AI - Colab 에서 LLM 실행
in DEV on Ai, Ml, Llm, Open-source-llm, Hugging-face, Google-colab, Pytorch, Transformers, Llama, Llama-3, Text-generation, Pipeline, Bfloat16, Safetensors, Cuda, Gpu, System-prompt
지금 우리는 인공지능 열풍의 한가운데 서 있다. 이는 마치 19세기 미국 서부 개척 시대의 Gold Rush 를 연상케 한다.
흥미롭게도 당시 가장 큰 부를 축적한 이들은 금을 직접 캔 광부들이 아니라, 그들에게 삽, 곡괭이 같은 장비나 텐트를 판 사람들이었다.
이 비유를 AI 시대에 적용해 본다면, LLM이 새로운 ‘금광’이라면, 이 금광을 캐기 위한 필수 장비는 단연 고성능 GPU가 탑재된 서버라고 할 수 있다.
하지만 LLM을 학습하거나 실행하려면 개발자가 이러한 고가의 GPU 서버를 직접 구축하고 운영하는 것은 상당한 기술적, 비용적 장벽으로 다가온다.
바로 이 지점에서 Google Colab 이 훌륭한 대안을 제시한다.
Google Colab 은 클라우드 환경에서 무료 또는 저렴한 비용으로 강력한 GPU 리소스를 활용할 수 있게 해준다.
LLM을 활용하면 코드 생성, 문서 요약 등 수많은 작업을 자동화하고 서비스의 지능을 한 차원 높일 수 있다. 그 시작은 바로 우리 개발 환경에서 LLM 을 직접 실행해보는 것이다.
이 포스트에서는 Google Colab 환경에서 개방형 LLM을 실행하고 활용하는 방법에 대해 알아본다.
목차
1. 개방형 LLM 작동 원리
1.1. 개방형 LLM(Open-Source LLM) 이란?
개방형 LLM 은 모델을 구성하는 코드, 학습된 가중치, 때로는 아키텍처 등 내부 작동 방식이 대중에게 공개된 인공지능 모델을 의미한다.
개발자는 누구나 이 모델을 자유롭게 내려받아 직접 실행하고, 특정 도메인에 맞게 수정하거나 추가 데이터로 파인튜닝을 수행할 수 있다.
이는 개발자에게 모델에 대한 완전한 제어권과 유연성을 부여한다.
Meta 에서 만든 LLaMA, 마이크로소프트의 Phi, 딥시크와 같은 모델이 대표적인 개방형 LLM이다.
1.2. 폐쇄형 LLM(Closed-Source LLM) 과의 차이점
반면, 폐쇄형 LLM 은 내부 구조와 학습 데이터, 가중치 등이 철저히 비공개로 관리되는 모델이다.
사용자는 오직 제공자가 공개한 API 를 통해서만 모델에 접근하고 활용할 수 있다.
OpenAI 의 GPT, 구글의 Gemini, Anthropic 의 Claude 등이 대표적인 폐쇄형 LLM이다.
이 모델들은 일반적으로 사용하기 편리하고 강력한 성능이 검증되어 있지만, API 호출 비용이 발생하며 모델의 작동 방식을 직접 수정하거나 제어할 수는 없다.
1.3. 개방형 LLM 의 장점과 윤리적 고려사항
개방형 LLM 의 가장 큰 장점은 자유로움과 투명성이다.
개발자는 모델을 로컬 환경이나 자체 서버에 구축하여 데이터 프라이버시를 확보할 수 있으며, 특정 목적에 맞게 모델을 최적화하는 새로운 연구와 개발을 자유롭게 시도할 수 있다.
하지만 이러한 자유에는 그만큼의 책임이 따른다.
- 데이터 투명성 문제
- 모델의 가중치가 공개되었다고 해서, 모델이 학습한 모든 원시 데이터까지 투명하게 공개되는 것은 아니다.
- 만약 훈련 데이터에 개인정보나 저작권이 있는 자료가 포함되었다면, 모델의 출력에서 의도치 않은 개인정보 침해나 저작권 문제가 발생할 소지가 있다.
- 품질 및 안정성
- 개방형 모델은 그 성능과 안정성이 항상 보장되지는 않는다.
- 따라서 이를 실제 서비스에 적용하기 위해서는 모델의 특성을 이해하고 성능을 검증할 수 있는 어느 정도의 기술적 지식이 필요하다.
- 윤리적 사용
- 모델이 공개된 만큼, 연구나 교육 목적을 넘어선 악의적인 용도로 활용될 가능성이 존재한다.
- 따라서 개방형 LLM을 활용할 때는 데이터 윤리, 보안, 그리고 사회적 영향까지 고려하는 책임있는 사용이 강력히 요구된다.
결론적으로 개방형 LLM은 우리에게 AI 기술을 깊이 있게 탐구하고 활용할 수 있는 강력한 도구를 제공한다. 하지만 동시에 데이터 윤리, 보안, 품질 관리의 책임을 사용자(개발자)가 직접 감당해야 하는 기술이기도 하다.
2. 허깅페이스 접근 코드 발급
개방형 LLM 을 우리 환경으로 가져오기 위해, 허깅페이스라는 플랫폼을 활용해야 한다. 이곳은 전 세계 AI 개발자들의 필수 방문 코스이다.
2.1. 허깅페이스(Hugging Face)
허깅페이스는 AI 모델, 데이터셋, 머신러닝 도구를 공유하고 협업할 수 있는 대표적인 오픈소스 플랫폼이다.
초기에는 AI 기반 챗봇 개발사로 시작했지만, 현재는 전 세계의 AI 연구자와 개발자들이 자신의 모델을 공개하고 다른 사람의 모델을 활용하는 AI 생태계의 허브로 완벽하게 자리 잡았다.
허깅페이스의 ‘모델 라이브러리’에는 이 포스트에서 다룰 LLaMA 와 같은 LLM뿐만 아니라, Stable Diffusion 같은 이미지 생성 모델, BERT, GPT 계열의 자연어 처리 모델 등 수만 개가 넘는 AI 모델이 등록되어 있다.
또한, 허깅페이스는 transformers, diffusers 와 같은 파이썬 라이브러리를 제공한다. 이 라이브러리들은 개발자가 단 몇 줄의 코드만으로 복잡한 AI 모델을 쉽게 불러오고 실행할 수 있도록 돕는다.
2.2. LLaMA 3 사용을 위한 접근 승인 및 토큰 발급
여기서는 Meta 에서 개발한 고성능 개방형 LLM 인 LLaMA 3를 사용한다.
LLaMA 3와 같이 라이선스 정책이 있는 Gated Model(접근 제한 모델)을 사용하기 위해서는 먼저 모델 사용을 위한 접근 승인을 받고, 그 다음 본인 인증을 위한 Access Token을 발급받아야 한다.
- LLaMA 3 모델 접근 승인 요청
- 허깅 페이스에 로그인 후 검색창에 ‘meta-llama-3.2’를 검색하여 ‘meta-llama/Llama-3.2-3B-Instruct’ 모델 선택
- [Expand to review and access] 를 클릭 후 스크롤을 내려 필요한 정보 입력 후 Submit 버튼을 눌러 접근 요청
- 승인 상태 확인
- 요청 제출 후 승인까지는 약간의 시간이 소요될 수 있음
- [프로필] → [Settings] → [Gated Repositories] 로 이동하여 상태가 ACCEPTED(승인) 상태로 변경되면 승인이 완료된 것임
- Access Token 생성
- 모델 승인이 완료되면 이제 Colab 이나 로컬 환경에서 인증에 사용할 토큰을 생성해야 함
- [프로필] → [Settings] → [Access Tokens] 에서 Create New Token 버튼을 통해 토큰을 생성
- 이 때 Repositories 는 모든 항목을 선택
- 새롭게 만든 토큰은 이 화면에서만 볼 수 있으므로 반드시 Copy 버튼으로 안전한 곳에 복사
3. Colab 환경 설정
이제 LLaMA 3 모델을 직접 실행해 볼 실습 환경인 Google Colab 을 설정한다.
LLM 은 막대한 양의 연산을 필요로 하므로, 반드시 GPU 가속기를 활성화해야 한다.
[런타임] → [런타임 유형 변경] 에서 T4 GPU 를 선택한다.
T4 GPU 는 NVIDIA Tesla T4 를 기반으로 하며, 약 15~16GB의 VRAM(비디오 메모리)을 제공한다. 이는 이 포스트에서 사용할 LLaMA 3 3B 모델(약 30억 개의 파라미터)과 같이 비교적 작은 크기의 개방형 LLM을 구동하고 테스트하기에 매우 적합하다.
TroubleShooting - Colab: The secret HF_TOKEN does not exist in your Colab secrets. 을 참고하여 Google Colab 에 액세스 토큰을 저장한 후 아래와 같이 허깅페이스에 로그인한다.
# Colab의 '보안 비밀' 기능에 접근하기 위한 라이브러리
from google.colab import userdata
# 허깅페이스 허브에 로그인하기 위한 함수
from huggingface_hub import login
# Colab '보안 비밀'에 저장된 'LLAMA_HF_TOKEN' 값을 불러옴
hf_token = userdata.get('LLAMA_HF_TOKEN')
# 불러온 토큰을 사용하여 허깅페이스에 인증(로그인)을 요청
login(token = hf_token)
print("Hugging Face 로그인 및 Colab 환경 설정이 완료되었습니다.")
4. LLM 내려받기
Colab 환경 설정과 허깅페이스 인증이 완료되었으니, 이제 LLaMA 3 모델을 우리 환경으로 내려받을 차례이다.
이 과정에서 딥러닝 프레임워크의 양대 산맥 중 하나인 파이토치(PyTorch)와 허깅페이스 생태계의 핵심인 트랜스포머(Transformers) 라이브러리를 사용한다.
import torch
from transformers import pipeline
pipe = pipeline(
"text-generation", # 수행할 작업: 텍스트 생성
model = "meta-llama/Llama-3.2-3B-Instruct", # 사용할 모델
dtype = torch.bfloat16, # 연산 데이터 타입
device_map = "auto", # 하드웨어 자동 할당
token = hf_token # 인증 토큰
)
import torch (PyTorch)
파이토치(PyTorch)는 텐서플로와 함께 딥러닝을 이끄는 핵심 프레임워크이다.
2016년 Meta가 개발하여 오픈소스로 공개했으며, GPU를 활용한 강력한 텐서(다차원 배열) 연산과 유연한 딥러닝 모델 구축을 지원한다.
2022년 리눅스 재단 산하의 파이토치 재단으로 이관되어 독립적인 생태계를 구축하고 있다.
from transformers import pipeline (Hugging Face Transformers)
트랜스포머(Transformers) 라이브러리는 허깅페이스가 2018년 공개한 자연어 처리(NLP) 오픈소스 라이브러리이다.
BERT, GPT, T5, LLaMA 와 같은 수많은 트랜스포머 아키텍처 기반 모델을 단 몇 줄의 코드로 내려받고, 파인튜닝하며, 추론할 수 있게 지원한다.
여기서 사용된 pipeline() 함수는 이 라이브러리의 가장 편리한 기능 중 하나로, 텍스트 생성, 번역, 요약, 감정 분석 등 자주 쓰이는 작업을 위한 전처리(Tokenizing)와 후처리 과정을 모두 추상화하여 제공하는 강력한 도구이다.
pipe = pipeline(…)
모델을 내려받는다.
이제 pipeline() 함수에 전달된 5개의 핵심 인자에 대해 알아보자.
1.“text-generation”
pipeline()이 수행할 작업을 지정한다.
여기서는 ‘텍스트 생성’을 의미하며, 이 외에도 텍스트 분류(text-classification), 번역(translation), 요약(summarization) 등 다양한 작업을 선택할 수 있다.
2.model = “meta-llama/Llama-3.2-3B-Instruct”
허깅페이스 모델 허브에서 내려받을 모델의 고유 ID 를 지정한다.
3.dtype = torch.bfloat16
모델 연산에 사용할 데이터 타입을 bfloat16으로 설정한다.
이는 T4 GPU와 같은 16GB VRAM 환경에서 3B(30억 파라미터)급 모델을 구동하기 위한 핵심 설정이다.
4.device_map = “auto”
모델을 로드할 장치(CPU or GPU)를 자동으로 감지한다.
T4 GPU 런타임을 활성화했으므로, 이 옵션은 자동으로 GPU(cuda:0)를 감지하고 모델을 GPU 메모리에 올린다.
5.token = hf_token
meta-llama 모델처럼 접근 승인이 필요한 ‘Gated Model’을 내려받기 위해 인증받은 인증 토큰을 전달한다.
4.1. 로그 분석
위 코드를 실행하면 Colab 콘솔에 여러 파일이 다운로드되는 로그가 출력된다.
이 로그를 이해하면 LLM이 어떤 구성 요소로 이루어져 있는지 파악할 수 있다.
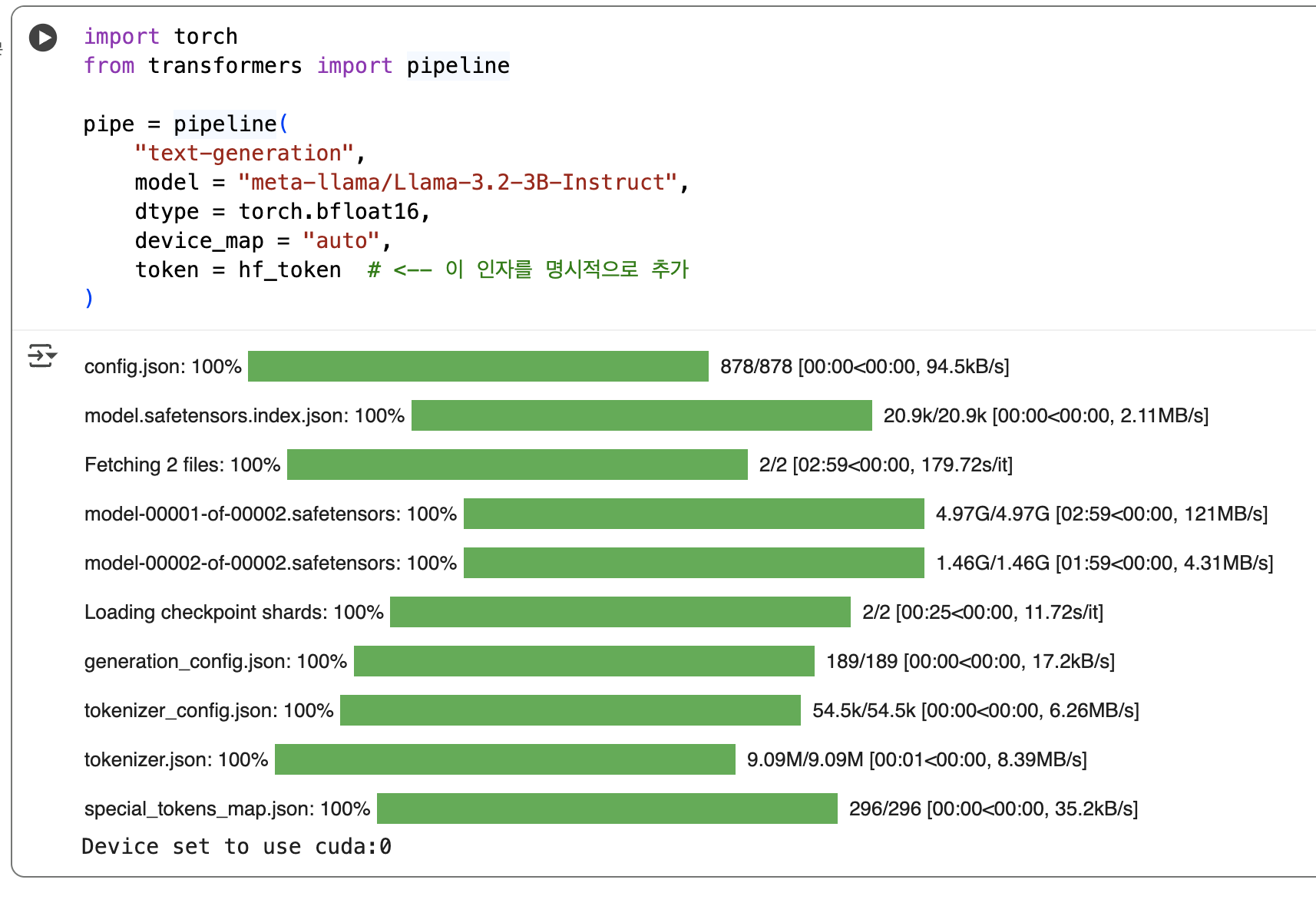
config.json: 100% 878/878 [00:00<00:00, 94.5kB/s]
config.json 은 모델의 설정 정보를 담고 있다.
이 모델이 몇 개의 레이어로 구성되어 있는지, 히든 레이어의 크기는 얼마인지 등 모델의 전체 아키텍처 정보가 담긴 설정 파일이다.
model.safetensors.index.json: 100% 20.9k/20.9k [00:00<00:00, 2.11MB/s]
Fetching 2 files: 100% 2/2 [02:59<00:00, 179.72s/it]
model-00001-of-00002.safetensors: 100% 4.97G/4.97G [02:59<00:00, 121MB/s]
model-00002-of-00002.safetensors: 100% 1.46G/1.46G [01:59<00:00, 4.31MB/s]
model-0000X-of-0000X.safetensors는 LLM 의 핵심인 가중치(Weights) 파일이다. LLaMA 3 3B 모델은 전체 용량이 6.43GB에 달해 하나의 파일로 관리하기 비효율적이다.
따라서 여러 조각(샤드)로 나뉘어 저장된다.
model.safetensors.index.json 파일은 이 조각난 샤드들을 어떻게 조합해야 완전한 모델이 되는지 알려주는 인덱스 파일이다.
뒤에 내려받은 여러 개로 나뉜 모델 조각(샤드)를 어떻게 결합해야 하는지 경로와 정보를 포함하고 있다.
.safetensors 는 기존의 pickle 포맷의 보안 취약점을 해결하고 빠르게 모델을 로드하기 위해 허깅페이스에서 개발한 새로운 표준 가중치 저장 형식이다.
Loading checkpoint shards: 100% 2/2 [00:25<00:00, 11.72s/it]
Colab 로컬 저장소에 내려받은 2개의 모델 샤드(safetensors 파일)를 T4 GPU의 VRAM(메모리)으로 불러들여 결합하는 과정이다.
이 단계가 완료되어야 모델이 추론 준비를 마친다.
generation_config.json: 100% 189/189 [00:00<00:00, 17.2kB/s]
모델이 텍스트를 생성할 때 필요한 다양한 설정 정보가 포함되어 있다.
출력 길이를 얼마로 할지, 반복 금지 설정을 할지 등의 정보가 포함된다.
tokenizer_config.json: 100% 54.5k/54.5k[00:00<00:00, 6.26MB/s]
tokenizer.json: 100% 9.09M/9.09M [00:01<00:00, 8.39MB/s]
special_tokens_map.json: 100% 296/296[00:00<00:00, 35.2kB/s]
토크나이저 관련 파일 3종 세트이다.
LLM 은 ‘안녕하세요’ 같은 텍스트를 직접 이해하지 못하고, 오직 숫자(토큰)로만 입력을 받는다.
토크나이저는 텍스트를 숫자 토큰 배열(예: [1,4,32])로 변환하고, 모델이 생성한 숫자 배열을 다시 텍스트로 복원하는 역할을 한다.
tokenizer.json 에 단어와 토큰 ID 의 매핑 사전(dictionary)이, special_tokens_map.json 에는 문장의 시작(<s>)이나 끝(</s>)을 알리는 특수 토큰 정보가 저장된다.
Device set to use cuda:0
모델이 cuda:0 장치를 사용하도록 설정되었다는 의미이다.
cuda:0 은 사용 가능한 첫 번째 NVIDIA GPU를 뜻하며, 이 메시지는 모델이 T4 GPU에 성공적으로 로드되었음을 확인시켜 준다.
4.2. bfloat16(Brain Floating Point 16)
딥러닝 모델은 본래 32비트 부동 소수점(FP32)으로 연산하는 것이 표준이지만, 이는 막대한 메모리를 차지한다.
bfloat16은 구글이 TPU(텐서 프로세싱 유닛)에서 처음 도입한 16비트 형식으로, 메모리 사용량을 절반으로 줄이면서도, 정밀도에 큰 영향을 주는 지수부는 FP32와 동일하게 8비트를 유지한다.
덕분에 정밀도 손실을 최소화하면서 메모리 효율을 극대화할 수 있어 대규모 딥러닝 모델 추론에 널리 사용된다.
4.3. 왜 딥러닝은 NVIDIA GPU를 선호할까?: cuda
로그의 마지막에 등장한 cuda 는 딥러닝 생태계에서 매우 중요한 키워드이다.
딥러닝 분야에서 유독 AMD 나 Intel 이 아닌 NVIDIA GPU가 압도적으로 사용되는 이유는 바로 CUDA(Compute Unified Device Architecture) 때문이다.
CUDA 는 NVIDIA가 2007년 독자적으로 개발한 GPU 프로그래밍 플랫폼(API 및 라이브러리)이다. 딥러닝에 필요한 핵심 연산은 수천 개의 코어를 활용한 고도의 병렬 처리인데, CUDA 는 개발자들이 이 GPU 병렬 연산을 매우 쉽고 강력하게 활용할 수 있도록 지원한다.
파이토치(PyTorch), 텐서플로와 같은 모든 주요 딥러닝 프레임워크는 처음부터 이 CUDA 생태계 위에서 개발되었고, NVIDIA GPU에 완벽하게 최적화되었다.
결과적으로 NVIDIA는 하드웨어(GPU)뿐만 아니라 소프트웨어 생태계(CUDA)까지 완벽하게 장악하며, AI 및 딥러닝 분야의 사실상 표준을 구축했다.
이것이 바로 Colab 에서 T4 GPU 를 사용하여 cuda:0 이라는 메시지를 보게 되는 이유이다.
5. LLM 에 질문하기
로드된 pipe 객체를 사용하여 모델에 질문하고 응답을 생성해보자.
아래 코드는 LLM 에게 ‘해적처럼 말하는 챗봇’이라는 페르소나를 부여하고, 사용자의 질문에 답하도록 요청하는 예시이다.
# 대화형 프롬프트를 위한 messages 리스트 정의
messages = [
{
"role": "system", # 시스템 역할
"content": "You are a pirate chatbot who always responds in pirate speak!"
},
{
"role": "user", # 유저 역할
"content": "Who are you?"
}
]
# 파이프라인을 실행하여 응답 생성
outputs = pipe(
messages,
max_new_tokens=256 # 최대 생성 토큰 수 제한
)
# 생성된 응답만 추출하여 출력
assistant_response = outputs[0]["generated_text"][-1]
print(f"--- AI 응답 (Role: {assistant_response['role']}) ---")
print(assistant_response['content'])
{ “role”: “system”, “content”: “You are a pirate chatbot who always responds in pirate speak!” }
시스템 프롬프트이다. 이는 모델에게 전반적인 지시사항, 작동 방식, 페르소나를 설정하는 가장 강력한 명령이다.
여기서는 ‘당신은 항상 해적 말투로 답하는 챗봇이다’라고 AI 의 정체성을 규정했다.
{ “role”: “user”, “content”: “Who are you?” }
사용자 프롬프트이다. 우리가 AI에게 던지는 실제 질문이나 요청을 의미한다.
이 입력을 기반으로 AI 가 설정된 해적 말투로 응답한다.
assistant_response = outputs[0][“generated_text”][-1]
outputs: 생성 결과가 리스트 형태로 담김
outputs[0]: 첫 번째 생성 결과를 의미
[“generated_text”]: key 에는 시스템, 사용자, 그리고 AI 의 응답까지 포함된 전체 대화 히스토리가 리스트로 들어있는데, 여기서 마지막 인덱스[-1] 을 선택하면 LLM이 방금 생성한 role: assistant 의 응답만 정확히 추출함
실행 결과는 아래와 같다.
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
--- AI 응답 (Role: assistant) ---
Yer askin' about ol' Blackbeak Betty, eh?
*adjusts eye patch* I be a swashbucklin' pirate chatbot,
here to share me treasure o' knowledge with ye landlubbers!
Me and me trusty computer be crewin' the digital seas,
ready to battle scurvy sea monsters and answer yer questions.
So hoist the sails and set course fer adventure, matey!
What be bringin' ye to these waters?
Setting pad_token_id to eos_token_id:128001 for open-end generation.
이 경고 메시지는 생성형 모델이 pad_token_id(패딩 토큰)를 문장의 끝을 알리는 eos_token_id(종료 토큰)으로 자동 설정했다는 단순 알림이다.
이는 일반적인 동작이므로 무시해도 괜찮다.
해석
옛날의 블랙비크 베티(Blackbeak Betty)에 대해 묻는 거요, 그렇지?
눈가리개를 고쳐 쓰며 나는 바다를 누비는 해적 챗봇이라오,
지식의 보물을 너희 육지쟁이들에게 나눠주러 왔지!
나와 내 믿음직한 컴퓨터는 디지털 바다를 항해하는 선원들이라네,
괴물 같은 바다 짐승들과 싸우며 너의 질문에 답할 준비가 되어 있지.
그러니 돛을 올리고 모험을 향해 항로를 잡자구, 친구!
무엇이 너를 이 바다로 이끌었나?
전체 코드
from google.colab import userdata
from huggingface_hub import login
hf_token = userdata.get('LLAMA_HF_TOKEN')
print(f"현재 로드된 토큰 (앞/뒤 5자리): {hf_token[:5]}...{hf_token[-5:]}")
login(token = hf_token)
print("설정 완료")
import torch
from transformers import pipeline
pipe = pipeline(
"text-generation",
model = "meta-llama/Llama-3.2-3B-Instruct",
dtype = torch.bfloat16,
device_map = "auto",
token = hf_token # <-- 이 인자를 명시적으로 추가
)
# 대화형 프롬프트를 위한 messages 리스트 정의
messages = [
{
"role": "system", # 시스템 역할
"content": "You are a pirate chatbot who always responds in pirate speak!"
},
{
"role": "user", # 유저 역할
"content": "Who are you?"
}
]
# 파이프라인을 실행하여 응답 생성
outputs = pipe(
messages,
max_new_tokens=256 # 최대 생성 토큰 수 제한
)
# 생성된 응답만 추출하여 출력
assistant_response = outputs[0]["generated_text"][-1]
print(f"--- AI 응답 (Role: {assistant_response['role']}) ---")
print(assistant_response['content'])
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 이영호 저자의 모두의 인공지능 with 파이썬을 기반으로 스터디하며 정리한 내용들입니다.
