Architecture - 아키텍처의 유연성을 높이는 핵심 설계 원칙과 품질 속성
in DEV on Architecture, DDD, Clean Architecture, Software-architecture, Port-and-adapter, Hexagonal-architecture, Clean-architecture, Union-architecture
소프트웨어는 초기 설계부터 배포 이후까지 수많은 변화와 결정을 겪는다.
이러한 생애주기의 모든 국면에서 아키텍처가 유연하게 대응할 수 있으려면, 단지 코드 수준이 아니라 아키텍처의 스타일과 결정이 어떤 방식으로 설계되었는지가 중요하다.
이 포스트에서는 아래와 같은 핵심 질문에 답하며, 아키텍처의 유연성을 높이는 전략에 대해 알아본다.
- 어떤 아키텍처 스타일이 일반적으로 사용되고, 어떤 상황에서 특수하게 사용되는가?
- 포트와 어댑터(헥사고날) 아키텍처는 왜 유연성을 높이는 데 효과적인가?
- 시스템을 모놀리스, 마이크로서비스, 또는 하이브리드로 나눌 때 고려해야 할 점은?
- REST 스타일은 왜 여전히 중요한가?
- 보안, 성능, 내결함성 등 비기능 품질 속성은 어떻게 고려되어야 하는가?
- 다양한 아키텍처 스타일과 결정의 이해
- 모든 아키텍처는 특정 상황에서 더 적합한 방식이 있으며, 일반적 사용과 특수한 컨텍스트 사용의 차이를 이해한다.
- 포트와 어댑터 아키텍처의 유연성
- 아키텍처 결정을 초기에 할 수도, 늦춰서 할 수도 있는 구조를 제공한다.
- 실행 환경이나 의존성 변경에 강하다.
- 모듈화를 통한 컨텍스트 분할
- 모놀리스, 마이크로서비스, 하이브리드 아키텍처에 모두 유용하다.
- 시스템이 성장하면 분할 가능한 구조를 갖추는 것이 중요하다.
- REST 스타일의 지속적인 중요성
- 단순히 웹 통신 방식이 아닌, 리소스 중심 모델링을 통해 시스템 전체의 이해 가능성을 높인다.
- 아키텍처 품질 속성의 고려
- 사용자 기능 외에도 아키텍처는 아래와 같은 품질 속성을 만족시켜야 한다.
- 보안, 개인 정보 보호, 성능, 확장성, 내결함성, 복잡성 제어
- 이러한 속성이 없으면 아키텍처 설계는 단순한 구현의 나열에 불과하다.
- 사용자 기능 외에도 아키텍처는 아래와 같은 품질 속성을 만족시켜야 한다.
아키텍처 결정은 비즈니스 동인을 반영해야 한다.
유연한 아키텍처는 단순히 기술적으로 잘 만든 구조를 의미하지 않는다.
비즈니스가 진짜로 원하는 것(동인)을 파악하고, 그에 따라 구조적 결정을 내려야 비로소 의미있는 아키텍처가 된다.
이는 특히 이벤트 우선 시스템(event-first system) 같은 패턴을 적용할 때 더욱 중요하게 적용된다.
동인(Driver)
어떤 행동이나 결정을 유도하거나 추진하는 주요한 이유 또는 동기
비즈니스 동인(Business Driver)
조직이 IT 시스템 또는 소프트웨어 아키텍처를 도입하거나 변경하는 근본적인 비즈니스 목적이나 요구사항
<비즈니스 동인의 사례>
| 비즈니스 동인 | 설명 |
|---|---|
| 비용 절감 | 인건비 또는 인프라 비용을 줄이기 위해 자동화 시스템이 필요하다. |
| 고객 만족도 향상 | 더 빠른 응답 시간과 안정적인 서비스 제공이 필요하다. |
| 시장 출시 속도 개선(Time to Market) | 경쟁사보다 빨리 제품을 출시해야 한다. |
목차
1. 아키텍처 스타일, 패턴, 결정 동인
1.1. 포트와 어댑터(헥사고날)
Clean Architecture 를 참고하세요.
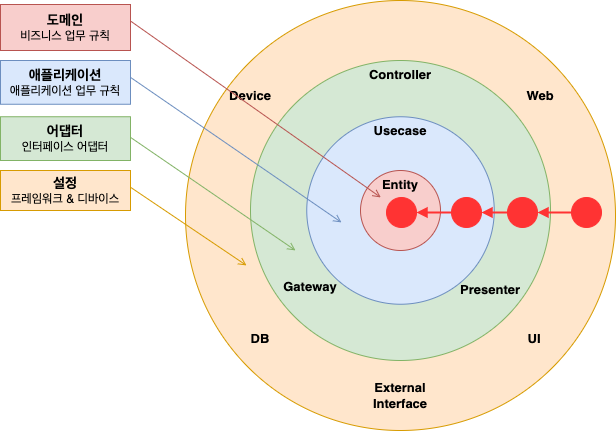
- 중심은 Entity 로, 비즈니스 규칙을 담당
- 바깥으로 갈수록 프레임워크, 디바이스, UI 등 외부 요소
- 외부로 갈수록 변경 가능성이 크며, 내부는 최대한 안정적으로 유지
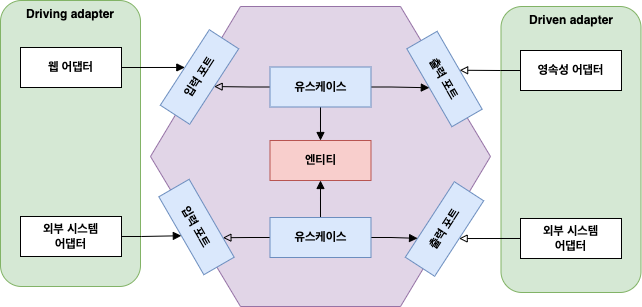
- 내부의 유스케이스와 엔티티는 외부와 분리되어 있음
- 입출력 포트와 어댑터가 외부와 내부를 연결
- Driving Adapter: UI, Web 등 외부로부터 요청을 수신
- Driven Adapter: DB, 외부 시스템 등 외부로 요청을 전송
소프트웨어는 웹, 모바일, 외부 서비스 등 다양한 I/O 메커니즘과 연결되어야 하며, 이러한 외부 요소들이 비즈니스 로직을 침범하지 않도록 보호하는 것이 포트와 어댑터 아키텍처의 핵심 목표이다.
<포트와 어댑터 주요 장점>
- 계층 분리로 테스트 용이성 확보
- 애플리케이션과 어댑터를 각각 독립적으로 테스트 가능
- 기술 종속성 제거
- mongoDB, MySQL 등 다양한 저장소나 프레임워크를 유연하게 교체 가능
- 유연한 확장성
- 새로운 외부 어댑터를 도입해도 내부 유스케이스는 영향 없음
- 의존성 역전 원칙 적용(DIP)
- 어댑터가 내부 로직에 의존하고, 반대는 불가
- 단일 책임 원칙 적용(SRP)
- 각 어댑터는 자신이 맡은 외부 I/O 에만 집중
<잠재적인 단점>
- 계층 증가에 따른 복잡성
- 구조가 늘어나면 구현과 유지보수 비용도 상승
- 선택한 메커니즘과 관련된 어댑터로 인해 복잡성이 증가할 수는 있지만, 이는 아키텍처 스타일과는 무관함 이러한 시스템은 다른 아키텍처를 사용해도 동일한 복잡성을 가짐
- 네크워크 오류 전파 위험성
- 외부 서비스 통합을 취한 인터페이스 구현체가 예외를 내부로 전파할 수 있음
- 해결 방법: 명령형 셸 + 함수형 코어
- 셸은 외부 통합 작업만 수행 (예: HTTP 호출)
- 함수형 코어는 순수 함수로 구성하여 예외 발생 방지
모든 어댑터 타입에 대해 별도의 포트 타입이 필요하지 않고, 여러 개의 외부 드라이버 타입 어댑터가 애플리케이션 포트를 효과적으로 재사용해서 작업을 수행할 수 있다.
포트와 어댑터는 다양한 애플리케이션 유형을 지원하는데 그 중 4가지 옵션에 대해 알아본다.
1.1.1. 트랜잭션 스크립트를 갖는 서비스 계층
DDD(1) - 트랜잭션 스크립트 패턴, 액티브 레코드 패턴 을 참고하세요.
1.1.2. 도메인 모델을 사용하는 서비스 계층
DDD(1) - 도메인 모델 패턴 을 참고하세요.
1.1.3. 액터 모델(Actor Model)
1.1.4. 명령형 셸과 함수형 코어 패턴(Imperative shell with functional core)
포트와 어댑터 아키텍처는 비즈니스 로직을 기술 세부사항으로부터 분리하기 위한 대표적인 구조이다.
하지만 이런 아키텍처에서 도메인 모델의 테스트 용이성, 부수 효과 분리, 예측 가능성을 더 강화하고 싶다면, 명령형 셸과 함수형 코어 패턴을 고려해볼 수 있다.
이 접근 방식은 함수형 프로그래밍의 이점을 실무 아키텍처에 자연스럽게 녹이는 방법으로, 복잡한 도메인 로직을 보다 안정적이고 예측 가능한 코드로 만들 수 있게 도와준다.
<함수형 코어>
- 비즈니스 로직이 담긴 부분(도메인 로직)
- 순수 함수로만 구성
- 외부 환경, I/O, 상태 변경과 무관
- 입력이 같으면 출력도 항상 같음 → 예측 가능
- 테스트가 쉬움 (mock/stub 없이도 가능)
함수형 코어 예시
fun calculateFee(user: User, itemCount: Int): Int {
return if (user.isVip) itemCount * 900 else itemCount * 1000
}
<명령형 셸>
- I/O, 네트워크 호출, DB 접근 등 부수 효과를 포함하는 외부 코드
- 사용자 입력 수신, 결과 출력, 로그 작성 등
- 함수형 코어를 호출하고, 결과를 전달하거나 외부에 반영
명령형 셸 예시
fun handleOrderRequest(req: HttpRequest) {
val user = userRepository.findById(req.userId)
val fee = calculateFee(user, req.itemCount) // 함수형 코어 호출
paymentGateway.charge(user, fee) // 명령형 셸에서 부수 효과 실행
}
<명령형 셸과 함수형 코어 패턴 장점>
- 테스트 용이성 극대화
- 순수 함수는 의존성 없이도 테스트 가능
- mock, stub, spy 없이도 단위 테스트 작성 가능
- 테스트에 대한 고급 지식이 없어도 테스트 작성이 쉬움
- 부수 효과 명확히 분리
- 비즈니스 로직(코어)는 외부 시스템에 영향을 주지 않음
- 오류나 네트워크 이슈가 로직 흐름에 혼동을 주지 않음
- 도메인 로직의 안정성과 예측 가능성이 향상됨
- 아키텍처 정합성 강화
- 포트와 어댑터 아키텍처에서 “어댑터”를 명령형 셸로, “포트” 안쪽을 함수형 코어로 볼 수 있음
- 도메인 서비스에서 외부 의존을 직접 호출하지 않으므로, 기술 세부사항 누수 방지
<명령형 셸과 함수형 코어 패턴이 유용한 상황>
- 테스트가 어려운 비즈니스 로직
- 순수 함수로 분리하면 테스트가 쉬움
- 외부 시스템 연동이 많은 구조
- 부수 효과를 명령형 셸로 제한
- 유지보수가 필요한 도메인 중심 아키텍처
- 기술과 환경에 독립된 도메인 코드 유지
1.1.5. 포트와 아키텍처 4가지 옵션 비교
| 트랜잭션 스크립트를 가진 서비스 계층 | 도메인 모델을 가진 서비스 계층 | 액터들의 도메인 모델 | 명령형 셸과 함수형 코어 | |
|---|---|---|---|---|
| 도메인 모델 격리 | 아니오. 데이터 업데이트에 집중함 | 예 | 예 | 예 |
| 비즈니스 복잡성 | 낮음 비즈니스 규칙이 많지 않거나 전혀 없으며 주로 데이터 중심 | 높음 | 높음 | 높음 |
| 인프라로부터 도메인 모델 격리 | 낮은 기술 오버헤드 그러나 도메인 모델이 없어서 주로 데이터 접근을 캡슐화함 인프라 관심사에 매우 가깝기 때문에 장기적인 유지 보수 측면에서 위험성을 갖고 있음 | 도메인 모델은 인프라와 잘 격리되지만 인프라 관심사에서 완전한 격리를 유지하려면 지속적인 노력이 필요함 조정을 위해 애플리케이션 서비스가 필요할 수 있음 | 도메인 모델은 인프라 관심사와 매우 잘 격리됨 격리 기능은 기본 액터 모델 구현에 내장되어 있어 인프라 문제없이 도메인 모델을 유지 보수하는데 도움이 됨 | 도메인 모델은 순수 함수를 기반으로 하기 때문에 인프라 관심사와 매우 잘 분리되어 있음 |
| 진화 가능성 | 낮음 도메인 모델이 없기 때문에 더 복잡한 비즈니스 시나리오로 발전하기 어려움 | 충간에서 높음 도메인 모델을 다른 인프라 관심사로부터 격리하는 방법에 따라 다름 | 매우 높음 비즈니스 동작을 추가하는 것이 매우 간단함 | 매우 높음 비즈니스 동작을 추가하는 것이 매우 간단함 |
| 확장성, 성능 및 동시성 | 매우 낮음 | 낮음에서 높음 확장성 및 동시성 요구 사항을 충족하기 위해 도메인 모델 주변에 기술적인 코드를 구현해야 할 수 있음 도메인 모델 자체는 동시성을 고려하지 않았기 때문에 주변 코드가 이를 처리해야 함 | 매우 높음 액터 모델 구현이 확장성, 성능, 동시성을 보장함 | 높음 도메인 모델은 순수 함수를 기반으로 하므로 동시성이 보장됨 그러나 명령형 셸 코드는 확장성과 성능을 향상시키고자 약간의 노력이 필요할 수 있음 |
| 테스트 용이성 | 낮음 | 높음 도메인 모델은 잘 격리되어 있어 테스트하기 쉬움 | 높음 모든 측면이 테스트 가능 | 높음 도메인 모델은 매우 테스트하기 쉬움 그러나 명령형 셸은 통합 테스트가 아니면 쉽게 테스트하기 어려움 |
1.2. 모듈화: 유연한 아키텍처의 출발점
모듈화는 아키텍처 유연성의 핵심 전략이다.
많은 팀이 처음부터 마이크로서비스를 시도하지만, 실제로는 모놀리스를 적절히 모듈화하는 것이 더 현실적이고 효과적인 출발점이 될 수 있다.
모놀리스는 아래와 같은 이유로 초기 아키텍처로 적합하다.
- 배포 및 운영이 단순하여 빠른 개발 주기 가능
- 코드 전반에 걸친 변경이 트랜잭션처럼 일관되게 적용 가능
- 팀 규모가 작을 때 관리가 쉬움
하지만 단일 컨테이너에 여러 모듈이 함께 있다고 해서 바운디드 컨텍스트 간의 강한 결합이나 침투적 의존성이 허용되어서는 안된다.
컨테이너 하나에 여러 개의 바운디드 컨텍스트가 존재할 수 있다.
중요한 것은 물리적 분리가 아니라 논리적 분리이다. 각 모듈은 독립적으로 책임을 가지며, 서로 간 메시징으로 통신할 수도 있다.
모놀리스라도 아래와 같은 비동기 메시징 메커니즘을 사용할 수 있다.
- 모듈 간 이벤트 발행/구독
- 메시지 큐를 사용한 decoupling
- Observer/EventBus 패턴 등
이러한 구조는 아래와 같은 상황에 대비할 수 있게 해준다.
- 메시지 지연 발생
- 순서가 보장되지 않는 수신
- 중복 메시지 수신
이 메시징 설계를 잘 해두면 마이크로서비스로 전환 시 부담이 적다.
변화하는 모듈은 분리 대상이 된다.
모듈화된 모놀리스를 운영하다 보면 아래와 같은 현상이 관찰될 수 있다.
- 일부 모듈만 빠르게 변화하고
- 서로 다른 변화 방향을 가진다.
이럴 경우 해당 모듈은 마이크로서비스로 분리하기 좋은 후보가 된다.
컨테이너가 늘어나면 분산 시스템이 된다.
만일 3개의 컨텍스트가 독립된 컨테이너로 분리되면 이제 분산 시스템의 문제가 등장한다.
- 네트워크 지연
- 순차성 미보장
- 메시지 중복 처리
- 서비스 간 호출 실패 처리
하지만 모놀리스를 잘 모듈화하고 메시징을 도입한 상태라면 이런 문제를 다룰 수 있는 준비가 된 셈이다.
1.3. REST 요청-응답
REST-API 를 참고하세요.
2. 품질 속성
2.1. 보안
애플리케이션에서 보안은 단순한 기능이 아니라, 시스템의 생존과 직결된 아키텍처의 핵심 목표이다.
보안은 사후가 아닌 사전 전략이다.
한 연구 결과에 따르면 데이터 침해의 주요 원인은 인프라보다 애플리케이션 계층의 보안 문제에 있다고 한다.
- 인증 우회
- 세션 탈취
- 부적절한 권한 처리
- 민감 정보 노출
이런 보안 취약점을 대부분 코드와 설계의 문제에서 발생한다.
인증과 인가는 필수로 구현해야 한다.
- 인증(Authentication)
- 사용자의 신원을 확인하는 과정
- 업계 표준: OpenID Connect + JWT
- 액세스 토큰을 활용하여 다양한 서비스 간 통합 인증 가능
- 인가(Authorization)
- 인증된 사용자가 특정 자원에 대해 어떤 행동을 할 수 있는지 확인하는 과정
<개발 초기부터 적용해야 할 보안 관행>
- 보안을 고려한 설계
- 보안을 사후적으로 추가하면 구조적으로 취약한 시스템이 됨
- 도메인 설계, 경계 정의, 데이터 흐름에서부터 보안 정책을 포함해야 함
- HTTPS 기본 사용
- TLS(Transport Layer Security) 를 통해 모든 통신을 암호화
- 인증서 갱신 자동화도 함께 고려
- 비밀 정보 암호화 및 보호
- 노출되면 심각한 API 키, 클라이언트 시크릿 등은 절대 평문 저장 금지
- KMS(클라우드 키 매니지먼트 서비스)나 Vault 사용 권장
- CI/CD 파이프라인 내 보안 검사 통합
- SAST(정적 애플리케이션 보안 테스트)도구를 사용하여 빌드 시 보안 취약점 사전 차단
- 예) GitHub Actions + CodeQL
SonarQube Security Plugin
- 직접 보안 로직을 작성하지 않기
- 자체 암호화/토큰 구현은 매우 위험
- 검증된 라이브러리 사용 필수
- 보안은 실전 테스트를 거친, 신뢰할 수 있는 외부 도구를 활용하는 것이 최선임
2.2. 개인 정보 보호
디스크 저장 비용은 점점 저렴해졌고, 기업은 가능한 많은 데이터를 저장하려는 경향이 있다.
하지만 특히 ‘개인 식별이 가능한 데이터(PII, Personally Identifiable Information)’ 를 다룰 경우, 이러한 전략은 심각한 법적 리스크와 신뢰 훼손으로 이어질 수 있다.
과잉 수집은 리스크다.
머신러닝/BI 분석 등을 위해 많은 데이터를 수집하지만, 그 중 일부는 향후 불필요하거나 폐기 대상일 가능성이 높다.
특히 개인을 식별할 수 있는 정보를 보안 공격의 주요 타킷이 된다.
<법적 프레임워크: GDPR>
유럽 연합(EU) 의 GDPR(General Data Protection Regulation)
- 적용 범위
- EU 거주자의 데이터를 다루는 모든 기업, 국경 외 기업도 포함
- 핵심 권리
- 개인 정보 삭제 권한
- 요구 사항
- 개인이 본인의 데이터를 제어할 수 있어야 함
미국, 한국, 일본 등 다른 국가들도 유사한 법안을 적용 중이다.
<개인 정보 보호를 위한 설계 전략>
- 최소한의 수집
- 가능한 비식별화된 데이터만 저장
- PII 필드 수가 적을수록 GDPR/CCPA 등 규정 준수의 부담이 감소함
// Bad: 불필요하게 많은 식별자 포함
{ "name": "홍길동", "email": "gil@example.com", "birth": "1990-01-01" }
// Better: 익명 ID 기반 처리
{ "userId": "uuid-abc-123", "category": "order" }
- 법무팀과의 협업
- 개발자 혼자 설계하지 말 것
- 법적 기준, 데이터 처리 목적, 보존 기간 등에 대해 법무팀과 사전 정의 필요
- 목적 기반 저장
- 수집 이유가 명확하지 않다면 그 데이터는 저장하지 않아야 함
- 목적을 분명히 정의해두면 삭제/익명화 기준도 함께 명확해짐
- 보존 및 삭제 정책 수립
- 무기한 저장은 이제 법적으로 위험한 관행
- 아래와 같은 정책이 사전에 마련되어야 함
- 보존 정책: 데이터 유형별 보관 기간 설정 (예: 계약 만료 후 1년)
- 삭제 방법: 사용자 요청 시, 관련된 모든 시스템에서 삭제 가능해야 함
- 파기 기준: 파기 대상 데이터를 식별 가능한 조건으로 자동 분류할 수 있어야 함
- 익명화 및 토큰화 전략
- 장기 보존이 필요한 경우 익명화 또는 토큰화 필요
- 고유 ID 와 같은 민감 정보는 물리적으로 분리된 스토리지에 저장
- 익명화 데이터는 다른 테이블과 조인 시에도 식별되지 않아야 함
userId → UUID(고유 ID) → Secure Vault → PII 데이터 (분리 저장)- 이 방식은 직접 식별자(이름, 이메일 등)을 시스템 전체에 노출하지 않기, 분실/침해 시 피해 범위 최소화, 법적 삭제 요청 발생 시 연관된 데이터를 손쉽게 식별 및 삭제 가능하게 함
userId- 애플리케이션 내에서 사용하는 논리적 사용자 식별자
- 예) DB 의 users 테이블 기본키 혹은 내부에서 생성된 appUser-12345 와 같은 값
- 직접적으로 이름이나 이메일 같은 정보를 포함하지 않음
UUID (토큰화된 ID)- userId 와 1:1 로 매핑되는 비식별화된 고유 ID
- 외부 API, 로그 등 사용자와 연관되지만 민감한 정보는 없어야 할 영역에 사용됨
- 예) c31c4ab0-2cd3-46d2-aeab-f42113382e77
- PII(개인정보)를 전혀 담지 않으므로 유출되어도 비교적 안전함
Secure Vault(보안 저장소)- 여기서 핵심은 UUID ↔ PII(실제 사용자 정보) 매핑을 저장하는 보안 강화 저장소임
- 예) AWS KMS, Google Cloud KMS, Azure Key Vault, 암호화된 별도 테이블 + 키 분리
- 이 영역은 암호화, 접근 제어, 감사 로그가 철저하게 관리되어야 함
PII 데이터- 이름, 이메일 등 직접 식별 가능한 데이터
- 이 정보는 Vault 안에만 존재하며, 일반 애플리케이션 로직에서는 UUID 를 통해 간접적으로만 접근됨
- 예시 흐름
[회원 가입 시]
- 클라이언트로부터 이름, 이메일 수신
- 내부 userId 생성 (ex. appUser-12345)
- UUID 생성 (ex. 12ac-44de-...)
- Secure Vault에: (UUID → {name, email}) 저장
- 애플리케이션에는 UUID만 보관
[마케팅 시스템 로그]
- 로그에 UUID만 남기고 PII는 포함하지 않음
[사용자 삭제 요청]
- userId → UUID 조회
- Vault에서 UUID로 연결된 PII 모두 삭제
- 설계 초기부터 반영
- 개인 정보 보호 기능은 “나중에 패치하는 것”이 아니라 처음부터 포함되어야 할 설계 요구 사항
<글로벌 시장 진출을 취한 필수 조건>
- EU 대상
- GDPR 완전 준수 필요
- 미국 대상
- CCPA 등 유사 정책 요구
- 한국/아시아
- 개인정보보호법, 위치정보법 등 다수 개별 법령 존재
- 공통점
- 삭제 요청 수용, 동의 기반 처리, 식별자 최소화
2.3. 성능: 지연 시간과 캐시 전략, 그리고 병렬성의 설계
시스템 성능을 논할 때 가장 중요한 핵심은 지연 시간(latency) 이다.
특히 분산 아키텍처와 MSA 환경에서는 단일 호출의 성능보다 서비스 간 호출의 누적 지연 시간이 문제가 된다.
네트워크 지연은 선형적으로 증가하지 않는다.
마이크로서비스 간 호출이 모두 직렬로 발생하는 것은 아니다.
비동기 메시징이 포함되면 요청 흐름을 병렬로 분기될 수 있다. 특히 게시-구독(fan-out) 구조에서는 하나의 메시지를 다수의 소비자에게 동시에 배포할 수 있다.
로컬 데이터 사본으로 네트워크 비용 최소화
다른 서비스의 데이터를 반복 조회하면 네트워크 호출이 누적되어 지연 시간이 커지는데 이 때 그 데이터를 로컬에 캐시하는 방법이 있다.
하지만 캐시는 아래와 같은 문제를 동반한다.
- 데이터 정합성
- 오래된 캐시가 여전히 사용될 수 있음
- 삭제/갱신 타이밍
- 변경 타이밍을 놓치면 일관성 문제 발생
- 캐시 무효화 전략
- TTL, 수동 갱신, 구독 기반 푸시 등
이러한 문제는 아래와 같은 방법으로 해결할 수 있다.
- 민감도가 낮은 데이터는 TTL 기반으로 캐시
- 중요한 데이터는 직접 조회하거나 변경 이벤트 기반으로 동기화
- 시간 및 수요에 민감한 데이터는 캐싱을 아예 하지 않음
성능과 확장성에는 트레이드오프가 존재한다.
- 높은 확장성 → 더 많은 서비스 간 호출 → 네트워크 지연 증가 가능
- 높은 성능을 위해 직접 연결/로컬화 → 확장성과 유연성 저하
결국 성능이 중요한 경로에만 최적화된 통로를 만들고, 나머지는 유연성고과 유지보수성을 우선시하는 것이 좋다.
2.4. 확장성: 리소스를 유연하게 쓰는 마이크로서비스의 이점
마이크로서스는 유연하고 비용 효율적인 확장 전략을 가능하게 한다.
특정 서비스에만 집중적으로 리소스를 할당할 수 있기 때문에 전체 리소스 소비를 최적화할 수 있다.
<마이크로서비스 확장 방식>
- 독립 확장
- 특정 서비스만 스케일 아웃 가능
- 리소스 집중
- 리소스가 많이 필요한 서비스에만 고사양 인스턴스 할당
- 부하 분산
- 각 서비스에 적합한 오토스케일 정책 설정 가능(CPU 등)
모놀리스는 하나의 애플리케이션 단위로 동작하므로 일부분만 부하가 높아도 전체 인스턴스가 확장되어야 한다.
이는 자원 낭비이자 비용 비효율로 이어진다.
하지만 모듈형 모놀리스를 서버리스 기반으로 배포하면 마이크로서비스 수준의 확장성을 확보할 수 있다.
예) AWS Lambda, Google Cloud Functions 등으로 모놀리스의 일부 기능만 이벤트 기반으로 분리 실행
이 부분에 대한 좀 더 상세한 내용은 7. 서버리스와 FaaS: 인프라 걱정없는 이벤트 기반 설계 를 참고하세요.
2.5. 복원성(Resilience): 신뢰성 및 내결함성
복원성은 하나의 실패가 시스템 전체로 전파되지 않도록 막는 항력이다.
복원성이 강한 아키텍처는 일부 장애 발생 시에도 전체 시스템이 안정적으로 동작한다.
마이크로서비스는 아래와 같은 특성을 통해 복구 가능성을 높일 수 있다.
- 각 서비스가 독립 프로세스로 실행됨
- 하나의 서비스 장애가 전체 시스템 중단으로 연결되지 않음
- 단, 적절한 설계 없이는 복원성을 보장하지 않음
이에 대한 내용은 1. MSA 로 전환 전 알아야 할 분산 장애와 회복 전략 을 참고하세요.
모놀리스의 경우 아래와 같은 한계가 있다.
- 하나의 JVM 또는 프로세스 안에서 모든 모듈이 동작함
- 특정 모듈에서 처리되지 않은 예외, 메모리 누수 등이 발생하면 전체 서비스 중단
- 예외 전파와 자원 공유가 광범위하게 영향을 미침
<마이크로서비스의 회복 전략>
- 리소스 관리자(Kubernetes 등)
- 장애 발생 시 비정상 컨테이너 자동 재기동
- Liveness/Readiness Probe로 상태 체크 후 빠른 실패 처리
- 서킷 브레이커(Circuit Breaker)
- 반복 실패 시 외부 호출을 차단하여 시스템 고갈 방지
- Retry + Backoff
- 일시적 장애에 대비해 재시도 및 점진적 지연(backoff) 전략 적용
- 카오스 엔지니어링
- 넷플릭스의 카오스 몽키처럼 의도적으로 실패를 발생시켜 내결함성 검증
- 대체 인스턴스가 즉시 투입되는가?
- 네트워크 호출이 우회되어 라우팅되는가?
- 전체 서비스 흐름이 유지되는가?
- 넷플릭스의 카오스 몽키처럼 의도적으로 실패를 발생시켜 내결함성 검증
2.6. 복잡성
아키텍처가 커질수록 복잡성은 자연스럽게 증가한다.
모놀리스의 복잡성
- 코드 전체가 한 프로젝트에 모여 있으므로 정적 분석이 쉬움
- Monorepo 구조에서 IDE, 검색 도구, 리팩토링 기능 사용이 수월
- 배포도 단순: 전체 앱을 한 번에 배포
하지만
- 코드 양이 많아질수록 의존성 얽힘과 모듈 경계 침범이 발생
- 변경 영향 범위가 넓음
마이크로서비스의 복잡성
- 서비스 단위로 분리되기 때문에 각 서비스의 기술 스택/언어/프레임워크가 다를 수 있음
- 공통된 로깅, 모니터링, 에러 추적, 버전 관리 전략이 필요함
- 여러 서비스가 동시에 배포되며, 서로 다른 배포 주기도 고려해야 함
- 운영 복잡성 증가
- 서로 다른 노드에 서비스 배치 및 오토스케일링 필요
- 배포 도구 및 오케스트레이션(Kubernetes 등) 에 대한 전문 지식 요구
- 장애 분석 시 여러 로그 소스 집계 필요 (ELK, Datadog 등)
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 반 버논, 토마스 야스쿨라 저자의 전략적 모놀리스와 마이크로서비스를 기반으로 스터디하며 정리한 내용들입니다.
