AI - 숫자 인식 인공지능 만들기
in DEV on AI, Ml, Deep-learning, Keras, Tensorflow, Mnist, Python, AI, Ml, Neural-network, Classification, Data-preprocessing, Model-training, Model-evaluation, One-hot-encoding
이번 포스팅에서는 딥러닝의 가장 대표적인 입문 과제인 ‘손글씨 숫자 인식’ 인공지능을 직접 만들어보면서 인공지능이 어떻게 이미지를 보고 그 의미를 파악하는지 알아본다.
성공적인 인공지능 모델을 구축하기 위한 첫걸음은 바로 양질의 데이터를 준비하는 것이다.
이 프로젝트에서 우리는 MNIST 데이터셋을 사용할 것이다. MNIST는 0~9까지의 숫자를 손으로 쓴 7만 개의 이미지로 구성된, 딥러닝 분야의 ‘Hello, World!’ 같은 상징적인 데이터셋이다.
수많은 개발자와 연구자들이 인공지능 모델을 처음 만들고 성능을 시험할 때 바로 이 데이터셋을 사용한다.
이번 포스팅을 통해 데이터 준비부터 모델 설계, 학습, 그리고 결과 분석까지 딥러닝 프로젝트의 전체적인 흐름을 경험해보자.
목차
- 1. 개발 환경 셋팅
- 2. 데이터셋 불러오기
- 3. 입력 데이터 전처리(X): 모델에 맞는 형태로 변환
- 4. 정답 데이터 전처리(Y): 원-핫 인코딩(One-Hot Encoding)
- 5. 인공지능(신경망) 모델 설계
- 6. 모델 학습
- 7. 모델 정확도: 모델의 진짜 실력 평가
- 8. 모델 학습 결과 확인
- 9. 잘 예측한 데이터
- 10. 잘 예측하지 못한 데이터
- 참고 사이트 & 함께 보면 좋은 사이트
1. 개발 환경 셋팅
여기서는 별도의 설치 과정 없이 웹 브라우저에서 바로 컴퓨팅 자원을 사용할 수 있는 Google Colab 을 사용한다.
모델 개발에 필요한 다양한 라이브러리들을 가져오는 코드부터 시작한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
딥러닝 신경망은 여러 개의 레이어가 순차적으로 쌓여있는 구조를 가진다.
입력층에서 시작해 은닉층을 거쳐 출력층으로 데이터가 한 방향으로 흐르는 가장 기본적인 모델을 순차(Sequential) 모델이라고 한다.
Sequential 은 바로 이 순차 모델의 뼈대를 만들어주는 핵심 함수이다.
from tensorflow.keras.layers import Dense, Activation
- Dense
- 뉴런들이 모여 구성하는 하나의 레이어를 의미한다.
Dense레이어는 이전 충의 모든 뉴런과 다음 층의 모든 뉴런이 서로 연결되어 있어 전결합층(fully-connected layer)이라고도 불린다. Dense를 사용하여 신경망의 각 층을 구성하고, 뉴런의 개수를 지정한다.
- 뉴런들이 모여 구성하는 하나의 레이어를 의미한다.
- Activation
- 활성화 함수는 뉴런에 들어온 신호를 처리하여 다음 뉴런으로 보낼지 말지를 결정하는 역할을 한다.
- 이 함수 덕분에 모델이 복잡한 패턴도 학습할 수 있다.
from tensorflow.keras.utils import to_categorical
컴퓨터가 레이블(정답)을 더 쉽게 이해하도록 데이터를 변환하는 원-핫 인코딩(One-Hot Encoding)을 수행하는 함수이다.
원-핫 인코딩은 숫자를 0,1,2.. 와 같은 하나의 숫자로 표현하는게 아니라 벡터로 표현한다.
즉, 여러 개의 선택지 중 단 하나만 Hot(1)으로 표현하고 나머지는 모두 Cold(0)로 표현하는 방식이다.
예를 들어, 숫자 ‘0’은 [1,0,0,0,0,0,0,0,0,0,0]으로 변환하여 모델이 각 숫자를 명확히 구분하도록 돕는다.
from tensorflow.keras.datasets import mnist
MNIST 손글씨 숫자 데이터셋을 손쉽게 불러올 수 있도록 케라스에서 기본으로 제공하는 기능이다.
import numpy as np
Numpy는 파이썬에서 대규모 배열과 행렬 연산을 효율적으로 처리하게 해주는 수학 라이브러리이다.
이미지 데이터를 숫자의 배열로 다룰 때 중요한 역할을 한다.
import matplotlib.pyplot as plt 맷플롯립은 데이터와 모델의 학습 결과르 그래프로 시각화하여 우리가 직관적으로 이해할 수 있도록 돕는 라이브러리이다.
학습 과정이나 예측 결과를 눈으로 직접 확인할 때 사용된다.
2. 데이터셋 불러오기
인공지능 모델을 만들려면 훈련(train) 데이터와 검증(test) 데이터가 모두 필요하다.
인공지능의 성능을 살펴보기 위해 학습에 사용한 데이터로 성능을 평가하는 것은 의미가 없다. 학습에 사용하지 않은 데이터로 성능을 평가해야만 그 모델의 진짜 성능을 알 수 있다.
MNIST 데이터셋을 조회 후 훈련 데이터와 검증 데이터로 분류
# mnist 데이터셋을 불러와 train 데이터와 test 데이터로 나눕니다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 데이터의 형태(shape)를 출력합니다.
print("x_train shape:", x_train.shape)
print("y_train shape:", y_train.shape)
print("x_test shape:", x_test.shape)
print("y_test shape:", y_test.shape)
- x_train
- 모델을 학습시키기 위한 60,000개의 이미지 데이터
- 각 이미지는 28*28 픽셀 크기
- y_train
- x_train 이미지에 대한 정답
- 60,000개의 숫자 레이블(0~9)이 들어있음
- x_test
- 모델의 성능을 평가하기 위한 10,000개의 이미지 데이터
- y_test
- x_test 이미지에 대한 정답
x_train shape (60000, 28, 28) # 28*28 크기의 데이터가 6만개
y_train shape (60000,)
x_test shape (10000, 28, 28)
y_test shape (10000,)
shape 속성 참고
3. 입력 데이터 전처리(X): 모델에 맞는 형태로 변환
데이터를 불러왔다면, 이제 모델이 읽기 좋은 형태로 가공하는 전처리(Preprocessing) 과정이 필요하다.
이미지 데이터(x_train, x_test)에 대해 2가지 중요한 작업을 수행한다.
데이터 형태 변경(Reshaping)
현재 이미지 데이터는 (28, 28) 형태의 2차원 배열이다. 여기서 만들 인공 신경망의 입력층은 데이터를 1차원 배열, 즉 한 줄로 된 데이터 형태로 받도록 설계할 것이다.
따라서 reshape()을 통해 2828 크기의 이미지를 784개(2828=784)의 픽셀이 나열된 한 줄짜리 데이터로 펼쳐줄 것이다.
인공지능을 만들 때 항상 입력 데이터를 한 줄로 만들 필요는 없다. 모델을 설계하는 방식에 따라 입력 형태는 바뀐다.
정규화(Normalization)
현재 각 픽셀은 0(검은색)부터 255(흰색) 사이의 정수값을 가진다.
정규화는 모든 픽셀 값을 0과 1사이의 실수값으로 변환하여, 모델이 더 안정적이고 빠르게 학습하도록 돕는 과정이다.
모든 값을 255로 나누면 간단하게 정규화를 수행할 수 있다.
# 1. 28x28 이미지를 784 크기의 1차원 배열로 변환합니다.
# (60000,28,28) -> (60000,784)
X_train = x_train.reshape(60000, 784)
X_test = x_test.reshape(10000, 784)
# 2. 데이터 타입을 정수(int)에서 실수(float)로 변경합니다.
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# 3. 픽셀 값을 255로 나누어 0~1 사이의 값으로 정규화합니다.
X_train /= 255
X_test /= 255
# 변환된 데이터의 형태를 확인합니다.
print("X_train matrix shape:", X_train.shape)
print("X_test matrix shape:", X_test.shape)
X_train matrix shape (60000, 784)
X_test matrix shape (10000, 784)
4. 정답 데이터 전처리(Y): 원-핫 인코딩(One-Hot Encoding)
입력 데이터(X)뿐 아니라 정답 데이터(Y)도 모델이 잘 이해할 수 있는 형태로 변환해야 한다.
현재 정답 데이터(y_train, y_test)는 3,8,0 과 같은 숫자 형태로 되어있다. 이 숫자들을 그대로 사용하면 모델은 ‘숫자 8이 숫자 3보다 크다’와 같이 값들 사이의 불필요한 관계를 학습할 수 있다.
하지만 여기서는 숫자의 크기를 비교하는 것이 아니라, 10개의 카테고리(0~9) 중 이미지가 어떤 카테고리에 속하는지 맞추는 분류(Classification) 문제이다.
이 때 사용하는 방법이 바로 원-핫 인코딩이다.
10개의 카테고리를 대표하는 10칸짜리 배열을 만들고, 정답에 해당하는 칸만 1로 표시 후 나머지는 모두 0으로 채우는 방식이다.
예) 숫자 3: [0,0,0,1,0,0,0,0,0,0] (4번째 칸이 1)
이것을 다른 말로 표현하면 수치형 데이터를 범주형 데이터로 변환하는 것이라고 할 수 있다.
이와 같이 몇 번째 라는 식으로 알려주면 인공지능을 더 높은 성능으로 분류를 할 수 있기 때문에, 예측이 아닌 분류 문제에서는 대부분 정답 레이블을 첫 번째, 두 번째.. 처럼 순서로 나타내도록 데이터 형태를 바꾼다.
이렇게 하면 모델은 각 숫자를 독립적인 카테고리로 인식하여 분류를 더 효과적으로 수행할 수 있다.
Keras 의 to_categorical() 함수를 사용하면 이 과정을 쉽게 처리할 수 있다.
# y 데이터를 원-핫 인코딩합니다. (0~9 -> 10개의 카테고리로 변환)
Y_train = to_categorical(y_train, 10)
Y_test = to_categorical(y_test, 10)
# 변환된 데이터의 형태를 확인합니다.
print("Y_train matrix shape:", Y_train.shape)
print("Y_test matrix shape:", Y_test.shape)
to_categorical() 에서 두 번째 인자인 10은 원-핫 인코딩할 숫자, 즉 몇 개로 구분하는고자 하는지에 대한 수치이다.
여기서는 0~9이므로 10으로 설정한다.
Y_train matrix shape (60000, 10)
Y_test matrix shape (10000, 10)
(60000,) 형태였던 훈련 데이터의 정답이 (60000,10) 으로 변환된 것을 확인할 수 있다.
5. 인공지능(신경망) 모델 설계
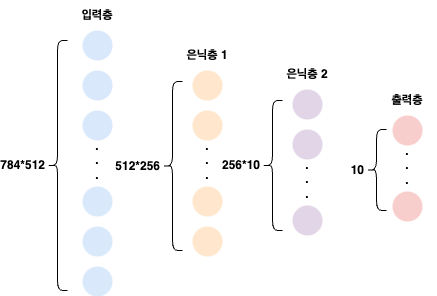
데이터 준비가 되었으니, 이제 신경망 모델(Neural Network Model)을 설계해보자.
정보를 처리하고 판단을 내리는 레이어들을 쌓아올려서 모델을 만들어보자.
<모델 아키텍처 구상>
여기서 만들 모델은 아래의 구조를 가진다.
- 입력층
- 784개의 픽셀 값을 입력받는 층 (28*28 이미지를 784개의 1차원 배열로 펼쳤기 때문)
- 은닉층 1
- 512개의 뉴런으로 구성
- 입력된 이미지에서 기본적인 특징(선, 곡선 등)을 찾아내는 역할
- 은닉층 2
- 256개의 뉴런으로 구성
- 은닉층 1에서 찾은 특징들을 조합하여 더 복잡한 패턴 학습
- 출력층
- 10개의 뉴런으로 구성
- 입력된 이미지가 0~9까지의 10개의 숫자 중 어디에 속하는지 최종적으로 판단하여 결과를 내보냄
<핵심 활성화 함수>
각 레이어에서 처리된 데이터는 활성화 함수(Activation Function)을 거쳐 다음 층으로 전달된다.
여기서는 2가지 함수를 사용한다.
- ReLU(Rectified Linear Unit)
- 은닉층에서 사용
- 뉴런에 들어온 값이 0보다 작으면 0으로, 0보다 크면 그 값을 그대로 내보내는 단순하지만 강력한 함수
- 기존의 다른 함수들(e.g., 시그모이드 함수)에 비해 학습 속도가 빠르고 성능이 좋아 최근 딥러닝 모델에서 널리 사용됨
- Softmax
- 마지막 출력층에서 사용
- 10개 뉴런의 출력값을 확률로 변환해주는 역할
- 예를 들어 어떤 이미지가 ‘7’일 확률 85%, ‘1’일 확률 10%, 나머지 숫자일 확률 5% 와 같이 변환해줌
- 출력된 모든 확률값의 총합은 항상 1이 되므로, 분류 문제에 필수적인 함수임
# 인공지능 모델 설계
from tensorflow.keras.layers import Input
# Sequential 모델의 뼈대를 생성합니다.
model = Sequential()
# 모델에 층(Layer)을 순서대로 추가합니다.
model.add(Input(shape=(784,))) # 입력층: 784개의 값을 받는다는 것을 명시
model.add(Dense(units=512)) # 첫 번째 은닉층 (뉴런 512개)
model.add(Activation('relu')) # 활성화 함수로 'relu' 사용
model.add(Dense(units=256)) # 두 번째 은닉층 (뉴런 256개)
model.add(Activation('relu')) # 활성화 함수로 'relu' 사용
model.add(Dense(units=10)) # 출력층 (뉴런 10개)
model.add(Activation('softmax')) # 활성화 함수로 'softmax' 사용
# 생성된 모델의 구조를 요약해서 출력합니다.
model.summary()
Model: "sequential_7"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ dense_6 (Dense) │ (None, 512) │ 401,920 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ activation_6 (Activation) │ (None, 512) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_7 (Dense) │ (None, 256) │ 131,328 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ activation_7 (Activation) │ (None, 256) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_8 (Dense) │ (None, 10) │ 2,570 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ activation_8 (Activation) │ (None, 10) │ 0 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 535,818 (2.04 MB)
Trainable params: 535,818 (2.04 MB)
Non-trainable params: 0 (0.00 B)
모델은 시퀀셜 모델로 구성되어 있다. 레이어를 나타내는 Layer 부분과 레이어의 모습을 나타내는 Output Shape 부분, 모델이 학습해야 할 파라미터(가중치와 편향)의 개수를 나타내는 Param 부분으로 나누어져 있다.
파라미터의 숫자가 클수록 모델의 표현력은 높아지지만, 더 많은 데이터와 계산 자원이 필요하다.
- 첫 번째 Dense 층(은닉층 1)
- (784개의 입력 * 512개 뉴런) + 512개의 편향 = 401,920개의 파라미터
- 784개의 입력층에서 512개의 은닉층으로 각각 연결되어 784*512개만큼 가중치가 있고, 은닉층 각 뉴런수만큼 편향(512)이 있음
- 두 번째 Dense 층(은닉층 2): (512개의 입력 * 256개 뉴런) + 256개의 편항 = 131,328개의 파라미터
- 세 번째 Dense 층(출력층): (256개의 입력 * 10개의 뉴런) + 10개의 편향 = 2,570개의 파라미터
6. 모델 학습
모델을 설계했으니 이제 이 모델을 훈련시킬 차례이다.
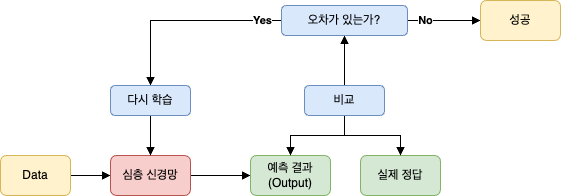
딥러닝의 학습 과정은 크게 3단계로 이루어진다.
- 예측(Predict): 모델에 데이터를 보여주고 정답을 예측하게 한다.
- 비교(Compare): 모델의 예측값과 실제 정답을 비교하여 오차(loss)를 계산한다.
- 개선(Adjust): 계산된 오차를 줄이는 방향으로 모델 내부의 파라미터(가중치와 편향)을 조금씩 수정한다.
이 과정을 수없이 반복하며 모델은 점점 더 똑똑해진다.
6.1. 학습의 규칙과 전략 설정(model.compile())
훈련에 앞서 모델을 어떤 방식으로 학습시킬지 규칙과 전략을 정해주어야 한다.
compile() 함수는 이러한 학습 환경을 설정하는 역할을 한다.
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
- 손실 함수(Loss function)
- 학습의 첫 단계는 모델이 얼마나 ‘못하는지’ 오차값을 수치화하는 것이다. 이것이 손실 함수의 역할이다.
- 이 인공 지능은 다중 분류 문제이므로
categorical_crossentropy를 사용한다. - 예시) 모델에게 ‘7’ 이라고 쓰인 이미지를 보여주었을 때
- 정답(One-Hot): [0,0,0,0,0,0,0,1,0,0] (8번째 자리가 1)
- 모델 예측: [0.01, 0.05, …, 0.8, …] (Softmax 결과)
categorical_crossentropy는 이 두 배열을 비교하여 ‘차이’를 계산한다.- 모델이 정답인 ‘7’일 확률을 80%(0.8)로 높게 예측했다면 손실(오차)는 낮게 계산된다.
- 반면, 엉뚱한 예측을 했다면 손실값은 매우 높게 계산된다.
- 즉, 손실 함수는 모델의 예측이 정답에서 얼마나 멀리 떨어져 있는지 알려주며, 이 값을 ‘0’에 가깝게 만드는 것이 학습의 목표이다.
- 옵티마이저(Optimizer): 경사 하강법
- 손실(오차)값을 구했으면 이제 이 오차를 줄여야 한다.
- 딥러닝으로 인공지능 모델을 학습시킬 때 발생하는 오차를 줄이려고 경사 하강법이라는 알고리즘을 사용한다.
- 이 때 경사 하강법을 어떤 방식으로 사용할지 다양한 알고리즘이 있는데, 이러한 알고리즘을 케라스에서 모아 놓은 것이 옵티마이저 라이브러리이다.
- 옵티마이저 종류에는 adam, 확률적 경사 하강법(SGD) 등이 있다.
- 평가 지표(Metrics)
loss값은 모델이 학습하는데 사용하는 핵심 수치이지만, 사람에게는 직관적이지 않다.metrics=["accuracy"]는 이 학습 과정을 사람이 이해하기 쉬운 ‘정확도’로 보여주는 역할을 한다.
6.2. 훈련 시작(model.fit())
이제 코드를 통해 실제 훈련을 시작해보자.
# 딥러닝
# 1. 모델의 학습 규칙과 전략을 설정합니다.
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
# 2. 모델을 훈련시킵니다.
model.fit(X_train, Y_train,
batch_size=128,
epochs=10,
verbose=1)
model.fit(X_train, Y_train, batch_size=128, epochs=10, verbose=1)
- X_train, Y_train: 학습에 사용할 입력 데이터와 정답(레이블)
- batch_size: 모델이 한 번에 학습할 데이터의 개수로 60,000개의 데이터를 128개의 작은 묶음으로 나누어 학습을 진행하면 더 안정적이고 효율적이다.
- epoch: 전체 데이터 훈련의 반복 횟수
- verbose:
fit()함수의 결과값을 출력하는 방법- 0: 아무런 표시를 하지 않음
- 1: 에포크별 진행 사항을 알려줌
- 2: 에포크별 학습 결과를 알려줌
Epoch 1/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 9s 16ms/step - accuracy: 0.8782 - loss: 0.4207
Epoch 2/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 6s 13ms/step - accuracy: 0.9728 - loss: 0.0880
Epoch 3/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 8s 16ms/step - accuracy: 0.9830 - loss: 0.0534
Epoch 4/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 7s 14ms/step - accuracy: 0.9874 - loss: 0.0377
Epoch 5/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 7s 15ms/step - accuracy: 0.9917 - loss: 0.0254
Epoch 6/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 7s 15ms/step - accuracy: 0.9931 - loss: 0.0210
Epoch 7/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 7s 14ms/step - accuracy: 0.9947 - loss: 0.0163
Epoch 8/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 8s 16ms/step - accuracy: 0.9960 - loss: 0.0119
Epoch 9/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 6s 13ms/step - accuracy: 0.9960 - loss: 0.0132
Epoch 10/10
469/469 ━━━━━━━━━━━━━━━━━━━━ 8s 16ms/step - accuracy: 0.9958 - loss: 0.0117
<keras.src.callbacks.history.History at 0x7cad806e6d80>
결과를 보면 에포크가 진행될수록 loss(오차) 값은 점점 줄어들고, accuracy(정확도) 값은 점점 1.0(100%)에 가까워지는 것을 확인할 수 있다.
이는 모델이 데이터를 통해 성공적으로 학습하고 있다는 명백한 증거이다.
7. 모델 정확도: 모델의 진짜 실력 평가
지금까지 훈련 데이터(train data)에 대한 모델의 학습 과정을 해보았다.
훈련 정확도가 99%를 넘으며 좋은 성적을 보였지만, 이것은 진짜 성능이 아니다.
이제 검증 데이터(test data)로 모델이 성능을 평가해보자.
model.evaluate() 함수를 하용하면 검증 데이터에 대한 모델의 정확도를 간단하게 확인할 수 있다.
# 검증 데이터(X_test, Y_test)로 모델의 성능을 평가합니다.
score = model.evaluate(X_test, Y_test)
print('Test score(loss):', score[0])
print('Test accuracy:', score[1])
model.evaluate(X_test, Y_test)
첫 번째 인자는 테스트할 데이터이고, 두 번째 인자는 테스트할 데이터의 정답이다.
첫 번째 결과값은 오차값(loss)이며 오차값은 0~1 사이의 값이다.
0이면 오차가 없는 것이고, 1이면 오차가 아주 크다는 것이다.
두 번째 결과값는 정확도이다.
모델이 예측한 값과 정답이 얼마나 정확한 지 0~1 사이의 값으로 보여지며, 1에 가까울수록 정답을 많이 맞춘 것이다.
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.9756 - loss: 0.0945
# 모델의 최종 오차값. 0에 매우 가까운 수치로, 모델이 정답과 매우 유사하게 예측했음을 의미함
Test score: 0.07793667912483215
# 모델의 최종 정확도. 처음 보는 손글씨 이미지 10,000개 중 약 9,805개를 정확하게 맞췄다는 의미로 매우 뛰어난 성능임
Test accuracy: 0.9805999994277954
313 은 모델이 10,000개의 테스트 데이터를 처리하는데 사용한 batch 의 총 개수, 즉 총 step 수이다.
evaluate() 함수의 기본 배치 크기는 32이다. 즉, 한 번에 32개의 이미지를 처리한다.
따라서 10,000(전체 데이터) / 32(배치 크기) = 312.5 이므로 총 313개의 스텝이 필요하다는 의미이다.
훈련 정확도(약 99%)보다 검증 정확도(약 98%)가 소폭 낮은 것은 자연스러운 현상이다.
이 정도의 차이는 모델이 단순히 훈련 데이터를 암기한 것이 아니라 새로운 데이터에도 적용할 수 있는 일반화된 능력을 잘 학습했다는 긍정적인 신호이다.
8. 모델 학습 결과 확인
전체 정확도가 98%라는 결과를 얻었지만 과연 모델은 어떤 이미지들을 맞추고, 어떤 이미지들을 헷갈려했을까?
이 질문에 답하기 위해, 10,000개의 검증 데이터에 대한 예측 결과를 모두 뽑아내고 ‘정답을 맞춘 그룹’과 ‘틀린 그룹’으로 나누는 작업을 해보자.
이제 실제로 인공지능이 어떤 그림을 무엇으로 예측했는지 알아보자.
# 모델이 Test 데이터를 보고 예측한 값을 predicted_classes에 저장
predicted_classes = np.argmax(model.predict(X_test), axis=1)
# 정답을 맞춘 데이터의 인덱스를 찾아 correct_indices에 저장
correct_indices = np.nonzero(predicted_classes == y_test)[0]
# 정답을 틀린 데이터의 인덱스를 찾아 incorrect_indices에 저장
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
print("모델의 예측 결과:", predicted_classes)
print("-" * 50)
print("정답을 맞춘 인덱스 개수:", len(correct_indices))
print("정답을 틀린 인덱스 개수:", len(incorrect_indices))
print("정답을 맞춘 인덱스:", correct_indices)
print("정답을 틀린 인덱스:", incorrect_indices)
model.predict(X_test)
10,000개의 테스트 이미지를 모델에 입력하여 예측을 수행한다. X_test 데이터는 모두 1만개 이므로 이 결과는 (10,000, 10)의 형태의 확률 배열로 나온다.
np.argmax(..., axis=1)
각 이미지(행)의 10개 확률값 중에서 가장 큰 값의 위치(인덱스)를 찾아낸다.
예를 들어 [0.1, 0.8, …] 이라는 확률 배열이 있다면, 가장 큰 값인 0.8의 위치, 즉 ‘1’을 최종 예측값으로 선택한다.
axis=0은 각 열(세로)에서 가장 큰 수를 고르는 것이고, axis=1은 각 행(가로)에서 가장 큰 수를 고르는 것이다.
np.nonzero()
모델의 예측값(predicted_classes)과 실제 정답(y_test)을 비교한다.
nonzero() 함수는 넘파이 배열에서 0이 아닌 값, 즉 1(인공지능이 예측한 값과 정답이 일치)을 찾아내는 함수이다.
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step
모델의 예측 결과: [7 2 1 ... 4 5 6]
--------------------------------------------------
정답을 맞춘 인덱스 개수: 9806
정답을 틀린 인덱스 개수: 194
정답을 맞춘 인덱스: [ 0 1 2 ... 9997 9998 9999]
정답을 틀린 인덱스: [ 115 149 217 247 321 340 381 445 448 495 582 613 646 659
674 720 740 877 882 900 947 951 956 965 1003 1014 1039 1112
1156 1226 1232 1242 1247 1260 1299 1319 1393 1414 1444 1522 1527 1530
1549 1553 1569 1597 1609 1670 1681 1717 1748 1790 1800 1850 1878 1901
1941 1952 1982 1987 2004 2024 2033 2044 2053 2093 2109 2118 2130 2135
2182 2272 2291 2293 2387 2406 2422 2488 2597 2630 2648 2654 2771 2810
2877 2896 2921 2939 2979 3030 3060 3073 3172 3225 3289 3405 3422 3451
3475 3503 3520 3558 3559 3565 3567 3597 3726 3727 3757 3762 3796 3801
3808 3893 3902 3906 3926 4075 4078 4176 4199 4201 4248 4289 4294 4306
4360 4497 4504 4639 4731 4740 4761 4807 4814 4823 4838 4860 4879 4880
4956 5265 5331 5457 5642 5676 5734 5842 5887 5936 5937 5955 5972 5973
6011 6028 6059 6071 6166 6555 6571 6597 6755 6783 7783 7990 8016 8143
8246 8273 8279 8311 8408 8522 8527 9009 9015 9019 9024 9422 9427 9540
9587 9634 9664 9679 9729 9770 9792 9808 9811 9839 9940 9953]
9. 잘 예측한 데이터
우리가 만든 모델이 약 98%의 높은 정확도를 기록했다는 사실을 확인하였다.
이제, 실제로 어떤 이미지들을 정확하게 예측했는지 직접 눈으로 확인해보자.
앞에서 분류한 correct_indices 목록을 사용하여 정답을 맞춘 이미지들 중 처음 9개를 3*3 격자 형태로 그려본다.
아래 코드는 matplotlib 라이브러리를 사용하여 correct_indices 에 해당하는 이미지를 가져와 시각화한다.
1차원 배열(784,) 형태의 이미지 데이터를 다시 2차원(28, 28)로 바꾸어 imshow() 함수로 그려준다.
import matplotlib.pyplot as plt
# 그래프를 그릴 Figure 객체 생성
plt.figure()
# 9개의 이미지를 3x3 격자로 그리기
for i in range(9):
# 3x3 격자의 i+1 번째 위치를 지정
plt.subplot(3, 3, i + 1)
# correct_indices 목록에서 i번째 인덱스를 가져옴
correct = correct_indices[i]
# X_test에서 해당 인덱스의 이미지를 28x28 형태로 변환하여 회색으로 표시
plt.imshow(X_test[correct].reshape(28, 28), cmap='gray')
# 이미지의 제목을 "예측값, 실제 정답" 형식으로 표시
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], y_test[correct]))
# 축 정보는 생략
plt.axis('off')
# 레이아웃을 자동으로 조정하여 겹치지 않게 함
plt.tight_layout()
plt.show()
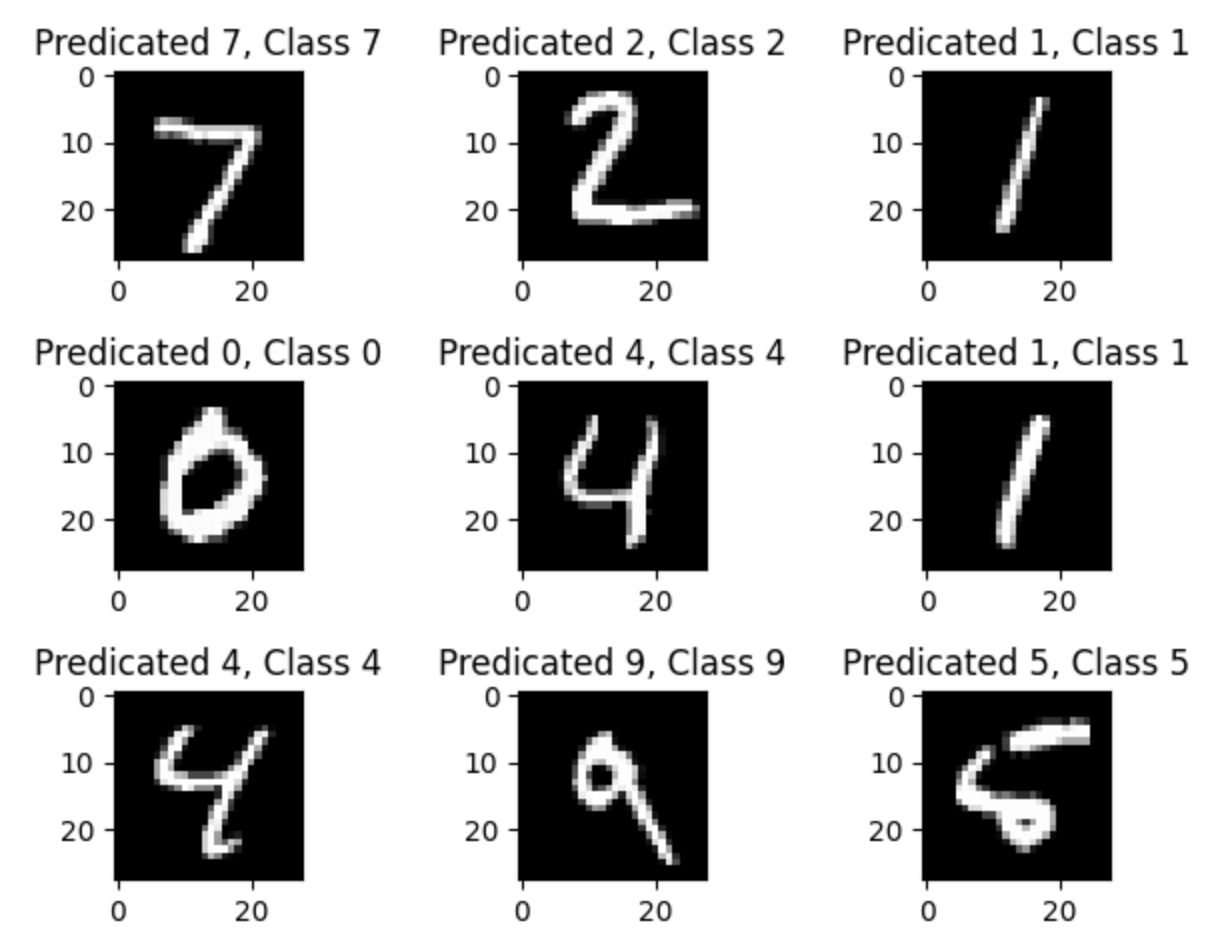
실행 결과를 보면 모델이 예측한 값(Predicted) 와 실제 정답(Class)이 정확히 일치하는 것을 볼 수 있다.
10. 잘 예측하지 못한 데이터
모델의 성공 사례를 보는 것도 중요하지만, 실패 사례를 분석하는 것은 모델을 개선하는데 훨씬 더 중요한 단서를 제공한다.
import matplotlib.pyplot as plt
# 그래프를 그릴 Figure 객체 생성
plt.figure()
# 9개의 이미지를 3x3 격자로 그리기
for i in range(9):
# 3x3 격자의 i+1 번째 위치를 지정
plt.subplot(3, 3, i + 1)
# incorrect_indices 목록에서 i번째 인덱스를 가져옴
incorrect = incorrect_indices[i]
# X_test에서 해당 인덱스의 이미지를 28x28 형태로 변환하여 회색으로 표시
plt.imshow(X_test[incorrect].reshape(28, 28), cmap='gray')
# 이미지의 제목을 "예측값, 실제 정답" 형식으로 표시
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], y_test[incorrect]))
# 축 정보는 생략
plt.axis('off')
# 레이아웃을 자동으로 조정하여 겹치지 않게 함
plt.tight_layout()
plt.show()
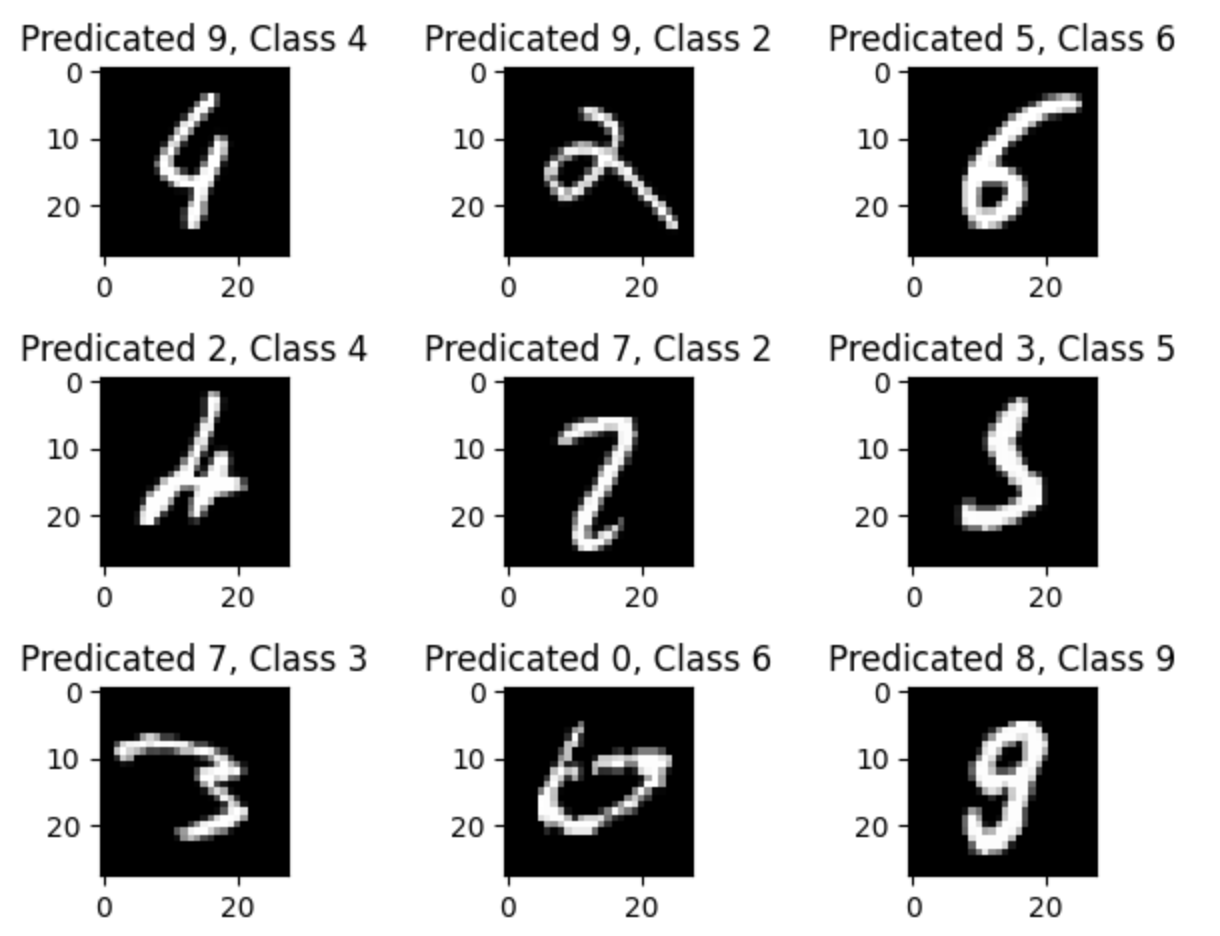
위 이미지를 보면 모델이 왜 실수를 했는지 어느 정도 짐작할 수 있다.
사람이 보기에도 애매한 글씨나, 숫자간의 유사성(‘5’와 ‘3’, ‘8’과 ‘3’처럼 구조적으로 비슷한 숫자들) 등은 모델도 구분하기 힘들다.
이 결과를 통해 모델을 개선할 방향을 엿볼 수 있다.
예를 들어 이미지를 약간씩 회전시키거나 변형하여 데이터의 다양성을 늘리는 데이터 증강(Data Augmentation) 기법을 사용하거나, 이미지 인식에 더 특화된 합성곱 신경망(CNN, Convolutional Neural Network)과 같은 더 발전된 모델 구조를 사용하면 이런 애매한 이미지들을 더 잘 분류할 수 있을 것이다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 이영호 저자의 모두의 인공지능 with 파이썬을 기반으로 스터디하며 정리한 내용들입니다.
