Kafka - 내부 메커니즘(1): 컨트롤러, `KRaft`, 복제, 요청 처리
이 포스트에서는 카프카를 실제로 사용하는 사용자 입장에서 특히 중요한 주제에 초점을 맞추어 아래의 내용에 대해 알아본다.
- 카프카 컨트롤러
- 카프카에서 복제 (replication) 가 작동하는 방식
- 카프카가 프로듀서와 컨슈머의 요청을 처리하는 방식
카프카의 내부 동작 방식을 알고 있으면 트러블 슈팅을 하거나 카프카가 실행되는 방식을 이해하는데 도움이 된다.
위의 주제들은 카프카를 튜닝할 때 특히 도움이 된다.
튜닝을 할 때 카프카 내부 메커니즘을 이해하고 있으면 명확한 의도를 가지고 설정값을 잡아줄 수 있다.
목차
- 1. 클러스터 멤버십
- 2. 컨트롤러
- 3. 복제: 레플리카 종류
- 4. 요청 처리
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
1. 클러스터 멤버십
카프카는 현재 클러스터의 멤버인 브로커들의 목록을 유지하기 위해 아파치 주키퍼를 사용한다.
각 브로커는 브로커 설정 파일에 정의되어 있거나 아니면 자동으로 생성된 고유한 식별자를 갖는다.
브로커 프로세스는 시작될 때마다 주키퍼에 Ephemeral 노드 의 형태로 ID 를 등록한다.
컨트롤러를 포함한 카프카 브로커들과 몇몇 툴들은 브로커가 등록되는 주키퍼의 /brokers/ids 경로를 구독함으로써 브로커가 추가되거나 제거될 때마다 알림을 받는다.
만일 동일한 ID 를 가진 다른 브로커가 시작하려 한다면 에러가 발생한다. (이미 동일한 브로커 ID 를 가진 ZNode 가 존재하므로)
브로커와 주키퍼 간의 연결이 끊어질 경우 (보통 브로커가 정지하기 때문이지만, 네트워크 단절이나 가비지 수집이 오래 걸려서 발생할 수도 있음) 브로커가 시작될 때 생성한 Ephemeral 노드는 자동으로 주키퍼에서 삭제되고, 이 브로커 목록을 지켜보고 있던 카프카 컴포넌트들은 해당 브로커가 내려갔음을 알아차리게 된다.
브로커가 정지하면 브로커를 나타내는 ZNode 역시 삭제되지만, 브로커의 ID 는 다른 자료구조에 남아 있게 된다.
예) 각 토픽의 레플리카 목록에는 해당 레플리카를 저장하는 브로커의 ID 가 포함되기 때문에 만일 특정 브로커가 완전히 유실되어 동일한 ID 를 가진 새로운 브로커를 투입할 경우, 곧바로 클러스터에서 유실된 브로커의 자리를 대신하여 이전 브로커의 토픽과 파티션들을 할당받음
각 토픽의 레플리카 목록에 관한 내용은 3. 복제 를 참고하세요.
2. 컨트롤러
컨트롤러는 일반적인 카프카 브로커의 기능에 더해서 파티션 리더를 선출하는 역할을 추가적으로 맡는다.
파티션 리더에 대한 내용은 2.5. 브로커, 클러스터, 컨트롤러, 파티션 리더, 팔로워 를 참고하세요.
클러스터에서 가장 먼저 시작되는 브로커는 주키퍼의 /controller 에 Ephemeral 노드를 생성함으로써 컨트롤러가 된다.
다른 브로커 역시 시작할 때 해당 위치에 노드를 생성하려고 시도하지만 ‘노드가 이미 존재함’ 예외를 받기 때문에 컨트롤러 노드가 이미 존재한다는 것을 알게 된다.
브로커들은 주키퍼의 컨트롤러 노드에 변동이 생겼을 때 알림을 받기 위해 이 노드에 와치 에 설정하는데 이를 통해 클러스터 안에 한 번에 단 한 개의 컨트롤러만 있도록 보장할 수 있다.
Ephemeral 노드는 삭제되는 경우는 아래와 같다.
- 컨트롤러 브로커가 멈추거나 주키퍼와의 연결이 끊어질 경우
- 컨트롤러가 사용하는 주키퍼 클라이언트가
zookeeper.session.timeout.ms에 설정된 값보다 더 오랫동안 주키퍼에 하트비트를 전송하지 않는 경우
Ephemeral 노드가 삭제될 경우 클러스터 안의 다른 브로커들은 주키퍼에 설정된 와치를 통해 컨트롤러가 없어졌다는 것을 알아차리게 되어 주키퍼에 컨트롤러 노드를 생성하려고 시도한다.
주키퍼에 가장 먼저 새로운 노드를 생성한 브로커가 다음 컨트롤러가 되며, 다른 브로커들은 ‘노드가 이미 존재함’ 예외를 받고 새 컨트롤러 노드에 대한 와치를 다시 생성한다.
브로커는 새로운 컨트롤러가 선출될 때마다 주키퍼의 조건적 증가 연산에 의해 증가된 epoch 값을 전달받게 된다.
브로커는 현재 컨트롤러의 epoch 값을 알고 있기 때문에 만일 더 낮은 epoch 값을 가진 컨트롤러로부터 메시지를 받을 경우 무시한다.
이 epoch 값은 컨트롤러 브로커가 오랫동안 가비지 수집 때문에 멈춘 사이 주키퍼와 연결이 끊어질 수 있기 때문에 중요하다. 그 사이에 새로운 컨트롤러가 선출될 수도 있기 때문이다.
이전 컨트롤러가 작업을 재개할 경우 새로운 컨트롤러가 선출되었다는 것을 알지 못한 채 브로커에 메시지를 보낼 수 있는데, 이런 컨트롤러를 좀비라고 한다.
컨트롤러가 전송하는 메시지에 컨트롤러 epoch 를 포함하면 브로커는 예전 컨트롤러가 보낸 메시지를 무시할 수 있는데 이는 좀비를 방지하는 방법이기도 한다.
브로커가 컨트롤러가 되면 클러스터 메타데이터 관리와 리더 선출을 시작하기 전에 먼저 주키퍼로부터 최신 레플리카 상태 맵을 읽어온다.
이 적재 작업은 비동기 API 로 수행되며, 지연을 줄이기 위해 읽기 요청을 여러 단계로 나눠서 주키퍼에 보내지만 그럼에도 불구하고 파티션 수가 매우 많은 클러스터에서는 적재 작업이 몇 초씩 걸릴 수 있다.
위 문제에 대한 테스트 결과는 아파치 카프카 1.1.0 블로그 포스트 에서 확인할 수 있음
주키퍼 경로에 와치를 설정해두었든 나가는 브로커로부터 ControlledShutdownRequest 를 받았든 브로커가 클러스터를 나갔다는 사실을 컨트롤러가 알게 되면, 컨트롤러는 해당 브로커가 리더를 맡고 있던 모든 파티션에 대해 새로운 브로커를 할당해주게 된다.
컨트롤러는 새로운 리더가 필요한 모든 파티션을 순회해가면서 새로운 리더가 될 브로커를 결정하는데 방법은 단순히 해당 파티션의 레플리카 목록에서 바로 다음 레플리카가 새 브로커가 된다.
그리고 나서 새로운 상태를 주키퍼에 쓴 뒤 (이 때도 지연을 줄이기 위해 요청을 여러 개로 나누어서 비동기 방식으로 주키퍼에 보냄) 새로 리더가 할당된 파티션의 레플리카를 포함하는 모든 브로커에게 LeaderAndISR 요청을 보낸다.
이 요청은 해당 파티션들에 대한 새로운 리더와 팔로워 정보를 포함하여, 효율성을 위해 배치 단위로 묶여서 전송된다.
즉, 각각의 요청은 같은 브로커에 레플리카가 있는 다수의 파티션에 대한 새 리더십 정보를 포함하게 되는 것이다.
새로 리더가 된 브로커 각각은 클라이언트로부터의 쓰기/읽기 요청을 처리하기 시작하고, 팔로워들은 새 리더로부터 메시지를 복제하기 시작한다.
클러스터 안의 모든 브로커들은 클러스터 내 전체 브로커와 레플리카의 맵을 포함하는 MetadataCache 를 갖고 있기 때문에 컨트롤러는 모든 브로커에 리더십 변경 정보를 포함하는 UpdateMetadata 요청을 보내서 각각의 캐시를 업데이트하도록 한다.
브로커가 백업을 시작할 때도 비슷한 과정이 반복되는데 차이점이라면 브로커에 속한 모든 레플리카들은 팔로워로 시작하고, 리더로 선출될 자격을 얻기 위해서는 그 전에 리더에 쓰여진 메시지를 따라잡아야 한다는 것이다.
요약하자면 컨트롤러는 브로커가 클러스터에 추가/제거될 때 파티션과 레플리카 중에서 리더를 선출할 책임을 가진다.
컨트롤러는 서로 다른 2개의 브로커가 자신이 현재 컨트롤러라 생각하는 스플릿 브레인 (split brain) 현상을 방지하기 위해 epoch 번호를 사용한다.
2.1. KRaft: 카프카의 Raft 기반 컨트롤러
아파치 카프카 커뮤니티는 주키퍼 기반 컨트롤러로부터 탈피하여 래프트 (raft) 기반 컨트롤러 쿼럼 프로젝트를 시작하였으며, KRaft 라고 불리는 새로운 컨트롤러 버전은 아파치 카프카 2.8 에 포함되었고, 3.3 부터는 프로덕션 환경에서 사용 가능하게 되었다.
카프카 커뮤니티가 컨트롤러를 교체하기로 한 이유는 아래와 같다.
- 주키퍼에 토픽, 파티션, 레플리카 정보를 저장하는 방식은 카프카에 필요로 하는 파티션 수까지 확장될 수 없음
- 브로커, 컨트롤러, 주키퍼 간에 메타데이터 불일치가 발생할 수 있으며, 잡아내기도 어려움
- 컨트롤러가 주키퍼에 메타데이터를 쓰는 작업을 동기적으로 이루어짐
- 브로커 메시지를 보내는 작업과 주키퍼로부터 업데이트를 받는 과정은 비동기적으로 이루어짐
- 파티션과 브로커의 수가 증가함에 따라 컨트롤러의 재시작은 더욱 느려짐
- 컨트롤러가 재시작될 때마다 주키퍼로부터 모든 브로커와 파티션에 대한 메타데이터를 읽어온 후 이 메타데이터를 모든 브로커로 전송함
- 이 부분에서 병목이 발생함
- 메타데이터 소유권 관련하여 내부 아키텍처가 좋지 못함
- 어떤 작업은 컨트롤러가 하고, 다른 건 브로커가 하고, 나머지는 주키퍼가 직접 함
- 카프카를 사용하기 위해 2개의 분산 시스템에 대해 알아야 함
- 주키퍼는 그 자체로 분산 시스템이며, 카프카와 마찬가지로 운영하기 위해서는 어느 정도 기반 지식이 있어야 함
위와 같은 이유로 아파치 카프카 커뮤니티는 주키퍼 기반 컨트롤러를 Kraft 기반 컨트롤러로 교체하게 되었다.
주키퍼는 중요한 기능 2개는 아래와 같다.
- 컨트롤러 선출
- 클러스터 메타데이터 저장
- 메타데이터는 현재 운영 중인 브로커, 설정, 토픽, 파티션, 레플리카 관련 정보임
또한 파티션 리더 선출, 토픽 생성/삭제, 레플리카 할당 시 사용되는 정보는 컨트롤러 그 자체가 관리하는 메타데이터이다.
새로운 컨트롤러 (= Raft) 설계의 핵심은 카프카 그 자체에 사용자가 상태를 이벤트 스트림으로 나타낼 수 있도록 하는 로그 기반 아키텍처를 도입한다는 점이다.
로그 기반 아키텍처의 장점은 카프카 커뮤니티에서는 이미 익숙한 것이다.
즉, 다수의 컨슈머를 사용하여 이벤트를 재생 (replay) 함으로써 최신 상태를 빠르게 따라잡을 수 있다.
로그는 이벤트 사이에 명확한 순서를 부여하며, 컨슈머들이 항상 하나의 타임라인을 따라 움직이도록 보장한다.
이러한 장점이 새로운 컨트롤러 아키텍처에서 메타데이터를 관리하는데에도 적용된다.
새로운 아키텍처에서 컨트롤러 노드들은 메타데이터 이벤트 로그를 관리하는 래프트 쿼럼이 된다.
이 로그는 클러스터 메타데이터의 변경 내역을 저장한다.
토픽, 파티션, ISR(In-Sync Replica), 설정 등등 주키퍼에 저장되는 모든 정보들이 여기에 저장된다.
Raft 알고리즘을 사용함으로써 컨트롤러 노드들은 외부 시스템에 의존하지 않고 자체적으로 리더를 선출할 수 있다.
메타데이터 로그의 리더 역할을 맡고 있는 컨트롤러를 액티브 컨트롤러라고 하며, 액티브 컨트롤러는 브로커가 보내온 모든 RPC 호출을 처리한다.
팔로워 컨트롤러들은 액티브 컨트롤러에 쓰여진 데이터들을 복제하며, 액티브 컨트롤러에 장애 발생 시 즉시 투입될 수 있도록 준비 상태를 유지한다.
컨트롤러들이 모두 최신 상태를 갖고 있으므로 컨트롤러 장애 복구 시 모든 상태를 새 컨트롤러로 이전하는 긴 reload 시간은 필요 없어진다.
컨트롤러가 다른 브로커에게 변경사항은 push 하는 대신 다른 브로커들이 새로 도입된 MetadataFetch API 를 이용하여 액티브 컨트롤러로부터 변경 사항을 pulling 한다.
컨슈머의 읽기 요청과 유사하게 브로커는 마지막으로 가져온 메타데이터 변경 사항의 오프셋을 추적하고 그보다 나중 업데이트만 컨트롤러에 요청한다.
브로커는 나중에 시동 시간을 줄이기 위해 파티션이 수백만개가 되더라도 메타데이터를 디스크에 저장한다.
브로커 프로세스는 시작 시 주키퍼가 아닌 컨트롤러 쿼럼에 등록한다.
그리고 운영자가 등록을 해제하지 않는 한 이를 유지하기 때문에 브로커가 종료되어도 오프라인 상태로 들어가는 것일 뿐 등록은 여전히 유지된다.
온라인 상태지만 최신 메타데이터로 최신 상태를 유지하고 있지 않은 브로커의 경우 펜스된 상태(fenced state) 가 되어 클라이언트의 요청을 처리할 수 없다.
브로커에 새로 도입된 펜스된 상태는 클라이언트가 더 이상 리더가 아닌, 하지만 최신 상태에서 너무 떨어지는 바람에 자신이 리더가 아니라는 것을 인식하지 못하는 브로커에 쓰는 것을 방지한다.
컨트롤러 쿼럼으로의 마이그레이션 작업의 일부로서, 기존에 주키퍼와 직접 통신하던 모든 클라이언트, 브로커 작업들은 이제 컨트롤러로 보내지게 된다.
이렇게 함으로써 브로커 쪽에는 아무것도 바꿀 것 없이 컨트롤러를 바꿔주는 것만으로 매끄러운 마이그레이션이 가능하다.
새 아키텍처의 전체적인 디자인은 KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum 에 나와있다.
Raft 프로토콜을 카프카에 적용하는 것에 대한 상세한 내용은 KIP-595: A Raft Protocol for the Metadata Quorum 에서 다룬다.
컨트롤러 설정과 클러스터 메타데이터와 상호작용하기 위한 새로운 명령줄 인터페이스를 포함하여 새 컨트롤러 쿼럼에 대한 구체적인 설계는 KIP-631: The Quorum-based Kafka Controller 에 나와있다.
2.2. KRaft 이전의 컨트롤러와 이후의 컨트롤러
카프카에서 커밋이 2가지의 의미로 사용될 수 있듯이 컨트롤러도 두 가지 의미로 쓰일 수 있다.
카프카에서 커밋이 2가지의 의미로 사용되는 부분에 대해서는 5. 신뢰성 있는 컨슈머 설정 을 참고하세요.
<KRaft 도입 이전의 카프카>
- 주키퍼 프로세스
- 카프카 클러스터의 동적 메타데이터를 저장하는 역할
- 홀수 개의 프로세스가 하나의 쿼럼을 구성하며, 이 중에서 저장된 데이터의 업데이트 작업을 담당하는 리더 프로세스가 하나 있음
- 카프카 프로세스
- 카프카 데이터를 저장하는 역할
- 이들 중에서 리더 파티션을 결정하는 역할을 하는 프로세스를 컨트롤러라고 함
KRaft 도입 이후부터는 주키퍼 프로세스가 제거되기 때문에 카프카 프로세스 외에 다른 프로세스는 없다.
다만, 카프카 프로세스가 아래 2개 중에 적어도 하나의 역할을 갖게 된다. (= 2개의 역할을 모두 겸할 수도 있음)
<KRaft 도입 이후 카프카 프로세스 역할>
- 컨트롤러
- 카프카 클러스터의 동적 메타데이터를 저장하는 역할
- 1개 이상의 프로세스가 하나의 쿼럼을 구성함, 이 중에서 저장된 데이터의 업데이트 및 조회 작업을 담당하는 프로세스를 액티브 컨트롤러라고 함
- 브로커
- 카프카 데이터를 저장하는 역할
- 하나의 컨트롤러 쿼럼을 사용하는 브로커들이 모여 하나의 클러스터를 이룸
즉, KRaft 이전의 브로커는 카프카 프로세스와 동의어이지만 KRaft 이후의 브로커는 카프카 프로세스가 맡을 수 있는 특정한 역할을 의미한다.
비슷하게 KRaft 이전의 컨트롤러는 브로커 중에서 파티션 리더를 결정하는 역할을 맡은 어느 특별한 브로커를 가리키지만, KRaft 이후의 컨트롤러는 동적 메타데이터를 저장하는 역할을 하는 카프카 프로세스를 가리킨다.
따라서 컨트롤러와 같은 용어가 나오면 KRaft 이전의 것을 의미하는지 이후의 것을 의미하는지 살펴볼 필요가 있다.
2.3. KRaft 릴리즈 정보
KIP-833: Mark KRaft as Production Ready 에 내용을 보면 아래와 같다.
- 2021년 카프카 2.8과 KRaft early access
- 2022년 카프카 3.3과 KRaft Production ready
- 2023년 카프카 3.5과 주키퍼 모드 deprecated, 주키퍼 마이그레이션 Preview
- 2023년 카프카 3.6과 주키퍼 마이그레이션 GA
- 2024년 카프카 3.7과 주키퍼 모드 지원 마지막 버전
- 2024년 카프카 4.0과 KRaft only 모드 지원
따라서 카프카 4.0 공개 후 카프카의 필수 최신 기능을 사용하기 위해서는 KRaft 모드로의 마이그레이션이 필수적이다.
2.4. 주키퍼에서 KRaft 로 마이그레이션: Bridge Release (브리지 릴리즈)
주키퍼에서
KRaft로의 마이그레이션 공식 문서는 Migrate from ZooKeeper to KRaft on Confluent Platform 을 참고하세요.
주키퍼가 제거되고
KRaft모드만 지원하는 시점에 대해서는 1.4. 추가 참고 사항 을 참고하세요.
주키퍼없이 카프카를 운영할 수 있게 해주는 KRaft 는 확실히 매력적이다.
아파치 카프카 커뮤니티는 하방 호환성을 유지하면서 기존에 주키퍼에 저장된 메타데이터를 컨트롤러 쿼럼으로 이전시킬 수 있도록 하기 위해 브리지 릴리즈를 제공하고 있다.
브리지 모드는 주키퍼 모드와 KRaft 모드를 동시에 지원하며, 두 모드 사이의 다리 역할을 하게 된다.
따라서 KRaft 도입 이전부터 사용되던 카프카 클러스터는 이 브리지 모드를 거쳐서 KRaft 를 사용하는 클러스터로 업그레이드가 가능하다.
아래는 전통적인 카프카(pre-KRaft), 적용 중인 카프카(브리지 릴리즈), KRaft 적용이 완료된 이후(Post-KRaft) 의 작동에 대한 그림이다.
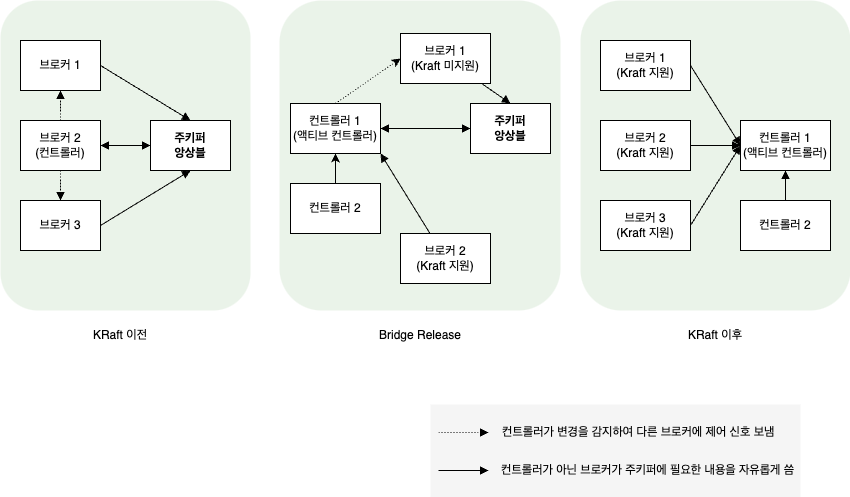
- Pre-KRaft
KRaft가 적용되기 이전 클러스터- 3.0 이전 버전 혹은
KRaft쿼럼 관련 설정이 되어 있지 않은 3.0 이후 버전을 사용하는 클러스터 - 메타데이터를 저장하기 위해 주키퍼 앙상블을 사용
- 어떤 브로커나 컨트롤러가 될 수 있음
- 컨트롤러가 아닌 브로커가 주키퍼에 필요한 내용을 자유롭게 씀(=실선)
- 컨트롤러가 변경을 감지해서 다른 브로커에 제어 신호를 보냄(=점선)
KRaft이전의 브로커, 클러스터, 컨트롤러, 파티션 리더에 대한 내용은 2.5. 브로커, 클러스터, 컨트롤러, 파티션 리더, 팔로워 를 참고하세요.
- 브리지 릴리즈
- 부분적으로
KRaft가 적용된 클러스터 - 이 때부터 컨트롤러, 브로커의 의미가 변경됨
- 컨트롤러로는
KRaft기능이 지원되는 3.0 이후의 버전이 필요하지만 일반 브로커로는 3.0 이전 버전도 사용 가능 - 전체 클러스터를 내린 상태에서 컨트롤러를 먼저 올리면 액티브 컨트롤러가 선출되면서 주키퍼에 저장된 메타데이터를 가져옴
- 이 때 주키퍼의
/controller노드를 생성해서 다른 브로커가 Pre-KRaft 컨트롤러 자격을 얻지 못하게 함
- 이 때 주키퍼의
- 이후 3.0 이후 버전을 사용하는 브로커는 액티브 컨트롤러에서 메타데이터를 읽고 쓰는 방식(= 실선)으로 작동
- 3.0 이전 버전을 사용하는 브로커는 주키퍼에 필요한 것을 쓰면서(= 실선) 이를 감지한(= 실선) 액티브 컨트롤러가 적절한 제어 신호를 보내주는 방식(=점선)으로 동작함 -액티브 컨트롤러는 Post-KRaft 에서 기대되는 기능 외에도 3.0 이전의 컨트롤러가 하던 작업까지 수행함으로써 하방 호환성을 유지함
- 즉, 주키퍼가 사용되기는 하지만, 대부분의 메타데이터는 이미 컨트롤러 쿼럼으로 옮겨간 상태이며, 주키퍼는 3.0 이전 버전 브로커들을 위해 제한적으로만 사용됨
- 부분적으로
- Post-KRaft
- 브리지 릴리즈 상태에서 3.0 이전 버전 브로커들은 3.0 이후 브로커로, 컨트롤러들은 주키퍼 관련 설정을 제거한 상태로 롤링 업그레이드를 해주면 완료됨
- 이 때부터는 주키퍼가 전혀 사용되지 않으므로 제거해도 상관없음
기존에 사용하면 Pre-KRaft 클러스터를 Post-KRaft 클러스터로 업그레이드하려면 전체 클러스터를 내리고 브리지 릴리즈로 업그레이드를 한 뒤 다시 한번 업그레이드를 해야 한다.
즉, 적어도 한 번은 클러스터를 완전히 정지시켜줘야 하는 것이다.
서비스 특성 상 카프카 클러스터를 중단시킬 수 없거나, 복잡한 업그레이드 과정을 거치고 싶지 않거나, 카프카 클러스터의 크기가 커서 롤링 재시작이 어렵다면 Post-KRaft 카프카 클러스터를 구축해놓은 후에 기존 데이터를 미러링하여 옮기는 것도 방법이다.
미러링에 대해서는
Kafka - 데이터 미러링(1): 다중 클러스터 아키텍처,
Kafka - 데이터 미러링(2): 미러메이커
를 참고하세요.
2.5. KRaft 모드 사용법
해당 책이 카프카 버전 2.8.0 때 쓰여진 책이라
KRaft기능이 구현되지 않았던 시기였지만, 버전 3.3.0 이후로 정식 기능이 되었음
따라서KRaft에 대해 다른 신기능이 있을 수 있음을 참고하고 보자.
KRaft 모드 클러스터를 설정해보자.
2.5.1. 클러스터 ID 생성 및 저장 공간 포맷
가장 먼저 해줘야 할 일은 클러스터 ID(UUID)를 생성하고 로그 저장 공감을 포맷하는 것이다.
포맷이라고 하지만 사실 클러스터 정보를 비롯한 메타데이터를 저장한 파일을 로그 저장 공간으로 사용되는 디렉터리마다 생성해주는 정도이다.
카프카가 설치된 위치에서 아래와 같이 kafka-storage.sh 를 실행하면 클러스터 ID 가 생성된다.
bin/kafka-storage.sh random-uuid
이 값을 갖고 아래와 같이 실행하면 카프카 설정 파일에 지정되어 있는 log.dirs 설정 디렉터리마다 메타데이터 파일이 생성된다.
bin/kafka-storage.sh format -t {클러스터 ID} -c {카프카 설정 파일}
클러스터 ID 는 새 클러스터를 설정할 때 한 번만 생성해주면 되지만, 포맷 작업은 서버를 설정할 때마다 해주어야 한다.
즉, 1개 서버로만 구성된 클러스터를 생성한다면 한 번만 포맷을 해줘도 되지만 5개의 서버로 구성된 클러스터를 생성한다면 포맷을 모두 5번 해주어야 한다.
새로운 서버를 추가 투입할 때도 마찬가지로 포맷을 먼저 해주어야 한다.
2.5.2. 설정 변경
카프카 버전 3.3.0 부터 KRaft 모드 예제 설정 파일이 함께 제공된다.
$ pwd
kafka/kafka_2.13-3.8.0/config/kraft
$ ll
-rw-r--r--@ 1 staff 6.0K Jul 23 17:04 broker.properties
-rw-r--r--@ 1 staff 5.6K Jul 23 17:04 controller.properties
-rw-r--r--@ 1 staff 6.2K Jul 23 17:04 server.properties
broker.properties- 해당 서버가 브로커 역할을 할 때의 예제 설정 파일
controller.properties- 해당 서버가 컨트롤러 역할을 하도록 설정할 때의 예제 설정 파일
server.properties- 해당 서버가 브로커, 컨트롤러 역할 둘 다 할 때의 예제 설정 파일
- 프로덕션 환경에서는 사용하지 않는 것을 권장함
3. 브로커 설정 에서 다룬 기존 설정 파일과 다른 매개 변수는 아래와 같다.
아래 매개 변수는 3개 파일 모두에 공통적으로 들어가있다.
2.5.2.1. process.roles
해당 인스턴스가 수행할 역할을 설정한다.
- broker
- 브로커 역할
- controller
- 컨트롤러 역할
- broker, controller
- 두 역할 모두 수행
server.properties 의 예시값
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
2.5.2.2. node.id
인스턴스의 id 이다.
기존의 broker.id 설정을 대체하며, 같은 클러스터에 속한 인스턴스들은 이 설정값이 서로 달라야 한다.
즉, node.id 가 1 인 컨트롤러가 있다면 node.id 가 1 인 브로커는 있을 수 없다.
server.properties 의 예시값
# The node id associated with this instance's roles
node.id=1
2.5.2.3. controller.quorum.voters
사용할 컨트롤러 쿼럼을 지정한다.
{컨트롤러의 node.id 값}@{컨트롤러의 호스트명}:{포트명} 을 쉼표로 구분하여 지정한다.
브로커가 9092 포트를 기본값으로 사용하듯이 컨트롤러는 9093 포트를 기본값으로 사용한다.
전체 컨트롤러 쿼럼을 모두 지정해 줄 필요는 없지만, 여유있게 2개 이상을 지정하는 것을 권장한다.
3 개의 컨트롤러 쿼럼을 지정한 경우
controller.quorum.voters=1@controller1.test.com:9093,2@controller2.test.com:9093,3@controller3.test.com:9093
2.5.2.4. listeners
기존의 listeners 와 같은 역할을 하지만, 브로커 리스너 뿐 아니라 컨트롤러 리스너도 설정할 수 있도록 확장되었다.
해당 인스턴스가 브로커 역할을 한다면 기존과 똑같이 설정해도 돼지만, 컨트롤러 역할을 한다면 CONTROLLER://: 로 시작하는 리스너를 설정해주어야 한다.
컨트롤러 리스너 이름은 controller.listener.names 설정을 이용하여 변경할 수 있다.
# 브로커 역할만 하는 경우
listeners=PLAINTEXT://:9092
# 컨트롤러 역할만 하는 경우
listeners=CONTROLLER://:9093
# 브로커와 컨트롤러 역할을 모두 하는 경우
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
2.5.2.5. log.dirs
기존의 log.dirs 와 같은 역할을 하지만, 레코드 로그 파일 뿐 아니라 메타데이터 로그 파일 역시 저장될 수 있다는 점이 다르다.
브로커 역할만 하는 경우라면 기존과 똑같이 동작하고, 컨트롤러 역할을 한다면 메타데이터 로그 파일이 저장된다.
두 역할을 동시에 수행하는 경우라면 두 로그 파일이 함께 저장된다.
# controller, broker 역할을 모두 하는 프로세스 시작
$ bin/kafka-server-start.sh config/kraft/server.properties
# controller 역할을 하는 프로세스 시작
$ bin/kafka-server-start.sh config/kraft/controller.properties
# broker 역할을 하는 프로세스 시작
$ bin/kafka-server-start.sh config/kraft/broker.properties
# test 토픽 생성
$ bin/kafka-topics.sh --create --topic test --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092
2.5.3. KRaft 모드로 실행
설정을 잡아주었다면 카프카를 KRaft 모드로 실행시킬 수 있다.
3. 복제: 레플리카 종류
복제에 대한 추가 설명은 2. 복제 를 참고하세요.
카프카는 ‘분산되고, 분할되고, 복제된 커밋 로그 서비스’ 로 표현되기도 한다.
복제가 중요한 이유는 개별적인 노드에 필연적으로 장애가 발생할 수밖에 없는 상황에서 카프카가 신뢰성과 지속성을 보장하는 방식이기 때문이다.
카프카에 저장되는 데이터는 토픽 단위로 해서 조직화된다.
각 토픽은 1개 이상의 파티션으로 분할되며, 각 파티션은 다시 다수의 레플리카를 가질 수 있다.
각각의 레플리카는 브로커에 저장되는데, 대개 하나의 브로커(= 서로 다른 토픽과 파티션에 속하는)는 수백개에서 수천개의 레플리카를 저장한다.
<레플리카의 종류>
- 리더 레플리카
- 각 파티션에는 리더 역할을 하는 레플리카가 하나씩 있음
- 일관성을 보장하기 위해 모든 쓰기 요청은 리더 레플리카로 주어짐
- 클라이언트들은 리더 레플리카나 팔로우로부터 레코드를 읽어올 수 있음
- 팔로워 레플리카
- 파티션에 속한 모든 레플리카중 리더 레플리카를 제외한 나머지 레플리카들
- 별도로 설정을 잡아주지 않는 한, 팔로워는 클라이언트의 요청을 처리할 수 없음
- 리더 레플리카로 들어온 최근 메시지들을 복제함으로써 최신 상태를 유지함
- 해당 파티션의 리더 레플리카에 크래쉬가 날 경우, 팔로워 레플리카 중 하나가 파티션의 새로운 리더 레플리카로 승격됨
리더 레플리카(를 저장하고 있는 브로커) 의 또 다른 역할은 팔로워 레플리카들이 리더 레플리카의 최신 상태를 유지하고 있는지 확인하는 것이다.
팔로워 레플리카(를 저장하고 있는 브로커)는 새로운 메시지가 도착하는 즉시 리더 레플리카로부터 모든 메시지를 복제해옴으로써 최신 상태를 유지하지만 네트워크 혼잡으로 인한 속도 저하, 브로커 크래시로 인해 브로커가 재시작되어 복제 작업을 다시 시작할 수 있게 될 때까지 해당 브로커에 저장되어 있는 모든 레플리카들의 복제 상태가 뒤쳐지는 등의 이유로 동기화가 깨질 수 있다.
3.1. 팔로워 레플리카로부터 데이터 읽기
팔로워 레플리카로부터 메시지를 읽는 기능은 KIP-392: Allow consumers to fetch from closest replica 부터 추가되었다.
이 기능의 주 목표는 클라이언트가 리더 레플리카 대신 가장 가까이에 있는 ISR(In-Sync Replica) 로부터 읽을 수 있게 함으로써 네트워크 트래픽 비용을 줄이는 것이다.
이 기능을 사용하려면 아래와 같은 설정을 해주어야 한다.
- 컨슈머 설정
- 클라이언트의 위치를 지정하는
client.rack설정
- 클라이언트의 위치를 지정하는
- 브로커 설정
replica.selector.class설정- 이 설정의 기본값은
LeaderSelector(= 항상 리더로부터 읽어옴) 인데,RackAwareReplicaSelector(= 클라이언트의client.rack설정값과 일치하는rack.id설정값을 갖는 브로커에 저장된 레플리카로부터 읽어옴) 로 설정할 수 있음
- 이 설정의 기본값은
ReplicaSelector인터페이스를 사용하여 레플리카 선택 로직을 직접 구현하여 사용할 수도 있음
복제 프로토콜은 클라이언트가 팔로워 레플리카로부터 메시지를 읽어올 경우에도 커밋된 메시지만 읽어오도록 확장되었다.
즉, 팔로워 레플리카로부터 메시지를 읽어올 때도 이전과 동일한 신뢰성이 보장된다.
그러기 위해선 모든 레플리카가 리더가 어느 메시지까지 커밋했는지를 알아야 하므로 리더는 팔로워에게 보내는 데이터에 현재의 하이 워터마크(high-water mark) 혹은 마지막으로 커밋된 오프셋 값을 포함시킴으로써 팔로워에게 알려준다.
하이 워터마크 전파에는 약간의 시간이 걸리기 때문에 데이터를 읽을 때는 리더 쪽에서 읽는 것이 팔로워로부터 읽는 것보다 조금 더 빠르다.
이 말은 리더 레플리카에서 읽으면 컨슈머 지연이 줄어든다는 장점이 있고, 팔로워 레플리카에서 읽으면 네트워크 트래픽 비용을 줄이는 대신 추가 지연이 있다는 의미이다.
3.2. 리더 레플리카와의 동기화 유지
리더 레플리카와의 동기화를 유지하기 위해 팔로워 레플리카들은 리더 레플리카에게 읽기 요청을 보내는데 이 요청은 컨슈머가 메시지를 읽어오기 위해 사용하는 바로 그 요청이기도 하다.
요청에 대한 응답으로 리더 레플리카(를 저장하고 있는 브로커)는 메시지를 되돌려주는데 복제를 수행하는 입장에서 다음에 받아야 할 메시지 오프셋과 함께 언제나 메시지를 순서대로 돌려준다.
즉, 리더 레플리카 입장에서는 팔로워 레플리카가 요청한 마지막 메시지까지 복제를 완료했는지, 이후 새로된 추가 메시지는 없는지의 여부를 알 수 있는 것이다.
리더 레플리카는 각 팔로워 레플리카가 마지막으로 요청한 오프셋 값을 확인함으로써 각 팔로워 레플리카가 얼마나 뒤쳐져있는지 알 수 있다.
만일 팔로워 레플리카가 일정 시간 이상 읽기 요청을 보내지 않건, 읽기 요청을 보냈지만 가장 최근에 추가된 메시지를 따라잡지 못하는 경우 해당 레플리카는 동기화가 풀린 것으로 간주한다.
이런 레플리카를 Out-of-sync Replica 하며, 해당 레플리카는 장애 상황에서 리더가 될 수 없다.
반대로 지속적으로 최신 메시지를 요청하고 있는 레플리카는 ISR(In-Sync replica) 라고 한다.
현재 리더에 장애가 발생한 경우 ISR 만이 파티션 리더로 선출될 수 있다.
팔로워 레플리카가 동기화가 풀린 것으로 판정될 때까지 걸리는 시간, 즉 읽기 요청을 보내지 않거나 뒤쳐진 상태로 있을 수 있는 일정 시간은 replica.lag.time.max.ms 설정 매개 변수에 의해 결정된다. (replica.lag.time.max.ms 기본값은 30s)
이렇게 허용될 수 있는 lag 의 양은 클라이언트의 작동이나 리더 선출 과정에 있어서 데이터 보존에도 영향을 미치는데 이에 대한 상세한 내용은 3.4. 레플리카를 In-Sync 상태로 유지:
zookeeper.session.timeout.ms,replica.lag.time.max.ms를 참고하세요.
3.3. 선호 리더(Preferred leader)
각 파티션은 선호 리더를 갖고 있다.
선호 리더는 토픽이 처음 생성되었을 때 리더 레플리카였던 레플리카를 말한다.
파티션이 처음 생성되는 시점에는 리더 레플리카가 모든 브로커에 걸쳐 균등하게 분포되기 때문에 선호 라는 표현이 붙음
클러스터 내의 모든 파티션에 대해 선호 리더가 실제 리더가 될 경우 부하가 브로커 사이에 균등하게 분배될 것으로 예상할 수 있다.
카프카에는 auto.leader.rebalance.enable=true 설정이 기본으로 잡혀있다.
이 설정은 선호 리더가 현재 리더가 아니지만, 현재 리더와 동기화가 되고 있을 경우 리더 선출을 실행시킴으로써 선호 리더를 현재 리더로 만들어준다.
선호 리더를 알 수 있는 방법은 파티션의 레플리카 목록을 보는 것이다. (kafka-topics.sh 툴이 출력하는 파티션과 레플리카 상세 정보에서 보면 됨)
이 목록에 표시된 첫 번째 레플리카가 선호 리더이다.
수동으로 레플리카를 재할당하고 있다면 첫 번째로 지정하는 레플리카가 선호 레플리카가 된다는 점을 알 필요가 없다.
반드시 선호 레플리카를 서로 다른 브로커들로 분산함으로써 부하가 한 쪽으로 몰리지 않도록 하는 것이 좋다.
4. 요청 처리
카프카 브로커가 하는 일은 대부분 클라이언트, 파티션 replica, 컨트롤러가 파티션 리더에게 보내는 요청을 처리하는 것이다.
언제나 클라이언트가 연결을 시작하고 요청을 전송하며, 브로커는 요청을 처리하고 클라이언트로 응답을 보낸다.
특정 클라이언트가 브로커로 전송한 모든 요청은 브로커가 받은 순서대로 처리하기 때문에 카프카가 저장하는 메시지는 순서가 보장되며, 이러한 동작 방식으로 인해 카프카를 메시지 큐로 사용할 수 있다.
모든 요청은 아래를 포함하는 표준 헤더를 갖는다.
- 요청 유형
- API 키라고도 함
- 요청 버전
- 브로커는 서로 다른 버전의 클라이언트로부터 요청을 받아 각각의 버전에 맞는 응답을 할 수 있음
- Correlation ID
- 각각의 요청에 붙는 고유한 식별자
- 응답이나 에러 로그에도 포함됨
- 클라이언트 ID
- 요청을 보낸 애플리케이션을 식별하기 위해 사용됨
브로커 내부에서 요청이 어떻게 처리되는지 알아두면 나중에 카프카 모니터링할 때와 설정 옵션에 대해 셋팅할 때 모니터링 지표와 설정 매개 변수들이 어떤 큐와 스레드에 연관되는지에 대해 알 수 있다.
브로커는 연결을 받는 각 포트별로 Acceptor 스레드를 하나씩 실행시킨다.
Acceptor 스레드는 연결을 생성하고, 들어온 요청을 Processor 스레드(= 네크워크 스레드)에 넘겨 처리하도록 한다.
Processor 스레드의 수는 설정 가능하며, 클라이언트 연결로부터 들어온 요청들을 받아서 요청 큐에 넣고, 응답 큐에서 응답을 가져다가 클라이언트로 보낸다.
가끔 클라이언트로 보낼 응답에 지연이 필요한 때가 있다.
- 컨슈머의 경우
- 브로커 쪽에 데이터가 준비되었을 때만 응답을 보낼 수 있음
- 어드민 클라이언트의 경우
- 토픽 삭제가 진행 중인 상황에서만
DeleteTopicRequest요청에 대한 응답을 보낼 수 있음
- 토픽 삭제가 진행 중인 상황에서만
지연된 응답들은 완료될 때까지 퍼거토리(Purgatory) 에 저장된다.
아래는 위의 과정(카프카 내부의 요청 처리)이다.
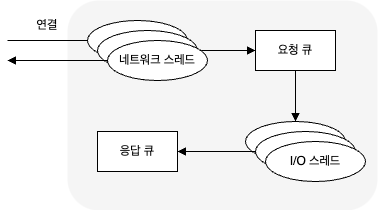
요청이 요청 큐에 들어오면 I/O 스레드(= 요청 핸들러 스레드)가 요청을 가져와서 처리하는 일을 담당한다.
- 쓰기 요청
- 카프카 브로커로 메시지를 쓰고 있는 프로듀서가 보낸 요청
- 읽기 요청
- 카프카 브로커로부터 메시지를 읽어오고 있는 컨슈머가 팔로워 레플리카가 보낸 요청
- 어드민 요청
- 토픽 생성, 삭제와 같이 메타데이터 작업을 수행 중인 어드민 클라이언트가 보낸 요청
쓰기 요청과 읽기 요청은 모두 파티션의 리더 레플리카로 전송되어야 한다.
만일 브로커가 다른 브로커가 리더를 맡고 있는 파티션에 대한 쓰기 요청이나 읽기 요청을 받을 경우, 해당 요청을 보낸 클라이언트는 Not a Leader for Partition 에러 응답을 받는다.
카프카의 클라이언트는 요청에 맞는 파티션의 리더를 맡고 있는 브로커에 쓰기나 읽기 요청을 전송해야 한다.
카프카 클라이언트는 메타데이터 요청이라고 불리는 또 다른 유형의 요청을 사용하는데, 이 요청은 클라이언트가 다루고자 하는 토픽들의 목록을 포함한다.
서버는 이 토픽들에 어떤 파티션이 있고, 각 파티션의 레플리카에 무엇이 있으며, 어떤 레플리카가 리더인지 명시하는 응답을 리턴한다.
모든 브로커들은 이러한 정보를 포함하는 메타데이터 캐시를 갖고 있기 때문에 메타데이터 요청은 아무 브로커에나 보내도 된다.
이런 메타데이터 요청을 통해 카프카 클라이언트는 어디로 요청을 보내야하는 것인지 알 수 있는 것이다.
클라이언트는 보통 이 정보를 캐시해두었다가 각 파티션의 리더 역할을 맡고 있는 브로커에 바로 쓰거나 읽는다.
클라이언트는 토픽 메타데이터를 최신값으로 유지하기 위해 주기적으로 메타데이터 요청을 보내서 새로고침한다.
새로고침 간격은 metadata.max.age.ms 설정 매개변수로 조절 가능하다.
만일 클라이언트가 Not a Leader for Partition 에러를 받는다면 클라이언트가 이미 만료된 정보를 사용중이라는 것이므로 요청을 재시도하기 전에 메타데이터를 먼저 새로고침한다.
4.1. 쓰기 요청
4.2. acks 에서 본 것처럼 acks 설정 매개 변수는 쓰기 작업이 성공한 것으로 간주되기 전 응답을 보내야하는 브로커의 수를 가리킨다.
어느 시점에 메시지가 성공적으로 쓰여졌다 라고 간주되는지는 프로듀서 설정을 통해 변경할 수 있다.
acks=0- 메시지가 보내졌을 때, 즉 브로커의 응답을 기다리지 않음
acks=1- 리더 레플리카가 메시지를 받았을 때
acks=all(기본값)- 모든 ISR(In-Sync Replica) 들이 메시지를 받았을 때
파티션의 리더 레플리카를 갖고 있는 브로커가 해당 파티션에 대한 쓰기 요청을 받게 되면 아래와 같은 유효성 검증부터 한다.
- 데이터를 보내고 있는 사용자가 토픽에 대한 쓰기 권한이 있는지?
- 요청에 저장되어 있는
acks의 설정값이 올바른지? (0 or 1 or all 만 가능) acks=all인 경우 메시지를 안전하게 쓸 수 있을만큼 충분한 ISR(In-Sync Replica) 가 있는지?- ISR 수가 설정된 값 아래로 내려가면 새로운 메시지를 받지 않도록 브로커 설정 가능함
위 기능에 대해서는 3.3. 최소 ISR(In-Sync Replica):
min.insync.replicas를 참고하세요.
이후 브로커는 새 메시지들을 로컬 디스크에 쓰는데 카프카는 데이터가 디스크에 저장될 때까지 기다리지 않는다.
즉, 메시지의 지속성을 위해 복제에 의존하는 것이다.
메시지가 파티션 리더에 쓰여지고 나면 브로커는 acks 설정에 따라 응답을 보낸다.
0 or 1 이면 바로 응답을 보내고, all 이면 일단 요청을 퍼거토리라는 버퍼에 저장한다.
이후 팔로워 레플리카들이 메시지를 복제한 것을 확인한 후에 클라이언트에 응답을 보낸다.
4.2. 읽기 요청
브로커는 쓰기 요청이 처리되는 것과 유사한 방식으로 읽기 요청을 처리한다.
클라이언트는 토픽, 파티션, 오프셋 목록에 해당하는 메시지들을 보내달라는 요청을 보낸다.
예) A 토픽의 파티션 0 오프셋 11 부터의 메시지와 파티션 3 오프셋 15 부터의 메시지 요청
클라이언트는 브로커가 되돌려 준 응답을 담을 수 있을 정도로 충분히 큰 메모리를 할당해야 하므로 각 파티션에 대해 브로커가 리턴할 수 있는 최대 데이터 양 역시 지정하여 보낸다.
이 한도값이 없을 경우 브로커는 클라이언트가 메모리 부족이 될 수 있을 정도로 큰 응답을 보낼 수도 있다.
4. 요청 처리 에서 본 것처럼 요청은 요청에 지정된 파티션들의 리더 브로커에게 전송되어야 하고, 클라이언트는 읽기 요청을 정확히 라우팅할 수 있도록 메타데이터에 대한 요청을 보낸다.
요청을 받은 파티션 리더는 먼저 요청이 유효(지정된 오프셋이 해당 파티션에 존재하는지?)한지 확인한 후 유효하지 않을 경우 브로커는 에러를 응답으로 보낸다.
오프셋이 존재하면 브로커는 파티션으로부터 클라이언트가 요청에 지정한 크기 한도만큼의 메시지를 읽어서 클라이언트에게 응답한다.
카프카는 클라이언트에게 보내는 메시지에 제로카피(zero-copy) 최적화를 적용하는 것으로 유명하다.
즉, 파일에서 읽어온 메시지들을 중간 버퍼를 거치지 않고 바로 네트워크 채널로 보내는 것이다.
이 점이 클라이언트에게 데이터를 보내기 전에 로컬 캐시에 저장하는 대부분의 DB 와의 차이점이며, 이 방식을 채택함으로써 데이터를 복사하고 메모리 상에 버퍼를 관리하기 위한 오버헤드가 사라져서 결과적으로 성능이 향상된다.
브로커가 리턴하는 데이터 양의 상한을 지정하는 것처럼 리턴될 데이터 양의 하한도 지정할 수 있다.
이는 클라이언트가 트래픽이 그리 많이 않은 토픽들로부터 메시지를 읽어오고 있을 때 CPU 와 네트워크 사용량을 줄일 수 있는 좋은 방법이다.
클라이언트가 요청을 보냈을 때 브로커는 충분한 양의 데이터가 모일 때까지 기다린 후 리턴한다.
이렇게 함으로써 전체적으로 같은 양의 데이터를 읽지만 데이터를 주고 받는 횟수는 훨씬 적으므로 오버헤드가 줄어들게 된다.
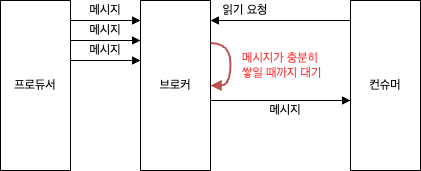
브로커가 충분한 데이터를 가질 때까지 무한정 기다릴 순 없으니 클라이언트는 브로커에게 데이터를 요청할 때 타임아웃도 지정할 수 있다.
예) 10ms 안에 하한량만큼의 데이터가 모이지 않으면 현재까지 모인 데이터 전송
클라이언트가 파티션 리더에 존재하는 모든 데이터를 읽을 수 있는 건 아니다.
대부분의 클라이언트는 모든 ISR(In-Sync Replica) 에 쓰여진 메시지만을 읽을 수 있을 뿐이다. (팔로워 레플리카 역시 컨슈머이지만 복제 기능이 동작해야 하므로 이 룰에서는 예외임)
파티션 리더는 어느 메시지가 어느 레플리카로 복제되었는지 알고 있으며, 특정 메시지가 모든 ISR 에 쓰여지기 전까지는 컨슈머들이 읽을 수 없다. (이 메시지를 읽으려고 하면 에러는 안 나지만 빈 응답이 리턴됨)
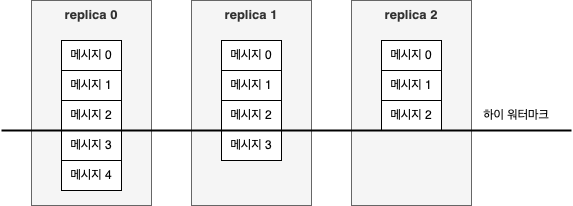
위 그림에서 컨슈머들은 메시지 0,1,2 들만 읽을 수 있다.
이렇게 동작하는 이유는 아래와 같다.
- 충분한 수의 레플리카에 복제가 완료되지 않은 메시지들은 불안전한 것으로 간주됨
- 만일 리더 브로커에 크래시가 발생해서 다른 레플리카가 리더 역할을 이어받는다면 복제가 완료되지 않은 메시지들은 더 이상 카프카에 존재하지 않게 됨
- 클라이언트가 이렇게 리더에만 존재하는 메시지들을 읽을 수 있도록 한다면 크래시 상황에서 일관성이 결여될 수 있음
- 예) 컨슈머가 어떤 메시지를 읽은 상태에서 리더 브로커에 크래시가 나고, 다른 브로커에 해당 메시지가 복제된 적이 없다면 이 메시지는 사라짐
다른 컨슈머들은 해당 메시지를 읽을 길이 없기 때문에 컨슈머들이 읽어 온 메시지들 사이에 불일치가 발생함
따라서 모든 ISR 가 메시지를 받을 때까지 기다린 뒤에 컨슈머는 메시지를 읽을 수 있다.
어떠한 이유로 브로커 사이의 복제가 늦어진다면 새로운 메시지가 컨슈머에 도달하는 시간도 길어지게 된다.
이렇게 지연되는 시간(= In-Sync 상태로 판정되는 레플리카가 새 메시지를 복제하는 과정에서 지연될 수 있는 최대 시간)은 replica.lag.time.max.ms 에 따라 제한되며, 이 시간 이상으로 지연되면 Out-of-sync replica 가 된다.
컨슈머가 매우 많은 수의 파티션들로부터 이벤트를 읽어오는 경우가 있다.
이 때 읽고자 하는 파티션의 전체 목록을 요청을 보낼 때마다 브로커에 전송하고, 브로커는 다시 모든 메타데이터를 응답하는 방식은 비효율적일 수 있다.
읽고자 하는 파티션의 집합이나 메타데이터는 잘 변경되지 않으며, 대부분 리턴해야 할 메타데이터가 그리 많지도 않다.
이러한 오버헤드를 줄이기 위해 카프카는 읽기 세션 캐시(fetch session cache) 를 사용한다.
컨슈머는 읽고 있는 파티션의 목록과 그 메타데이터를 캐시하는 세션을 생성할 수 있고, 세션이 생성되면 컨슈머는 더 이상 요청을 보낼 때마다 모든 파티션을 지정할 필요가 없다.
세션 캐시 크기에 한도가 있기 때문에 어떤 경우에는 캐시된 세션이 아예 생성되지 않거나, 생성되었던 세션이 해제될 수도 있다.
어떠한 경우에도 브로커는 적절한 에러를 클라이언트에게 리턴하고, 컨슈머는 사용자가 개입하지 않아도 알아서 모든 파티션 메타데이터를 포함하는 읽기 요청을 보낸다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
- 카프카 핵심 가이드
- 예제 코드 & 오탈자
- Kafka Doc
- Git:: Kafka
- 주키퍼 Ephemeral 노드
- 주키퍼 와치
- KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum
- KIP-595: A Raft Protocol for the Metadata Quorum
- KIP-631: The Quorum-based Kafka Controller
- Kraft 마이그레이션 blog
- KIP-833: Mark KRaft as Production Ready
- Migrate from ZooKeeper to KRaft on Confluent Platform
- KIP-392: Allow consumers to fetch from closest replica
