Kafka - 데이터 미러링(2): 미러메이커
이 포스트에서는 아래의 내용에 대해 알아본다.
- 미러메이커가 무엇이고, 어떻게 사용하는지
- 미러메이커를 전개하는 방법과 성능을 튜닝하는 방법 등 운영상의 팁
목차
- 1. 아파치 카프카 미러메이커(MirrorMaker)
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
1. 아파치 카프카 미러메이커(MirrorMaker)
카프카는 두 데이터센터 간 데이터 미러링을 위한 미러메이커 툴을 포함한다.
<미러메이커 초기 버전>
- 하나의 컨슈머 그룹에 속하는 여러 개의 컨슈머를 사용하여 복제할 토픽의 집합을 읽은 뒤, 미러메이커 프로세스들이 공유하는 카프카 프로듀서를 이용해서, 읽어 온 이벤트를 목적지 클러스터로 씀
- 설정 변경 시 지연값이 갑자기 높아진다던가, 새 토픽을 추가하면 리밸런스 때문에 멈춘다던가(stop-the-world) 하는 문제가 있었음
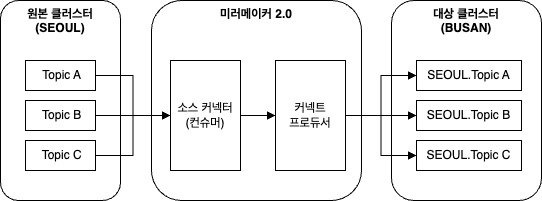
미러메이커 2.0 은 카프카 커넥트 프레임워크에 기반하여 개발되었으며, 초기 버전의 많은 단점들을 해결하고 있다.
미러메이커는 DB 가 아닌 다른 카프카 클러스터로부터 데이터를 읽어오기 위해 소스 커넥터를 사용한다.
각각의 커넥터는 전체 작업을 사전에 설정된 개수의 태스크로 분할한다.
미러메이커에서는 각 태스크가 한 쌍의 컨슈머와 프로듀서로 이루어지고, 커넥트 프레임워크가 각 태스크를 필요에 따라 서로 다른 커넥트 워커 노드로 할당한다.
그래서 여러 태스크를 하나의 서버에서 수행할 수도 있고, 서로 다른 서버에서 나눠서 수행할 수도 있다.
바로 이 기능이 인스턴스별로 몇 개의 미러메이커 스트림을 실행시켜야 하는지, 서버별로 몇 개의 인스턴스를 실행시켜야 하는지를 직접 결정하는 작업을 자동화해준다.
만일 대부분의 카프카 클러스터가 카프카 커넥트를 포함하고 있을 경우(예- DB 의 변경 내역을 카프카로 보내는 경우), 미러메이커를 커넥트 안에서 실행시킴으로써 관리해야 할 클러스터의 수를 줄일 수 있다.
미러메이커는 카프카의 컨슈머 그룹 관리 프로토콜을 사용하는 것이 아니라 태스크에 파티션을 균등하게 배분함으로써 새로운 토픽이나 파티션이 추가되었을 때 발생하는 리밸런스로 인해 지연이 튀어오르는 상황을 방지한다.
미러메이터는 원본 클러스터의 각 파티션에 저장된 이벤트를 대상 클러스터의 동일한 파티션으로 미러링함으로써 파티션의 의미 구조나 각 파티션 안에서의 이벤트 순서를 그대로 유지한다.
원본 토픽에 새로운 파티션이 추가되면 자동으로 대상 토픽에 새로운 파티션이 생성된다.
미러메이커는 데이터 복제 뿐 아니라 컨슈머 오프셋, 토픽 설정, 토픽 ACL 마이그레이션까지 지원하는, 자동 클러스터 배치에 필요한 완전한 기능을 갖춘 미러링 솔루션이다.
아래는 액티브-스탠바이 아키텍처에서 미러메이커를 사용하는 예시 그림이다
1.1. 미러메이커 설정
미러메이커는 매우 세밀한 것까지 설정이 가능하다.
- 클러스터 설정
- 토폴로지, 카프카 커넥트, 커넥터 설정 등
- 내부적으로 사용하는 프로듀서, 컨슈머, 어드민 클라이언트의 모든 설정 매개변수 커스터마이즈 가능
미러메이커 실행
$ pwd
/Users/kafka/kafka_2.13-3.8.0
$ bin/connect-mirror-maker.sh config/connect-mirror-maker.properties
/config/connect-mirror-maker.properties (미러메이커 설정 옵션들)
# This is a comma separated host:port pairs for each cluster
# for e.g. "A_host1:9092, A_host2:9092, A_host3:9092"
A.bootstrap.servers = A_host1:9092, A_host2:9092, A_host3:9092
B.bootstrap.servers = # Licensed to the Apache Software Foundation (ASF) under A or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see org.apache.kafka.clients.consumer.ConsumerConfig for more details
# Sample MirrorMaker 2.0 top-level configuration file
# Run with ./bin/connect-mirror-maker.sh connect-mirror-maker.properties
# specify any number of cluster aliases
clusters = A, B
# connection information for each cluster
# This is a comma separated host:port pairs for each cluster
# for e.g. "A_host1:9092, A_host2:9092, A_host3:9092"
A.bootstrap.servers = A_host1:9092, A_host2:9092, A_host3:9092
B.bootstrap.servers = B_host1:9092, B_host2:9092, B_host3:9092
# enable and configure individual replication flows
A->B.enabled = true
# regex which defines which topics gets replicated. For eg "foo-.*"
A->B.topics = .*
B->A.enabled = true
B->A.topics = .*
# Setting replication factor of newly created remote topics
replication.factor=1
############################# Internal Topic Settings #############################
# The replication factor for mm2 internal topics "heartbeats", "B.checkpoints.internal" and
# "mm2-offset-syncs.B.internal"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
checkpoints.topic.replication.factor=1
heartbeats.topic.replication.factor=1
offset-syncs.topic.replication.factor=1
# The replication factor for connect internal topics "mm2-configs.B.internal", "mm2-offsets.B.internal" and
# "mm2-status.B.internal"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offset.storage.replication.factor=1
status.storage.replication.factor=1
config.storage.replication.factor=1
# customize as needed
# replication.policy.separator = _
# sync.topic.acls.enabled = false
# emit.heartbeats.interval.seconds = 5
1.1.1. 복제 흐름
액티브-스탠바이 복제에 대한 설정 (A 가 액티브, B 가 스탠바이)
# 복제 흐름에 사용될 클러스터 별칭
clusters = A, B
# 각 클러스터에 대한 부트스트랩 서버 설정
A.bootstrap.servers = A_host1:9092, A_host2:9092, A_host3:9092
B.bootstrap.servers = B_host1:9092, B_host2:9092, B_host3:9092
# {원본}->{대상} 접두어를 사용하여 클러스터 간 복제 흐름 활성화
A->B.enabled = true
# 복제 흐름에 미러링되는 토픽을 정의
A->B.topics = .*
1.1.2. 미러링 토픽
위의 A->B.topics = .* 처럼 각 복제 흐름에서 미러링될 토픽들을 지정하기 위해 정규식을 사용할 수 있다.
여기선 모든 토픽을 미러링하도록 설정했지만 프로덕션 환경에서는 테스트 토픽은 복제되지 않도록 하는 것이 좋다.
(제외할 토픽 목록이나 패턴을 별도로 지정할 수도 있음)
특정 토픽만 복제하려면 아래와 같이 하면 된다.
예) A->B.topics=my-topic,my-topic-.*
복제된 대상 토픽 이름 앞에는 기본적으로 원본 클러스터의 별칭이 접두어로 붙는다.
예) A->B.topics = .* 는 A 의 모든 토픽이 B. 접두어가 붙어서 복제됨
이런 기본 네이밍 전략은 액티브-액티브 아키텍처모드에서 두 클러스터 간에 메시지가 무한 순환 복제되는 것을 방지한다.
미러메이커는 원본 클러스터에 새로운 토픽이 추가되었는지 주기적으로 확인하고, 설정된 패턴과 일치할 경우 자동으로 이 토픽들에 대한 미러링 작업을 시작한다.
1.1.3. 컨슈머 오프셋 마이그레이션: RemoteClusterUtils
미러메이커는 주 클러스터에서 DR 클러스터로 장애 복구를 수행할 때 주 클러스터에서 마지막으로 체크포인트된 오프셋을 DR 클러스터에서 찾을 수 있도록 RemoteClusterUtils 클래스를 포함한다.
주기적인 컨슈머 오프셋 마이그레이션 기능은 2.7.0 버전부터 지원함
컨슈머 오프셋 마이그레이션 기능은 주기적으로 주 클러스터에 커밋된 오프셋을 자동으로 변환하여 DR 클러스터의 __consumer_offsets 에 커밋해줌으로써 DR 클러스터로 옮겨가는 컨슈머들이 별도의 마이그레이션 작업 없이 주 클러스터의 커밋 지점에 해당하는 오프셋에서 바로 작업을 재개할 수 있도록 해준다.
이 작업은 데이터 유실도 없고, 중복도 최소화된다.
이렇게 오프셋을 마이그레이션할 컨슈머 그룹의 목록도 커스터마이즈 가능하다.
단, 사고 방지를 위해 현재 대상(DR) 클러스터 쪽 컨슈머 그룹을 사용중인 컨슈머들이 있을 경우, 미러메이커는 오프셋을 덮어쓰지 않으므로 현재 작동 중인 컨슈머들의 컨슈머 그룹 오프셋과 원본에서 마이그레이션된 오프셋이 충돌하는 상황은 발생하지 않는다.
1.1.4. 토픽 설정 및 ACL(Access Control Level) 마이그레이션
토픽 설정과 접근 제어 목록(ACL, Access Control Level) 을 미러링하면 원본과 대상 토픽이 똑같이 작동하도록 할 수 있다.
기본값을 그대로 사용하면 일정 주기로 ACL 을 마이그레이션해 준다.
위에 대한 상세한 내용은 2.1.
AclAuthorizer를 참고하세요.
대부분의 원본 토픽 설정값은 대상 토픽에 그대로 적용되지만, min.insync.replicas 등 몇 개는 예외이다. 이렇게 동기화에서 제외되는 설정의 목록 역시 커스터마이징 가능하다.
<명시적으로 셋팅해주어야 하는 설정들>
- 미러링되는 토픽에 해당하는 Literal 타입의 ACL 만이 미러링되기 때문에 자원 이름에 prefix 혹은 와일드카드를 사용하거나, 다른 인가 메커니즘을 사용하고 있을 경우 대상 클러스터에 명시적으로 설정을 잡아주어야 함
- 리소스에 데이터를 수정하거나 생성할 권한인
Topic:Write ACL도 미러링되지 않음 (미러메이커만이 대상 토픽에 쓸 수 있도록 하기 위해) - 장애 복구를 위해 애플리케이션이 대상 클러스터에 읽거나 쓸 수 있도록 하기 위해서는 적절한 접근 권한을 명시적으로 설정해주어야 함
1.1.5. 커넥터 태스크: tasks.max
tasks.max 는 미러메이커가 띄울 수 있는 커넥터 태스크의 최대 개수이다.
기본값은 1이며, 최소 2 이상으로 잡아줄 것을 권장한다.
복제할 토픽 파티션 수가 많은 경우 병렬 처리 수준을 높이기 위해 가능한 더 큰 값을 사용해야 한다.
1.1.6. 설정 접두어
커넥터, 프로듀서, 컨슈머, 어드민 클라이언트 등 미러메이커에 사용되는 모든 컴포넌트들에 대해서 설정 옵션을 잡아줄 수 있다.
카프카 커넥트와 커넥터 설정은 별도 접두어가 필요없지만, 미러메이커에는 2개 이상의 클러스터에 대한 설정이 포함될 수 있으므로 특정 클러스터나 복제 흐름에 적용되는 설정의 경우 접두어를 사용할 수 있다.
1.1.1. 복제 흐름에서 본 것처럼 클러스터를 구분할 때 사용하는 별칭은 해당 클러스터에 관련된 설정값을 잡아줄 때 접두어로 사용된다.
<미러메이커가 사용하는 접두어>
- {클러스터}.{커넥터 설정}
- {클러스터}.admin.{어드민 클라이언트 설정}
- {원본 클러스터}.consumer.{컨슈머 설정}
- {대상 클러스터}.producer.{프로듀서 설정}
- {원본 클러스터}->{대상 클러스터}.{복제 흐름 설정}
1.2. 다중 클러스터 토폴로지
1.1.1. 복제 흐름 에서 단순한 액티브-스탠바이 아키텍처 복제 흐름을 정의하는 미러메이커 설정 예시를 보았다.
여기서는 이제 다른 일반적인 아키텍처 패턴을 정의해본다.
액티브-액티브 토폴로지 는 단순히 양방향 복제 흐름을 활성화하는 것만으로 설정이 가능하다.
원격 토픽 앞에 클러스터 별칭을 붙임으로써 동일한 이벤트가 순환 복제되는 것을 방지한다.
여러 개의 미러메이커 프로세스를 실행시킬 때는 설정이 대상 데이터센터의 내부 토픽을 통해 공유될 때 발생하는 충돌을 방지할 수 있도록 전체 복제 토폴로지를 기술하는 공통 설정 파일을 사용하는 것이 좋다.
액티브-액티브 아키텍처 복제흐름
# 복제 흐름에 사용될 클러스터 별칭
cluster = A, B
# 각 클러스터에 대한 부트스트랩 서버 설정
A.bootstrap.servers = kafka.a.test.com:9092
B.bootstrap.servers = kafka.b.test.com:9092
# {원본}->{대상} 접두어를 사용하여 클러스터 간 복제 흐름 활성화
A->B.enabled = true
# 복제 흐름에 미러링되는 토픽을 정의
A->B.topics = .*
B->A.enabled = true
B->A.topics = .*
토폴로지에는 복제 흐름을 추가로 정의할 수 있는데 예를 들어서 위 설정에서 C 에 대한 복제 흐름을 추가하여 A 에서 B, C 로 팬아웃(fan-out) 되는 토폴로지를 구성할 수 있다.
cluster = A, B, C
C.bootstrap.servers = kafka.c.test.com:9092
A->C.enabled = true
A->C.topics = .*
1.3. 미러메이커 보안
프로덕션 환경에서는 모든 데이터센터 간 트래픽에 보안을 적용해야 한다.
카프카 클러스터 보안 설정에 대해서는
Kafka - 보안(1): 보안 프로토콜(TLS, SASL), 인증(SSL, SASL),
Kafka - 보안(2): 암호화, 인가, 감사
를 참고하세요.
미러메이커의 경우 원본과 대상 클러스터 양쪽에 대해 보안이 적용된 브로커 리스너를 사용해야 하며, 모든 데이터센터 간 트래픽에는 SSL 암호화가 적용되어야 한다.
미러메이커에 자격 증명 적용 예시
# 사용되는 보안 프로토콜은 클러스터의 부트스트랩 서버에 해당하는 브로커 리스너와 일치해야 함
# SSL 이나 SASL_SSL 을 권장함
A.security.protocol=SASL_SSL
A.sasl.mechanism=PLAIN
# SASL 을 사용했으므로 JAAS 설정을 사용하여 미러메이커가 사용할 자격 증명 지정
# SSL 의 경우 클라이언트 상호 인증을 사용할 때는 키스토어를 지정해주어야 함
A.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginMudule \
required username="MirrorMaker" password="Password"
<미러메이커에 부여되어야 하는 ACL>
- 원본 토픽을 읽어오기 위한 원본 클러스터의
Topic:Read권한 - 대상 클러스터에 토픽을 생성하고 메시지를 쓰기 위한 대상 클러스터의
Topic:Create,Topic:Write권한 - 원본 토픽의 설정을 얻어오기 위한 원본 클러스터의
Topic:DescribeConfigs권한 - 대상 토픽 설정을 업데이트하기 위한 대상 클러스터의
Topic:AlterConfigs권한 - 원본 토픽에 새 파티션이 추가되었을 때 대상 토픽에도 새 파티션을 추가하기 위한 대상 클러스터의
Topic:Alter권한 - 오프셋, 원본 컨슈머 그룹 메타데이터를 얻어오기 위한 원본 클러스터의
Group:Describe권한 - 컨슈머 그룹의 오프셋을 대상 클러스터에 커밋해주기 위한 대상 클러스터의
Gruop:Write권한 - 원본 토픽의 ACL 을 가져오기 위한 원본 클러스터의
Cluster:Descibe권한 - 대상 토픽의 ACL 을 업데이트하기 위한 대상 클러스터의
Cluster:Alter권한 - 미러메이커 내부 토픽에 사용하기 위한 원본/대상 클러스터 모두의
Topic:Create,Topic:Write권한
1.4. 프로덕션 환경에 미러메이커 배포
전용 모드(dedicated mode) 프로세스를 여러 개 띄우면 확장성과 내고장성(fault tolerance) 를 갖춘 미러메이커 클러스터를 구성할 수 있다.
전용 모드(dedicated mode)
미러메이커 클러스터에서 각종 미러링 작업을 수행하는 전용 작업 프로세스를 설정하는 방식
미러링 작업을 커넥터(task) 에 전용 프로세스로 분리하여 실행함
미러메이커를 사용하는 대부분의 조직들은 설정 매개변수를 포함하는 자체적인 시동 스크립트를 갖고 있다.
배포 자동화를 하고, 설정 옵션들을 관리하기 위해 앤서블(Ansible), 퍼펫(Puppet), 쉐프(Chef), 솔트(Salt) 와 같은 프로덕션 배포 시스템을 사용한다.
미러메이커는 상태가 없기 때문에(stateless) 디스크 공간을 아예 필요로 하지 않는다.
모든 필요한 데이터와 상태는 카프카에 저장된다.
미러메이커가 카프카 커넥트에 기반하였기 때문에 standalone(독립 실행 모드) 혹은 distributed(분산 모드) 여부에 상관없이 카프카 커넥트에서 미러메이커를 실행시킬 수 있다.
개발 환경이면 독립 실행 모드로 작동시켜서 장비 한 대에서 독립 실행되는 한 개의 커넥트 워커 프로세스로 형태로 사용해도 된다.
프로덕션 환경이라면 분산 모드로 실행시킬 것을 권장한다.
미러메이커는 가능하면 대상 데이터센터에서 실행시키는 것이 좋다.
예) A 데이터센터에서 B 데이터센터로 데이터를 보내고 있다면, B 에서 실행중인 미러메이커가 A 에서 데이터를 읽어오는 식
이유는 장거리 네트워크는 데이터센터 내의 네트워크에 비해 더 불안정할 수 있는데 만일 네트워크 단절이 일어나서 데이터센터 간 연결이 끊어졌을 경우, 컨슈머가 클러스터에 연결할 수 없는 편이 프로듀서가 연결할 수 없는 편보다 훨씬 안전하다.
컨슈머가 클러스터에 연결할 수 없을 경우 단순히 읽어오지만 못할 뿐 이벤트 자체는 여전히 원본 카프카 클러스터에 저장되어 있으므로 이벤트 유실의 위험이 없다.
2. 데이터센터 간 통신의 현실적 문제 에서 원격 브로커-컨슈머 통신을 참고하세요.
지역 읽기-원격 쓰기(Local Read-Remote Write)의 경우 데이터센터 간에 전송될 때는 암호화를 해야하지만, 데이터센터 안에서는 암호화할 필요가 없는 데이터가 여기에 해당한다.
컨슈머는 SSL 암호화를 사용해서 카프카에 연결할 경우 데이터를 암호화하기 위해 데이터를 복사해야 하기 때문에 프로듀서보다 훨씬 더 성능에 타격을 입는다.
즉, 컨슈머는 더 이상 제로카피 의 이득을 볼 수 없게 되는데 이는 곧 카프카 브로커에도 영향을 미친다.
만일 데이터센터 간 트래픽에는 암호화가 필요한데 지역 트래픽은 그렇지 않다면, 암호화되지 않은 데이터를 같은 데이터센터 내에서 읽어서 SSL 암호화된 연결을 통해 원격 데이터센터 쪽으로 쓰도록 미러메이커를 원본 쪽 데이터센터에 위치시키는 것이 더 낫다.
그러면 프로듀서쪽은 SSL 을 통해 카프카에 연결하지만, 컨슈머쪽은 그렇지 않기 때문에 성능에 큰 영향을 주지 않는다.
지역 읽기-원격 쓰기 방식을 사용한다면 acks=all, 충분한 수의 retries 를 통해 미러메이커의 커넥트 프로듀서에 절대로 이벤트 유실이 발생하지 않도록 해야 한다.
또한, 미러메이커에 문제가 발생했을 때 빠르게 실패하도록 errors.tolerance=none 설정을 잡아주어야 한다.
미러메이커를 이용할 때는 아래와 같은 사항들을 모니터링 해야한다.
- 카프카 커넥트 모니터링
- 미러메이커 지표 모니터링
- lag 모니터링
- 프로듀서/컨슈머 지표 모니터링
- 카나리아 테스트
1.4.1. 카프카 커넥트 모니터링
커넥터 상태를 모니터링하기 위한 커넥터 지표, 처리량을 모니터링하기 위한 소스 커넥터 지표, 리밸런스 지연을 모니터링하기 위한 워커 지표 등을 제공한다.
1.4.2. 미러메이커 지표 모니터링
커넥트 단위에서 제공하는 재포 외에도 미러메이커는 미러링 처리량과 복제 지연을 모니터링할 수 있는 지표들을 제공한다.
replication-latency-ms- 복제 지연 지표
- 레코드의 타임스탬프와 대상 클러스터에 성공적으로 쓰여진 시각 사이의 간격을 제공함
- 대상 클러스터가 원본 클러스터를 제대로 따라오고 있지 못한 상황을 탐지할 때 사용
record-age-ms- 복제 시점에 레코드가 얼마나 오래되었는지
byte-rate- 복제 처리량
checkpoint-latency-ms- 오프셋 마이그레이션의 지연
미러메이커도 주기적으로 대상 클러스터에 생성하는 heartbeats 토픽에 하트비트를 보내는데 이를 이용하여 미러메이커의 상태 모니터링도 가능하다.
이 토픽에 1초에 한 번씩 레코드를 추가함으로써 ‘이 클러스터를 대상 클러스터로 하는 미러링 작업이 마지막으로 이루어진 시각’을 확인할 수 있다.
emit.heartbeats.enabled=false 로 하면 이 기능을 비활성화할 수 있고, emit.heartbeats.interval.seconds 로 간격 조정이 가능하다.
1.4.3. lag 모니터링
lag 은 원본 카프카 클러스터의 마지막 메시지 오프셋과 대상 카프카 클러스터의 마지막 메시지 오프셋 사이의 차리를 가리킨다.
lag 을 통해 대상 클러스터가 원본 클러스터에 얼마나 뒤쳐져있는지 알 수 있다.
<lag 값을 추적하는 방법>
- 미러메이커가 원본 카프카 클러스터에 마지막으로 커밋된 오프셋 추적
kafka-consumer-groups툴을 이용하여 미러메이커가 현재 읽고 있는 각 파티션의 마지막 이벤트 오프셋, 미러메이커가 커밋한 마지막 오프셋, 그리고 둘 사이의 lag 을 볼 수 있음- 하지만 미러메이커가 항상 오프셋을 커밋하는 것이 아니기 때문에 이 값이 100% 정확하지는 않음
- 커밋 여부와 상관없이 미러메이커가 읽어온 최신 오프셋 추적
- 미러메이커에 포함되어 있는 컨슈머들의 핵심 지표 중 하나는 현재 읽고 있는 파티션들에 대한 lag 최대값을 보여주는 최대 컨슈머 lag 이 있음
- 이 값 역시 100% 정확하지는 않음
- 컨슈머가 읽어온 메시지를 기준으로 업데이트될 뿐, 프로듀서가 해당 메시지를 대상 카프카 클러스터에 썼는지, 응답은 받았는지에 대한 여부를 전혀 고려하지 않았기 때문임
미러메이커가 메시지를 건너뛰거나 놓칠 경우 위의 두 방법 모두 마지막 오프셋을 추적하므로 알아차릴 수 없다.
1.4.4. 프로듀서/컨슈머 지표 모니터링
Doc:: 카프카 모니터링 지표에 사용 가능한 지표 전체가 나와있다.
아래는 미러메이커 성능을 튜닝할 때 유용한 것들이다.
- 컨슈머
fetch-size-avg,fetch-size-max,fetch-rate,fetch-throttle-time-avg,fetch-throttle-time-max
- 프로듀서
batch-size-avg,batch-size-max,requests-in-flight,record-retry-rate
- 둘 다
io-ratio,io-wait-ratio
1.4.5. 카나리아 테스트
1분에 한 번 소스 클러스터의 특정 토픽에 이벤트를 하나 보낸 뒤, 대상 클러스터의 토픽에서 해당 메시지를 읽는 식으로 구현한다.
그러면 이벤트가 복제될 때까지 걸리는 시간이 일정 수준을 넘어갔을 때 경보를 받을 수 있다.
만일 그런 상황이 발생한다면 미러메이커가 lag 이 높거나 아니면 아예 작동 중이지 않은 것이다.
1.5. 미러메이커 튜닝
미러메이커는 수평 확장이 가능하다.
미러메이커 클러스터의 크기는 필요 처리량과 허용할 수 있는 lag 의 크기에 의해 결정된다.
lag 을 전혀 허용할 수 없다면 최고 수준이 처리량을 유지할 수 있는 수준으로 미러메이커의 크기를 키워야 한다.
어느 정도의 lag 을 허용할 수 있다면 미러메이커가 전체 시간의 약 75% 정도의 사용율을 보이도록 하면 된다.
커넥터 태스크 수(tasks.max) 에 따른 미러메이커 처리량은 직접 테스트를 돌려보아야 한다.
카프카에는 kafka-performance-producer 툴이 있는데 이 툴을 사용해서 원본 클러스터에 부하를 생성한 뒤 미러메이커를 연결하여 미러링하기 시작한다.
미러메이커를 1,2,4,8,16,24,32 개 태스크와 함께 실행시켜 본 후 tasks.max 의 값을 성능이 줄어드는 지점의 값보다 살짝 밑으로 잡아준다.
데이터센터 간 미러링에 대역폭은 주 병목인만큼 이벤트 압축이 권장되는데, 압축된 이벤트를 읽거나 쓰고 있을 경우 미러메이커는 이벤트의 압축을 해제한 뒤 재압축을 한다.
이 때 CPU 을 매우 많이 사용하므로 태스크 수를 늘릴 때는 CPU 사용률에 유의해야 한다.
이 과정에서 단일 미러메이커 워커의 최대 처리량을 찾을 수 있는데 이 값이 충분하지 않다면 워커를 추가해서 테스트해본다.
절대적으로 지연이 낮아야 하고, 원본에 새 메시지가 들어오는 즉시 바로 미러링이 되어야 하는 민감한 토픽들은 별도의 미러메이커 클러스터로 분리하는 것도 방법이다.
미러메이커가 사용하는 프로듀서/컨슈머를 튜닝하고 싶을 때는 먼저 프로듀서에서 병목이 발생하는지 컨슈머에서 병목이 발생하는지 확인한다.
이를 확인하는 방법 중 하나는 모니터링하고 있는 프로듀서나 컨슈머의 지표를 보고, 한 쪽은 최대 용량으로 돌아가고 있는데 한 쪽은 놀고 있다면 놀고 있는 쪽을 튜닝해주어야 한다.
<프로듀서 처리량을 높이기 위한 튜닝>
linger.ms,batch.size- 프로듀서가 계속해서 부분적으로 빈 배치들을 전송하고 있다면
linger.ms을 올려잡아 약간의 지연을 추가함으로써 처리량 증대 가능 - 꽉 찬 배치가 전송되고 있는데 메모리에는 여유가 있다면
batch.size를 올려잡아 더 큰 배치를 전송하도록 함
- 프로듀서가 계속해서 부분적으로 빈 배치들을 전송하고 있다면
max.in.flight.requests.per.connection- 현재는 일부 메시지에 대해 성공적으로 응답이 올 때까지 몇 번의 재시도가 필요한 상황에서 미러메이커가 메시지 순서를 보존하는 방법은 전송중인 요청의 수를 1로 제한하는수 밖에 없음
- 즉, 프로듀서가 요청을 전송할 때마다 대상 클러스터로부터 응답이 오기 전까지는 다음 메시지를 보낼 수 없음
- 메시지 순서가 그리 중요하지 않다면
max.in.flight.requests.per.connection의 기본값인 5를 사용하여 처리량을 증가시킬 수 있음
<컨슈머 처리량을 높이기 위한 튜닝>
fetch.max.bytes- 만일
fetch-size-avg,fetch-size-max지표가fetch.max.bytes와 비슷하게 나온다면 컨슈머는 브로커로부터 최대한의 데이터를 읽어오고 있는 것임- 메모리가 충분하다면 컨슈머가 각 요청마다 더 많은 데이터를 읽어올 수 있도록
fetch.max.bytes를 올려잡으면 됨
- 메모리가 충분하다면 컨슈머가 각 요청마다 더 많은 데이터를 읽어올 수 있도록
- 만일
fetch.min.bytes,fetch.max.wait.ms- 컨슈머의
fetch-rate지표가 높게 유지된다면 컨슈머가 브로커에게 너무 많은 요청을 보내고 있는데 정작 각 요청에서 실제로 받은 데이터를 너무 적다는 의미임 - 이 때
fetch.min.bytes와fetch.max.wait.ms를 올려잡아주면 컨슈머는 요청을 보낼 때마다 더 많은 데이터를 받게 되고, 브로커는 컨슈머 요청에 응답하기 전에 충분한 데이터가 쌓일 때까지 기다리게 됨
- 컨슈머의
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
