DDD(1) - 이벤트 소싱 도메인 모델 패턴
이 포스트에서는 DDD 에서 복잡한 비즈니스 로직을 구현하는 또다른 방식인 이벤트 소싱 도메인 모델 패턴에 대해 알아본다.
- 이벤트 소싱 개념
- 이벤트 소싱을 도메인 모델 패턴과 결합하여 이벤트 소싱 도메인 모델로 만드는 방법
이벤트 소싱 도메인 모델
- 시간의 관점을 추가하고, 비즈니스 로직을 모델링하고 구현하는 훨씬 발전된 방법
- 시간 차원을 모델링하여 도메인 모델 패턴을 확장하는 방법
이벤트 소싱 도메인 모델은 도메인 모델 패턴과 동일한 전체를 기반으로 한다.
즉, 복잡한 비즈니스 로직을 갖은 핵심 하위 도메인에 사용하며, 도메인 모델과 동인한 전술적 패턴인 밸류 오브젝트, 애그리거트, 도메인 이벤트를 사용한다.
도메인 모델 패턴과 이벤트 소싱 도메인 모델 패턴의 차이는 애그리거트의 상태를 저장하는 방식이다.
이벤트 소싱 도메인 모델은 이벤트 소싱 패턴을 사용하여 애그리거트의 상태를 관리한다.
즉, 애그리거트의 상태를 유지하는 대신 모델은 각 변경 사항을 설명하는 도메인 이벤트를 생성하고, 애그리거트 데이터에 대한 원천 데이터로 사용한다.
목차
1. 이벤트 소싱
아래와 같은 데이터가 있다고 해보자.
상태 기반 모델
| lead-id | name | status | phone | followup-on | created-on | updated-on |
|---|---|---|---|---|---|---|
| 1 | aaa | CONVERTED | 1111 | 2025-01-01T01:01:01.01Z | 2025-01-01T01:01:01.01Z | |
| 2 | bbb | CLOSED | 2222 | 2025-01-01T01:01:01.01Z | 2025-01-01T01:01:01.01Z | |
| 3 | ccc | NEW_LEAD | 3333 | 2025-01-01T01:01:01.01Z | 2025-01-01T01:01:01.01Z | |
| 4 | ddd | FOLLOWUP_SET | 4444 | 2025-01-01T01:01:01.01Z | 2025-01-01T01:01:01.01Z | 2025-01-01T01:01:01.01Z |
| 6 | eee | PAYMENT_FAILED | 5555 | 2025-01-01T01:01:01.01Z | 2025-01-01T01:01:01.01Z |
위 테이블에서 각 잠재 고객의 처리 주기를 가정할 수 있다.
- 판매 흐름은 NEW_LEAD 상태의 잠재 고객과 함께 시작함
- 판매 전화는 아래와 같은 상태일 때 종료될 수 있음
- 제안에 관심이 없는 사람(CLOSED)
- 후속 전화 예약 (FOLLOWUP_SET)
- 제안 수락 (PENDING_PAYMENT)
- 결제가 성공하면 고객으로 전환(CONVERTED) 되며, 결제가 실패(PAYMENT_FAILED)할 수도 있음
하지만 위 데이터에 빠진 정보가 있다.
- 각 데이터는 리드의 현재 상태를 문서화하는데, 각 리드가 현재 상태에 도달하기까지의 이력
- 각 리드의 수명 주기 동안 어떠한 일이 발생했는지?
- 리드가 CONVERTED 되기 전까지 몇 번이나 전화를 하고, 구매는 바로 이루어졌는지?
- 과거 데이터를 기반으로 다른 후속 조치를 취한 뒤 다시 연락하는 것이 효율적인지, 리드를 닫고 다른 잠재 고객으로 이동하는 것이 효율적인지?
위 내용에 대한 정보는 없고, 리드의 현재 상태만 데이터로 남아있다.
위 내용은 영업 프로세스를 최적화하는데 필요한 비즈니스 문제를 반영한다.
비즈니스 관점에서 데이터를 분석하여 프로세스를 최적화하는 것이 중요하다.
이벤트 소싱을 통해 이러한 누락된 정보를 채울 수 있다.
이벤트 소싱은 객체를 저장하는 대신 객체가 변경된 기록은 저장하며, 애그리거트 상태 변경 기록을 이벤트로 캡처해야 한다.
이벤트 소싱 패턴은 데이터 모델에 시간 차원을 도입한다.
애그리거트의 현재 상태를 반영하는 스키마 대신 애그리거트 수명 주기의 모든 변경사항을 문서화하는 이벤트를 유지한다.
이벤트 소싱의 개념은 간단하다.
애그리거트에서 처리하는 커맨드에 의해 상태가 변경되며 그 변경은 적어도 하나의 이벤트로 표현된다. 이러한 이벤트는 특정 애그리거트에 대해 이벤트가 발생한 순서를 유지할 수 있는 DB 에 저장된다.
이렇게 정렬된 이벤트 컬렉션을 애그리거트 스트림이라고 한다.
애그리거트에 변경 사항이 발생하여 하나 이상의 이벤트가 발생할 때마다 다른 버전의 스트림으로 표현된다.
아래는 이벤트 소싱 시스템에서 위 상태 기반 모델의 lead-id 1 번인 CONVERTED 고객의 데이터가 표현되는 방식이다.
[
{
"lead-id": 1,
"event-id": 0,
"event-type": "lead-initialized", // 리드에서 이벤트 생성
"name": "aab",
"phone": "1111",
"timestamp": "2025-01-01T01:00:01.01Z"
},
{
"lead-id": 1,
"event-id": 1,
"event-type": "contacted", // 영업 담당자가 연락함
"timestamp": "2025-01-01T01:00:02.01Z"
},
{
"lead-id": 1,
"event-id": 2,
"event-type": "followup-set", // 다른 전화번호로 연락하기로 함
"followup-on": "2025-01-01T01:00:02.01Z",
"timestamp": "2025-01-01T01:00:02.01Z"
},
{
"lead-id": 1,
"event-id": 3,
"event-type": "contact-details-updated", // 이름에 오타가 있어서 수정함
"name": "aaa",
"timestamp": "2025-01-01T01:00:03.01Z"
},
{
"lead-id": 1,
"event-id": 4,
"event-type": "contacted", // 다시 연락함
"timestamp": "2025-01-01T01:00:04.01Z"
},
{
"lead-id": 1,
"event-id": 5,
"event-type": "order-submitted", // 주문서 제출, 주문은 XX 까지 결제 예정
"payment-deadline": "2025-01-01T01:10:02.01Z",
"timestamp": "2025-01-01T01:00:05.01Z"
},
{
"lead-id": 1,
"event-id": 6,
"event-type": "payment-confirmed", // 결제 완료되서 리드가 신규 고객으로 전환됨
"stauts": "converted",
"timestamp": "2025-01-01T01:01:01.01Z"
}
]
고객의 상태는 간단한 변환 로직을 각 이벤트에 순차적으로 적용하여 이런 도메인 이벤트로부터 쉽게 프로젝션할 수 있다.
프로젝션
이벤트 소싱 패턴에서 쓰기 모델을 통해 이력 형태로 저장된 데이터를 읽기 모델을 적용하여 원하는 시점의 데이터를 추출하는 기법
public class LeadSearchModelProjection {
long leadId;
HashSet<String> name;
HashSet<String> phone;
int version;
public void apply(LeadInitialized event) {
leadId = event.leadId;
name = new HashSset<String>();
phone = new HashSset<String>();
name.add(event.name);
phone.add(event.phone);
version = 0;
}
public void apply(Contacted event) {
version += 1;
}
public void apply(FollowupSet event) {
version += 1;
}
// ...
}
이런 식으로 애그리거트의 이벤트를 반복해서 순서대로 정의된 apply() 메서드에 넣으면 제일 처음의 상태 기반 모델 테이블에 모델링된 상태 표현이 정확히 만들어진다.
각 이벤트를 적용한 후 버전 필드가 증가하는데 이는 엔티티에 가해진 모든 변경 횟수를 의미한다.
따라서 버전 5의 엔티티 상태가 필요하면 처음 5개의 이벤트만 적용하면 된다.
1.1. 검색
리드의 이름, 전화번호는 업데이트될 수 있는 상황에서 검색 기능을 구현한다고 해보자.
이벤트 소싱을 사용하면 과거 정보를 쉽게 프로젝션할 수 있다.
public class LeadSearchModelProjection {
long leadId;
HashSet<String> name;
HashSet<String> phone;
int version;
public void apply(LeadInitialized event) {
leadId = event.leadId;
name = new HashSset<String>();
phone = new HashSset<String>();
name.add(event.name);
phone.add(event.phone);
version = 0;
}
public void apply(ContactDetailsChange event) {
name.add(event.name);
phone.add(event.phone);
version += 1;
}
public void apply(FollowupSet event) {
version += 1;
}
// ...
}
위 로직은 LeadInitialized, ContactDetailsChange 이벤트를 사용하여 각 리드의 개인 정보를 채운다.
이 프로젝션 로직을 이름이 aaa 인 이벤트에 적용하면 아래 상태가 된다.
leadId: 1
name: ['aab', 'aaa']
phone: ['1111']
version: 6
1.2. 분석
위 데이터에서 좀 더 분석하기 편한 리드 데이터를 요청한다고 해보자.
후속 전화가 예약된 (FOLLOWUP-SET) 개수를 얻은 후, 나중에 종료된 리드 데이터를 필터링한 모델을 사용하여 영업 프로세스를 최적화하려 한다.
public class AnalysisModelProjection {
long leadId;
int followups;
LeadStatus status;
int version;
public void apply(LeadInitialized event) {
leadId = event.leadId;
followups = 0;
status = LeadStatus.NEW_LEAD;
version = 0;
}
public void apply(FollowupSet event) {
status = LeadStatus.FOLLOWUP_SET;
followups += 1;
version += 1;
}
public void apply(OrderSubmitted event) {
status = LeadStatus.PENDING_PAYMENT;
version += 1;
}
public void apply(PaymentConfirm event) {
status = LeadStatus.CONVERTED;
version += 1;
}
}
위 로직은 후속 전화 이벤트가 리드 이벤트에 나타난 횟수를 유지하며, 이 프로젝션을 애그리거트 이벤트에 적용하면 아래 상태가 된다.
leadId: 1
followups: 1
status: converted
version: 6
실제 필요한 기능을 구현하려면 프로젝션된 모델을 DB 에 유지해야 한다.
이를 가능하게 하는 CQRS(command-query responsibility segregation: 명령과 조회의 책임 분리) 패턴은 DDD - CQRS 를 참고하세요.
1.3. 원천 데이터
이벤트 소싱 패턴은 객체 상태에 대한 모든 변경사항이 이벤트로 표현되고 저장되는데 이 때 이벤트는 시스템의 원천 데이터가 된다.
이벤트를 저장하는 DB 는 유일하고 일관된 시스템의 원천 데이터이며, 이러한 이벤트를 저장하는데 사용되는 DB 를 이벤트 스토어(Event Store)라고 한다.
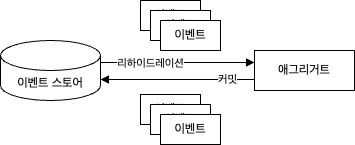
리하이드레이션
데이터에 액세스할 수 있게 재구성 또는 복원하는 작업
1.4. 이벤트 스토어(Event Store)
이벤트 스토어는 추가만 가능하므로 이벤트를 수정하거나 삭제할 수 없다. (단, 데이터 마이그레이션과 같은 예외는 제외)
이벤트 스토어는 엔티티에 속한 모든 이벤트를 가져오고 이벤트를 추가하는 기능을 지원해야 한다.
interface IEventStore {
IEnumerable<Event> fetch(Guid instanceId);
void append(Guid instanceId, Event[] newEvents, int expectedVersion);
}
위에서 append() 의 expectedVersion 인수는 엔티티 버전 및 낙관적 동시성 제어 구현 시 필요하다.
대부분 CQRS 패턴을 구현하기 위해 추가 엔드포인트가 필요하다.
2. 이벤트 소싱 도메인 모델
이벤트 소싱 도메인 모델은 애그리거트의 수명주기를 모델링하기 위해 도메인 이벤트를 사용한다.
애그리거트 상태에 대한 모든 변경사항은 도메인 이벤트로 표현되어야 한다.
<이벤트 소싱 애그리거트에 대한 각 작업 순서>
- 애그리거트의 도메인 이벤트 로드
- 이벤트를 의사결정을 내리는 데 사용할 수 있는 상태로 프로젝션하여 상태 표현 재구성
- 애그리거트의 명령을 실행하여 비즈니스 로직 실행 후 결과적으로 새로운 도메인 이벤트 생성
- 새로운 도메인 이벤트를 이벤트 스토어로 커밋
1. 도메인 모델 에서 본 Ticket 애그리거트를 보자.
public class TicketAPI {
private TicketRepository ticketRepository;
public void RequestEscalation(TicketId id, EscalationReason reason) {
// 관련 티켓의 이벤트 로드 (= 애그리거트의 도메인 이벤트 로드)
Event[] events = ticketRepository.loadEvents(id);
// 관련 명령 호출 (= 애그리거트의 명령을 실행하여 비즈니스 로직 실행
RequestEscalation cmd = new RequestEscalation(reason);
ticket.execute(cmd);
// 애그리거트 인스턴스를 리하이드레이션(= 이벤트를 의사 결정을 내릴 수 있는 상태로 프로젝션하여 상태 표현 재구성)
Ticket ticket = new Ticket(events);
long originalVersion = ticket.version;
// 변경 사항을 DB 에 저장 (= 새로운 도메인 이벤트를 이벤트 스토어로 커밋)
ticketRepository.commitChange(ticket, originalVersion);
}
}
위에서 Ticket 생성자는 Ticket 애그리거트의 리하이드레이션 로직을 포함한다.
상태를 프로젝션하는 TicketState 인스턴스를 생성하고, 티켓의 각 이벤트에 대해 appendEvent() 메서드를 순차적으로 호출한다.
이벤트 소싱 애그리거트
public class Ticket {
// ...
private List<DomainEvent> domainEvents = new List<DomainEvent>();
private TicketState state;
// ...
// 애그리거트 인스턴스를 리하이드레이션(= 이벤트를 의사 결정을 내릴 수 있는 상태로 프로젝션하여 상태 표현 재구성)
public Ticket(IEnumerable<IDomainEvents> events) {
state = new TicketState();
for (i=0; i <= events.length; i++) {
appendEvent(events[i]);
}
}
// 들어오는 이벤트를 TicketState 프로젝션 로직에 전달하여 티켓의 현재 상태에 대한 메모리 내 표현 방식을 만듦
private void appendEvent(IDomainEvent event) {
domainEvents.append(event);
// apply() 의 올바른 오버로드를 동적으로 호출
apply(event);
}
}
애그리거트 이벤트 컬렉션에 추가된 모든 이벤트는 TicketState 클래스의 상태 프로젝션 로직으로 전달되고, 여기서 관련 필드값이 이벤트 데이터에 따라 변경된다.
public class TicketState {
public TicketId id;
public int version;
public boolean isEscalated;
// ...
public void apply(TicketInitialized event) {
id = event.id;
version = 0;
isEscalated = false;
// ...
}
public void apply(TicketEscalated event) {
isEscalated = true;
version += 1;
}
// ...
}
2.1. 장점
- 상태 재구성
- 애그리거트의 모든 상태 변화는 도메인 이벤트로 기록
- 필요할 때 언제든지 과거 이벤트를 순차적으로 리플레이하여 상태 재현 가능
- 실용적 유스케이스:
- 소급 디버깅 → 버그가 발생한 시점의 정확한 상태로 시스템을 복원해 문제 분석 가능
- 추가 인사이트 제공
- 기록된 이벤트는 새로운 관점에서 재해석 가능
- 기존 이벤트를 기반으로 추가 프로젝션, 리포트, 통계 등 다양한 뷰 생성 가능
- 새로운 요구사항이 생겨도 이벤트만 잘 정의되어 있다면 과거 데이터로부터 새로운 인사이트 도출 가능
- 완전한 감사 추적
- 이벤트 소싱 기반 시스템에서는 모든 변경 이력이 명확하게 남아있음
- 누가, 언제, 무엇을, 왜 변경했는지를 정확하게 추적 가능
- 보안 감사, 규제 준수, 법적 대응에 매우 유리
- 고급 낙관적 동시성 제어(Optimistic Concurrency Control)
- 고급 낙관적 동시성 제어는 읽기 데이터가 기록되는 동안 다른 프로세스에 의해 덮어 쓰여지는 경우 예외를 발생시킴
- 이벤트 소싱을 사용하면 기존 이벤트를 읽고 새로운 이벤트를 작성하는 동안 정확히 어떤 일이 일어났는지 알 수 있음
- 이벤트 스토어에서 동시에 추가된 정확한 이벤트를 추출하고, 새로운 이벤트가 시도된 작업과 충돌하는지 여부 확인이 가능함
2.1.1. 낙관적 동시성 제어(OCC, Optimistic Concurrency Control)
‘낙관적 동시성 제어’는 개념이고, ‘낙관적 잠금’은 그 개념을 구현하는 방식 중 하나이다.
<낙관적 동시성 제어>
- 복수의 트랜잭션이 충돌하지 않을거라고 ‘낙관적으로’ 가정하고 먼저 작업을 수행함
- 다만, 커밋 직전에 다른 트랜잭션과 충돌이 발생했는지 검사
- 충돌이 있으면 롤백하고 사용자에게 재시도 요청
- 주로 읽기가 많은 시스템, 경합이 적은 시스템에 유리함
<낙관적 잠금>
- 위 개념을 실제로 구현할 때 흔히 사용하는 방식 중 하나
- 일반적으로 버전 필드를 사용함
- 예) 엔티티에 version 컬럼을 추가하여 업데이트 시 버전 일치 여부 검사
- JPA 에서도
@Version애너테이션으로 구현 가능
| 항목 | 낙관적 동시성 제어 | 낙관적 잠금 |
|---|---|---|
| 의미 | 충돌이 없다고 가정하는 제어 전략 | 그 전략을 버전 기반으로 구현하는 기술 |
| 대상 | 광범위한 전략 개념 | 구현 방식 중 하나 |
| 예시 | 커밋 시 충돌을 검사하여 실패 시 롤백 | 버전 컬럼을 이용한 업데이트 시 일치 검사 |
| 항목 | 낙관적 잠금 | 비관적 잠금 |
|---|---|---|
| 접근 방식 | 충돌이 나지 않는다고 믿고 실행 | 충돌이 날 거라고 보고 선제적으로 잠금 |
| 성능 | 경합이 적은 경우 효율적 | 경합이 많은 경우 안정적 |
| 구현 | 버전 검사(@Version) | DB 잠금 (SELECT FOR UPDATE) |
2.2. 단점
- 학습 곡선
- 모델의 진화
- 이벤트 소싱 모델을 발전시키는 것은 어려움
- 이벤트 소싱의 정의를 엄밀히 따지면 이벤트는 변경할 수 없음
- 아키텍처 복잡성
- 이벤트 소싱을 구현하면 수많은 아키텍처의 ‘유동적인 부분’이 도입되어 전체 설계가 더 복잡해짐
어떤 비즈니스 로직 구현 패턴을 사용할지 결정하는데 도움이 되는 법칙에 대해서는 DDD(1) - 휴리스틱 설계 를 참고하세요.
3. 이벤트 소싱 패턴 구현 시 고려할 부분
이벤트 소싱은 단순히 이벤트를 저장하는 패턴이 아니다.
실전에서는 데이터 정합성, 보안, 스냅숏 처리, CQRS 분리 등 다양한 측면을 함께 고려해야 한다.
3.1. 이벤트 스토어 샤딩
이벤트 소싱은 확장성 높은 설계가 가능하다.
모든 작업은 단일 애그리거트로 단위로 수행되므로, 애그리거트 ID 기준으로 샤딩하면 수평 확장이 가능하다. (= 즉, 이벤트 스토어를 여러 개로 분할)
단, 하나의 애그리거트 인스턴스에 속하는 모든 이벤트는 반드시 하나의 샤드에 속해야 한다.
샤딩
데이터를 분할해 물리적으로 서로 다른 저장소에 나누는 방식
대량의 데이터를 처리하기 위해 DB 테이블을 분할하여 물리적으로 서로 다른 곳에 분산 저장 및 조회
3.2. 데이터 삭제
이벤트 스토어는 기본적으로 추가 전용 DB 이지만, GDPR 같은 법적 요구에 따라 개인정보 삭제가 필요할 수 있다.
이 때는 Forgettable Payload Pattern 으로 해결할 수 있다.
<Forgettable Payload Pattern>
- 민감 정보를 암호화하여 이벤트에 포함
- 암호화 키는 외부 key-value 저장소에 저장
- key: 애그리거트 ID / value: 암호화 키
- 삭제 시 암호화 키만 제거
- 이벤트는 남지만 해독 불가 상태가 됨
3.3. 여러 애그리거트 타입에서 설계 변경이 발생한 경우
애그리거트가 변경되면 이벤트 스트림을 유지하면서도 새로운 모델에 적용해야 한다.
방법은 기본 스트림을 분할하거나, 복수 스트림을 병합하는 새로운 스트림을 생성해야 한다.
3.4. 애그리거트 스트림 이벤트에 오류가 있는 경우
기존 이벤트는 절대 수정하지 말고, 보상 이벤트(compensating event) 를 따로 추가한다.
이 방식은 이전에 오류의 영향을 받은 상태로 재구성된 애그리거트 상태의 오류와 오류가 포함된 이벤트의 모든 다운스트림 소비자에 대해 오류를 보상하게 된다.
3.5. 대량의 이벤트 스트림을 가진 애그리거트 상태를 재구성하는 경우
수천 개 이벤트를 하나하나 리플레이하면 성능 저하가 발생한다.
이 때 상태 스냅숏 전략을 적용하면 성능을 향상시킬 수 있다.
이 스냅숏은 특정 버전 간격(예: 100, 200 또는 허용 가능한 성능을 달성하는 버전 수마다) 에 따라 전체 애그리거트 상태의 스냅솟을 생성한다. 애그리거트 상태를 재구성하고자 스트림을 읽을 때 스냅숏을 먼저 읽은 후 스냅숏 버전 이후에 발생한 이벤트만 순서대로 읽고 상태에 적용한다.
스냅숏 방식을 이용하면 이벤트가 아무리 많아도 10~20개만 리플레이하면 상태 복구가 가능하다.
3.6. 이벤트에서 복잡한 조회 뷰가 필요한 경우
이벤트 소싱을 사용할 때는 거의 항상 CQRS 가 필요하다고 가정해야 한다.
이유는
- 이벤트는 도메인 행위 중심으로 저장됨
- 복잡한 읽기를 위한 별도 리드 모델 필요
4. 일반 로그 방식이 적합하지 않은 이유
4.1. 텍스트 파일에 로그를 작성하여 감사 로그를 사용할 수 없는 이유
실시간 데이터 처리 DB 와 로그 파일 모두에 데이터를 쓰는 것은 결국 DB 와 파일, 2 가지 저장 장치에 대한 트랜잭션이므로 오류가 발생하기 쉽다.
4.2. 동일한 DB 트랜잭션에서 로그를 로그 테이블에 추가할 수 없는 이유
개발자가 실수로 로그 추가를 누락할 수 있으며, 유지 보수 중 신뢰성이 저하된다.
4.3. 전용 로그 테이블로 복사하는 DB 트리거를 사용할 수 없는 이유
이 방식은 로그 테이블에 레코드를 추가하기 위해 명시적인 호출은 필요하지 않다.
하지만 결과 기록에는 어떤 필드가 변경되었는지에 대한 사실만 있을 뿐, ‘왜’ 라는 정보가 없다.
변경에 대한 이력 정보가 없다면 추론 가능한 프로젝션 모델을 만들 수 없다.
정리하며..
- 이벤트 소싱 도메인 모델은 애그리거트 상태에 대한 모든 변경사항을 일련의 도메인 이벤트로 표현함
- 결과 도메인 이벤트는 애그리거트의 현재 상태를 프로젝션하는데 사용할 수 있음
- 이벤트 기반 모델은 모든 이벤트를 특정 작업에최적화된 여러 표현 모델로 프로젝션할 수 있는 유연성을 제공함
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 블라드 코노노프 저자의 도메인 주도 설계 첫걸음과 반 버논, 토마스 야스쿨라 저자의 전략적 모놀리스와 마이크로서비스를 기반으로 스터디하며 정리한 내용들입니다.
