AI - 인공 신경망의 학습 원리: 오차, 경사 하강법, 오차 역전파법
in DEV on AI, Ml, Deep-learning, Neural-network, Loss-function, Error, Gradient-descent, Backpropagation, Differentiation, Weight
AI - 인공 신경망 신호 전달 원리: 가중치, 편향, 활성화 함수 에서 하나의 뉴런이 입력값을 받아 어떤 과정을 거쳐 출력값을 만들어내는지 알아보았다.
하지만 이 출력값이 항상 우리가 원하는 정답이라는 보장은 없다. 만약 모델이 틀린 값을 예측했다면, 인공지능을 학습시켜야 한다.
인공지능의 학습 과정은 생각보다 단순한 원리에서 출발한다.
먼저 특정 데이터를 모델에 입력하여 예측값(출력값)을 얻는다. 그리고 미리 준비된 실제 정답과 이 예측값을 비교한다. 이 둘의 차이가 바로 오차이며, 인공 신경망은 이 오차를 기반으로 스스로를 수정하고 개선해나간다.
결국 인공지능을 학습시킨다는 것은 ‘예측하고, 비교하고, 오차를 줄여나가는’ 과정을 끊임없이 반복하여 예측 성능을 정답에 가깝게 만들어 가는 여정이다.
여기서는 이 학습 과정의 핵심인 인공 신경망의 오차를 어떻게 구하고, 그 오차를 어떤 방식으로 줄여나가는지에 대해 알아본다.
목차
1. 인공 신경망의 오차 구하기
인공 신경망의 학습은 오차를 측정하는 것부터 시작한다. 모델이 내놓은 예측이 실제 정답이 얼마나 다른지를 정량적으로 측정해야 개선의 방향을 잡을 수 있기 때문이다.
이 오차를 계산하는 함수를 손실 함수(Loss Function) 또는 비용 함수(Cost Function)이라고 한다.
1.1. 남녀 구분: 이진 분류(Binary Classification)
‘예’ 또는 ‘아니오’처럼 두 개의 선택지 중 하나를 맞추는 문제를 이진 분류라고 한다.
모델이 모든 데이터에 대해 예측을 수행하면, 우리는 이 전체 예측이 얼마나 정답에서 벗어났는지 하나의 값으로 계산해야 한다. 이 때 주로 사용하는 손실 함수가 바로 이진 교차 엔트로피(Binary Cross-Entropy)이다.
이진 교차 엔트로피의 핵심 원리는 아래와 같다.
- 모델이 정답을 높은 확률로 예측했다면(잘 맞췄다면) 오차를 0에 가깝게 부여
- 모델이 오답을 높은 확률로 예측했다면(크게 틀렸다면) 오차를 매우 큰 값으로 부여
이 과정을 모든 데이터에 대해 반복하고 평균을 내어, 모델 전체의 오차를 계산한다.
모델의 성능이 좋을수록 이 전체 오차 값은 0에 수렴하게 된다.
1.2. 나이대 예측: 다중 분류(Multi-class Classification)
3개 이상의 선택지 중 하나를 맞추는 문제를 다중 분류라고 한다. 예를 들어 ‘20대 이하’, ‘30~40대’, ‘50대 이상’ 중 하나의 나이대를 예측하는 모델이 있다고 해보자.
모델은 각 항목에 대한 확률을 출력한다. 가령 어떤 데이터에 대해 ‘20대 이하일 확률 30%, 30~40대일 확률 60%, 50대 이상일 확률 10%’라고 예측했다고 해보자.
이 경우 모델은 가장 확률이 높은 ‘30~40대’를 최종 예측으로 선택한다.
그런데 실제 정답이 ‘20대 이하’라면 오차는 어떻게 계산될까? 이 때 사용하는 손실 함수가 범주형 교차 엔트로피(Categorical Cross-Entropy)이다.
- 정답 클래스(‘20대 이하’)에 대해서는 예측 확률(30%)이 낮을수록 오차를 크게 부여
- 오답 클래스(‘30~40대’, ‘50대 이상’)에 대해서는 예측 확률(60%, 10%)이 높을수록 오차를 크게 부여
즉, 정답일 확률은 낮게 예측하고, 오답일 확률은 높게 예측할수록 더 큰 오차를 주는 방식이다.
1.3. 나이 예측: 회귀(Regression)
분류 문제처럼 카테고리를 맞추는 것이 아니라, 연속된 실제 숫자 값을 예측하는 문제를 회귀라고 한다. ‘나이’를 20세, 41세처럼 정확한 숫자로 예측하는 경우가 여기 해당한다.
회귀 문제의 오차는 직관적으로 계산할 수 있다. 실제 정답 값과 예측 값 사이의 거리를 측정하면 된다. 이 때 가장 널리 쓰이는 방법이 평균 제곱 오차(MSE, Mean Squared Error)이다.
평균 제곱 오차의 계산 방식은 아래와 같다.
- 각 데이터에 대해 (실제 값 - 예측 값) 으로 오차를 구함
- 이 오차를 제곱함
- 모든 데이터의 제곱 오차를 구한 후, 데이터 개수로 나누어 평균을 구함
오차를 그냥 더하지 않고 제곱하는 이유는 두 가지가 있다.
- 음수 오차와 양수 오차가 서로 상쇄되는 것을 막아 순수한 오차의 크기를 측정
- 오차가 클수록 오차를 훨씬 더 크게 부과하여 모델이 큰 실수를 하지 않도록 유도
2. 인공 신경망의 핵심! 오차 줄이기
위에서 인공 신경망이 내놓은 예측값과 실제 정답 사이의 ‘오차’를 어떻게 측정하는지 알아보았다. 이제 계산된 오차를 바탕으로 모델을 개선하여 오차를 줄여나가는 방법에 대해 알아보자.
오차가 발생했다는 것은 현재 신경망의 상태가 최적이 아니라는 신호이다.
그렇다면 무엇을 바꾸어야 할까?
바로 각 뉴런(노드)를 잇는 연결선의 가중치(Weight)이다. 가중치는 뉴런 간에 전달되는 신호의 세기를 조절하는 역할을 한다. 이 가중치 값을 섬세하게 조정함으로써, 인공 신경망의 최종 출력값이 정답에 더 가까워지도록 만들 수 있다.
수많은 가중치를 어떤 방향으로, 또 얼마만큼 조정해야 오차를 효과적으로 줄일 수 있을까?
이 중요한 문제를 해결하기 위해 고안된 2가지 방법이 있다.
- 경사 하강법(Gradient Descent)
- 손실 함수의 ‘기울기’를 이용해 오차가 줄어드는 방향으로 가중치를 점진적으로 업데이트하는 방법
- 오차 역전파법(Backpropagation)
- 경사 하강법의 원리를 심층 신경망 전체에 효율적으로 적용하기 위해, 출력층에서부터 입력층 방향으로 오차를 역으로 전파하며 각 가중치를 연쇄적으로 업데이트하는 방법
2.1. 기울기로 가중치 값을 변경하는 경사 하강법(Gradient Descent)
가중치는 인공 신경망의 성능을 결정하는 핵심적인 요소이다. 이 가중치 값을 어떻게 최적의 값으로 조정할 수 있을까?
그 해답은 바로 경사 하강법에 있다.
특정 가중치 값의 변화에 따른 오차의 크기를 그래프로 그려보면, 일반적으로 아래로 볼록한 2차 함수와 유사한 형태가 나타난다.
우리의 목표는 이 그래프에서 가장 낮은 지점, 즉 오차가 최소가 되는 지점(a)을 찾는 것이다.
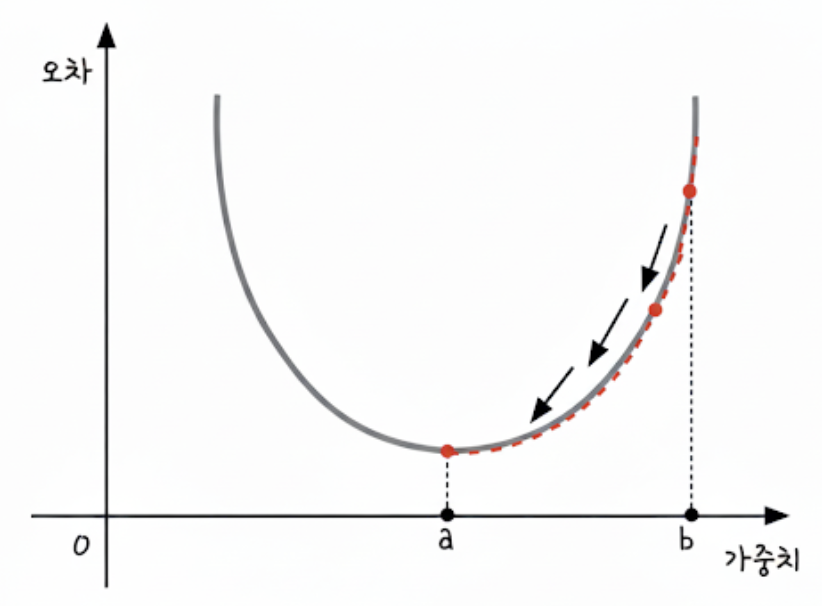
그래프 위의 임의의 지점 b에서 시작한다고 해보자. 목표 지점 a로 이동하려면 어느 방향으로 움직여야 할까?
이 때 활용하는 것이 바로 그 지점에서의 기울기(gradient)이다.
- 목표 지점(a)에서 멀리 떨어진 (b)와 같은 곳에서는 기울기가 매우 가파르다.
- 목표 지점(a)에서 가까워질수록 기울기는 점점 완만해진다.
- 목표 지점(a)에서의 기울기는 정확히 0이 된다.
따라서 우리는 현재 위치에서의 기울기를 계산하고, 그 기울기가 감소하는 방향으로 가중치 값을 조금씩 이동시키면 된다.
이처럼 기울기를 따라 산을 내려가듯 오차의 최솟값을 향해 점진적으로 나아가는 방법이 바로 경사 하강법이다.
2.1.1. 기울기와 미분
여기서 말하는 ‘한 지점에서의 기울기’는 수학적으로 미분(differentiation)을 통해 구할 수 있다.
미분은 특정 지점에서의 순간적인 변화율을 의미하며, 이는 그래프에서 한 점에 접하는 접선(tangent line)의 기울기와 같다.
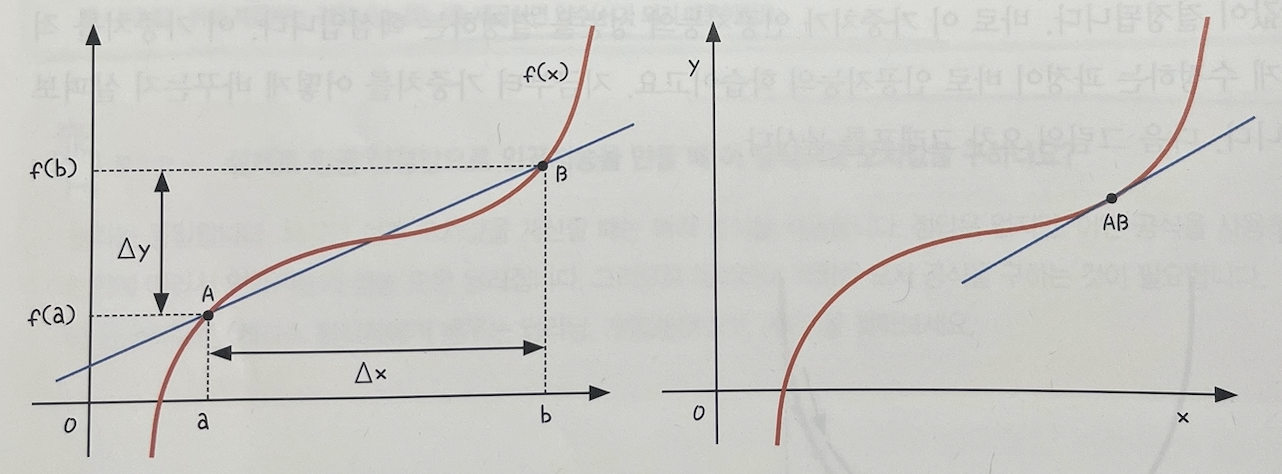
위 그래프는 미분(differentiation)의 기본 개념인 순간 변화율(기울기)를 설명하는 그림이다.
- Δx(Delta x): x값의 변화량(그래프에서는 b와 a의 차이, 즉 b-a)
- Δy(Delta y): y값의 변화량(그래프에서는 f(b)와 f(a)의 차이, 즉 f(b)-f(a))
따라서 Δy는 ‘y의 변화량’을 뜻한다.
두 그래프는 곡선 위의 ‘한 점’에서의 기울기를 어떻게 구하는지를 보여주고 있다.
왼쪽 그래프: 두 점 사이의 평균 기울기
- 그래프에는 f(x)라는 빨간색 곡선과 그 위의 두 점 A, B 가 있다.
- 이 두 점을 직선으로 이은 파란색 선을 할선(secant line)이라고 한다.
- 이 할선의 기울기는 ‘x값이 변하는 동안 y값이 얼마나 변했는가’를 나타내며, 이를 평균 변화율이라고 한다.
- 기울기는 아래와 같이 계산할 수 있다.
오른쪽 그래프: 한 점에서의 순간 기울기
- 왼쪽 그래프의 점 A를 점 B쪽으로 점점 더 가깝게 이동시킨다고 해보자. (Δx를 0에 가깝게 만드는 과정)
- 두 점이 거의 만나 하나의 점 AB가 되면, 두 점을 잇던 파란색 직선은 한 점에서 접하는 접선(tangent line)이 된다.
- 이 접선의 기울기가 바로 점 A에서의 순간적인 기울기이며, 이것이 미분 계수(derivative)의 의미이다.
요약하면 이 그래프는 두 점 사이의 평균 기울기(Δy/Δx)에서 출발하여, 두 점의 간격(Δx)를 극한으로 줄여 한 점에서의 순간 기울기(미분 계수)를 구하는 미분의 기본 원리를 보여준다.
경사 하강법에서 미분(기울기)가 중요한 이유는 아래와 같다.
- 방향 제시
- 기울기는 오차가 가장 가파르게 증가하는 방향을 알려준다. 우리는 그 반대 방향으로 가중치를 업데이트하여 오차를 줄일 수 있다.
- 보폭 조절
- 기울기의 크기는 현재 지점이 최적의 값에서 얼마나 멀리 떨어져 있는지를 가늠하게 해준다.
- 기울기가 크면(가파르면) 많이 이동하고, 작으면(완만하면) 적게 이동하여 정밀하게 최적점에 다가갈 수 있다.
결론적으로, 경사 하강법의 핵심은 미분을 통해 기울기를 구하고, 이 기울기를 이용해 오차가 줄어드는 방향으로 가중치를 반복적으로 업데이트하는 것이다.
2.2. 여러 가중치를 차례로 변경해 나가는 오차 역전파법(Backpropagation)
위에서는 가중치가 하나인 단순한 경우를 가정했다. 하지만 실제 인공 신경망, 특히 여러 개의 은닉층을 가진 딥러닝 모델에는 수십만 개에서 수억 개에 이르는 가중치가 존재한다.
이 모든 가중치를 어떻게 효율적으로 업데이트할 수 있을까?
이 때 사용되는 것이 바로 오차 역전파법이다.
이름에서 알 수 있듯이, 오차 역전파법은 뒤에서부터 앞으로 전파시키며 가중치를 수정하는 방식이다. 과정은 아래와 같다.
- 순전파(Forward Propagation)
- 입력 데이터로부터 출발하여 신경망의 각 층을 순서대로 거쳐 최종 출력값을 계산한다.
- 오차 계산
- 출력층에서 계산된 예측값과 실제 정답 사이의 오차를 손실 함수를 통해 계산한다.
- 역전파(Backward Propagation)
- 계산된 오차를 기반으로 경사 하강법을 적용하여 출력층의 가중치를 먼저 업데이트한다. 그리고 이 오차 정보를 이전 은닉층으로 거꾸로 전달한다.
- 반복 업데이트
- 이전 은닉층은 전달받은 오차 정보를 기반하여 자신의 가중치를 업데이트하고, 다시 그 이전층으로 오차 정보를 전달한다. 이 과정이 입력층에 도달할 때까지 반복된다.
이처럼 출력층에서 발생한 오차를 마치 연쇄 반응처럼 뒤에서부터 앞으로 하나씩 전달하며 모든 가중치를 효율적으로 업데이트하는 알고리즘이 바로 오차 역전파법이다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 이영호 저자의 모두의 인공지능 with 파이썬을 기반으로 스터디하며 정리한 내용들입니다.
