Kafka - 내부 메커니즘(2): 파티션 할당, 인덱스, 보존 정책, 로그 압착
in DEV on Kafka, Tiered-storage, Message-batch, Control-batch, Compact, Tombstone-message
카프카의 기본 저장 단위는 파티션 레플리카이다.
파티션은 서로 다른 브로커들로 분리될 수 없고, 같은 브로커의 서로 다른 디스크에 분할 저장되는 것도 불가능하다.
따라서 파티션의 크기는 특정 마운트 지점에 사용 가능한 공간에 제한을 받는다.
카프카를 설정할 때 파티션들이 저장될 디렉터리 목록을 정의하는데 이것은 log.dirs 매개 변수에 지정된다.
카프카가 사용할 각 마운트 지점별로 하나의 디렉터리를 포함하도록 설정하는 것이 일반적이다.
이 포스트에서는 카프카가 데이터를 저장하기 위해 사용 가능한 디렉터리들을 어떻게 활용하는지에 대해 아래의 순서대로 알아본다.
- 데이터가 클러스터 안의 브로커, 브로커 안의 디렉터리에 할당되는 방식
- 브로커가 파일을 관리하는 방법
- 특히 보존 기한 관련 보장이 처리되는 방식
- 파일 내부로 초점을 옮겨서 데이터가 저장되는 파일과 인덱스의 형식
- 카프카를 장시간용 데이터 저장소로 사용할 수 있게 해주는 고급 기능은 로그 압착(log compaction) 의 작동 원리
목차
- 1. 계층화된 저장소 (Tiered storage)
- 2. 파티션 할당
- 3. 파일 관리: 보존 기한, 세그먼트
- 4. 파일 형식: 세그먼트
- 5. 인덱스
- 6. 보존 정책: 삭제 보존, 압착 보존
- 7. 로그 압착(Compact)의 작동 원리
- 8. 삭제된 이벤트: 툼스톤 메시지
- 9. 토픽이 압착되는 시기:
min.compaction.lag.ms,max.compaction.lag.ms - 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
1. 계층화된 저장소 (Tiered storage)
카프카 3.6.0 부터 계층 저장소의 얼리 엑세스 모드가 가용 가능하다.
카프카가 제공하는 계층 저장소는 아직 얼리 엑세스 모드로 많은 기능이 제한적임
(한번 리모트 저장소로 저장한 토픽은 다시 로컬 저장소로 변경 불가능, 카프카 클라이언트와 호환성 부족 등)
이 외에도 안정성 측면에서 아직은 프로덕션 레벨에서 사용하기는 부적합함
카프카는 현재 대량의 데이터를 저장하기 위한 목적으로 사용되고 있는데 이는 아래와 같은 문제점을 야기한다.
- 파티션별로 저장 가능한 데이터에 한도가 있음
- 결과적으로 최대 보존 기한과 파티션 수가 물리적인 디스크 크기에 제한을 받음
- 비용 증가
- 디스크와 클러스터의 크기는 저장소 요구 조건에 의해 결정됨
- 지연과 처리량이 주 고려사항일 경우 클러스터는 필요 이상으로 커지는 경우가 많은데 이는 곧 비용과 직결됨
- 탄력성 감소
- 예를 들어 클러스터의 크기를 키우거나 줄일 때, 혹은 파티션의 위치를 다른 브로커로 옮기는 데 걸리는 시간은 파티션의 크기에 따라 결정됨
- 파티션의 크기가 클수록 클러스터의 탄력성은 줄어듦
- 최대한 탄력성을 가지는 것이 아키텍처 설계의 추세임
계층화된 저장소는 카프카 클러스터의 저장소를 로컬과 원격, 두 계층으로 나눈다.
- 로컬 계층
- 현재 카프카 저장소 계층과 동일하게 로컬 세그먼트를 저장하기 위해 카프카 브로커(서버)의 로컬 디스크 사용
- 원격 계층
- 완료된 로그 세그먼트를 저장하기 위해 HDFS(Hadoop Distributed File System, 하둡 분산형 파일 시스템), S3 와 같은 전용 저장소 시스템 사용
로컬과 원격 계층별로 서로 보존 정책을 적용할 수 있다.
로컬 계층 저장소가 원격 계층 저장소에 비해 훨씬 비싼 것이 보통이므로 로컬 계층의 보존 기한은 몇 시간 이하로 설정하고, 원격 계층의 보존 기한은 그보다 길게 (며칠 혹은 몇 달) 로 설정할 수 있다.
원격 저장소 사용 여부 설정은 토픽 단위로 지정이 가능하다.
따라서 보존 기한이 짧고 자주 접근해야 하는 데이터는 로컬 저장소를 선택하고, 자주 접근하지 않고 데이터를 오래 저장해야 한다면 리모트 저장소를 선택하면 된다.
로컬 저장소는 원격 저장소에 비해 지연이 훨씬 짧다.
지연에 민감한 애플리케이션들은 로컬 계층에 저장되어 있는 최신 데이터들을 읽어오게 해도 데이터를 전달하기 위해 페이지 캐시를 활용하는 카프카 메커니즘에 의해 문제없이 동작한다.
빠진 데이터를 메꾸거나 장애 복구용 애플리케이션들은 로컬 저장소보다 오래된 데이터를 필요로 하는 만큼 원격 계층에 있는 데이터를 전달하도록 한다.
계층화된 저장소의 이중화된 구조 덕분에 카프카 클러스터의 메모리와 CPU 에 상관없이 저장소를 확장할 수 있게 됨으로써 카프카는 장기간용 저장 솔루션으로서의 역할을 할 수 있게 되었다.
카프카 브로커에 로컬 저장되는 데이터 양과 복구/리밸런싱 과정에서 복사되어야 할 데이터 양도 줄어든다.
원격 계층에 저장되는 로그 세그먼트들은 굳이 브로커로 복원될 필요 없이 원격 계층에서 바로 클라이언트로 전달된다.
모든 데이터가 브로커에 저장되지 않으므로 보존 기한을 늘려도 카프카 클러스터 저장소를 확장하거나 새로운 노드를 추가할 필요가 없으며, 전체 데이터 보존 기한 역시 더 길게 설정할 수 있다.
현재 흔히 하고 있는 것처럼 카프카의 데이터를 외부 저장소로 복사하는 별도의 데이터 파이프라인을 구축할 필요가 없어지는 것이다.
계층화된 저장소의 설계는 KIP-405: Kafka Tiered Storage 에 상세히 나와있다.
해당 문서에는 새로운 컴포넌트인 RemoteLogManager 에 대한 설명과 레플리카의 리더 데이터 복제 기능, 리더 선출과 가능 기존 기능과 어떻게 상호작용하는지에 대해서도 나와있다.
해당 문서에는 계층화된 저장소 도입으로 인한 성능 변화 실험 결과도 있다.
- 상시적으로 막대한 작업 부하가 걸린 상황
- 브로커들이 원격 저장소로 로그 세그먼트를 전송해야 하는 만큼 지연이 약간 증가함
- 일부 컨슈머들이 오래된 데이터를 읽어오는 상황
- 계층화된 저장소가 설정되지 않은 상태에서는 컨슈머가 오래된 데이터를 읽어오는 것이 지연이 큰 영향을 미치지만 계층화된 저장소 기능을 활성화하면 오히려 영향이 줄어듦
- 계층화된 저장소는 네트워크 경로를 통해서 HDFS(Hadoop Distributed File System, 하둡 분산형 파일 시스템) 나 S3 에서 데이터를 읽어오는데 네트워크 읽기는 로컬 읽기, 디스크 I/O, 페이시 캐시를 놓고 경합할 일이 없기 때문에 페이지 캐시가 온전히 새로운 데이터를 읽고 쓰는데 사용될 수 있음
즉, 계층화된 저장소 기능은 무한한 저장 공간, 더 낮은 비용, 탄력성, 오래된 데이터와 실시간 데이터를 읽는 작업의 분리 효과가 있다.
2. 파티션 할당
토픽을 생성하면 카프카는 이 파티션을 브로커 중 하나에 할당한다.
_브로커가 6개, 여기에 파티션이 10개, 복제 팩터 (RF, Replication Factor)가 3인 토픽을 생성_한다고 해보자.
이 때 카프카는 30개의 파티션 레플리카를 6개의 브로커에 할당해야 한다.
<파티션 할당 시 목표>
- 레플리카들을 가능한 브로커 간에 고르게 분산
- 위의 경우엔 브로커별로 5개의 레플리카할당
- 각 파티션에 대해 각각의 레플리카는 서로 다른 브로커에 배치
- 예를 들어 파티션 0 의 리더가 브로커 2 에 있다면, 팔로워들은 브로커 3과 4에 배치될 수 있음
하지만 브로커 2에 팔로워가 또 배치되거나 (= 즉, 브로커 2에 리더와 팔로워가 하나씩 함께 배치), 브로커 3 에 팔로워 2개가 함께 배치될 수는 없음
- 예를 들어 파티션 0 의 리더가 브로커 2 에 있다면, 팔로워들은 브로커 3과 4에 배치될 수 있음
- 브로커에 rack 정보가 설정되어 있다면 가능한 각 파티션의 레플리카들을 서로 다른 rack 에 할당
- 이렇게 하면 하나의 rack 전체가 작동 불능이 되어도 파티션 전체가 작동 불능이 되는 사태 방지 가능
rack 에 대한 추가 설명은
2. 파티션 할당,
3.1. 복제 팩터(레플리카 개수):replication.factor,default.replication.factor
를 참고하세요.
위처럼 하기 위해 임의의 브로커(여기서는 4라고 하자)부터 시작하여 라운드 로빈 방식으로 파티션을 할당함으로써 리더를 결정한다.
그러면 브로커는 6대이니까 아래와 같이 할당된다.
- 파티션 0의 리더는 브로커 4에 할당
- 파티션 1의 리더는 브로커 5에 할당
- 파티션 2의 리더는 브로커 0에 할당
- 파티션 3의 리더는 브로커 1에 할당
- 파티션 4의 리더는 브로커 2에 할당
- 파티션 5의 리더는 브로커 3에 할당
그리고 나서 각 파티션의 레플리카는 리더로부터 증가하는 순서로 배치한다.
- 파티션 0의 리더가 브로커 4에 배치되어 있으므로 첫 번째 팔로워는 브로커 5에, 두 번째 팔로워는 브로커 0에 배치
- 파티션 1의 리더가 브로커 5에 배치되어 있으므로 첫 번째 팔로워는 브로커 0에, 두 번째 브로커는 브로커 1에 배치
rack 인식 기능을 고려하면 단순히 순서대로 브로커를 선택하는 것이 아니라 서로 다른 rack 에 있는 브로커가 번갈아 선택되도록 순서를 정해야 한다.
rack 1 에 브로커 0,1 이 있고, rack 2 에 브로커 2,3 이 있을 때 브로커를 0,1,2,3의 순서대로 선택하는 것이 아니라 0,2,1,3 과 같은 순서로 선택할 수 있다.
파티션 0 의 리더가 브로커 2에 할당되면 첫 번째 팔로워는 완전히 다른 rack 에 위치한 브로커 1에 할당된다.
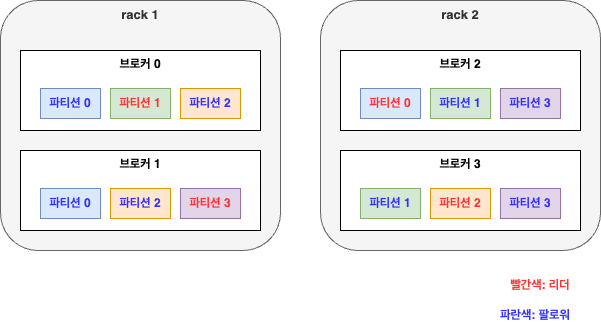
rack 1 이 오프라인이 되더라도 여전히 동작 가능한 레플리카가 있는만큼 파티션은 여전히 사용 가능하므로 위와 같은 방법은 매우 좋은 방식이다.
각 파티션과 레플리카에 올바른 브로커를 선택했다면 새로우누 파티션을 저장할 디렉터리를 결정한다.
이 작업은 파티션별로 독립적으로 수행되며, 각 디렉터리에 저장되어 있는 파티션의 수를 센 뒤에 가장 적은 파티션이 저장된 디렉터리에 새 파티션을 저장한다.
즉, 새로운 디스크를 추가할 경우 모든 새로운 파티션들은 이 새로운 디스크에 생성될 것이라는 것을 의미한다. (균형이 잡힐 때까지는 새로운 디스크가 항상 가장 적은 수의 파티션을 보유하므로)
파티션 할당 시 주의할 점
파티션을 브로커에 할당할 때 사용 가능한 공간이나 부하같은 것은 고려되지 않음
파티션을 디스크에 할당할 때 디스크에 저장된 파티션의 수만이 고려될 뿐 크기는 고려되지 않음따라서 어떤 브로커들이 다른 브로커들에 비해 공간이 더 많이 남았다면 몇몇 파티션들이 비정상적으로 크거나, 같은 브로커에 서로 다른 크기의 디스크들이 장착되어 있는 것일스도 있으므로 파티션 할당에 주의할 필요가 있음
3. 파일 관리: 보존 기한, 세그먼트
카프카는 데이터를 영구적으로 저장하지도 않고 데이터를 지우기 전에 모든 컨슈머들이 메시지를 읽어갈 수 있도록 기다리지도 않는다.
대신 각 토픽에 대해 보존 기한(retention period) 을 설정한다.
예) 특정 기한이 지난 메시지 삭제 혹은 특정 용량이 넘어가면 삭제
큰 파일에서 삭제해야 할 메시지를 찾아서 지우는 작업은 시간도 오래 걸리고, 에러 가능성도 높으므로 하나의 파티션을 여러 개의 세그먼트로 분할한다.
기본적으로 각 세그먼트는 1GB 혹은 최근 일주일치의 데이터 중 적은 쪽만큼을 저장한다.
카프카가 파티션 단위로 메시지를 쓰는 만큼 각 세그먼트 한도가 다 차면 세그먼트를 닫고 새로운 세그먼트를 생성한다.
현재 쓰여지고 있는 세그먼트를 액티브 세그먼트라고 한다.
세그먼트가 닫히기 전까지는 데이터를 삭제할 수 없기 때문에 액티브 세그먼트는 어떠한 경우에도 삭제되지 않는다.
예) 로그 보존 기한을 하루로 설정했는데 세그먼트가 5일치의 데이터를 저장하고 있을 경우 실제로는 5일치의 데이터가 보존됨
만일 데이터를 일주일간 보존되도록 설정하고 매일 새로운 세그먼트를 생성한다면, 매일 가장 오래된 세그먼트 하나가 삭제되고 새로운 세그먼트가 하나 생성될 것이다.(= 대부분의 시간동안 파티션은 7개의 세그먼트 보유)
4. 파일 형식: 세그먼트
각 세그먼트는 하나의 데이터 파일 형태로 저장되며, 파일 안에는 카프카 메시지와 오프셋이 저장된다.
디스크에 저장되는 데이터 형식은 프로듀서를 통해서 브로커로 보내는, 브로커로부터 컨슈머로 보내지는 메시지의 형식과 동일하다.
네트워크를 통해 전달되는 형식과 디스크에 저장되는 형식을 통일함으로써 카프카는 컨슈머에 메시지를 전송할 때 제로카피 최적화를 달성할 수 있으며, 프로듀서가 이미 압축한 메시지들을 압축 해제한 후 다시 압축하는 과정 역시 하지 않을 수 있다.
즉, 만일 메시지 형식을 변경하려고 한다면 네트워크 프로토콜과 디스크 저장 형식이 모두 변경되어야 하며, 카프카 브로커들은 업그레이드로 인한 2개의 파일 형식이 뒤섞여있는 파일을 처리할 방법을 알아야 한다.
파일 시스템에 저장된 파티션의 세그먼트의 모든 내용을 알고 싶다면 브로커에 포함되어 있는 DumpLogSement 를 이용하면 된다.
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments
--deep-iteration 을 지정해주면 래퍼 메시지 안에 압축되어 있는 메시지들에 대한 정보도 조회한다.
4.1. 배치 단위로 메시지 전송
카프카 프로듀서는 언제나 메시지를 배치 단위로 전송한다.
메시지, 배치에 대한 내용은 2.1. 메시지, 키, 배치 를 참고하세요.
프로듀서의 내부 동작에 대한 내용은 1. 프로듀서 를 참고하세요.
배치 단위로 묶어서 메시지를 보낼 경우 공간을 절약하게 되는만큼 네크워크 대역폭과 디스크 공간을 덜 사용할 수 있게 된다.
이것이 linger.ms를 0이 아닌 10으로 잡아줘서 약간의 지연을 추가함으로써 더 많은 메시지들이 같은 배치로 묶일 확률을 증가시켜 결론적으로 성능이 더 좋아지는 이유이기도 하다.
카프카가 파티션별로 별도의 배치를 생성하는 만큼 더 적은 수의 파티션에 쓰는 프로듀서가 더 효율적이다.
카프카 프로듀서는 같은 쓰기 요청에 여러 개의 배치를 포함할 수 있다.
이 말은 즉 프로듀서에서 압축 기능을 사용할 경우 더 큰 배치를 전송할수록 네트워크를 통해 전송되고 브로커의 디스크에 저장되는 데이터가 더 잘 압축된다는 이야기이다.
4.2. 카프카 메시지 내용: 헤더
카프카 메시지는 사용자 페이로드와 시스템 헤더로 나뉜다.
사용자 페이로드는 키값(선택 사항)와 밸류값, 헤더 모음(선택 사항) 을 포함하고, 각각의 헤더는 자체적인 key/value 순서쌍으로 포함한다.
4.2.1. 메시지 배치 헤더
메시지 배치 헤더는 아래의 내용을 포함한다.
- 메시지 형식의 현재 버전을 가리키는 매직 넘버
- 배치에 포함된 첫 번째 메시지의 오프셋과 마지막 오프셋의 차이
- 이 값들은 나중에 배치가 압착되어 일부 메시지가 삭제되더라도 보존됨
- 프로듀서가 배치를 생성해서 전송하는 시점에서는 첫 번째 메시지의 오프셋이 0이 됨
- 이 배치를 처음으로 저장하는 브로커(= 파티션 리더)가 이 값을 실제 오프셋으로 교체함
- 첫 번째 메시지의 타임스탬프와 배치에서 가장 큰 타임스탬프
- 타임스탬프 유형이 생성 시각이 아닌 추가 시각으로 잡혀있을 경우 브로커가 타임스탬프를 잡아주게 됨
- 바이트 단위로 표시된 배치의 크기
- 해당 배치를 받은 리더의 에포크 값
- 배치가 오염되지 않았음을 확인하기 위한 체크섬
- 서로 다른 속성을 표시하기 위한 16비트
- 압축 유형
- 타임스탬프 유형(타임스탬프는 클라이언트가 지정할 수도 있고, 브로커가 지정할 수도 있음)
- 배치가 트랜잭션의 일부 혹은 컨트롤 배치인지의 여부
- 프로듀서 ID, 프로듀서 에포크, 배치의 첫 번째 시퀀스 넘버
- 모두 정확히 한 번의 보장을 위해 사용됨
- 배치에 포함된 메시지들의 집합
매직 넘버(Magic Number)
의미있는 이름의 상수로 대체될 수 있는 숫자를 의미함
3.14 란 숫자가 나올 때 어떤 사람은 원주율로 생각할 수 있는데 작성자의 의도는 그냥 아무 숫자나 넣었던 것일 수도 있음
따라서 매직 넘버는 코드에서 제거하는 것이 권장되는 안티 패턴임매직 넘버 대신 의미 있는 이름의 상수로 바꿔주는 것이 좋음
예) add(3.14) 대신 val CIRCUMFERENCE = 3.14; add(CIRCUMFERENCE); 로 하면 원주율을 사용하려고 했던 의도가 분명해짐
4.3. 레코드
각각의 레코드 역시 자체적인 시스템 헤더를 갖고 있으며, 각 레코드는 아래의 정보를 포함한다.
- 바이트 단위로 표시된 레코드의 크기
- 현재 레코드의 오프셋과 배치 내의 첫 번째 레코드의 오프셋과의 차이
- 현재 레코드의 타임스탬프와 배치 내의 첫 번째 레코드의 타임스탬프와의 차이(ms)
- 사용자 페이로드
- 키, 밸류, 헤더
각 레코드에는 오버헤드가 거의 없으며, 대부분의 시스템 정보는 배치 단위에서 저장하고 있다.
배치의 첫 번째 오프셋과 타임스탬프는 헤더에 저장하고, 각 레코드에 대해서는 차이만 저장함으로써 각 레코드의 오버헤드를 극적으로 줄일 수 있으며, 배치가 더 커질수록 효율성도 더 높아진다.
4.4. 컨트롤 배치
사용자 데이터를 저장하는 메시지 배치 외에 트랜잭션 커밋 등을 가리키는 컨트롤 배치도 있다.
컨트롤 배치는 컨슈머가 받아서 처리하기 때문에 애플리케이션 관점에서는 보이지 않으며 현재는 버전과 타입 정보만을 포함한다. (0: 중단된 트랜잭션, 1: 커밋된 트랜잭션)
5. 인덱스
카프카는 컨슈머가 사용 가능한 오프셋부터 메시지를 읽어올 수 있도록 한다.
만약 컨슈머가 오프셋 100에서부터 시작되는 1MB 의 메시지를 요청할 경우 브로커는 오프셋 100에 해당하는 메시지가 저장된 위치(파티션의 어느 세그먼트에도 있을 수 있음)를 빠르게 찾아서 해당 오프셋에서부터 메시지를 읽기 시작할 수 있어야 한다.
브로커가 주어진 오프셋의 메시지를 빠르게 찾을 수 있도록 하기 위해 카프카는 각 파티션에 대해 오프셋을 유지하며, 이 인덱스는 오프셋과 세그먼트 파일 및 그 안에서의 위치를 매핑한다.
비슷하게 카프카는 타임스탬프와 메시지 오프셋을 매핑하는 인덱스도 가지고 있다.
이 인덱스는 타임스탬프를 기준으로 메시지를 찾을 때 사용된다.
예) 장애 복구 상황에서 사용
인덱스들 역시 세그먼트 단위로 분할되기 때문에 메시지를 삭제할 때 오래된 인덱스 항목도 삭제할 수 있다.
카프카는 인덱스에 체크섬을 유지하지 않는 대신 인덱스가 오염되면 해당하는 로그 세그먼트에 포함된 메시지들을 다시 읽어서 오프셋과 위치를 기록하는 방식으로 인덱스를 재생성한다.
따라서 필요한 경우 인덱스 세그먼트를 삭제해도 완벽히 안전하다.
복구 시간이 길어질 수 있지만 어차피 자동으로 생성되기 때문이다.
6. 보존 정책: 삭제 보존, 압착 보존
보존 기능에 대한 추가 내용은 2.5.1. 보존 (retention) 기능을 참고하세요.
대개 카프카는 설정된 기간 동안만 메시지를 저장하고, 보존 기한이 지나면 메시지들을 삭제한다.
하지만 현재 상태를 저장하기 위해 카프카를 사용하는 경우 상태가 변할 때마다 애플리케이션은 새로운 상태를 카프카에 쓰게 되고, 크래시가 발생하여 복구를 할 때 애플리케이션은 이 메시지들을 카프카에서 읽어와서 가장 최근 상태로 복원한다.
이 때 필요한 것은 애플리케이션이 구동 중일 때의 모든 상태 변경이 아닌 크래시가 나기 직전의 마지막 상태만 필요하다.
이렇게 특정 기간 동안의 메시지를 저장하는 것보다 가장 마지막 메시지만 저장하는 것이 합리적인 경우가 있다.
카프카는 아래 2가지 보존 정책을 이용하여 특정 기간 혹은 마지막 메시지만 저장하도록 지원한다.
- 삭제 보존 정책
- 지정된 보존 기한보다 오래된 이벤트들을 삭제
- 압착 보존 정책
- 토픽에서 각 key 의 가장 최근값만 저장
- 토픽에서 key 값이 null 인 메시지가 있을 경우 압착은 실패함
delete,compact 값을 설정하여 보존 기한과 압착 설정을 동시에 적용할 수도 있다.
이렇게 하면 지정된 보존 기한보다 오래된 메시지들은 key 에 대한 가장 최근값인 경우에도 삭제된다.
이 설정은 압착된 토픽이 지나치게 커지는 것을 방지해주면서 일정 기한이 지난 레코드들을 삭제해야 하는 경우에 활용할 수 있다.
7. 로그 압착(Compact)의 작동 원리
각 로그는 아래와 같이 2개의 영역으로 나뉜다.
- 클린
- 이전에 압착된 적이 있던 메시지들이 저장됨
- 하나의 key 마다 하나의 value 만을 포함함 (이 value 는 이전 압착 시점에서의 최신값이기도 함)
- 더티
- 마지막 압착 작업 이후 쓰여진 메시지들이 저장됨
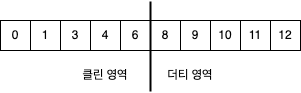
위 그림을 보면 클린 영역의 일부 오프셋의 메시지(2, 5, 7)들이 압착 과정에서 삭제된 것을 볼 수 있다.
더티 영역은 나중에 압착될 것이다.
압착 기능은 log.cleaner.enabled 설정을 통해 활성화할 수 있다.
카프카가 시작되었는데 압착 기능이 활성화되어 있다면 각 브로커는 압착 매니저 스레드와 함께 다수의 압착 스레드를 시작시킨다.
압착 스레드들은 압착 작업을 담당하는데, 각 스레드는 전체 파티션 크기 대비 더티 메시지의 비율이 높은 파티션을 골라서 압착한 뒤 클린 상태로 만든다.
파티션 압착을 위해 클리너 스레드는 파티션의 더티 영역을 읽어서 인-메모리 맵을 생성한다.
맵의 각 항목은 메시지 key 의 16 byte 해시와 같은 key 를 갖는 이전 메시지의 오프셋 8 byte 로 이루어진다.
즉, 맵의 각 항목은 오직 24 byte 만을 사용한다.
예) 개별 메시지의 크기가 1KB 인 1GB 크기의 세그먼트를 압착한다고 하면, 세그먼트 안에는 백만개의 메시지가 있을 것이므로 압착에 필요한 맵의 크기는 24MB 임
key 가 반복되는만큼 동일한 해시 엔트리를 여러 번 재사용하므로 실제로는 24MB 보다 더 적은 메모리를 사용하게 됨
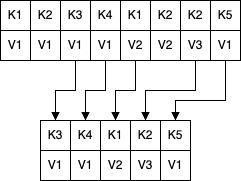
클리너 스레드가 오프셋 맵을 생성하고 나면 오래된 클린 세그먼트들부터 읽어들이면서 오프셋 맵의 내용과 대조한다.
각 메시지에 대해 해당 메시지의 key 가 현재 오프셋 맵에 저장되어 있는지 확인한다.
저장되어 있지 않다면 방금 읽어들인 메시지의 value 는 최신값이라는 의미이므로 메시지를 교체용 세그먼트로 복사된다.
저장되어 있다면 파티션 내에 같은 key 를 가졌지만 더 새로운 value 를 갖는 메시지가 있다는 의미이므로 해당 메시지를 건너뛴다.
key 에 대한 최신 value 를 갖는 모든 메시지들이 복사되고 나면 압착 스레드는 교체용 세그먼트와 원본 세그먼트르 바꾼 뒤 다음 세그먼트로 계속 진행한다.
작업이 완료되면 key 별로(최신 value 를 포함하는) 하나의 메시지만이 남게 된다.
8. 삭제된 이벤트: 툼스톤 메시지
가장 최근 메시지도 남기지 않고 시스템에서 특정 key 를 완전히 삭제하려면 해당 key 값과 value 값이 null 인 메시지를 써주면 된다.
클리너 스레드가 이 메시지를 발견하면 평소대로 압착 작업을 한 뒤 null 의 value 값을 갖는 메시지만을 보존할 것이다.
카프카는 사전에 설정된 기간동안 이 메시지(= 툼스톤, tombstone)를 보존한다.
이 기간동안 컨슈머는 이 메시지를 보고 해당 value 가 삭제되었음을 알 수 있다.
따라서 만약 컨슈머가 카프카에서 읽어 온 데이터를 RDB 로 복사할 경우 툼스톤 메시지를 보고 해당 데이터를 DB 에서 지워야 함을 알 수 있다.
이 기간이 지나면 클리너 스레드는 툼스톤 메시지를 삭제하며, 해당 key 역시 파티션에서 완전히 삭제된다.
컨슈머가 툼스톤 메시지를 볼 수 있도록 충분한 시간을 주는 것은 매우 중요하다.
만약 컨슈머가 몇 시간동안 작동을 멈추는 바람에 툼스톤 메시지를 놓치게 되면 나중에 데이터를 읽어도 해당 key 에 대해 알 수 없어서 이 데이터가 카프카에서 삭제되었는지, DB 에서 삭제해줘야하는지 알 수 없기 때문이다.
이 작업은 어드민 클라이언트의 deleteRecords() 와는 다르다.
deleteRecords() 는 지정된 오프셋 이전의 모든 레코드를 삭제한다.
deleteRecords() 메서드가 호출되면 카프카는 파티션의 첫 번째 레코드를 가리키는 로우 워터마크(low-water mark) 를 해당 오프셋으로 이동시킨다.
이렇게 함으로써 컨슈머는 업데이트된 로우 워터마크 이전 메시지들을 읽을 수 없으므로 사실상 접근이 불가능하게 된다.
이 레코드들은 나중에 클리너 스레드에 의해 삭제된다.
deleteRecords() 메서드는 보존 기한이 설정되어 있거나 압착 설정이 되어 있는 토픽에 사용 가능하다.
9. 토픽이 압착되는 시기: min.compaction.lag.ms, max.compaction.lag.ms
삭제 정책이 액티브 세그먼트를 절대로 삭제하지 않는 것처럼 압착 정책 역시 액티브 세그먼트는 절대로 압착하지 않는다.
액티브 세그먼트가 아닌 세그먼트에 저장되어 있는 메시지만이 압착의 대상이 된다.
기본적으로 카프카는 토픽 데이터의 50% 이상이 더티 레코드인 경우에만 압착을 시작한다.
압착의 목표는 아래와 같다.
- 토픽을 지나치게 자주 압착하지 않음
- 압착은 토픽의 읽기/쓰기 성능에 영향을 줄 수 있음
- 너무 많은 더티 레코드가 존재하지 않도록 함
- 더키 레코드가 많으면 그만큼 디스크 공간을 차지함
따라서 토픽이 사용하는 디스크 공간의 50% 를 더티 레코드에 사용하다가 압착하는 것은 합리적인 트레이드오프이며, 이 기준은 튜닝하는 것도 가능하다.
min.compaction.lag.ms- 메시지가 쓰여진 뒤 압착될 때까지 지나야 하는 최소 시간
max.compaction.lag.ms- 메시지가 쓰여진 뒤 압착될 때까지 지연될 수 있는 최대 시간
- 특정 기한 안에 압착이 반드시 실행된다는 것을 보장해야 하는 상황에서 자주 사용됨
- 예) GDPR(유럽 연합 개인정보 보호법) 은 특정한 정보가 삭제가 요청된 지 30일 안에 실제로 삭제될 것을 요구함
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
- 카프카 핵심 가이드
- 예제 코드 & 오탈자
- Doc Kafka
- Git:: Kafka
- Blog: 카프카에서 계층 저장소(Tiered storage)가 필요한 이유
- KIP-405: Kafka Tiered Storage
- Kafka Tiered Storage Early Access Release Notes
- KIP-101: Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation
- KIP-279: Fix log divergence between leader and follower after fast leader fail over
