연결 에러는 연결 회복 시 해결
- 메시지를 전송받은 브로커가 ‘해당 파티션의 리더가 아닐 경우’ 발생하는 에러는 해당 파티션에 새로운 리더가 선출되고 클라이언트 메타데이터가 업데이트되면 해결
- 재시도 가능한 에러 발생 시 자동으로 재시도하도록
KafkaProducer설정이 가능하므로 재전송 횟수가 소진되고서도 에러가 해결되지 않은 경우에 한해 재시도 가능한 예외가 발생함
- 재시도 불가능한 에러
- 메시지가 너무 클 경우 재시도를 해도 해결되지 않음
- 이러한 경우
KafkaProducer는 재시도없이 바로 예외 발생
재시도 설정에 관한 내용은 4.2. 프로듀서 재시도 설정:
delivery.timeout.ms,enable.idempotence를 참고하세요.
3.2. 비동기적으로 메시지 전달: Callback 인터페이스
sned()를 콜백과 함께 비동기적으로 호출하는 방법이 가장 일반적이고 권장되는 방식임
애플리케이션과 카프카 클러스터 사이에 네트워크 왕복 시간 (network roundtrip time) 이 10ms 일 때 메시지를 보낼 때마다 응답을 기다린다면 100개의 메시지 전송 시 약 1초가 소요된다. (10ms * 100 = 1,000ms)
반면 보내야 할 메시지를 전부 전송하고 응답을 기다리지 않는다면 100개의 메시지를 전송하더라도 거의 시간이 걸리지 않고, 대부분의 경우 굳이 응답이 필요없다.
카프카는 레코드를 쓴 뒤 해당 레코드의 토픽, 파티션, 오프셋을 리턴하는데 대부분의 애플리케이션에서는 이런 메타데이터가 필요없기 때문이다.
하지만 메시지 전송에 완전히 실패했을 경우에는 예외 발생, 에러 로그 등의 작업을 위해 그 내용을 알아야 한다.
메시지를 비동기적으로 전송하면서 에러를 처리해야 하는 경우, 프로듀서는 레코드를 전송할 때 콜백을 지정함으로써 이를 가능하게 해준다.
아래는 콜백을 사용하는 예시이다.
ProducerSample.java
package com.assu.study.chap03;
import java.util.Properties;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
public class ProducerSample {
// ...
// 비동기적으로 메시지를 전송하면서 콜백으로 에러 처리
public void AsyncMessageSendWithCallback() {
Properties kafkaProp = new Properties();
kafkaProp.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
kafkaProp.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
kafkaProp.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
Producer<String, String> producer = new KafkaProducer<>(kafkaProp);
// ProducerRecord 객체 생성
ProducerRecord<String, String> record =
new ProducerRecord<>("Topic_Country", "Key_Product", "Value_France");
// 레코드 전송 시 콜백 객체 전달
producer.send(record, new ProducerCallback());
}
// 콜백을 사용하려면 Callback 인터페이스를 구현하는 클래스 필요
private class ProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
// 카프카가 에러를 리턴하면 onCompletion() 메서드는 null 이 아닌 Exception 객체를 받음
// 실제로는 확실한 에러 처리 함수가 필요함
e.printStackTrace();
}
}
}
}
콜백은 프로듀서의 메인 스레드에서 실행되기 때문에 만일 2개의 메시지를 동일한 파티션에 전송한다면 콜백 역시 보낸 순서대로 실행된다.
즉, 전송되어야 할 메시지가 전송이 안되서 프로듀서가 지연되는 상황을 막기 위해서는 콜백이 충분히 빨라야 한다는 의미이다.
콜백 안에서 블로킹 작업을 수행하는 것 역시 권장되지 않는다.
대신 블로킹 작업을 동시에 수행하는 다른 스레드를 사용해야 한다.
4. 프로듀서 설정
프로듀서 설정값 중 위의 2. 프로듀서 생성 에서 bootstrap.servers 와 시리얼라이저는 살펴보았다.
대부분의 경우 합리적인 기본값을 갖고 있기 때문에 각각의 설정값을 모두 일일이 잡아줄 필요는 없다.
다만, 일부 설정값의 경우 메모리 사용량이나 성능, 신뢰성 등에 영향을 미치므로 이러한 값들에 대해 알아본다.
4.1. client.id
프로듀서와 프로듀서를 사용하는 애플리케이션을 구분하기 위한 논리적 식별자이다.
임의의 문자열을 사용할 수 있으며ㅣ, 브로커는 프로듀서가 보내온 메시지를 서로 구분하기 위해 client.id 를 사용한다.
브로커가 로그 메시지를 출력하거나 성능 메트릭 값을 집계할 때, 클라이언트별로 사용량을 할당할 때 사용된다.
client.id 를 잘 선택하면 트러블 슈팅에 용이하다.
예를 들어 아래 2 개의 메시지 중 아래의 메시지가 트러블 슈팅에 더 용이하다.
- IP 102.121.221.125 에서 인증 실패가 발생하고 있음
- 주문 확인 서비스에서 인증 실패가 발생하고 있으니 xx 가 확인해주어야 할 것 같음
4.2. acks
프로듀서가 임의의 쓰기 작업이 성공했다고 판별하기 위해 얼마나 많은 파티션 레플리카가 해당 레코드를 받아야 하는지를 결정한다.
acks 매개변수는 메시지가 유실될 가능성에 큰 영향을 미친다.
쓰기 요청과
acks관계에 대한 내용은 4.1. 쓰기 요청 를 참고하세요.
카프카가 보장하는 신뢰성 수준에 대해서는 4. 신뢰성 있는 프로듀서 설정 을 참고하세요.
<acks 설정 옵션>
acks=0- 프로듀서는 네트워크로 메시지를 전송한 시점에서 메시지가 카프카에 성공적으로 전달되었다고 간주하고 브로커의 응답을 기다리지 않음
- 전송하는 객체가 직렬화될 수 없는 등의 문제일때는 에러를 받겠지만, 파티션이 오프라인이거나 리더 선출이 진행중이거나, 카프카 클러스터가 작동 불능인 경우엔 에러가 발생하지 않음
- 이 때 프로듀서는 이 상황에 대해 알 수 없고 메시지는 유실됨
- 다만, 프로듀서가 서버로부터 응답을 기다리지 않으므로 네트워크가 허용하는 한 빠르게 메시지를 보낼 수 있음
- 따라서 이 설정은 매우 높은 처리량이 필요할 때 사용됨
예) 벤치마크를 돌리는 경우 - acks=0 설정은 지연은 낮지만 종단 지연이 개선되지는 않음
(컨슈머는 메시지가 모든 ISR 로 복제되지 않는 한 해당 메시지를 볼 수 없으므로)
acks=1- 프로듀서는 리더 레플리카가 메시지를 받아서 파티션 데이터 파일에 쓴 직후 브로커로부터 성공 혹은 에러의 응답을 받음
- 만일 리더에 크래시가 났는데 새 리더가 아직 선출되지 않은 상태라서 리더에 메시지를 쓸 수 없다면 프로듀서는 에러 응답을 받을 것이고, 데이터 유실을 피하기 위해 메시지 재전송을 시도함
- 하지만 리더에 크래시가 난 상태에서 해당 메시지가 복제가 안된 채로 새 리더가 선출될 경우 여전히 메시지는 유실될 수 있음
- 일부 메시지가 리더에 성공적으로 쓰여져서 클라이언트로 응답이 간 상태에서 미처 팔로워로 복제가 완료되기 전에 리더가 정지하거나 크래시가 나면 데이터가 유실될 수 있음
- acks=1 설정은 메시지를 복제하는 속도보다 더 빨리 리더에 쓸 수 있기 때문에 불완전 복제 파티션(URP, Under-Replication Partition) 이 발생할 수 있음
(리더 입장에서는 복제가 완료되기 전에 프로듀서에게 응답을 먼저 하기 때문에)
acks=all(기본값)- 프로듀서는 메시지가 ISR(In-Sync Replica) 에 전달된 뒤에야 브로커로부터 성공 혹은 에러의 응답을 받음
- 프로듀서는 메시지가 완전히 커밋될 때까지 계속해서 메시지를 재전송함
- 최소 2개 이상의 브로커가 해당 메시지를 갖고 있으며 이것은 크래시가 났을 경우에도 유실되기 않기 때문에 가장 안전한 형태임
위 부분에 대한 좀 더 상세한 내용은 4.1. 쓰기 요청 을 참고하세요.
- 하지만
acks=1처럼 단순히 브로커 하나가 메시지를 받는 것보다는 더 기다려야 하기 때문에 지연 시간은 좀 더 길어짐 - 브로커의
min.insync.replicas설정과 함께 acks=1 은 응답이 오기 전까지 얼마나 많은 레플리카에 메시지가 복제될 것인지를 조절할 수 있게 해줌
<acks 설정으로 인한 신뢰성과 지연 간의 트레이드 오프 관계>
acks설정은 신뢰성과 프로듀서 지연 사이에서 트레이프 오프 관계가 있음acks설정을 낮게 잡아서 신뢰성을 낮추면 그만큼 레코드를 빠르게 보낼 수 있다는 의미임- 하지만 레코드가 생성되어 컨슈머가 읽을 수 있을 때까지의 시간을 의미하는 종단 지연 (eed to end latency) 의 경우 3개의 설정값 (0, 1, all) 이 모두 동일함
- 카프카는 일관성을 유지하기 위해 모든 ISR(In-Sync Replica) 에 복제가 완료된 뒤에서 컨슈머가 레코드를 읽어갈 수 있게 하기 때문임
- 따라서 단순한 프로듀서 지연이 아니라 종단 지연이 주로 고려되어야 하는 경우라면 가장 신뢰성 있는 설정인
acks=all을 선택해도 종단 지연이 동일하므로 딱히 절충할 것이 없음
4.3. 메시지 전달 시간
Producer 의 send() 메서드를 호출했을 때 성공/실패하기까지 걸리는 시간은 카프카가 성공적으로 응답을 내려보내줄 때까지 사용자가 기다릴 수 있는 시간이며, 요청 실패를 인지하여 포기할 때까지 기다릴 수 있는 시간이기도 하다.
프로듀서는 ProducerRecord 를 보낼 때 걸리는 시간을 2 구간으로 나누어 따로 처리 가능하다.
send()에 대한 비동기 호출이 이루어진 시간 ~ 결과를 리턴할 때까지 걸리는 시간- 이 시간동안
send()를 호출한 스레드를 블록됨
- 이 시간동안
send()에 대한 비동기 호출이 성공적으로 리턴한 시각(성공 or 실패) ~ 콜백이 호출될 때까지 걸리는 시간ProducerRecord가 전송을 위해 배치에 추가된 시점에서부터 카프카가 성공 응답을 보내거나, 재시도 불가능한 실패가 일어나거나, 전송을 위해 할당된 시간이 소진될 때까지의 시간과 동일함
만일 send() 를 동기적으로 호출할 경우 메시지를 보내는 스레드는 2 구간에 대해 연속적으로 블록이 되기 때문에 각각의 구간이 어느 정도 걸렸는지 알 수 없다.
이 포스트에서는 가장 일반적이고 권장되는 방식인 send() 를 콜백과 함께 비동기적으로 호출하는 방법에 대해 알아본다.
아래는 프로듀서 내부에서의 데이터 흐름과 각 설정 매개변수들이 어떻게 상호작용하는지를 도식화한 것이다.
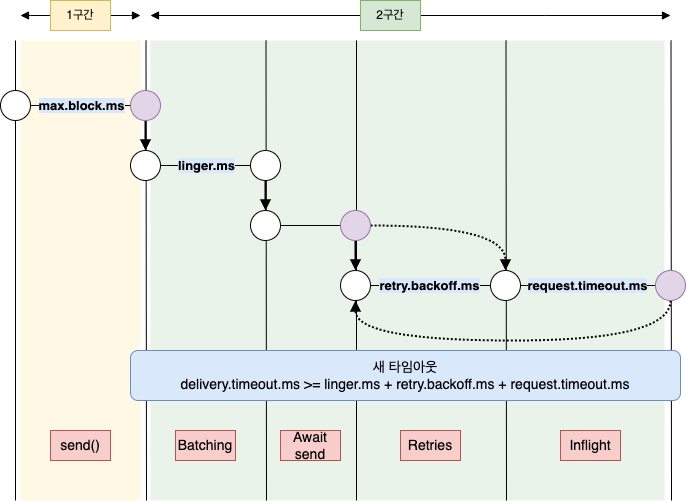
4.3.1. max.block.ms
max.block.ms 매개변수는 send() 를 호출하거나 partitionsFor() 를 호출해서 명시적으로 메타데이터 요청했을 때 프로듀서가 얼마나 오랫동안 블록될 지 결정한다.
즉, 버퍼가 가득찼을 때 send(), partitionsFor() 메서드를 블록하는 시간이다.
send() 메서드는 프로듀서의 전송 버퍼가 가득 차거나, 메타데이터가 아직 사용 가능하지 않을 때 블록되는데 이 때 max.block.ms 만큼 시간이 흐르면 예외가 발생한다.
4.3.2. delivery.timeout.ms
레코드 전송 준비가 완료된 시점 (= send() 가 문제없이 리턴되고, 레코드가 배치에 저장된 시점) 부터 브로커의 응답을 받거나 아니면 전송을 포기하게 되는 시점까지의 제한 시간이다.
즉, send() 메서드를 호출하고 난 뒤 성공과 실패를 결정하는 상한시간이다.
브로커로부터 ack 를 받기 위해 대기하는 시간이며, 실패 시 재전송에 허용된 시간이다.
복구할 수 없는 오류가 발생하거나 재시도 횟수를 다 소모하면 delivery.timeout.ms 설정 시간보다 먼저 에러를 낼 수 있다.
delivery.timeout.ms 는 linger.ms 와 request.timeout.ms 보다 커야 한다.
(위의 제한 조건을 벗어난 설정으로 프로듀서 생성 시 예외 발생)
메시지는 delivery.timeout.ms 보다 빨리 전송될 수 있으며 실제로도 대부분 그렇다.
프로듀서가 재시도를 하는 도중에 delivery.timeout.ms 를 초과하면 마지막으로 재시도를 하기 전에 브로커가 리턴한 에러에 해당하는 예외와 함께 콜백이 호출된다.
레코드 배치가 전송을 기다리는 도중에 delivery.timeout.ms 를 초과하면 타임아웃 예외와 함께 콜백이 호출된다.
재시도 관련 설정 튜닝
재시도 관련 설정을 튜닝하는 일반적인 방식은 아래와 같음
브로커가 크래시 났을 때 리더 선출에 약 30s 가 소요되므로 재시도 한도를 안전하게 120s 로 유지하는 것을 튜닝한다고 했을 때 재시도 횟수와 재시도 사이의 시간 간격으로 조정하는 것이 아니라 그냥delivery.timeout.ms를 120s 로 설정함
4.3.3. request.timeout.ms
프로듀서가 데이터를 전송할 때 서버로부터 응답을 받기 위한 최대 대기 시간이다.
각각의 쓰기 요청 후 전송을 포기하기까지의 대기하는 시간을 의미하는 것이므로 재시도 시간이나 실제 전송 이전에 소요되는 시간 등은 포함하지 않는다.
타임아웃 시간동안 응답을 받지 못할 경우 프로듀서는 재전송을 시도하거나 TimeoutException 과 함께 콜백을 호출한다.
불필요한 재시도를 줄이려면 브로커 설정인 replica.lag.time.max.ms 보다 큰 값이어야 한다.
replica.lag.time.max.ms브로커 팔로워가 복제를 위한 패치 요청을 하지 않을 경우 ISR(In-Sync-Replica) 에서 제외하는 시간
ISR 은 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태를 말함
리더 파티션은replica.lag.time.max.ms만큼의 주기로 팔로워 파티션이 데이터를 복제하는지 확인
팔로워 파티션은replica.lag.time.max.ms보다 더 긴 시간동안 데이터를 가져가지 않으면 해당 팔로워 파티션에 문제가 생간것으로 판단하고 ISR 그룹에서 제외3.4. 레플리카를 In-Sync 상태로 유지:
zookeeper.session.timeout.ms,replica.lag.time.max.ms와 함께 보면 도움이 됩니다.
4.3.4. retries, retry.backoff.ms
프로듀서가 서버로부터 에러 메시지를 받았을 때 일시적인 에러일 수도 있다.
예) 파티션에 리더가 없는 경우
이 때 retries 매개변수는 프로듀서가 메시지 전송을 포기하고 에러를 발생시킬 때까지 메시지를 재전송하는 횟수를 결정한다.
기본적으로 프로듀서는 각각의 재시도 사이에 100ms 동안 대기하는데 retry.backoff.ms 를 이용하여 이 간격을 조정할 수 있다.
하지만 retries 와 retry.backoff.ms 를 조정하는 것보다 크래시 난 브로커가 정상으로 돌아오기까지 (= 모든 파티션에 대해 새 리더가 선출되는데 얼마나 시간이 걸리는지) 의 시간을 테스트한 뒤 delivery.timeout.ms 매개변수값을 설정하는 것을 권장한다. (= retries 를 다 채우지 않고도 재시도를 멈추도록 delivery.timeout.ms 를 설정)
즉, 카프카 클러스터가 크래시로부터 복구되기까지의 시간보다 재전송을 시도하는 전체 시간을 더 길게 잡아주는 것이다. (그렇지 않으면 프로듀서가 너무 일찍 메시지 전송을 포기하게 되므로)
프로듀서가 모든 에러를 재전송하는 것은 아니다.
메시지가 지나치게 큰 경우는 일시적인 에러가 아니기 때문에 재시도의 대상도 아니다.
일반적으로 프로듀서가 알아서 재전송을 처리해주식 때문에 애플리케이션 코드에서는 관련 처리를 수행하는 코드가 필요없다.
애플리케이션에서는 재시도 불가능한 에러를 처리하거나 재시도 횟수가 고갈되었을 경우에 대한 처리만 하면 된다.
참고로 재전송 기능을 끄는 방법은 retries=0 으로 설정하는 것 뿐이다.
재시도 설정에 관한 내용은 4.2. 프로듀서 재시도 설정:
delivery.timeout.ms,enable.idempotence를 참고하세요.
4.4. linger.ms
linger.ms 는 현재 배치를 전송하기 전까지 대기하는 시간이다.
KafkaProducer 는 현재 배치가 가득 차거나 linger.ms 에 설정된 제한 시간이 되었을 때 메시지 배치를 전송한다.
(= 한 파티션에 batch.size 만큼 레코드가 있으면 linger.ms 값을 무시하고 발송)
기본적으로 프로듀서는 메시지 전송에 사용할 수 있는 스레드가 있을 때 곧바로 전송하는데 linger.ms 를 0 보다 큰 값으로 설정하면 프로듀서가 브로커에 메시지 배치를 전송하기 전에 메시지를 추가할 수 있도록 더 기다리게 할 수 있다. (= linger.ms 가 기본값인 0 으로 되어있으면 대기하지 않고 바로 전송)
단위 메시지 당 추가적으로 드는 시간은 매우 작지만 압축이 설정되어 있거나 할 경우 훨씬 효율적이므로 linger.ms 를 설정하는 것은 지연을 조금 증가시키는 대신 처리율을 크게 증대시킨다.
4.5. buffer.memory
buffer.memory 는 프로듀서가 메시지를 전송하기 전에 메시지를 대기시키는 버퍼의 크기 (= 메모리 양, bytes) 이다.
프로듀서가 사용하는 전체 메모리 크기는 buffer.memory 와 대략 비슷하다.
정확히 일치하지 않는 이유는 압축하는 과정과 브로커에 보내는 과정에서 사용하는 메모리가 추가로 들기 때문이다.
애플리케이션이 서버에 전달 가능한 속도보다 더 빠르게 메시지를 전송한다면 버퍼 메모리가 가득찰 수 있다.
이 때 추가로 호출되는 send() 는 max.block.ms 동안 블록되어 버퍼 메모리에 공간이 생길 때까지 대기 (= 버퍼가 부족할 때 max.block.ms 설정이 필요) 하는데, 해당 시간동안 대기하고 나서도 공간이 확보되지 않으면 예외를 발생시킨다.
대부분의 프로듀서 예외는 send() 메서드가 리턴하는 Future 객체에서 발생하지만, 이 타임아웃은 send() 메서드에서 발생한다.
4.6. compression.type
기본적으로 메시지는 압축되지 않은 상태로 전송되는데 compression.type 매개변수를 snappy, gzip, lz4, zstd 중 하나로 설정하면 해당 압축 알고리즘을 사용하여 메시지를 압축한 뒤 브로커로 전송된다.
압축 기능을 활성화함으로써 카프카로 메시지를 전송할 때 자주 병목이 발생하는 네트워크 사용량과 저장 공간을 절약할 수 있다.
snappy- 구글에서 개발된 압축 알고리즘
- CPU 부하가 작으면서도 성능이 좋으며 좋은 압축률을 보임
- 압축 성능과 네트워크 대역폭 모두가 중요할 때 권장됨
gzip- CPU 와 시간을 더 많이 사용하지만 압축율이 더 좋음
- 네트워크 대역폭이 제한적일 때 사용 권장
4.7. batch.size
같은 파티션에 있는 다수의 레코드가 전송될 경우 프로듀서는 이것들을 배치 단위로 모아서 한꺼번에 전송한다.
batch.size 는 각각의 배치에 사용될 메모리의 양 (갯수가 아닌 바이트 단위) 이다.
배치가 가득 차면 해당 배치에 들어있는 모든 메시지가 한꺼번에 전송되지만, 프로듀서가 각각의 배치가 가득 찰 때까지 기다린다는 의미는 아니다.
프로듀서는 절반만 찬 배치나 심히어 하나의 메시지만 들어있는 배치도 전송하기 때문에 batch.size 를 지나치게 큰 값으로 유지한다고 해서 메시지 전송에 지연이 발생하지는 않는다.
단, batch.size 를 지나치게 작게 설정할 경우 프로듀서가 지나치게 자주 메시지를 전송해야 하므로 오버헤드가 발생한다.
4.8. max.in.flight.requests.per.connection
max.in.flight.requests.per.connection 매개변수는 프로듀서가 서버로부터 응답을 받지 못한 상태에서 전송할 수 있는 최대 메시지 수이다.
kafka 의 request 는 배치 단위임
max.in.flight.requests.per.connection은 acks 를 받지 않고 한 번에 보낼 수 있는 최대 메시지 배치의 개수
(= acks 를 받지 않고 연속으로 보낼 수 있는 request 의 최대 개수)
이 값을 높게 설정하면 메모리 사용량이 증가하지만 처리량 역시 증가한다.
단일 데이터 센터에서 카프카를 설정할 경우
max.in.fligh.requests.per.connection을 2로 설정했을 때 처리량이 최대를 기록했지만, 기본값인 5를 사용할 때도 비슷한 성능을 보여준다는 점이 알려져 있음An analysis of the impact of max.in.flight.requests.per.connection and acks on Producer performance
4.8.1. max.in.flight.requests.per.connection 과 순서 보장
아파치 카프카는 파티션 내에서 메시지의 순서를 보장하게 되어있다.
즉, 만일 프로듀서가 메시지를 특정한 순서로 보낼 경우 브로커가 받아서 파티션에 쓸 때나 컨슈머가 읽어올 때 해당 순서대로 처리된다는 것을 의미한다.
입출금처럼 순서가 중요한 상황이 있는 반면 순서가 그리 중요하지 않은 상황도 있다.
retries 매개변수를 0 보다 큰 값으로 설정한 상태에서 max.in.flight.requests.per.connection 을 1 이상으로 잡아줄 경우 메시지의 순서가 뒤집힐 수 있다.
즉, 브로커가 첫 번째 배치를 받아서 쓰려다 실패했는데 두 번째 배치를 쓸 때는 성공한 상황(= 두 번째 배치가 in-flight 상태) 에서 다시 첫 번째 배치가 재전송 시도하여 성공한 경우 메시지의 순서가 뒤집히게 된다.
성능상의 이슈로 in-flight 요청이 최소 2이상은 되어야 한다는 점과 신뢰성을 보장하기 위해 재시도 횟수 또한 높아야 한다는 점을 감안하면 가장 합당한 선택은 enable.idempotence=true 로 설정하는 것이다.
enable.idempotence 설정은 최대 5개의 in-flight 요청을 허용하면서도 순서도 보장하고, 재전송이 발생하더라도 중복이 발생하는 것 또한 방지해준다.
이 부분에 대해서는 1. 멱등적 프로듀서(idempotent producer) 를 참고하세요.
4.9. max.request.size
max.request.size 는 프로듀서가 전송하는 쓰기 요청의 크기이다.
거대한 요청을 피하기 위해 프로듀서에 의한 한 배치에 보내는 사이즈를 제한하는 것으로 압축하지 않은 배치의 최대 사이즈이다.
max.request.size 는 메시지의 최대 크기를 제한하기도 하지만, 한 번의 요청에 보낼 수 있는 메시지의 최대 개수 역시 제한한다.
예) max.request.size 의 기본값은 1MB 인데 이 때 전송 가능한 메시지의 최대 크기는 1MB 이며, 한 번에 보낼 수 있는 1KB 크기의 메시지 개수는 1,024 개가 됨
브로커에는 브로커가 받아들 일 수 있는 최대 메시지 크기를 결정하는 message.max.bytes 매개변수가 있는데 이를 max.request.size 와 동일하게 맞춰줌으로써 프로듀서가 브로커가 받아들이지 못하는 크기의 메시지를 전송하는 것을 방지할 수 있다.
4.10. receive.buffer.bytes, send.buffer.bytes
receive.buffer.bytes, send.buffer.bytes 매개변수는 데이터를 읽거나 쓸 때 소켓이 사용하는 TCP 송수신 버퍼의 크기이다.
각각의 값이 -1 일 경우에는 운영체제의 기본값이 사용된다.
프로듀서나 컨슈머가 다른 데이터센터에 위치한 브로커와 통신할 경우 네트워크 대역폭은 낮고 지연은 길어지는 것이 보통이기 때문에 이 값들을 높게 잡아주는 것이 좋다.
4.11. enable.idempotence
멱등적 프로듀서는 매우 중요한 부분이다.
4.2. 프로듀서 재시도 설정:
delivery.timeout.ms,enable.idempotence과 함께 보면 도움이 됩니다.
멱등적 프로듀서에 대한 좀 더 상세한 내용은 1. 멱등적 프로듀서(idempotent producer) 를 참고하세요.
신뢰성을 최대화하는 방향으로 프로듀서를 설정할 경우 acks=all 로 잡고, 실패가 나더라도 충분히 재시도하도록 delivery.timeout.ms 를 매우 큰 값으로 잡는다.
이 경우 메시지는 반드시 최소 한번 카프카에 쓰여지게 된다.
브로커가 프로듀서로부터 레코드를 받아서 로컬 디스크에 쓰고, 다른 브로커에도 성공적으로 복제되었다고 가정해보자.
여기서 첫 번째 브로커가 프로듀서로 응답을 보내기 전에 크래시가 났을 경우 프로듀서는 request.timeout.ms 만큼 대기한 후 재전송을 시도하게 된다.
이 때 새로 보내진 메시지는 이미 기존 쓰기 작업이 성공적으로 복제되었으므로 이미 메시지를 받은 바 있는 새 리더 브로커로 전달된다.
즉, 메시지가 중복되어 저장되는 것이다.
이러한 상황을 방지하기 위해 enable.idempotence=true 를 설정한다.
멱등적 프로듀서 기능을 활성화하면 프로듀서는 레코드를 보낼 때마다 순차적인 번호를 붙여서 보내게 되는데, 만일 동일한 번호를 가진 레코드를 2개 이상 받을 경우 하나만 저장하게 되며 프로듀서는 별다른 문제를 발생시키지 않는 DuplicateSequenceException 을 받게 된다.
멱등적 프로듀서 기능 활성화
멱등적 프로듀서 기능을 활성화하기 위해선 아래 조건을 만족해야 함
acks=allmax.in.flight.requests.per.connection은 5 이하retries는 1 이상이 조건을 만족하지 않으면
ConfigException이 발생함
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
- 카프카 핵심 가이드
- 예제 코드 & 오탈자
- Kafka Doc
- Git:: Kafka
- 아파치 카프카 프로젝트 위키
- 아파치 카프카 프로토콜
- Producer config 정리
- An analysis of the impact of max.in.flight.requests.per.connection and acks on Producer performance
- 카프카 기본 개념 정리
