Kafka - 스트림 처리(1): 스트림 처리 개념, 스트림 처리 디자인 패턴
전통적으로 카프카는 이벤트 스트림을 전달하는 것만 가능할 뿐 메시지 처리나 변환은 불가능한 강력한 메시지 버스로 인식되어 왔고, 신뢰성 있는 전달이 가능했기 때문에 카프카는 스트림 처리 시스템을 위한 완벽한 저장소 역할을 할 수 있었다.
처음에는 단순한 메시지 버스로, 나중에는 데이터 통합 시스템으로 카프카의 활용이 늘어나면서 많은 조직들이 내용상 중요하고, 완벽한 순서를 유지하면서 오랫동안 저장되어 있고, 스트림 처리 프레임워크를 사용해서 처리만 하면 결과가 나오는 데이터 스트림을 대거 보유하게 되었다.
카프카 스트림즈를 사용하면 외부 처리 프레임워크에 의존할 필요 없이 애플리케이션에 이벤트를 읽고, 처리하고, 쓰는 기능을 구현할 수 있다.
- 스트림 처리가 무엇인지?
- 스트림 처리의 기본 개념과 모든 스트림 처리 시스템에 공통적으로 사용되는 디자인 패턴들
- 카프카의 스트림 처리 라이브러리의 목표와 아키텍처
목차
개발 환경
- mac os
- openjdk 17.0.12
- zookeeper 3.9.2
- apache kafka: 3.8.0 (스칼라 2.13.0 에서 실행되는 3.8.0 버전)
1. 스트림 처리란?
데이트 스트림(= 이벤트 스트림, 스트리밍 데이터) 에 대해 알아보자.
데이터 스트림은 무한히 늘어나는 데이터세트를 추상화한 것이다.
시간이 흐름에 따라 새로운 레코드가 계속해서 추가되기 때문에 데이터세트가 ‘무한’해진다.
‘무한’이라는 특성 외에도 이벤트 스트림 모델에는 아래와 같은 특성들이 있다.
- 이벤트 스트림에는 순서가 있음
- 이벤트는 그 자체로 다른 이벤트 전/후에 발생했다는 의미를 가짐
- 이것은 이벤트 스트림과 DB 테이블의 차이점 중 하나임
테이블의 레코드는 항상 순서가 없는 것으로 간주하기 때문에 ‘order by’ 절은 관계형 모델의 일부는 아님. 단지 보기 편하라고 추가된 기능일 뿐임
- 데이터 레코드는 불변함
- 이벤트는 한 번 발생한 뒤에는 절대 수정할 수 없음
- 기존 거래가 취소되면 취소되었다는 추가적인 이벤트 스트림이 쓰여지는 개념임
- 이것이 이벤트 스트림과 DB 테이블의 또 다른 차이점임
- 이벤트 스트림은 재생(replay) 가능함
- 과거의 raw stream 을 그대로 재생할 수 있다는 것은 에러를 수정하거나, 감사를 수행하기 위해 매우 중요함
이벤트 스트림에 대해 알아보았으니 이제 스트림 처리에 대해 알아보자.
스트림 처리는 하나 이상의 이벤트 스트림을 계속해서 처리하는 것이다.
스트림 처리는 ‘요청-응답’, ‘배치 처리’ 와 마찬가지로 프로그래밍 패러다임 중 하나이다.
- 요청-응답(Request-Response)
- 응답 시간이 1 ms~x ms 수준인 패러다임으로 가장 지연이 적은 패러다임임
- 처리 방식이 보통 블로킹 방식이라 요청을 보낸 뒤 응답을 받을 때까지 대기하는 것이 보통임
- 데이터베이스 관점에서 이 패러다임을 OLTP(OnLine Transaction Processing) 으로 알려져있음
- POS(Point-of-sale) 시스템, 결제 시스템, 시간 추적 시스템이 보통 이 패러다임으로 동작함
- 배치 처리(Batch Processing)
- 지연이 크지만, 처리량도 큼
- 필요한 모든 입력데이터를 읽고, 모든 출력 데이터를 쓰고, 다음 번 실행 시간까지 대기하는 식임
- 사용자들은 결과물이 다소 시간이 지난 데이터라는 것은 감안하고 봄
- 데이터베이스 관점에서 Data Warehouse, BI(Business Intelligence) 가 이 패러다임에 속함
- 이 패러다임은 효율성이 높고, 규모의 경제를 달성할 수 있지만 최근의 비즈니스는 보다 시기적절하고 효율적인 의사 결정을 위해 더 짧은 시간 간격 안에 사용 가능한 데이터를 필요로 함
- 스트림 처리
- 연속적이고 논블로킹하게 동작하는 방식임
- 스트림 처리는 이벤트 처리에 2ms 정도 기다리는 응답-요청 방식과 하루 한번 작업이 실행되고 완료하는데 많은 시간이 걸리는 배치 처리 사이의 격차를 메워줌
- 대부분의 비즈니스는 굳이 수 ms 이내의 응답을 즉시 요구하지는 않지만, 그렇다고 해서 다음 날까지 기다릴 수도 없음
- 의심스러운 카드 결제나 네트워크 사용 내역이나 물품 배송 추적 등 ‘연속적이지만 논블로킹한 처리’에 딱 맞는 패러다임임
무한한 크기의 데이터 세트에서 연속적으로 데이터를 읽어와서 처리를 하고 결과를 내보내면 스트림 처리를 수행하고 있는 것이다.
단, 이것이 지속적으로 계속되어야 한다.
매일 오전 2시에 시작해서 스트림에서 100개의 레코드를 읽어서 처리하고 결과를 내놓은 뒤 끝나는 프로세스는 엄밀히 말해서 스트림 처리 프로세스라고 할 수 없다.
2. 스트림 처리 개념
스트림 처리는 데이터를 읽고, 처리하고, 결과물을 쓴다는 점에서 다른 형태의 데이터 처리와 비슷하지만 스트림 처리 고유의 핵심 개념이 몇 개 있다.
그래서 다른 형태의 데이터 처리 경험이 있는 사람이 스트림 처리 애플리케이션을 개발하면 혼란을 일으키기도 하는데 그 중 몇 개를 살펴보자.
2.1. 토폴로지
스트림 처리 애플리케이션은 하나 이상의 처리 토폴로지를 포함한다.
하나의 처리 토폴로지는 아래의 요소로 구성된다.
- 하나 이상의 소스 스트림
- 스트림 프로세서의 그래프
- 하나 이상의 싱크 스트림
하나의 토폴로지는 위 요소들이 서로 연결된 것으로서, 하나 이상의 소스 스트림에서 시작된 이벤트 스트림은 연결된 스트림 프로세서들을 거치면서 처리되다가 마지막에 하나 이상의 싱크 스트림에 결과를 쓰는 것으로 끝난다.
각 스트림 프로세서는 이벤트 변환을 위해 이벤트 스트림에 가해지는 연산 단계라고 할 수 있다.
2.2. 시간: TimestampExtractor
스트림 처리 시스템은 보통 아래와 같은 시간 개념을 사용한다.
- 이벤트 시간(Event Time): 정확성 제공
- 이벤트가 발생하여 레코드가 생성된 시점
- 0.10.0 이후부터 카프카는 프로듀서 레코드를 생성할 때 기본적으로 현재 시각을 추가함
- 만일 이벤트 시간이 애플리케이션의 이벤트 시간 개념과 일치하지 않는다면 레코드에 이벤트 시간을 가리키는 필드를 하나 추가하여 나중에 처리할 때 2개의 시간을 모두 활용할 수 있게 하는 것이 좋음
예) 이벤트가 발생하고 시간이 조금 지난 뒤에 DB 레코드를 기준으로 카프카 레코드를 생성할 경우 - 데이터의 정확한 시점을 반영할 수 있기 때무넹 분석 및 처리 결과의 신뢰성이 높음
- 로그 추가 시간(= 접수 시간, Ingestion Time): 단순성과 대안 제공
- 이벤트가 카프카 브로커에 전달된 후 레코드가 토픽 파티션에 저장된 시점
- 0.10.0 이후부터 카프카가 로그 추가 시간을 저장하도록 설정되어 있음
- 설정이 간단하며 이벤트 시간이 없을 경우 대안으로 사용가능하지만, 이벤트 발생 시점과의 차이가 클 경우 정확도가 떨어질 수 있음
- 처리 시간(Processing Time): 실시간성 제공
- 스트림 처리 애플리케이션이 연산을 수행하기 위해 이벤트를 받은 시간(= 이벤트를 처리한 시간)
- 구현이 간단하며, 실시간 처리가 가능함
- 동일한 이벤트라고 하더라고 언제 스트림 처리 애플리케이션이 이벤트를 읽었느냐에 따라 전혀 다른 타임스탬프가 주어질 수 있고, 심지어 같은 애플리케이션 안에서도 스레드별로 다를 수도 있음
- 따라서 처리 시간은 신뢰성이 매우 떨어지므로 분석 목적으로는 적합하지 않음
특정 애플리케이션에서 위 3가지 시간 개념을 동시에 사용하면 데이터 지연 원인 분석(이벤트 발생-저장-처리 간의 시간 비교)을 할 수 있다.
만일 특정 요구 사항에 따라 하나의 시간 기준만 선택적으로 사용할 수도 있다.
예) 실시간 처리가 중요할 경우 처리 시간을 우선적으로 사용
카프카 스트림즈는 TimestampExtractor 인터페이스를 사용하여 각 이벤트에 시간을 부여하는데 개발자는 이 인터페이스의 서로 다른 구현체를 사용하여 위의 3가지 시간 개념 중 하나를 사용하거나, 이벤트 내용에서 타임스탬프를 결정하는 등의 완전히 다른 시간 개념을 사용할 수도 있다.
카프카 스트림즈가 결과물을 토픽에 쓸 때 아래 규칙에 따라서 이벤트에 타임스탬프를 부여한다.
- 결과 레코드가 입력으로 주어진 레코드에 직접적으로 대응될 경우
- 결과 레코드는 입력 레코드와 동일한 타임스탬프 사용
- 결과 레코드가 집계(aggregation) 연산의 결과물일 경우
- 집계에 사용된 레코드 타임스탬프의 최대값을 결과 레코드의 타임스탬프로 사용
- 결과 레코드가 두 스트림을 join 한 결과물일 경우
- join 된 두 레코드 타임스탬프 중 큰 쪽의 타임스탬프를 결과 레코드의 타임스탬프로 사용
- 스트림과 테이블을 조인한 경우, 스트림 레코드 쪽의 타임스탬프를 사용
punctuate()와 같이 입력과 상관없이 특정한 스케쥴에 따라 데이터를 생성하는 카프카 스트림즈 함수에 의해 생성된 결과 레코드일 경우- 스트림 처리 애플리케이션 현재 내부 시각에 따라 결정됨
전체 파이프라인은 표준화된 시간대 하나만 사용해야 한다.
만일 서로 다른 시간대의 데이터 스트림을 다뤄야하는 경우, 윈도우에 작업을 수행하기 전에 이벤트 시각을 하나의 시간대로 변환해 주어야 한다. 아예 레코드에 시간대 정보를 저장해넣는 것도 방법이다.
2.3. 상태(state)
각 이벤트를 따로따로 처리한다면 스트림 프로세싱은 매우 간단해진다.
하지만 다수의 이벤트가 포함되는 작업을 한다면 좀 복잡해진다.
예) 이벤트를 종류별로 집계, 이동 평균 계산, 2개의 스트림을 조인하여 확장된 정보를 보유하는 스트림 생성 등등..
특정 시간동안 발생한 타입별 이벤트 수나 join, 합계, 평균 등을 계산해야 하는 모든 이벤트 등 더 많은 정보를 추적 관리할 때 이러한 정보를 상태(state) 라고 한다.
스트림 처리 애플리케이션의 로컬 변수에 상태를 저장하면 된다고 생각할 수도 있지만 그렇게 하게 되면 스트림 처리 애플리케이션이 정지하거나 크래시가 날 경우 상태가 유실되고 겨로가가 달라지기 때문에 스트림 처리에서 상태를 관리하는 방법으로서 신뢰성이 떨어진다.
따라서 최신 상태를 보존하면서 애플리케이션을 재시작할 때 상태가 복구되도록 신경쓸 필요가 있다.
스트림 처리에는 로컬 혹은 내부 상태와 외부 상태, 2가지 유형의 상태가 있다.
- 로컬 or 내부 상태
- 스트림 처리 애플리케이션의 특정 인스턴스에서만 사용할 수 있는 상태
- 보통 애플리케이션에 포함되어 구동되는 내장형 인메모리 DB 를 사용하여 유지 관리됨
- 장점은 매우 빠르다는 점임
- 단점은 사용 가능한 메모리 크기의 제한은 받는다는 점임
- 스트림 처리의 많은 디자인 패턴들은 데이터를 분할해서 한정된 크기의 로컬 상태를 사용하여 처리 가능한 서브스트림을 만드는 데 초점을 두고 있음
- 외부 상태
- 외부 데이터 저장소에서 유지되는 상태임
- 대부분 카산드라와 같은 NoSQL 시스템을 사용하여 저장됨
- 장점은 사실상 크기에 제한이 없으며, 여러 애플리케이션 인스턴스에서 접근이 가능하다는 점임
- 단점은 다른 시스템을 추가하는데 따른 지연/복잡도 증가, 가용성 문제임 (외부 시스템이 사용 불가능할 때 대응할 방법도 필요함)
- 많은 스트림 처리 애플리케이션은 외부 저장소를 사용하는 걸 피하거나, 내용을 로컬 상태에 캐싱함으로써 외부 저장소와 가능한 한 통신하지 않게 함으로써 지연 부담을 최소화함
2.4. 스트림-테이블 이원성(Stream-Table Duality)
테이블은 현재 시점에서의 데이터를 찾을 수는 있지만 과거의 변경 내역을 저장하도록 특별히 설계되어 있지 않다면 과거 데이터는 찾을 수 없다.
테이블과 달리 스트림은 변경 내역을 저장한다.
스트림은 변경을 유발하는 이벤트의 연속이다.
<테이블을 스트림으로 변환하는 작업>
- 테이블을 수정한 변경 내역을 갸져와서 스트림에 저장하면 됨
- 많은 DB 에서는 이러한 변경점들을 잡아내기 위한 CDC 솔루션을 제공하며, 이러한 변경점을 스트림 처리에 활용할 수 있도록 카프카로 전달해 줄 수 있는 카프카 커넥터가 많이 있음
<스트림을 테이블로 변환하는 작업>
- 스트림에 포함된 모든 변경 사항을 테이블에 적용하면 됨
- 이러한 작업을 “스트림을 구체화(materialize) 함” 이라고 함
2.5. 시간 윈도우(Time Windows)
대부분의 스트림 작업은 시간을 윈도우라고 불리는 구간 단위로 잘라서 처리한다.
예) 이동 평균 계산, 오늘 가장 많이 팔린 상품 계산 등..
동일한 시간 간격 안에 발생한 이벤트들끼리 조인하는 두 스트림을 조인하는 작업도 윈도우 작업이다.
<이동 평균 계산 시 주의할 점>
- 윈도우 크기
- 예를 들어 5분 마다 발생한 모든 이벤트의 평균을 구하는 것인지? 15분인지?
- 윈도우 크기가 커질수록 이동 평균은 완만해지고, lag 도 커짐 (주가가 오를 경우 윈도우가 작은 경우보다 큰 경우가 더 알아차리기 어려움)
- 카프카 스트림은 윈도우의 크기가 비활동 기간의 길이에 따라 결정되는 세션 윈도우 역시 지원함
- 세션 간격(session gap)을 정의하면 세션 간격보다 작은 시간 간격을 두고 연속적으로 도착한 이벤트들은 하나의 세션에 속하게 됨
- 세션 갭 이상으로 이벤트가 도착하지 않으면 새로운 세션이 생성되어 이후 도착하는 이벤트들을 담게 됨
- 시간 윈도우의 진행 간격
- 5분 단위 평균은 매초, 매분 혹은 이벤트가 도착할 때마다 업데이트될 수 있음
- 윈도우에는 호핑 윈도우(hopping window) 와 텀블링 윈도우(tumbling window) 개념이 있음
- 윈도우를 업데이트할 수 있는 시간(grace period)
- 만일 00:00~00:05 까지의 시간 윈도우에 대해 5분 단위 이동 평균을 계산하고 있는데 만일 한 시간 뒤에 이벤트 시간이 00:02 인 레코드가 주어진 경우 이것을 00:00~00:05 기간에 대한 결과에 업데이트해야 할까, 아니면 무시해야 할까?
- 이벤트가 이벤트에 해당하는 윈도우에 추가될 수 있는 기한을 정해두는 것이 이상적임
- 예를 들어 이벤트가 최대 4시가지 지연될 수 있다면 겨로가를 다시 계산하고 업데이트 함
2.5.1. 텀블링 윈도우(tumbling window) vs 호핑 윈도우(hopping window)
텀블링 윈도우는 크기가 일정한 고정된 시간 간격으로 스트림을 분할하여 처리하는 윈도우이다.
윈도우 간에 중첩이 없으며, 각 윈도우는 연속적으로 배치되고 윈도우가 닫히면 새로운 윈도우가 열린다.
하나의 이벤트는 오직 하나의 윈도우에만 속한다.
예) 매 10초 동안 수집된 데이터의 평균값 계산, 매 5분마다 웹사이트 방문자 수 집계
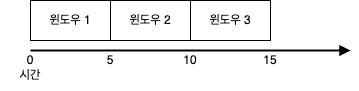
위 그림은 5분마다 이동하는 5분 길이의 윈도우의 예시이다.
호핑 윈도우는 일정한 시간 간격(슬라이드 간격)마다 열리는 고정 크기의 윈도우이지만, 서로 겹칠 수 있다.
윈도우 크기 > 슬라이드 간격 이면 중첩되어 데이터가 여러 윈도우에 포함될 수 있고, 윈도우 크기 == 슬라이드 간격 이면 텀블링 윈도우와 동일하다.
예) 매 1분마다 최근 5분간의 평균 온도 계산, 매 10초마다 지난 30초 동안 발생한 이벤트의 개수 집계
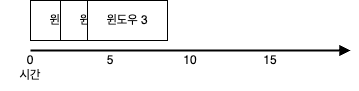
위 그림은 슬라이드 간격은 1분, 윈도우 크기는 5분인 윈도우의 예시이다.
윈도우끼리 서로 겹치므로 하나의 이벤트가 여러 개의 윈도우에 속할 수 있다.
텀블링 윈도우는 중복을 허용하지 않고 특정 시간 단위별로 데이터를 정확히 나누어야 할 때 사용한다.
예) 매 1분마다 주문 건수 집계
호핑 윈도우는 중복을 허용하고 데이터를 여러 윈도우에서 분석해야 할 때 사용한다.
예) 최근 5분 동안의 평균 계산을 매 1분마다 수행
2.6. 처리 보장: processing.guarantee
2.4.1. 카프카 스트림즈 사용:
processing.guarantee와 함께 보면 도움이 됩니다.
스트림 처리 애플리케이션은 장애가 발생했을 경우에도 각 레코드를 한 번만 처리할 수 있는 ‘정확히 한 번’ 의 보장을 필요로 한다.
Kafka - 멱등적 프로듀서, 트랜잭션 에서 본 것처럼 카프카는 트랜잭션적이고 멱등적 프로듀서 기능을 통해 ‘정확히 한 번’ 의미 구조를 지원하며, 카프카 스트림즈는 카프카의 트랜잭션 기능을 사용하여 스트림 처리 애플리케이션에 ‘정확히 한 번’ 보장을 지원한다.
카프카 스트림즈 라이브러리를 사용하는 모든 애플리케이션은 processing.guarantee 설정을 exactly_once_v2 로 설정함으로써 정확히 한 번 보장 기능을 활성화할 수 있다.
3. 스트림 처리 디자인 패턴
여기서는 스트림 처리 아키텍처의 공통된 요구 사항에 대해 잘 알려진 해법인 기본 패턴에 대해 알아본다.
3.1. 단일 이벤트 처리(map/filter 패턴)
단일 이벤트 처리는 가장 단순한 스트림 처리 패턴으로 각 이벤트를 개별적으로 처리한다.
불필요한 이벤트를 스트림에서 걸러내거나 각 이벤트를 변환하기 위해 사용되는 경우가 많기 때문에 맵/필터 패턴이라고도 한다.
(맵 이라는 단어는 맵/리듀스 패턴에서 유래함. 맵 단계에서는 이벤트를 변환하고, 리듀스 단계에서는 집계함)
단일 이벤트 처리 패턴에서 스트림 처리 애플리케이션은 스트림의 이벤트를 읽어와서 각 이벤트를 수정한 뒤 수정된 이벤트를 다른 스트림에 쓴다.
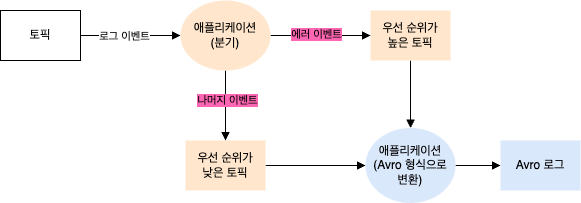
- 스트림으로부터 로그 메시지를 읽어와서 에러 이벤트는 우선 순위가 높은 스트림에, 나머지 이벤트는 우선 순위가 낮은 스트림에 쓰는 애플리케이션이 있음
- 스트림으로부터 JSON 이벤트를 읽어와서 수정한 뒤 Avro 형식으로 쓰는 애플리케이션이 있음
각 이벤트가 독립적으로 처리될 수 있기 때문에 애플리케이션 안에 상태를 유지할 필요가 없다.
상태를 복구할 필요도 없기 때문에 장애 복구나 부하 분산이 매우 쉽다.
위와 같은 패턴은 간단한 프로듀서와 컨슈머를 사용하여 쉽게 처리가 가능하다.
3.2. 로컬 상태와 스트림 처리
대부분의 스트림 처리 애플리케이션은 윈도우 집계와 같이 정보의 집계에 초점을 맞춘다.
이렇게 집계를 할 때는 스트림의 상태(state)를 유지할 필요가 있다.
예) 각 주식의 일별 최저가와 평균가를 계산하기 위해서는 최소값과 총합, 지금까지 본 레코드의 개수를 저장해놓아야 함
위의 예에서 각 작업은 그룹별 집계이므로 공유 상태(shared state) 가 아닌 로컬 상태(local state) 를 사용해서 수행할 수 있다.
즉, 전체 주식이 아닌 종목별로 분류해야 한다는 것이다.
먼저 카프카 파티셔너를 사용하여 동일한 주식에 대한 모든 이벤트가 동일한 파티션에 쓰여지게 할 수 있다.
이 후 각 애플리케이션 인스턴스는 자신에게 할당된 파티션에 저장된 모든 이벤트를 읽어온다. (카프카 컨슈머 단위에서 보장됨) 즉, 애플리케이션의 각 인스턴스는 자신에게 할당된 파티션에 쓰여진 전체 주식 종목의 부분 집합에 대한 상태를 유지할 수 있다는 것이다.
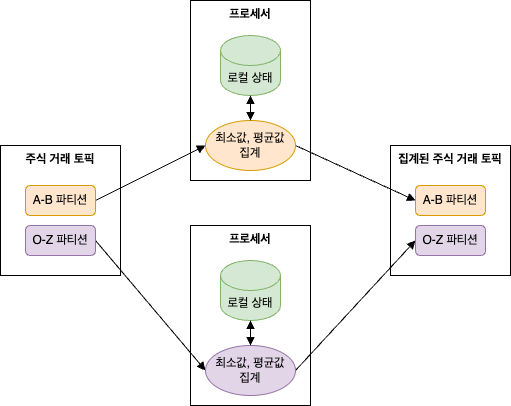
스트림 처리 애플리케이션은 로컬 상태를 보유하게 되는 순간 훨씬 더 복잡해진다.
<스트림 처리 애플리케이션이 고려해야 할 사항>
- 메모리 사용
- 로컬 상태는 애플리케이션 인스턴스가 사용 가능한 메모리 안에 들어갈 수 있는 것이 이상적임
- 영속성
- 애플리케이션 인스턴스가 종료되었을 때 상태가 유실되지 않고, 인스턴스가 재실행되거나 다른 인스턴스에 의해 대체되었을 때 복구될 수 있음을 확신할 있어야 함
- 카프카 스트림즈는 내장된 RocksDB 를 활용하여 로컬 상태를 인메모리 방식으로 저장함과 동시에 재시작 시 빠르게 복구 가능하도록 디스크에 데이터를 영속적으로 저장함
- 또한, 상태 변경 사항을 체인지로그 토픽에 기롬함으로써 장애 발생 시에도 데이터를 복구할 수 있도록 설계됨
- 리밸런싱
- 파티션은 가끔 서로 다른 컨슈머에게 다시 할당될 수 있음
- 재할당이 발생하면 파티션을 상실한 애플리케이션 인스턴스는 마지막 상태를 저장함으로써 해당 파티션을 할당받은 인스턴스가 재할당 이전 상태를 복구시킬 수 있도록 해야 함
만일 애플리케이션이 로컬 상태를 유지해야 한다면, 사용 중인 프레임워크가 로컬 상태 관리 기능의 수준을 어디까지 지원하는지 확실히 확인할 필요가 있다.
3.3. 다단계 처리/리파티셔닝
그룹별 집계가 필요한 경우엔 로컬 상태를 이용하면 좋다.
하지만 사용 가능한 모든 정보를 사용해서 내야 하는 결과가 있는 경우엔 로컬 상태만으로는 충분하지 않다.
예) 매일 가장 많이 오른 주식 10개를 계산해야 하는 경우
상위 10개 주식 전체는 서로 다른 인스턴스에 할당된 파티션에 분산되어 있기 때문에 각 애플리케이션 인스턴스에서 따로 작업하는 것만으로는 충분하지 않다.
이런 경우 2단계로 접근하면 된다.
- 각 주식별로 하루 동안의 상승/하락 산출
- 이 작업은 각 애플리케이션 인스턴스에서 로컬 상태만을 가지고도 할 수 있음
- 하나의 파티션만 가진 새로운 토픽에 결과를 씀(상승/하락 토픽)
- 이 파티션을 하나의 애플리케이션 인스턴스에서 읽어서 매일 상위 10개 주식을 찾음
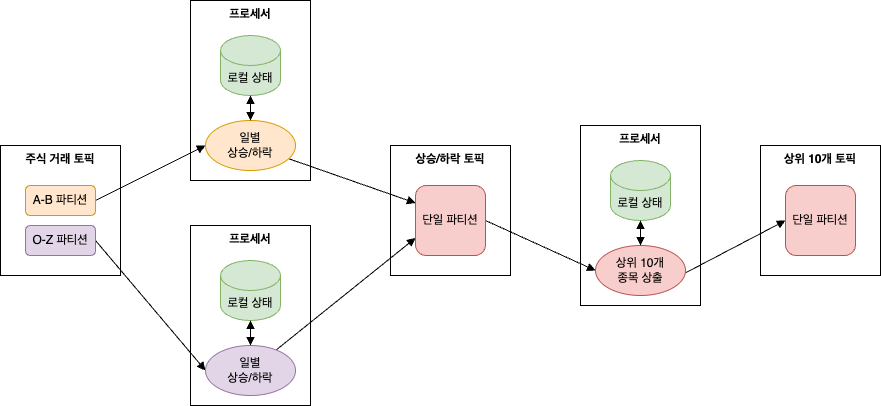
위의 경우 각 주식의 일별 등락만을 포함하는 두 번째 토픽인 상승/하락 토픽은 전체 거래 내역을 포함하는 토픽에 비해 크기와 트래픽이 훨씬 작기 때문에 단일 인스턴스만 가지는 애플리케이션만으로도 충분히 처리할 수 있다.
3.4. 외부 검색을 사용하는 처리: 스트림-테이블 조인(CDC 사용)
스트림 처리를 할 때 외부 데이터를 스트림과 조인해야 하는 경우가 있다.
예) 거래 내역을 DB 에 저장된 규칙을 사용해서 검증, 유저 클릭 내역을 사용자 정보와 합쳐서 확장
만일 클릭 이벤트가 발생해서 스트림으로 들어올 때마다 프로필 DB 에서 사용자를 조회한 후 원래의 클릭 이벤트에 정보를 추가하여 새로운 이벤트를 다른 토픽에 쓰게 된다면 외부 검색이 각 레코드를 처리하는데 있어서 상당한 지연을 발생시킨다.
스트림 처리 시스템은 보통 초당 10~50만개의 이벤트를 처리할 수 있는 반면, DB 는 초당 1만개 가량의 이벤트를 처리하는 것이 보통이다.
이 문제를 해결하기 위해서는 스트림 처리 애플리케이션 안에 DB 에 저장된 데이터를 캐시할 필요가 있다.
문제는 어떻게 하면 캐시의 정보가 만료되지 않도록(혹은 최신으로 유지) 하는가? 이다.
만일 DB 에 가해지는 변경 이벤트를 너무 자주 가져오게 되면 여전히 DB 를 건드리는 꼴이 되므로 캐시는 무용지물이 된다.
그렇다고 새로운 이벤트를 가져오는 시간 간격이 너무 길면 이미 만료된 정보를 가지고 스트림 처리를 하게 된다.
이 때 DB 테이블에 가해지는 모든 변경점을 이벤트 스트림에 담을 수 있다면 스트림 처리 작업이 이 이벤트 스트림을 받아와서 캐시를 업데이트하는데 사용하도록 할 수 있다.
DB 의 변경 내역을 이벤트 스트림으로 받아오는 것을 CDC(Change Data Capture) 라고 하며, 카프카 커넥트는 CDC 를 수행하여 DB 테이블을 변경 이벤트 스트림으로 변환할 수 있는 커넥터가 여럿 있다.
CDC 에 대한 좀 더 상세한 내용은 1.3.2.1. CDC(Change Data Capture, 변경 데이터 캡처) 와 디비지움 프로젝트 를 참고하세요.
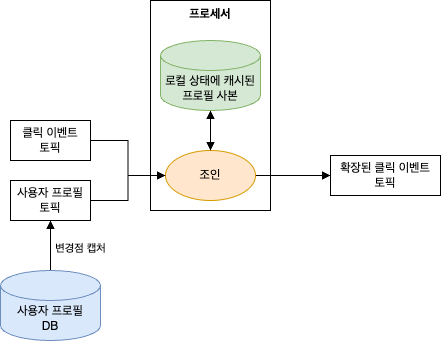
위 그림을 보면 스트림 처리에 있어서 외부 데이터 저장소의 필요성을 제거하였다.
클릭 이벤트를 받을 때마다 로컬 상태에서 사용자 프로필을 조회한 후 이벤트를 확장할 수 있다.
또한 로컬 상태를 사용하고 있기 때문에 확장이 용이하다.
스트림 중 하나가 로컬에 캐시된 테이블에 대한 변경 사항을 나타내기 때문에 이것을 스트림-테이블 조인이라고 한다.
3.5. 테이블-테이블 조인
위에서 테이블과 변경 이벤트 스트림이 어떻게 동등한지에 대해 알아보았고, 스트림과 테이블을 조인할 때 이것이 어떻게 동작하는지에 대해 알아보았다.
그렇다면 조인 연산의 양쪽에 이와 같은 방식으로 구체화된 테이블을 사용하지 못할 이유는 하나도 없다.
두 개의 테이블을 조인하는 것은 언제나 윈도우 처리되지 않는 연산(테이블이므로 과거 데이터에 대한 시간 조건이 없음)이며, 작업이 실행되는 시점에서의 양 테이블의 현재 상테를 조인한다.
<윈도우 처리가 없는 이유>
- 카프카 스트림즈에서 조인을 할 때 각 테이블은
KTable로 표현되며, 조인은 해당 시점의 최신 상태값을 기준으로 이루어짐 KTable은 스트림의 상태로, 각 키에 대한 최신 값을 유지하고 관리함- 따라서 조인 연산이 발생할 때 양쪽 테이블의 현재 상태(=최신값)을 기준으로 조인이 수행됨
- 새로운 레코드가 들어오면 해당 키의 값이 업데이트됨
- 조인된 테이블도 자동으로 업데이트되며, 변경 사항만 반영됨
- 과거 데이터에 대한 시간 조건이 없기 때문에 윈도우 개념이 적용되지 않음
윈도우 기반 조인은 KStream-to-KStream 조인에서 사용됨
카프카 스트림에서는 동일한 방식으로 파티션된 동일한 키를 가지는 2개의 테이블에 대해 동등 조인(equi-join)울 수행할 수 있으며, 이렇게 함으로써 조인 연산이 많은 수의 애플리케이션 인스턴스와 장비에 효율적으로 분산(= 분산 환경에서 효율적으로 동작함)될 수 있다.
<동일한 파티션 방식과 동일한 키가 중요한 이유>
- 카프카는 데이터를 파티션 단위로 분산 저장하고 처리함
- 조인을 수행할 때 동일한 키가 동일한 파티션에 존재해야 별도의 데이터 이동(shuffling) 없이 조인을 수행할 수 있음
- 따라서 두 테이블이 동일한 키로 파티셔닝되어 있으면 네트워크 오버헤드없이 조인 연산이 이루어짐
<분산 환경에서의 동작 방식>
- 파티션 레벨에서 조인
- 동일한 키를 가진 두 레코드는 동일한 파티션에 저장되므로 조인 연산이 해당 파티션에서만 수행됨
- 결과적으로 네트워크 I/O 비용 절감
- 효율적인 확장성
- 여러 개의 애플리케이션 인스턴스(컨슈머)들이 병렬로 작업 처리 가능
- 결과적으로 작업 부하가 고르게 분산되며, 확장성이 향상됨
- 장비 리소스 최적화
- 특정 파티션에서만 연산이 발생하므로 CPU, 메모리 등의 리소스를 더 효율적으로 사용할 수 있음
3.6. 스트리밍 조인(윈도우 조인)
스트림과 테이블이 아닌, 두 개의 실제 이벤트 스트림을 조인해야 하는 경우도 있다.
스트림은 무한이라는 특징을 가진다.
테이블에서는 현재 상태만 관심사이기 때문에, 스트림을 사용해서 테이블을 나타낼 경우 스트림에 포함된 대부분의 과거 이벤트를 무시할 수 있었지만, 두 개의 스트림을 조인할 경우 한 쪽 스트림에 포함된 이벤트를 같은 키 값과 함께 같은 시간 윈도우에 발생한 다른 쪽 스트림 이벤트와 맞춰야 하기 때문에 과거와 현재의 이벤트 전체를 조인해야 한다.
이런 부분 때문에 스트리밍 조인을 윈도우 조인이라고도 한다.
3.7. 비순차 이벤트(out-of-sequence)
잘못된 시간에 스트림에 도착한 이벤트인 비순차 이벤트는 상당히 자주 발생할 수 있다.
스트림 애플리케이션은 이런 상황을 처리할 수 있어야 하며, 이는 곧 애플리케이션이 아래와 같은 일들을 해야한다는 것을 의미한다.
- 이벤트 순서가 벗어났음을 알아차릴 수 있어야 함
- 그러기 위해선 애플리케이션이 이벤트 시간을 확인해서 현재 시각보다 더 이전인지를 확인할 수 있어야 함
- 비순차 이벤트의 순서를 복구할 수 있는 시간 영역을 정해야 함
- 예를 들어 3시간 정도면 복구 가능, 3시간 이후면 포기
- 순서를 복구하기 위해 이벤트를 묶을 수 있어야 함
- 이것은 스트리밍 애플리케이션과 배치 작업의 주요한 차이점이기도 함
- 배치 작업은 작업이 끝난 후 이벤트가 추가로 도착하면 보통 이전의 작업을 다시 돌려서 이벤트를 변경해 줌
- 하지만 스트림 처리는 계속해서 돌아가는 동일한 프로세스가 주어진 시점 기준으로 오래된 이벤트와 새로운 이벤트를 모두 처리해야 함
- 결과를 변경할 수 있어야 함
- 스트림 처리 결과가 DB 에 쓰여진다면 결과 변경 시 put or update 정도면 충분함
- 하지만 만일 스트림 처리 결과를 이메일로 전송할 경우 변경이 곤란함
구글의 Dataflow 나 카프카 스트림과 같은 스트림 처리 프레임워크는 처리 시간과 독립적인 이벤트 시간의 개념을 자체적으로 지원하며, 현재 처리 시간 이전이나 이후의 이벤트 시간을 가지는 이벤트를 다룰 수 있는 기능도 지원한다.
이것은 보통 로컬 상태에 다수의 집계 윈도우를 변경 가능한 형태로 유지해준다.
카프카 스트림즈 API 는 언제나 집계 결과를 결과 토픽에 쓰며, 이 토픽들은 보통 로그 압착이 설정되어 있는 토픽이다.
즉, 각 키값에 대해 마지막 밸류값만 유지된다.
집계 윈도우의 결과가 늦게 도착한 이벤트로 인해 변경되어야 하는 경우, 카프카 스트림즈는 단순히 해당 집계 윈도우에 새로운 결과값을 씀으로써 기존 결과값을 대체한다.
3.8. 재처리
이벤트를 재처리하는 패턴도 중요한데, 여기엔 2가지 변형이 있다.
- 새로 개선된 버전의 스트림 처리 애플리케이션
- 구버전에서 사용하던 이벤트 스트림을 신버전의 애플리케이션이 읽어와서 산출된 새로운 결과 스트림을 씀
- 단, 기존 구버전의 결과를 교체하는 것이 아니라 한동안은 두 버전의 결과를 비교한 뒤 어느 시점에 구버전 대신 신버전의 결과를 사용하도록 함
- 기존의 스트림 처리 애플리케이션의 버그를 수정하여 이벤트 스트림을 재처리한 후 결과 재산출
첫 번째 경우는 카프카가 확장 가능한 데이터 저장소에 이벤트 스트림을 오랫동안 온전히 저장하기 때문에 간단하게 해결된다.
이는 하난의 스트림 처리 애플리케이션의 두 가지 버전이 동시에 두 개의 결과 스트림을 쓰기 위해 아래만 지키면 된다는 의미이다.
- 신버전 애플리케이션을 새 컨슈머 그룹으로 실행시킴
- 신버전 애플리케이션이 입력 토픽의 첫 번째 오프셋부터 처리를 시작하도록 설정하여 입력 스트림의 모든 이벤트에 대해 복사본을 가질 수 있게 함
- 신버전 애플리케이션이 처리를 계속하도록 하고, 신버전 처리 작업이 따라잡았을 때 클라이언트 애플리케이션을 새로운 결과 스트림으로 전환함
두 번째 경우는 이미 존재하는 애플리케이션을 초기화해서 입력 스트림의 맨 처음ㅂ터 재처리하도록 되돌리고, 로컬 상태를 초기화하고, 기존 출력 스트림 결과를 지워야 한다.
같은 애플리케이션을 2개 돌려서 결과 스트림도 2개가 나올 정도로 용량이 충분하다면 첫 번째 방식을 권장한다.
2개 이상의 버전 결과물을 비교할 수 있고, 결리 과정에서 중요한 데이터가 유실될 위험이 없기 때문이다.
3.9. 인터랙티브 쿼리(interactive query)
스트림 처리 애플리케이션은 상태를 보유하며, 이 상태는 애플리케이션의 여러 인스턴스 사이에 분산될 수 있다.
스트림 처리 애플리케이션의 사용자는 겨로가 토픽을 읽어들임으로써 처리 결과를 받아보는데 상태 저장소 그 자체에서 바로 결과를 읽어올 필요가 없는 경우가 있다.
예) 가장 많이 팔린 책 10개 (처리 결과가 테이블 형태인 경우)
이 경우 결과 스트림이 곧 이 테이블에 대한 업데이트 스트림이기 때문에 스트림 처리 애플리케이션의 상태에서 테이블을 바로 읽어오는 것이 훨씬 빠르다.
스트림 처리 애플리케이션의 상태를 쿼리하기 위한 API 는 Kafka Streams Interactive Queries for Confluent Platform 를 참고하세요.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 김병부 저자의 O’REILLY 카프카 핵심 가이드 2판를 기반으로 스터디하며 정리한 내용들입니다.
