Kafka - 프로듀서(2): 시리얼라이저, 파티션, 파티셔너, 헤더, 인터셉터, 쿼터, 스로틀링
이 포스트에서는 카프카에 메시지를 쓰기 위한 클라이언트에 대해 알아본다.
- 파티션 할당 방식을 정의하는 파티셔너
- 객체의 직렬화 방식을 정의하는 시리얼라이저
소스는 github 에 있습니다.
목차
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
pom.xml (parent)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<packaging>pom</packaging>
<modules>
<module>chap03</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.assu.study</groupId>
<artifactId>kafka_me</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka_me</name>
<description>kafka_me</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
pom.xml (chap03)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.assu.study</groupId>
<artifactId>kafka_me</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>chap03</artifactId>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<kafka.version>3.8.0</kafka.version>
<avro.version>1.12.0</avro.version>
<confluent.version>7.7.0</confluent.version>
</properties>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/avro</sourceDirectory>
<stringType>String</stringType>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
1. 시리얼 라이저
2. 프로듀서 생성 에서 본 것처럼 프로듀서를 설정할 때는 반드시 시리얼라이저를 지정해주어야 한다.
카프카의 client 패키지에는 StringSerializer, IntegerSerializer, ByteArraySerializer 등이 포함되어 있으므로 자주 사용되는 타입 사용 시 시리얼라이저를 직접 구현할 필요는 없지만 이것만으로는 모든 데이터를 직렬화할 수 없으므로 결국 더 일반적인 레코드를 직렬화할 수 있어야 한다.
카프카로 전송해야 하는 객체가 단순한 문자열이나 정수값이 아닐 경우 직렬화하기 위한 2가지 방법이 있다.
- 레코드를 생성하기 위해 에이브로 (Avro), 스리프트 (Thrift), 프로토버프 (Protobuf) 와 같은 범용 직렬화 라이브러리 사용
- 사용하고 있는 객체를 직렬화하기 위한 커스텀 직렬화 로직 작성
범용 직렬화 라이브러리를 사용하는 방안을 강력히 권장하지만, 시리얼라이저가 작동하는 방식과 범용 직렬화 라이브러리의 장점을 이해하기 위해 직접 커스텀 시리얼라이저를 구현해보는 법도 함께 알아본다.
1.1. 커스텀 시리얼라이저
아파치 에이브로를 사용하여 직렬화하는 것을 강력히 권장하므로 커스텀 시리얼라이저는 내용만 참고할 것
Customer.java
package com.assu.study.chap03.serializer;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
@RequiredArgsConstructor
@Getter
public class Customer {
private final int customerId;
private final String customerName;
}
CustomerSerializer.java (고객 클래스를 위한 커스텀 시리얼라이저)
package com.assu.study.chap03.serializer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.util.Map;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Serializer;
// Customer 클래스를 위한 커스텀 시리얼라이저
public class CustomerSerializer implements Serializer<Customer> {
/**
* customerId: 4 byte int
* customerName Length: 4 byte int, UTF-8 (customerName 이 null 이면 0)
* customerName: N bytes, UTF-8
*/
@Override
public byte[] serialize(String topic, Customer data) {
try{
byte[] serializeName;
int stringSize;
if (data == null) {
return null;
} else {
if (data.getCustomerName() != null) {
serializeName = data.getCustomerName().getBytes(StandardCharsets.UTF_8);
stringSize = serializeName.length;
} else {
serializeName = new byte[0];
stringSize = 0;
}
}
ByteBuffer buf = ByteBuffer.allocate(4 + 4 + stringSize);
buf.putInt(data.getCustomerId());
buf.putInt(stringSize);
buf.put(serializeName);
return buf.array();
} catch (Exception e) {
throw new SerializationException("Error when serializing Customer to byte[]: ", e);
}
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
// nothing to configure
}
@Override
public void close() {
// nothing to close
}
}
위와 같은 방식으로 직렬화를 한다면 유저가 많아져서 customerId 의 타입을 int -> Long 으로 변경하거나 새로운 필드를 추가할 때 기존 형식과 새로운 형식 사이의 호환성을 유지해야 하는 심각한 문제점이 있다.
서로 다른 버전의 직렬화/비직렬화 로직을 디버깅하는 것은 단순 바이트를 일일이 비교해야 하기 때문에 상당히 어려운 작업이다.
또한 여러 곳에서 Customer 데이터를 카프카로 쓰는 작업을 수행하고 있다면 모두가 같은 로직을 사용하고 있어야 하므로 코드를 동시에 변경해야 한다.
이러한 이유 때문에 JSON, 아파치 에이브로, 스리프트, 프로토버트와 같은 범용 라이브러리를 사용할 것을 권장한다.
1.2. 아파치 에이브로를 사용하여 직렬화
에이브로의 데이터는 언어에 독립적인 스키마의 형태로 기술된다.
이 스키마는 보통 JSON 형식으로 정의되며, 주어진 데이터를 스키마에 따라 직렬화하면 이진 파일 형태의 결과물이 나오는 것이 보통이다. (JSON 형태로 나오게 할 수도 있음)
에이브로는 직렬화된 결과물이 저장된 파일을 읽거나, 직렬화를 할 때 스키마 정보가 별도로 주어진다고 가정하고 보통은 에이브로 파일 자체에 스키마를 내장하는 방법을 사용한다.
에이브로가 카프카와 같은 메시지 전달 시스템에 적합한 이유는 메시지를 쓰는 애플리케이션이 새로운 스키마로 전환하더라도 기존 스키마와 호환성을 유지하는 한, 데이터를 읽는 애플리케이션은 일체의 변경/업데이트없이 계속해서 메시지를 처리할 수 있다는 점이다.
아래 예시를 보자.
기존 스키마
{
"namespace": "customerManagement.avro",
"type": "record",
"name": "Customer",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "address", "type": ["null", "string"], "default": "null"}
]
}
위 스키마를 계속 사용해놨고 이미 위 형식으로 몇 TB 의 데이터가 생성되어 있는 상황에서 address 필드가 없어지고 email 필드가 추가되었다고 해보자.
{
"namespace": "customerManagement.avro",
"type": "record",
"name": "Customer",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": "null"}
]
}
이제 새로운 버전으로 업그레이드를 하면 예전 레코드는 address 를 가지고 있는 반면, 새로운 레코드는 email 을 갖고 있게 된다.
업그레이드는 몇 달씩 걸리는 것이 보통이므로 이전 버전 애플리케이션과 새로운 버전 애플리케이션이 카프카에 저장된 모든 이벤트를 처리할 수 있도록 해줘야 한다.
아직 업그레이드되기 전인 이벤트를 읽는 쪽의 애플리케이션은 getId(), getName(), getAddress() 와 같은 메서드가 있을 것이다.
이 애플리케이션이 새로운 버전의 스키마를 사용하여 쓰여진 메시지를 받을 경우 getAddress() 는 null 을 리턴하게 된다.
이제 읽는 쪽의 애플리케이션을 업그레이드하게 되면 getAddress() 는 없고, getEmail() 이 있을 것이다.
이 애플리케이션이 구버전 스키마로 쓰인 메시지를 받을 경우 getEmail() 은 null 을 리턴하게 된다.
즉, 에이브로를 사용하면 데이터를 읽는 쪽 애플리케이션을 모두 변경하지 않고 스키마를 변경하더라도 예외나 에러가 발생하지 않으며, 기존 데이터를 새 스키마에 맞춰서 업데이트하는 엄청난 작업을 할 필요가 없다.
단, 이러한 시나리오에도 주의할 점이 있다.
- 데이터를 쓸 때 사용하는 스키마와 읽을 때 기대하는 스키마가 서로 호환되어야 함
- 역직렬화를 할 때는 데이터를 쓸 때 사용했던 스키마에 접근이 가능해야 함
- 설명 데이터를 쓸 때 사용했던 스키마가 읽는 쪽 애플리케이션에서 기대하는 스키마와 다른 경우에도 마찬가지임
위에서 두 번째 조건을 만족시키기 위해 에이브로 파일을 쓰는 과정에는 사용된 스키마를 쓰는 과정이 포함되어 있지만, 카프라 메시지를 다룰 때는 좀 더 나은 방법이 있다.
아래에서 그 방법에 대해 살펴본다.
1.3. 카프카에서 에이브로 레코드 사용: Schema Registry, KafkaAvroSerializer
파일 안에 전체 스키마를 저장함으로써 약간의 오버헤드를 감수하는 에이브로 파일과는 달리, 카프카 레코드에 전체 스키마를 저장할 경우 전체 레코드 사이즈는 2배 이상이 될 수 있다.
하지만 에이브로는 레코드를 읽을 때 스키마 전체를 필요로 하기 때문에 어딘가 스키마를 저장해 두기는 해야는데 이 문제를 해결하기 위해 스키마 레지스트리 라고 불리는 아키텍처 패턴을 사용한다.
스키마 레지스트리는 아파치 카프카의 일부가 아니며, 여러 오픈 소스 구현체 중에 하나를 골라서 사용하면 된다.
이 포스트에서는 컨틀루언트에서 개발한 스키마 레지스트리를 사용한다.
- 컨플루언트 스키마 레지스트리 코드 (깃허브)
- 컨플루언트 플랫폼 의 일부로도 설치 가능
- 컨플루언트 스키마 레지스트리 문서
카프카에 데이터를 쓰기 위해 사용되는 모든 스키마를 레지스트리에 저장하고, 카프카에 쓰는 레코드에는 사용된 스티마의 고유 식별자만 넣어준다.
컨슈머는 이 식별자를 이용하여 스키마 레지스트리에서 스키마를 가져와서 데이터를 역직렬화할 수 있다
여기서 중요한 점은 스키마를 레지스트리에 저장하고 필요할 때 가져오는 이 모든 작업이 주어진 객체를 직렬화하는 시리얼라이저와 직렬화된 데이터를 객체로 복원하는 디시리얼라이저 내부에서 수행된다는 점이다.
즉, 카프카에 데이터는 쓰는 코드는 그저 다른 시리얼라이저를 사용하듯이 에이브로 시리얼라이저를 사용하면 된다.
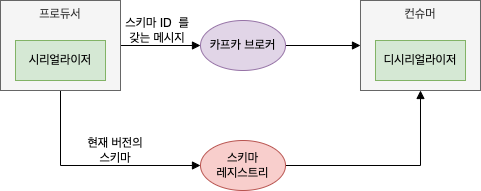
아래는 에이브로를 사용하여 생성한 객체를 카프카에 쓰는 예시이다.
에이브로 스키마에서 객체를 생성하는 방법은 아파치 에이브로 docs 를 참고하세요.
/resources/avro/AvroCustomer.avsc
{
"namespace": "avrocustomer.avro",
"type": "record",
"name": "AvroCustomer",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "email",
"type": [
"null",
"string"
],
"default": null
}
]
}
에이브로 클래스를 생성하는 것은 avro-tools.jar 를 이용하거나 에이브로 메이븐 플러그인을 사용하여 생성 가능하다.
위처럼 스키마 정의 후 빌드하면 AvroCustomer.java 가 생성된다.

AvroProducer.java
package com.assu.study.chap03.avrosample;
import avrocustomer.avro.AvroCustomer;
import io.confluent.kafka.serializers.AbstractKafkaSchemaSerDeConfig;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import java.util.Properties;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
@Slf4j
public class AvroProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 에이브로를 사용해서 객체를 직렬화하기 위해 KafkaAvroSerializer 사용
// KafkaAvroSerializer 는 객체 뿐 아니라 기본형 데이터도 처리 가능
// (그렇기 때문에 아래 레코드의 key 로 String, value 로 AvroCustomer 를 사용할 수 있는 것임)
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
// 에이브로 시리얼라이저의 설정 매개변수 설정
// 프로듀서가 시리얼라이저에게 넘겨주는 값으로, 스키마를 저장해놓은 위치를 기리킴 (= 스키마 레지스트리의 url 지정)
props.put(AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://sample.schemaurl");
String topic = "customerContacts";
// AvroCustomer 는 POJO 가 아니라 에이브로의 코드 생성 기능을 사용해서 스키마로부터 생성된 에이브로 특화 객체임
// 프로듀서에 사용할 레코드의 밸류 타입이 AvroCustomer 라는 것을 알려줌
// 에이브로 시리얼라이저는 POJO 객체가 아닌 에이브로 객체만 직렬화 가능
try (Producer<String, AvroCustomer> producer = new KafkaProducer<>(props)) {
// 10번 진행
for (int i = 0; i < 10; i++) {
AvroCustomer customer = new AvroCustomer();
log.info("Avro Customer: {}", customer);
// 밸류 타입이 AvroCustomer 인 ProducerRecord 객체를 생성하여 전달
ProducerRecord<String, AvroCustomer> record =
new ProducerRecord<>(topic, customer.getName(), customer);
// AvroCustomer 객체 전송 후엔 KafkaAvroSerializer 가 알아서 해줌
producer.send(record);
}
}
}
}
1.3.1. 제네릭 에이브로 객체 사용
에이브로를 사용하면 key-value 맵 형태로 사용 가능한 제네릭 에이브로 객체 역시 사용할 수 있다.
스키마를 지정하면 여기에 해당하는 getter, setter 와 함께 생성되는 에이브로 객체와는 달리 제네릭 에이브로 객체는 아래와 같이 스키마를 지정해주기만 하면 된다.
GenericAvroProducer.java
package com.assu.study.chap03.avrosample;
import io.confluent.kafka.serializers.AbstractKafkaSchemaSerDeConfig;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import java.util.Properties;
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
public class GenericAvroProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
props.put(AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://sample.schemaurl");
// 에이브로가 자동 생성한 객체를 사용하지 않기 때문에 에이브로 스키마를 직접 지정
String schemaString =
"""
{
"namespace": "avrogeneric.avro",
"type": "record",
"name": "AvroGeneric",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "email",
"type": [
"null",
"string"
],
"default": null
}
]
}
""";
Producer<String, GenericRecord> producer = new KafkaProducer<>(props);
String topic = "customerContacts";
// 에이브로 객체 초기화
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(schemaString);
for (int i = 0; i < 10; i++) {
String name = "sampleName" + i;
String email = "sampleEmail" + i;
GenericRecord customer = new GenericData.Record(schema);
customer.put("id", i);
customer.put("name", name);
customer.put("email", email);
// ProducerRecord 의 밸류값에 "직접 지정한 스키마와 데이터"가 포함된 GenericRecord 가 들어감
ProducerRecord<String, GenericRecord> record = new ProducerRecord<>(topic, name, customer);
// 시리얼라이저는 레코드를 스키마에서 얻어오고, 스키마 레지스트리에 저장하며,
// 객체 데이터 직렬화하는 과정을 알아서 처리함
producer.send(record);
}
}
}
2. 파티션
위에서 생성한 ProducerRecord 객체는 토픽, 키, 밸류값을 포함한다.
토픽, 키, 밸류가 포함된 ProducerRecord
// 밸류 타입이 AvroCustomer 인 ProducerRecord 객체를 생성하여 전달
ProducerRecord<String, AvroCustomer> record =
new ProducerRecord<>(topic, customer.getName(), customer);
// ProducerRecord 의 밸류값에 "직접 지정한 스키마와 데이터"가 포함된 GenericRecord 가 들어감
ProducerRecord<String, GenericRecord> record = new ProducerRecord<>(topic, name, customer);
카프카 메시지는 키의 기본값이 null 이라서 토픽, 파티션 (Optional), 키 (Optional), 밸류로 구성될 수 있기 때문에 토픽과 밸류만 있어도 ProducerRecord 객체 생성이 가능하지만 대부분 키 값이 지정된 레코드를 사용한다.
토픽, 밸류가 포함된 ProducerRecord (키 없음)
// 밸류 타입이 AvroCustomer 인 ProducerRecord 객체를 생성하여 전달
ProducerRecord<String, AvroCustomer> record =
new ProducerRecord<>(topic, customer);
// ProducerRecord 의 밸류값에 "직접 지정한 스키마와 데이터"가 포함된 GenericRecord 가 들어감
ProducerRecord<String, GenericRecord> record = new ProducerRecord<>(topic, customer); // key 는 null
<key 의 역할>
- 그 자체로 메시지에 밸류값과 함께 저장되는 추가적인 정보
- 하나의 토픽에 속한 여러 개의 파티션 중 해당 메시지가 저장될 파티션을 결정짓는 기준점
- 같은 키 값을 갖는 모든 메시지는 같은 파티션에 저장됨
- 즉, 임의의 프로세스가 전체 파티션 중 일부만 읽어올 경우 특정한 키 값을 갖는 모든 메시지를 읽게 됨
키 값은 로그 압착 기능이 활성화된 토픽에서도 중요한 역할을 하는데 해당 내용은
6. 보존 정책: 삭제 보존, 압착 보존,
7. 로그 압착(Compact)의 작동 원리
를 참고하세요.
임의의 프로세스가 전체 파티션 중 일부만 읽어오는 경우에 대한 좀 더 상세한 내용은 3. 특정 오프셋의 레코드 읽어오기:
seekToBeginning(),seekToEnd(),seek(),assignment(),offsetsForTimes()를 참고하세요.
2.1. 키 값이 없는 상태에서 기본 파티셔너 이용
기본 파티셔너 사용 중에 키 값이 null 인 레코드가 주어질 경우 레코드는 현재 사용 가능한 토픽의 파티션 중 하나에 랜덤하게 저장된다.
카프카 2.4. 프로듀서부터 기본 파티셔너는 키 값이 null 일 경우 sticky 처리가 있는 라운드 로빈 알고리즘을 사용하여 메시지를 파티션에 저장한다.
sticky 처리가 있는 라운드 로빈 알고리즘을 사용하면 프로듀서가 메시지 배치를 채울 때 다음 배치로 넘어가기 전에 이전 배치를 먼저 채운다.
이 기능은 더 적은 요청으로 같은 수의 메시지를 전송함으로써 지연 시간을 줄이고 브로커의 CPU 사용량을 줄여준다.
아래 그림은 10개의 레코드를 5개의 파티션을 가진 토픽에 쓸 때 sticky 처리가 있는 경우와 없는 경우에 대한 비교이다.
키 값이 있는 0번과 3번은 각각 0, 4번 파티션에 저장되어야 하며, 한번에 브로커로 전송될 수 있는 메시지의 수는 4개라고 해보자.
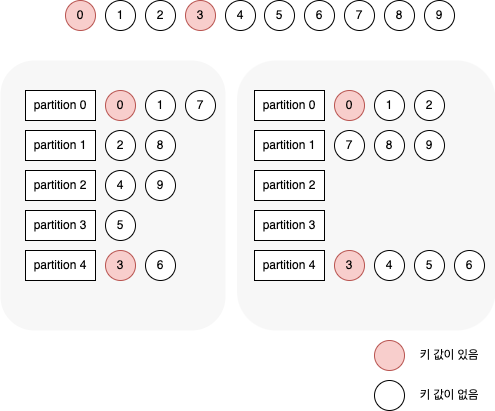
위 그림에서 왼쪽은 sticky 처리가 없는 경우이고, 오른쪽은 sticky 처리가 있는 경우이다.
비교해보면 파티션 할당에 차이가 나게 된다.
sticky 처리가 없을 경우 키 값이 null 인 메시지들은 5개의 파티션에 라운드 로빈 방식으로 배치되는 반면, sticky 처리가 있는 경우 키 값이 null 인 메시지들은 일단 키 값이 있는 메시지 뒤에 따라붙은 다음에 라운드 로빈 방식으로 배치된다.
결과적으로 보내야 하는 요청의 수가 5개 → 3개로 줄어들었을 뿐더라 한 번에 브로커에 보내는 메시지의 한도 역시 최대한 활용해서 보내게 된다.
메시지의 수가 많을수록 위의 차이는 크다.
2.2. 키 값이 있는 상태에서 기본 파티셔너 이용
반대로 키 값이 지정된 상황에서 기본 파티셔너 사용 시 카프카는 키 값을 해시한 결과를 기준으로 메시지를 저장할 파티션을 특정한다.
이 때 동일한 키 값은 항상 동일한 파티션에 저장 되므로 파티션을 선택할 때는 토픽이 모든 파티션을 대상으로 선택한다. (= 사용 가능한 파티션만을 대상으로 하지 않음)
따라서 특정한 파티션에 장애가 발생한 상태에서 해당 파티션에 데이터를 쓰려고 하면 에러가 발생하는데 카프카의 복제와 가용성 덕분에 그런 경우는 드물다.
카프카의 복제와 가용성에 대한 내용은 3.1. 복제 팩터(레플리카 개수):
replication.factor,default.replication.factor를 참고하세요.
기본 파티셔너가 사용될 경우 특정한 키 값에 대응하는 파티션은 파티션 수가 변하지 않는 한 변하지 않는다.
만일 파티션 수가 변경되지 않는다는 가정하에 ‘111에 해당하는 레코드는 모두 222 파티션에 저장된다’ 라는 예상이 가능하므로 파티션에서 데이터를 읽어 오는 부분을 최적화할 때 이 부분을 활용할 수 있다.
하지만 토픽에 새로운 파티션을 추가하는 순간 이 특성은 유효하지 않다.
파티션을 추가하기 전의 레코드들은 여전히 222 파티션에 저장되어 있겠지만, 이후에 쓴 레코드들은 다른 위치에 저장될 수 있다.
만일 파티션을 결정하는데 사용되는 키가 중요해서 같은 키 값이 저장되는 파티션이 변경되면 안되는 경우 가장 쉬운 방법은 충분한 수의 파티션을 가진 토픽을 생성한 뒤 더 이상 파티션을 추가하지 않는 것이다.
파티션의 수를 결정하는 방법은 How to Choose the Number of Topics/Partitions in a Kafka Cluster? 참고하세요.
2.3. 키 값이 있는 상태에서 RoundRobinPartitioner, UniformStickyPartitioner 이용
기본 파티셔너 외에도 카프카 클라이언트는 RoundRobinPartitioner, UniformStickyPartitioner 를 포함하고 있다.
이들은 각각 메시지가 키 값을 포함하고 있을 경우에도 랜덤 파티션 할당과 sticky 파티션 할당을 수행한다.
키 값 분포가 불균형해서 특정한 키 값을 갖는 레코드가 많은 경우 작업의 부하가 한 쪽으로 몰릴 수 있는데 UniformStiskyPartitioner 를 사용할 경우 전체 파티션에 대해서 균등한 분포를 갖도록 파티션이 할당된다.
위 2개 파티셔너들은 컨슈머 쪽 애플리케이션에서 키 값이 중요한 경우에 유용하다.
예) 카프카에 저장된 데이터를 DB로 보낼 때 카프카 레코드의 키 값을 PK 로 사용하는 ETL 애플리케이션
ETL 애플리케이션
ETL 은 추출 (Extract), 변환 (Transform), 로드 (Load) 를 의미하며, 여러 시스템의 단일 DB 를 결합하기 위해 일반적으로 사용하는 방법
2.4. 커스텀 파티셔너 구현: Partitioner
항상 키 값을 해시처리해서 파티션을 결정해아만 하는 것은 아니다.
예를 들어 일일 트랜잭션의 큰 부분을 A 업무를 처리하는데 사용한다고 해보자.
이 때 키 값의 해시값을 기준으로 파티션을 할당하는 기본 파티셔너를 사용한다면 A 에서 업무에서 생성된 레코드들은 다른 레코들과 같은 파티션에 저장될 가능성이 있고, 이 경우 한 파티션에 다른 파티션보다 훨씬 많은 레코들들이 저장되어 서버의 공간이 부족해기저나 처리가 느려지는 사태가 발생할 수 있다.
이 때는 A 는 특정 파티션에 저장되도록 하고, 다른 레코드들은 해시값을 사용해서 나머지 파티션에 할당되도록 할 수 있다.
아래는 커스텀 파티셔너의 예시이다.
CustomPartitioner.java
package com.assu.study.chap03.partitioner;
import io.confluent.common.utils.Utils;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.InvalidRecordException;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
// 커스텀 파티셔너
public class CustomPartitioner implements Partitioner {
// partition() 에 특정 데이터를 하드 코딩하는 것보다 configure() 를 경유하여 넘겨주는 것이 좋지만 내용 이해를 위해 하드 코딩함
@Override
public int partition(
String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if ((keyBytes == null) || (!(key instanceof String))) {
throw new InvalidRecordException("all messages to have customer name as key.");
}
if (key.equals("A")) {
// A 는 항상 마지막 파티션으로 지정
return numPartitions - 1;
}
// 다른 키들은 남은 파티션에 해시값을 사용하여 할당
return Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1);
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> map) {}
}
3. 헤더
레코드는 키, 밸류 외 헤더를 포함할 수 있다.
레코드 헤더는 카프카 레코드의 키, 밸류값을 건드리지 않고 추가 메타데이터를 심을 때 사용한다.
즉, 데이터가 생성된 곳의 정보를 헤더에 저장해두면 메시지를 파싱할 필요 없이 헤더에 심어진 정보만으로 메시지를 라우팅하거나 출처 추적이 가능하다.
헤더는 순서가 있는 키/밸류 쌍의 집합으로 구현되는데 키 값은 언제나 String 타입이고, 밸류는 메시지의 밸류값과 동일하게 아무 직렬화된 객체라도 상관없다.
ProducerRecord 에 헤더 추가하는 예시
// 헤더 추가
record.headers().add("privacy-level", "YOLO".getBytes(StandardCharsets.UTF_8));
4. 인터셉터: ProducerInterceptor
모든 애플리케이션에 동일한 작업을 집어넣거나 원래 코드를 사용할 수 없는 등 카프카 클라이언트 코드를 고치지 않으면서 그 작동을 변경해야 하는 경우가 있다.
이 때 사용하는 것이 카프카의 ProducerInterceptor 이다.
ProducerIntercepter 에는 2개의 메서드를 정의할 수 있다.
ProducerRecord<K,V> onSend(ProducerRecord<K,V> record)- 프로듀서가 레코드를 브로커로 보내기 전, 직렬화되기 직전에 호출됨
- 보내질 정보 조회 및 수정 가능
- 이 메서드에서 유효한
ProducerRecord를 리턴하도록 주의하기만 하면 됨 - 이 메서드가 리턴한 레코드가 직렬화되어 카프카로 보내짐
void onAcknowledgement(RecordMetadata metadata, Exception exception)- 카프카 브로커가 보낸 응답을 클라이언트가 받았을 때 호출됨
- 브로커가 보낸 응답을 조회는 가능하지만 수정은 할 수 없음
인터셉터의 일반적인 사용 사례로 모니터링, 정보 추적, 표준 헤더 삽입 등이 있다.
특히 레코드에 메시지가 생성된 위치에 대한 정보를 심음으로써 메시지의 전달 경로를 추적하거나 민감한 정보를 삭제 처리하는 등의 용도로 많이 사용된다.
아래는 N ms 마다 전송된 메시지의 수와 특정한 시간 윈도우 사이에 브로커가 리턴한 acks 수를 집계하는 간단한 프로듀서 인터셉터 예시이다.
CountingProducerInterceptor.java
package com.assu.study.chap03.interceptor;
import java.util.Map;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
// N ms 마다 전송된 메시지 수와 확인된 메시지 수 출력
@Slf4j
public class CountingProducerInterceptor implements ProducerInterceptor {
static AtomicLong numSent = new AtomicLong(0);
static AtomicLong numAcked = new AtomicLong(0);
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
public static void run() {
log.info(String.valueOf(numSent.getAndSet(0)));
log.info(String.valueOf(numAcked.getAndSet(0)));
}
// ProducerInterceptor 는 Configurable 인터페이스를 구현하므로 configure() 메서드를 재정의함으로써
// 다른 메서드가 호출되기 전에 뭔가 설정해주는 것이 가능함
// 이 메서드는 전체 프로듀서 설정을 전달받기 위해 어떠한 설정 매개 변수도 읽거나 쓸 수 있음
@Override
public void configure(Map<String, ?> map) {
Long windowSize = Long.valueOf((String) map.get("counting.interceptor.window.size.ms"));
executorService.scheduleAtFixedRate(
CountingProducerInterceptor::run, windowSize, windowSize, TimeUnit.MILLISECONDS);
}
// 프로듀서가 레코드를 브로커로 보내기 전, 직렬화되기 직전에 호출됨
@Override
public ProducerRecord onSend(ProducerRecord producerRecord) {
// 레코드가 전송되면 전송된 레코드 수를 증가시키고, 레코드 자체는 변경하지 않은 채 그대로 리턴함
numSent.incrementAndGet();
return producerRecord;
}
// 브로커가 보낸 응답을 클라이언트가 받았을 때 호출
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
// 카프카가 ack 응답을 받으면 응답 수를 증가시키고 별도로 뭔가를 리턴하지는 않음
numAcked.incrementAndGet();
}
// 프로듀서에 close() 메서드가 호출될 때 호출됨
// 인터셉터의 내부 상태를 정리하는 용도
@Override
public void close() {
// 생성했던 스레드 풀 종료
// 만일 파일을 열거나 원격 저장소에 연결을 생성했을 경우 여기서 닫아주어야 리소스 유실이 없음
executorService.shutdownNow();
}
}
인터셉터는 클라이언트 코드를 변경하지 않은채로 적용이 가능하다.
위 인터셉터를 아파치 카프카가 함께 배포되는 kafka-console.producer.sh 툴과 함께 사용하려면 아래와 같이 하면 된다.
- 인터셉터를 컴파일하여 jar 파일로 만든 후 classpath 에 추가 ( ~/target 디렉토리 안dp jar 파일이 있다고 가정)
export CLASSPATH=$CLASSPATH:~./target/CountProducerInterceptor.jar - 아래와 같이 설정 파일 생성 (예- producer.config)
interceptor.classes=com.assu.study.interceptor.CountingProducerInterceptor counting.interceptor.window.size.ms=10000 - 평소와 같이 애플리케이션을 실행시키되, 앞 단계에서 작성한 설정 파일을 포함하여 실행
bin/kafka-console-producer.sh --brocker-list localhost:9092 --topic interceptor-test --producer.config producer.config
5. 쿼터
카프카 브로커에는 쓰기/읽기 속도를 제한할 수 있는 기능이 있는데 총 3개의 쿼터 타입에 대해 한도를 설정할 수 있다.
- produce quota (쓰기 쿼터)
- 클라이언트가 데이터를 전송할 때의 속도를 초당 바이트 수 단위로 제한
- consume quota (읽기 쿼터)
- 클라이언트가 데이터를 받는 속도를 초당 바이트 수 단위로 제한
- request quota (요청 쿼터)
- 브로커가 요청을 시간 비율 단위로 제한
쿼터 설정은 아래과 같이 할 수 있다.
- 기본값 설정
- 특정한
client.id값에 대해 설정 - 특정 유저에 대해 설정
- 보안 기능과 클라이언트 인증 (authentication) 기능이 활성화되어 있는 클라이언트에서만 동작함
- 특정
client.id와 특정 유저에 대해 둘 다 설정
모든 클라이언트에 적용되는 쓰기/읽기 쿼터의 기본값을 카프카 브로커를 설정할 때 함께 설정할 수 있다.
예) 각 프로듀서가 초당 평균적으로 쓸 수 있는 데이터를 2MB 로 제한한다면 브로커 설정 파일에 quota.producer.default=2M 추가
브로커 설정 파일에 특정 클라이언트에 대한 쿼터값을 정의하여 기본값을 덮어쓸 수도 있지만 권장되는 사항은 아니다.
예) client A 에 초당 4MB, client B 에 초당 10MB 의 쓰기 속도를 허용하고 싶다면
quota.producer.override="clientA:4M,clientB:10M 추가
카프카의 설정 파일에 정의된 쿼터값은 고정되어 있기 때문에 이 값을 변경하고 싶다면 설정 파일을 변경한 후 모든 브로커를 재시작하는 방법 밖에 없다.
새로운 클라이언트는 언제고 들어올 수 있기 때문에 이러한 방법은 불편하다.
따라서 특정한 클라이언트에 쿼터를 적용할 때는 kafka-configs.sh 또는 AdminClient API 에서 제공하는 동적 설정 기능을 사용하는 것이 보통이다.
- clientC 클라이언트 (
client.id값으로 지정) 의 쓰기 속도를 초당 1,024 바이트로 제한bin/kafka-configs --bootstrap-server localhost:9092 --alter \ --add-config 'producer_byte_rate=1024' --entity-name clientC \ -- entity-type clients - user1 (authenticated principal 로 지정) 의 쓰기 속도를 초당 1,024 바이트로, 읽기 속도는 초당 2,048 바이트로 제한
bin/kafka-configs --bootstrap-server localhost:9092 --alter \ --add-config 'producer_byte_rate 1024,consumer_byte_rate=2048' \ --entity-name user1 --entity-type users - 모든 사용자의 읽기 속도를 초당 2,048 바이트로 제한하되, 기본 설정값을 덮어쓰고 있는 사용자에 대해서는 예외로 처리 (이런 식으로 기본 설정값을 동적으로 변경 가능)
bin/kafka-configs --bootstrap-server localhost:9092 --alter \ --add-config 'consumer_byte_rate=2048' --entity-type users
6. 스로틀링
클라이언트가 할당량을 다 채우면 브로커는 클라이언트 요청에 대한 스로틀링을 시작하여 할당량을 초과하지 않도록 한다. (= 브로커가 클라이언트의 요청에 대한 응답을 늦게 보내준다는 의미이기도 함)
대부분 클라이언트는 응답 대기가 가능한 요청의 수인 max.in.flight.requests.per.connection 가 한정되어 있어서 이 상황에서 자동적으로 요청 속도를 줄이는 것이 보통이기 때문에 해당 클라이언트의 메시지 사용량이 할당량 아래로 줄어들게 되는 것이다.
클라이언트는 아래 JMX 메트릭을 통해서 스로틀링 작동 여부를 확인할 수 있다.
-produce-throttle-time-avg-produce-throttle-time-max-fetch-throttle-time-avg-fetch-throttle-time-max
각각 쓰기/읽기 요청이 스로틀링 때문에 지연된 평균/최대 시간을 의미하는데 이 값들은 쓰기 쿼터/읽기 쿼터에 의해 발생한 스로틀링 때문에 지연된 시간을 가리킬 수도 있고, 요청 쿼터 때문에 지연된 시간을 가리킬 수도 있고, 둘 다 때문에 지연된 시간을 가리킬 수도 있다.
6.1. 브로커가 처리할 수 있는 용량과 프로듀서가 데이터를 전송하는 속도를 모니터링하고 맞춰줘야 하는 이유
비동기적으로 Producer.send() 를 호출하는 상황에서 브로커가 받아들일 수 있는 양 이상으로 메시지를 전송한다고 해보자.
이 때 메시지는 우선 클라이언트가 사용하는 메모리 상의 큐에 적재된다.
이 때 계속해서 브로커가 받아들이는 양 이상으로 전송을 시도할 경우 클라이언트의 버퍼 메모리가 고갈되면서 다음 Producer.send() 호출을 블록하게 된다.
여기서 브로커가 밀린 메시지를 처리해서 프로듀서 버퍼에 공간이 확보될때까지 걸리는 시간이 타임아웃 딜레이를 넘어가면 Producer.send() 는 결국 TimeoutException 을 발생시키게 된다.
반대로, 전송을 기다리는 배치에 이미 올라간 레코드는 대기 시간이 delivery.timeout.ms 를 넘어가는 순간 무효화되고, TimeoutException 이 발생하면서 send() 메서드 호출 때 지정했던 콜백이 호출된다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
- 카프카 핵심 가이드
- 예제 코드 & 오탈자
- Kafka Doc
- Git:: Kafka
- Producer config 정리
- 에이브로 문서 중 호환성 규칙
- 컨플루언트 스키마 레지스트리 코드 (깃허브)
- 컨플루언트 플랫폼
- 컨플루언트 스키마 레지스트리 문서
- 아파치 에이브로 docs
- How to Choose the Number of Topics/Partitions in a Kafka Cluster? 참고하세요.
