AI - 파이썬(1): 변수, 배열, NumPy
in DEV on Ai, Ml, Python, Numpy, Variable, Array, List, Slicing, Numpy-array, Numpy-random, Reshape, Seed
AI 와 머신러닝 프로젝트를 시작하기에 앞서, 가장 기본이 되는 도구인 파이썬의 핵심 문법을 익히는 것은 필수이다.
이 포스트에서는 데이터 처리의 기본 단위인 변수부터 시작하여, 데이터 집합을 다루는 배열(리스트), 그리고 과학 계산의 핵심 라이브러리인 NumPy 에 대해 알아본다.
목차
1. 변수
# 숫자 변수 선언 및 연산
a = 2
b = 10
c = a + b
print(c) # 결과: 12
# 문자 변수 선언 및 연산
first = '안녕'
second = '하세요'
hello = first + second
print(hello) # 결과: 안녕하세요
1.1. 변수 자료형(Data Type)
파이썬은 할당된 값에 따라 자동으로 자료형을 결정한다.
type() 함수를 사용하면 해당 변수가 어떤 자료형인지 확인할 수 있다.
a = 2
hello = '안녕하세요'
print(type(a)) # <class 'int'>
print(type(hello)) # <class 'str'>
a = 2.5
print(type(a)) # <class 'float'>
1.2. 강제로 변수형 변환(Type Casting)
때로는 특정 자료형을 다른 자료형으로 강제 변환해야할 필요가 있다. 예를 들어 문자열로 저장된 숫자를 실제 숫자처럼 연산하고 싶을 때 사용한다.
string2int = '10'
print(type(string2int)) # <class 'str'>
# int() 함수를 사용해 정수형으로 변환
converted_int = int(string2int)
print(type(converted_int)) # <class 'int'>
# float() 함수를 사용해 실수형으로 변환
converted_float = float(string2int)
print(type(converted_float)) # <class 'float'>
2. 배열(List)
mylist = [1, 2, 3]
print(mylist) # [1, 2, 3]
# 리스트의 길이 확인
print(len(mylist)) # 3
# 원소 접근 (Indexing)
# 인덱스는 0부터 시작합니다.
print(mylist[0]) # 첫 번째 원소: 1
# 음수 인덱스는 뒤에서부터 접근합니다.
print(mylist[-1]) # 마지막 원소: 3
2.1. 슬라이싱(Slicing)
슬라이싱은 리스트의 특정 범위를 잘라내어 새로운 리스트를 만드는 기능이다.
리스트[시작인덱스:끝인덱스] 형태로 사용하며, 끝 인덱스 바로 앞까지의 원소를 가져온다는 점을 기억해야 한다.
mylist2 = [1, 3, 5, 7, 9, 11, 13, 15]
# 인덱스 2부터 5까지 (6번째 원소 앞까지)
print(mylist2[2:6]) # [5, 7, 9, 11]
# 인덱스 2부터 끝까지
print(mylist2[2:]) # [5, 7, 9, 11, 13, 15]
# 처음부터 인덱스 4까지 (5번째 원소 앞까지)
print(mylist2[:5]) # [1, 3, 5, 7, 9]
# 처음부터 마지막 원소 앞까지
print(mylist2[:-1]) # [1, 3, 5, 7, 9, 11, 13]
3. 넘파이(NumPy, Numerical Python): AI를 위한 행렬 연산의 핵심
NumPy 는 다차원 배열 객체와 이를 처리하기 위한 효율적인 함수들을 제공하는 파이썬의 핵심 과학 계산 라이브러리이다.
특히 인공 신경망에서 대량의 데이터를 행렬 형태로 다룰 때 필수적이다.
3.1. 넘파이 배열 생성
import numpy as np 를 통해 라이브러리를 불러온 후, np.array() 함수를 사용하여 파이썬 리스트를 NumPy 배열로 변환할 수 있다.
.shape 속성으로 배열의 형태(차원과 크기)를 확인할 수 잇다.
import numpy as np
narray = np.array([1, 3, 5, 7, 9])
print(narray) # [1 3 5 7 9]
# 배열의 형태 조회 (원소가 5개인 1차원 배열)
print(narray.shape) # (5,)
3.2. 넘파이 2차원 배열 생성
2차원 배열은 행(row, 가로의 각 줄)와 열(column, 세로의 각 줄)으로 구성된 구조로, 행렬(Matrix)이라고도 한다.
인공지능 모델에서 데이터를 표현하는 가장 일반적인 형태이다.
아래와 같은 배열은 2x5 배열이라고 하고, 숫자 6은 2행 3열에 있다.
# 2행 5열의 2차원 배열 생성
darray = np.array([[1, 3, 5, 7, 9], [2, 4, 6, 8, 10]])
print(darray)
# [[ 1 3 5 7 9]
# [ 2 4 6 8 10]]
print(darray.shape) # (2, 5)
3.3. 넘파이 배열 형태 변경: reshape()
NumPy 의 가장 강력한 기능 중 하나는 reshape() 함수를 통해 배열의 형태를 자유자재로 변경할 수 있다는 점이다.
단, 변경 전후의 총원소 개수는 동일해야 한다.
# (2, 5) 형태의 배열을 (5, 2) 형태로 변경
d52 = darray.reshape(5, 2)
print(d52)
# [[ 1 3]
# [ 5 7]
# [ 9 2]
# [ 4 6]
# [ 8 10]]
# 2차원 배열을 1차원 배열로 변경
# (10,)은 원소가 10개인 1차원 배열을 의미합니다.
d10 = darray.reshape(10,)
print(d10) # [ 1 3 5 7 9 2 4 6 8 10]
1차원 배열로 형태를 나타낼 때는 (원소 수, 원소 수)가 아니라 (원소 수,)로 나타내기도 한다.
3.4. 넘파이 배열 생성 함수
NumPy 는 특정 값으로 채워진 배열을 쉽게 생성할 수 있는 다양한 함수를 제공한다.
np.zeros(): 모든 원소가 0인 배열 생성np.ones(): 모든 원소가 1인 배열 생성
0으로 된 넘파이 배열 생성: zeros()
# 모든 원소가 0인 (2, 5) 형태의 실수 배열 생성
zeros_float = np.zeros((2, 5))
print(zeros_float)
# [[0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0.]]
# dtype=int 옵션으로 정수 배열 생성
zeros_int = np.zeros((2, 5), dtype=int)
print(zeros_int)
# [[0 0 0 0 0]
# [0 0 0 0 0]]
NumPy는 정밀한 과학 및 수치 계산에 특화된 라이브러리이므로, 더 넓은 범위의 숫자를 다룰 수 있는 실수형을 기본 데이터 타입으로 사용한다.
1으로 된 넘파이 배열 생성
ones = np.ones((2,5))
print(ones)
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
3.4.1. 무작위 수로 된 넘파이 배열 생성: np.random
인공 신경망의 가중치를 초기화하는 등 AI 모델링에서는 무작위 수가 매우 중요하다.
np.random 모듈이 이 기능을 담당한다.
rand(): 0과 1 사이의 균등 분포로 생성normal(): 정규 분포(가우시안 분포)에 따라 값 생성(평균, 표준편차 지정 가능)randint(): 지정된 범위 내에서 무작위 정수 생성
3.4.1.1. rand()
# 0~1 사이의 무작위 값 3개 생성
r = np.random.rand(3)
print(r)
array([0.30226897, 0.56284468, 0.55792285])
많은 수를 만들어 보면 정말 0~1 사이의 균등한 분포로 만들어지는지 확인할 수 있다.
import matplotlib.pyplot as plt # 그래프를 그리기 위해 matplotlib 라이브러리 사용
r1000 = np.random.rand(1000)
plt.hist(r1000) # r1000변수값을 히스토그램으로 표시
plt.grid() # 히스토그램을 격자 무늬 형태로 표시
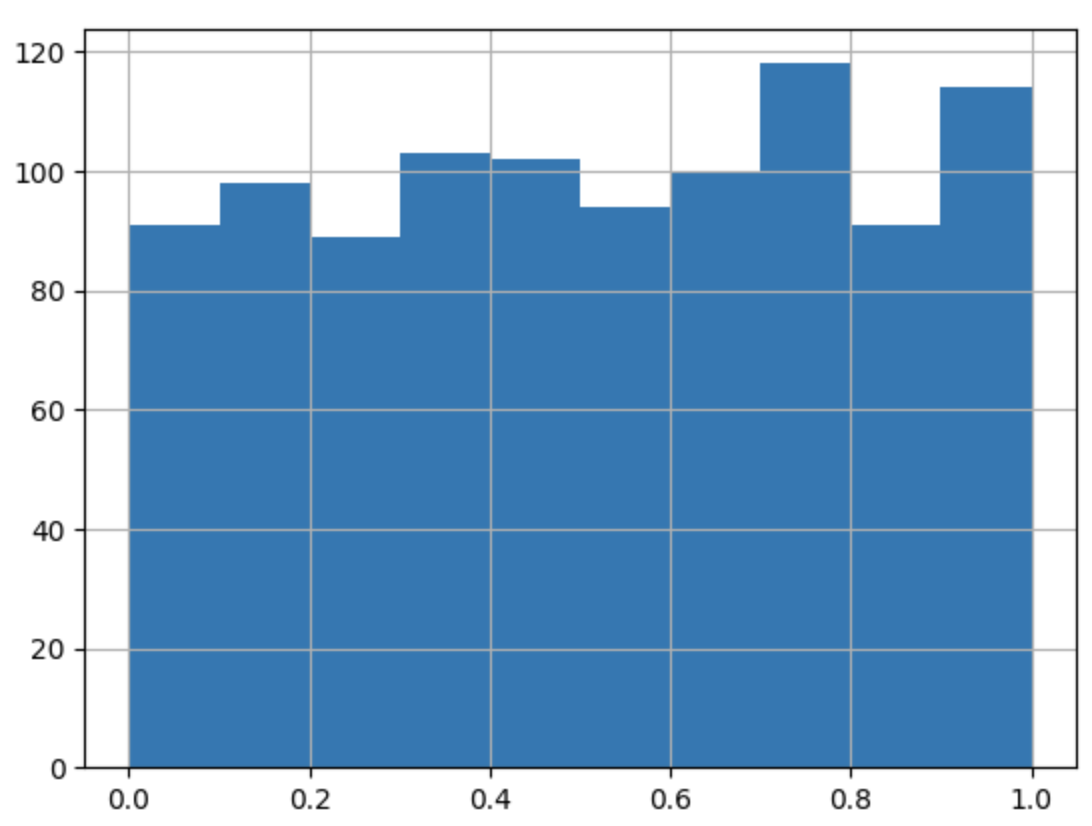
히스토그램은 화면에 나타낼 때 가로의 값은 각각의 숫자값, 즉, 0~1까지 숫자를 나타내며 새로의 값은 그 값을 가진 값 개수를 의미한다.
3.4.1.2. normal()
# 평균 0, 표준편차 1인 정규 분포에서 무작위 값 3개 생성
rn = np.random.normal(0, 1, 3)
print(rn)
[ 1.02290858 0.78916499 -0.43053464]
이제 무작위 값 1000개를 만들어보자.
rn1000 = np.random.normal(0, 1, 1000)
plt.hist(rn1000)
plt.grid()
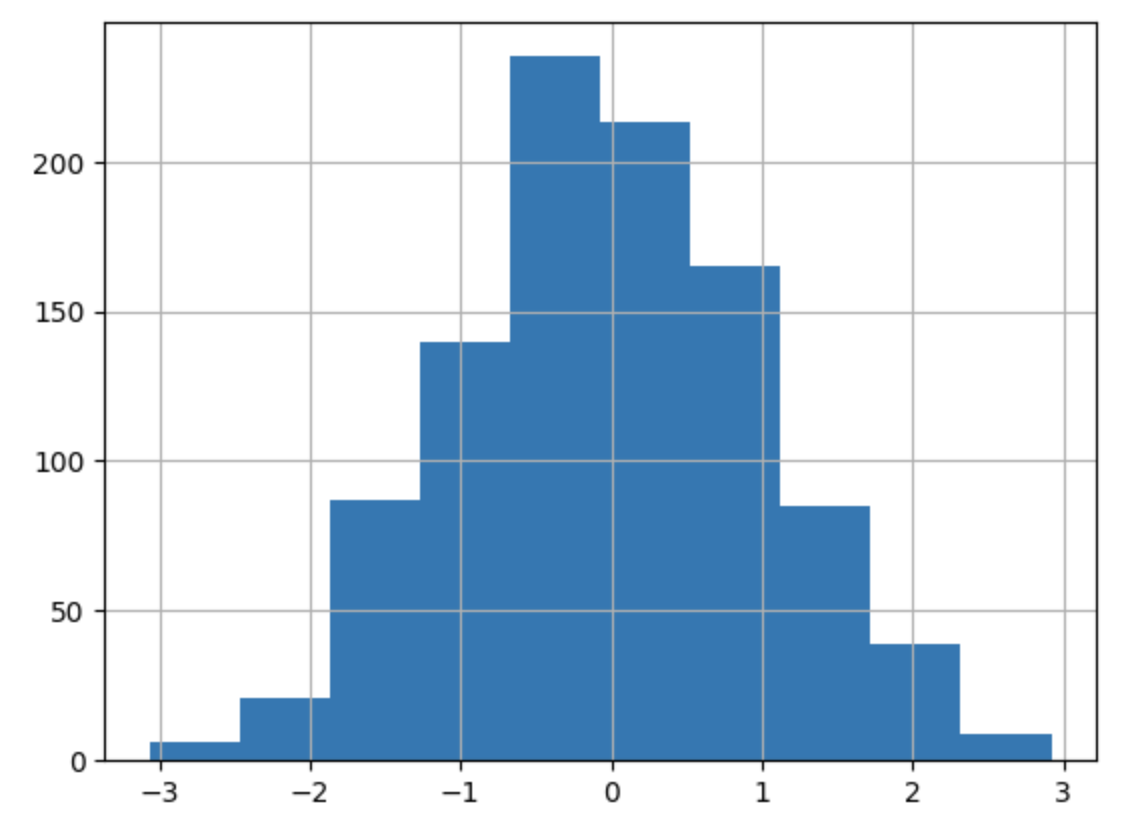
생성된 값이 0에 몰려있는 것을 확인할 수 있다. 이것으로 normal() 함수가 정규 분포에 해당하는 값을 생성하는 것을 알 수 있다.
3.4.1.3. randint()
# 1~100 사이의 무작위 정수 5개 생성
ni = np.random.randint(1, 100, 5)
print(ni)
array([25, 3, 52, 19, 35])
3.4.1.4. seed()
seed() 함수는 재현 가능한 무작위 수를 생성한다.
컴퓨터가 생성하는 난수는 사실 정해진 규칙에 따라 만들어지는 유사 난수(Pseudo-random)이다.
seed() 함수는 이 규칙의 시작점을 고정하여, 코드를 다시 실행해도 항상 동일한 난수 시퀀스가 생성되도록 한다.
이는 실험 결과를 재현하고 디버깅하는 데 매우 중요하다.
# seed를 고정하지 않으면 매번 다른 결과가 나옴
print(np.random.rand(3)) # [0.111 0.222 0.333]
print(np.random.rand(3)) # [0.444 0.555 0.666]
# seed를 0으로 고정
np.random.seed(0)
print(np.random.rand(3)) # [0.548 0.715 0.602]
# seed를 다시 0으로 고정하면 같은 결과가 나옴
np.random.seed(0)
print(np.random.rand(3)) # [0.548 0.715 0.602]
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 이영호 저자의 모두의 인공지능 with 파이썬을 기반으로 스터디하며 정리한 내용들입니다.
