Architecture(1) - 대규모 아키텍처 설계 핵심 12가지 체크리스트
in DEV on Architecture Scalability Load-balancing Database-replication Caching-strategies Cdn Stateless Message-queue Sharding
- 1. 단일 서버 아키텍처
- 2. DB: RDBMS vs NoSQL
- 3. Scale-out vs Scale-up
- 4. 웹 계층의 부하 분산: Load Balancer와 Private IP
- 5. 데이터 계층의 안정성 확보: 데이터베이스 다중화
- 6. Latency 줄이기: Cache
- 7. CDN(Content Delivery Network)
- 8. Stateless 웹 계층
- 9. 다중 데이터 센터와 지리적 라우팅(GeoDNS)
- 10. 시스템 간 결합도 낮추기: 메시지 큐
- 11. 로그, 메트릭 모니터링 그리고 자동화
- 12. DB 샤딩 도입
- 요약
- 참고 사이트 & 함께 보면 좋은 사이트
1. 단일 서버 아키텍처
단일 서버 아키텍처는 웹 애플리케이션, DB, 캐시 등 서비스 운영에 필요한 모든 컴포넌트를 단 한 대의 서버에서 모두 실행하는 가장 단순한 형태의 시스템 구조이다.
트래픽이 적은 초기 스타트업이나 토이 프로젝트에서 주로 사용한다.
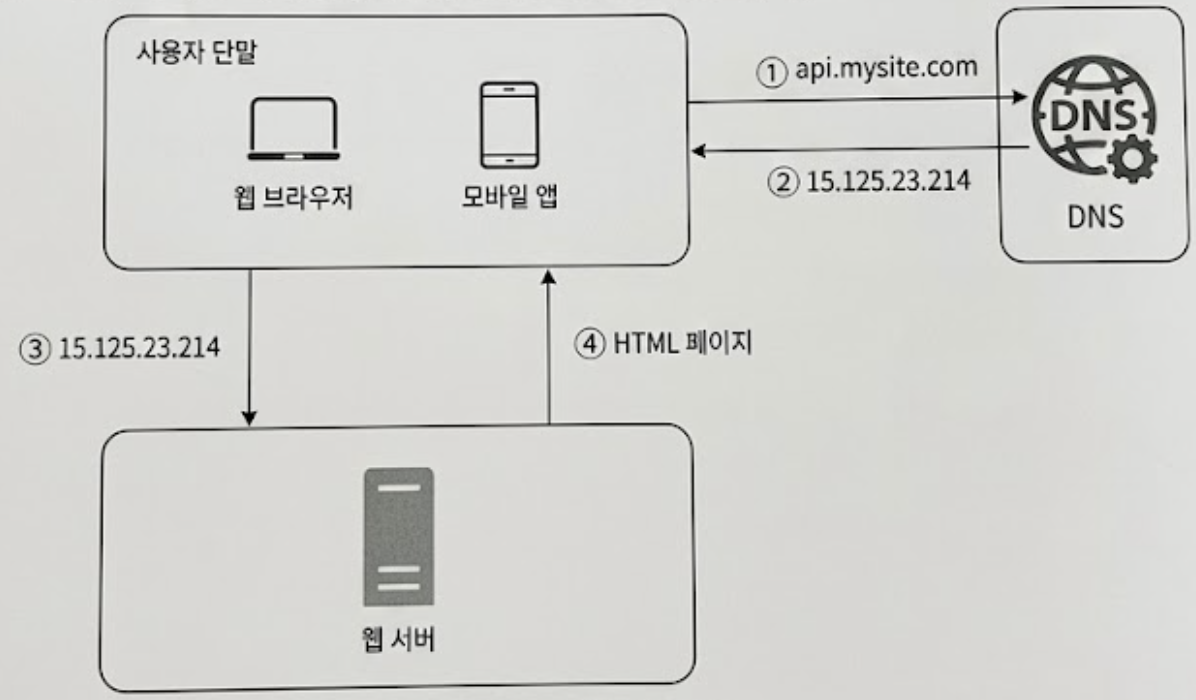
① DNS 질의(Domain Name Resolution): 사용자는 도메인 이름(api.mysite.com)을 브라우저 주소창에 입력한다. 클라이언트는 이 도메인을 가진 서버의 실제 주소를 찾기 위해 DNS(Domain Name Service) 서버에 질의한다.
② IP 주소 반환: DNS 서버는 도메인 이름을 확인한 후, 그에 매핑된 웹 서버의 실제 IP 주소를 클라이언트로 반환한다.
③ HTTP 요청 송신: IP 주소를 확보한 클라이언트는 해당 웹 서버를 향해 직접 HTTP 요청을 보낸다.
④ 응답 반환: 요청을 수신한 웹 서버는 처리 후 HTTP 페이지나 데이터를 담아 JSON 형태로 응답한다.
⚠️단일 서버의 한계
- SPOF(Single Point of Failure, 단일 장애 지점): 서버 한 대에 모든 것이 의존하므로, 서버가 다운되면 전체 서비스가 마비된다.
- 자원의 한계: 동시 접속자 수가 늘어나면 CPU, 메모리, 디스크 I/O 병목이 발생하여 급격한 성능 저하가 발생한다.
2. DB: RDBMS vs NoSQL
대규모 아키텍처를 설계할 때 핵심은 비즈니스 데이터의 특성에 맞춰 RDBMS를 사용할지, 혹은 비관계형 데이터베이스(NoSQL)을 사용할지 결정하는 것이다.
| RDBMS | NoSQL | |
|---|---|---|
| 데이터 구조 | 엄격한 스키마, 테이블 기반(Row, Column) | 유연한 스키마, 다양한 데이터 모델 |
| 특징 | SQL 활용, 고성능 JOIN 연산 지원, ACID 트랜잭션 보장 | JOIN 없음, Scale-out이 매우 용이함 |
| 대표 기술 | MySQL, Oracle, PostgreSQL, MariaDB | Redis, MongoDB, Cassandra |
NoSQL은 4가지 분류로 나눌 수 있다.
- Key-Value 저장소
- 고유한 키와 값의 쌍으로 데이터 저장
- 읽기/쓰기 속도가 극도로 빠름
- 예) Redis, DynamoDB
- Document 저장소
- JSON이나 XML 같은 계층적인 문서 형태로 데이터 저장
- 데이터 구조가 유연하게 바뀔 때 유리함
- 예) MongoDB, CouchDB
- Column 저장소
- 행(Row)이 아닌 열(Column) 단위로 데이터를 묶어서 저장
- 대규모 데이터 분석 및 대량의 쓰기 연산에 특화
- 예) Cassandra, HBase
- Graph 저장소
- 노드(Node)와 간선(Edge)으로 데이터 간의 ‘관계’를 지도처럼 저장
- SNS의 친구 관계나 추천 시스템에 필수적
- 예) Neo4j
NoSQL은 일반적으로 join 연산은 지원하지 않는다.
❓NoSQL은 어떤 경우에 사용해야 할까?
대규모 아키텍처 설계 관점에서 NoSQL은 일반적으로 아래와 같은 요구사항이 있을 때 RDBMS 대신, 혹은 RDBMS와 함께(Polyglot) 도입한다.
- 초저지연(Low Latency)이 요구될 때: 복잡한 관계 처리가 필요 없고, ms 단위의 빠른 응답 속도가 중요할 때 유리
- 비정형/반정형 데이터를 다룰 때: 정해진 양식 없이 자주 스키마가 변경되거나 직렬화된 객체를 그대로 저장해야 할 때
- 방대한 대용량 데이터를 저장해야 할 때: RDBMS가 감당하기 힘든 TB, PB 급의 데이터를 저비용으로 확장하며 저장해야 할 때
3. Scale-out vs Scale-up
서버로 유입되는 대규모 트래픽과 성능 병목을 해결하는 확장 전략은 크게 Scale-up과 Scale-out 으로 나뉜다.
<Scale-up의 장단점>
- 장점
- 설계가 매우 단순함. 애플리케이션 코드를 수정하거나 복잡한 분산 아키텍처를 도입할 필요 없이 하드웨어만 교체하면 성능이 즉시 향상됨
- 단점
- 비용의 비선형적 증가: 고성능 장비로 갈수록 가격이 기하급수적으로 비싸져 비용 효율성이 떨어짐
- 장애 복구(Failover) 불가: 여전히 ‘단일 서버’ 구조이므로, 해당 장비에 장애가 발생하면 전체 서비스가 다운되는 위험(SPOF)을 해결하지 못함
<Scale-out의 장단점>
- 장점
- 무한한 확장성: 이론적으로 서버를 수십, 수백 대 계속 추가할 수 있어 확장의 한계가 없음
- 고가용성 확보: 특정 서버 한 대가 다운되더라도 다른 서버들이 트래픽을 나누어 받으므로 서비스가 중단되지 않고 자동 복구(failover) 설계가 가능해짐
- 단점
- 복잡성 증가. 여러 서버로 트래픽을 고루 나눠주기 위한 로드밸런서 도입이 필수적이며, 데이터의 일관성을 유지하기 위한 분산 시스템 설계가 요구됨
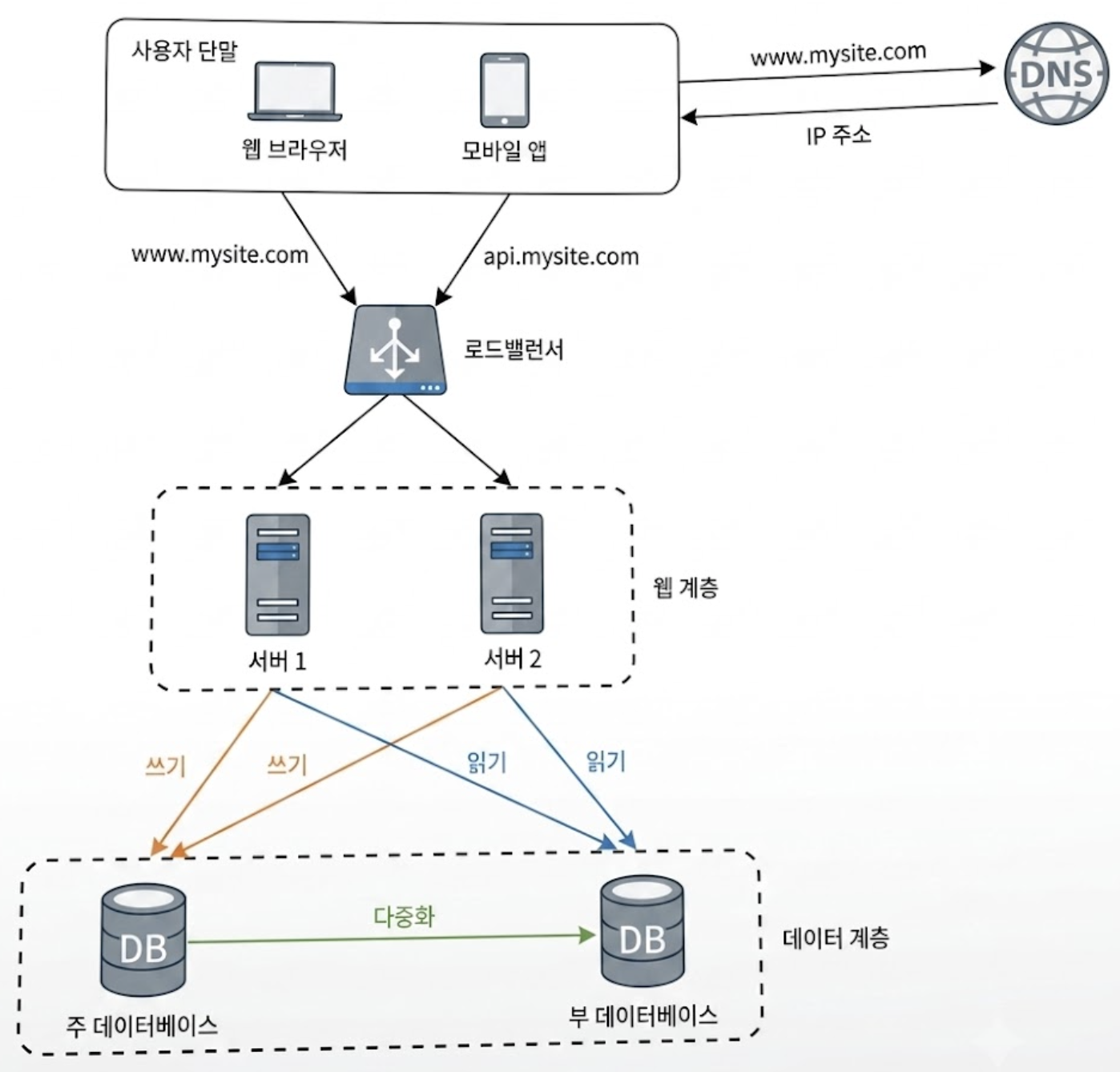
4. 웹 계층의 부하 분산: Load Balancer와 Private IP
로드밸런서는 서버로 유입되는 대규모 트래픽을 여러 대의 웹 서버로 골고루 분산해 주는 부하 분산 장치이다.
웹 계층을 Scale-out할 때 클라이언트의 요청을 최전선에서 맞이하는 핵심 컴포넌트이다.
로드밸런서가 도입되면 보안성이 극대화되는데 그 중심에는 로드밸런서의 Public IP(예: 88.88.88.1)와 Private IP가 있다.
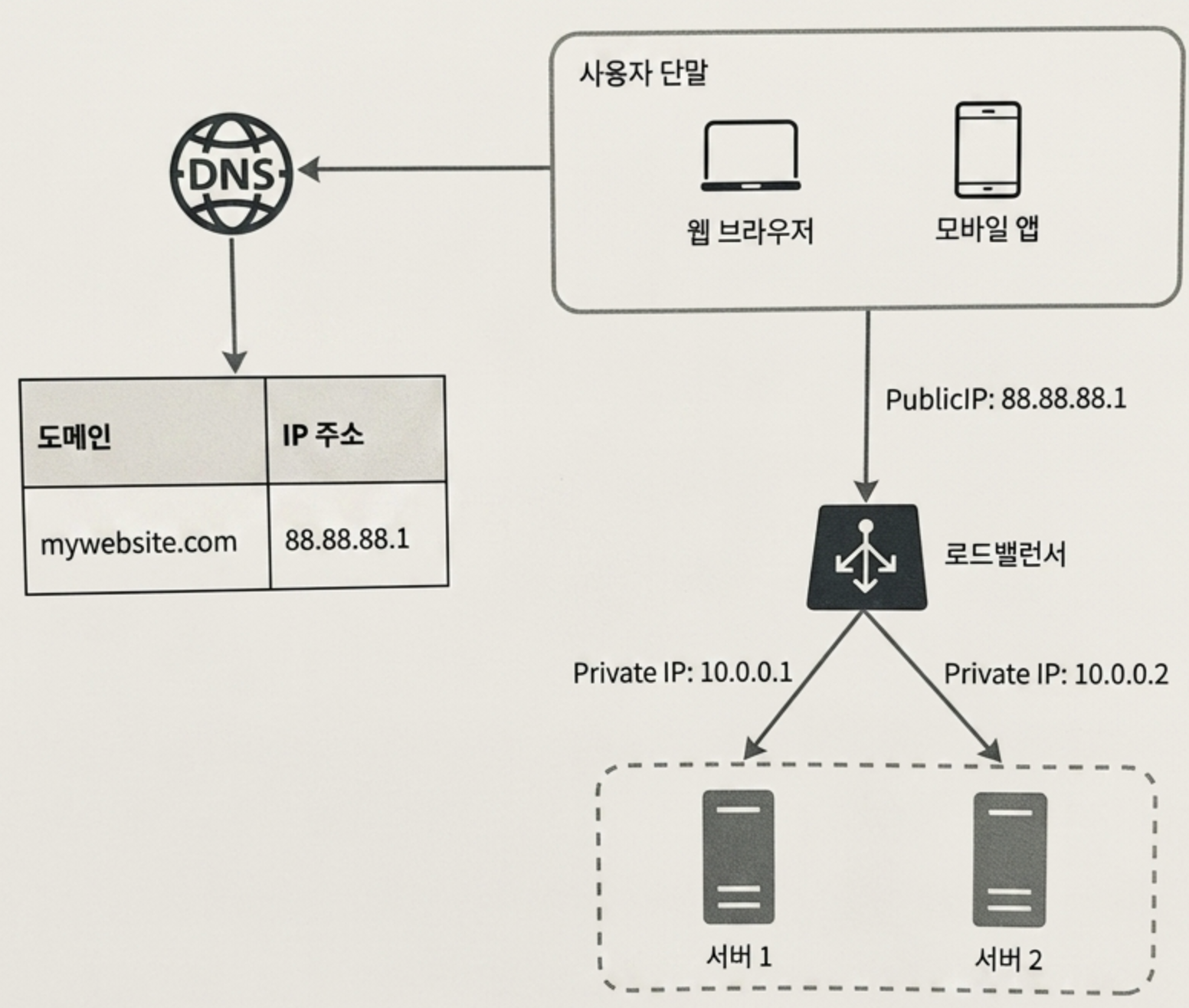
- Public IP(인터넷 공개 주소): 클라이언트는 로드밸런서의 Public IP로만 접속한다. 웹 서버의 실제 주소는 외부 인터넷에 절대 노출되지 않는다.
- Private IP(내부 네트워크 주소): 로드밸런서 뒷단에 위치한 웹 서버들은 동일한 로컬 네트워크 안에서만 통신할 수 있는 Private IP를 부여받는다. 인터넷을 통해서는 이 주소로 직접 접근할 수 없다.
5. 데이터 계층의 안정성 확보: 데이터베이스 다중화
데이터베이스 다중화란 데이터의 원본을 보유한 Primary와 복제된 사본을 보유한 Replica를 분리하여 데이터를 실시간 동기화하는 기술이다.
🔄Read와 Write의 철저한 분업
통상적인 웹 서비스는 Write 연산보다 Read 연산의 비중이 훨씬 높다.
따라서 Primary DB 서버 한 대에 여러 대의 Replica DB 서버를 붙이는 구조가 일반적이다.
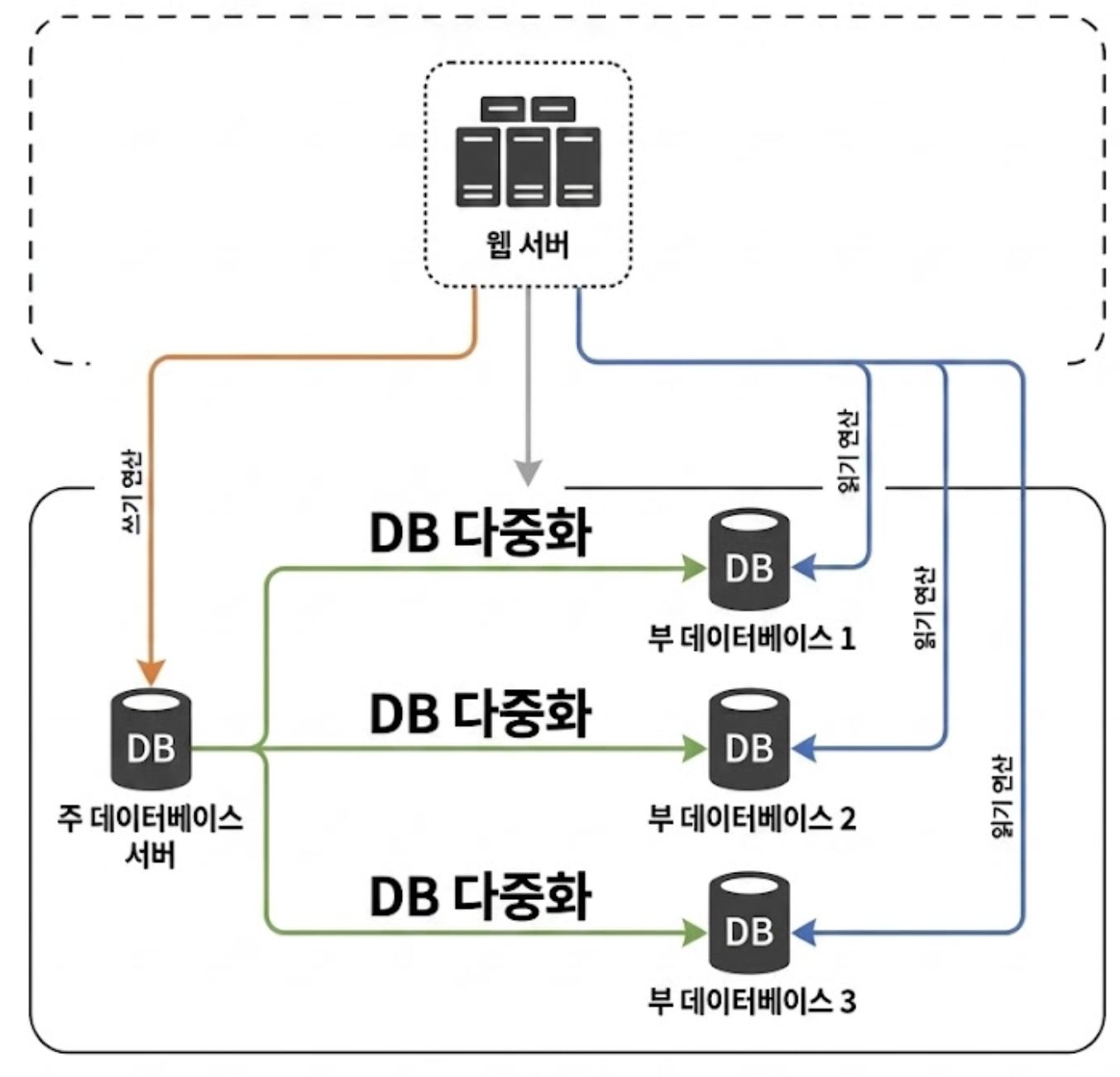
<DB 다중화의 장점>
- 더 나은 성능: 모든 쓰기는 Primary로, 읽기는 여러 Replica로 분산 처리되므로 병렬 질의 속도가 획기적으로 빨라짐
- 안정성: 데이터센터 일부가 손상되더라도 여러 지역에 사본(Replica)이 보존되어 있으므로 데이터 유실 없음
- 고가용성: Primary 서버가 죽으면 Replica 중 하나가 새로운 Primary DB로 승격(Failover)되어 중단 없는 서비스 제공 가능
6. Latency 줄이기: Cache
캐시는 처리 속도가 느린 DB를 매번 호출하는 대신, 상대적으로 연산 비용이 비싸거나 자주 참조되는 데이터를 메모리(RAM) 기반의 고속 저장소에 임시로 두고 요청을 빠르게 처리하는 컴포넌트이다.
애플리케이션은 읽기 요청을 처리할 때 DB로 가기 전 먼저 캐시를 확인하는 캐시 우선 읽기 전략(Look-Aside / Cache-Aside)을 주로 사용한다.
- Cache Hit: 찾으려는 데이터가 캐시에 있는 경우, DB를 거치지 않고 즉시 데이터 반환
- Cache Miss: 캐시에 데이터가 없는 경우, DB에서 데이터를 직접 조회한 뒤 이를 캐시에 적재하고 클라이언트에 반환
🧹캐시 지우기 정책(Eviction)
메모리 공간은 유한하기 때문에 캐시가 가득 차면 어떤 데이터를 버리고 새 데이터를 넣을지 결정해야 하는데 이를 캐시 지우기 정책이라고 한다.
- LRU(Least Recently Used): 마지막으로 사용된 지 가장 오래된 데이터를 우선 삭제하는 정책(가장 널리 쓰임)
- LFU(Least Frequently Used): 지금까지 사용된 빈도가 가장 낮은 데이터를 우선 삭제하는 정책
- FIFO(First In, First Out): 가장 먼저 들어온 순서대로 데이터를 삭제하는 정책
🚀Deep Dive: 캐시 전략 5가지 비교
Caching Strategies and How to Choose the Right One 에 따르면 시스템의 쓰기/읽기 패턴에 맞는 정확한 캐싱 전략을 선택해야만 정합성 문제와 Latency를 모두 잡을 수 있다.
- Cache Aside(Lazy Loading)
- 작동 방식: 앱이 캐시/DB 직접 제어, 애플리케이션이 캐시를 먼저 보고, 없으면(Miss) DB에서 가져와 직접 채워넣는 가장 일반적인 방식
- 장점: 캐시 서버가 다운되어도 서비스가 중단되지 않고 DB로 직접 붙을 수 있어 복구 탄력성(Resilient)이 좋음
- 단점: DB 데이터가 수정되었을 때 캐시 데이터와 불일치가 발생할 수 있으므로, TTL 설정 필수
- 데이터 변경은 적고 읽기 부하가 크고, 캐시 장애가 서비스 중단으로 이어지면 안될 때 사용
- 예) 상품 카탈로그
- Read-Through
- 작동 방식: 캐시가 DB 조회 대행, 애플리케이션은 오직 캐시 시스템하고만 통신함. 데이터가 없으면 캐시 라이브러리나 프로바이더가 내부적으로 직접 DB에서 데이터를 조회하여 캐시 갱신
- 장점: 애플리케이션 코드가 단순해지고 캐시 채우기 책임이 분리됨
- 단점: 캐시와 DB의 데이터 모델 구조가 항상 동일해야 하는 제약이 있음
- 동일한 데이터의 반복적인 읽기가 주를 이루고, 코드를 깔끔하게 유지할 때 사용
- 예) 실시간 트렌드 피드
- Write-Through
- 작동 방식: 캐시와 DB 동시 저장, 데이터를 저장할 때 캐시와 DB 두 곳에 동시에 데이터를 기록
- 장점: 캐시의 데이터가 항상 최신 상태를 유지하므로 데이터 정합성이 완벽하게 보장됨
- 단점: 매번 두 군데에 쓰기 연산을 수행하므로 쓰기 지연 시간이 늘어남. 읽기가 드문 데이터까지 캐싱되어 리소스가 낭비될 수 있음
- 데이터 유실이나 불일치가 절대 용인되지 않는 중요 정보 처리 시 사용
- 예) 계좌 잔액, 실시간 상품 재고, 유저의 결제 상태 변경
- Write-Around
- 작동 방식: DB에만 저장(캐시 우회), 모든 데이터는 캐시를 거치지 않고 DB에만 직접 기록됨. 캐시는 오직 읽기 시 Cache Miss가 발생할 때만 채워짐
- 장점: 한 번 저장된 후 자주 읽히지 않는 데이터를 처리할 때 캐시 공간을 무모하게 오염시키지 않음
- 단점: 방금 쓴 데이터를 바로 읽으려고 할 때 캐시 미스가 발생하여 초기 지연이 생길 수 있음
- 한 번 쓰인 후 거의 읽히지 않는 대량의 데이터 처리 시 사용
- 예) 시스템 로그, 과거 결제 내역, 보안 이벤트 기록
- Write-Back(Write-Behind)
- 작동 방식: 캐시에 선저장 후 DB 저장, 데이터를 캐시에만 먼저 초고속으로 저장한 뒤, 일정 주기나 데이터가 모였을 때 DB에 비동기 배치로 일괄 반영하는 방식
- 장점: 쓰기 연산이 극단적으로 많은 서비스(대규모 이벤트 로그 수집, 게임 실시간 위치 정보 등)에서 최고의 쓰기 성능을 냄. DB 부하를 획기적으로 줄여줌
- 단점: 캐시 서버가 배치를 반영하기 전에 갑자기 다운되면 메모리에만 있던 데이터가 영구 유실될 위험 존재
- 쓰기 트래픽이 폭발적이어서 DB 병목을 반드시 해결해야 할 때 사용
- 예) 실시간 게임의 유저 좌표 데이터, SNS 게시글의 실시간 좋아요 수
Write-Around는 오직 데이터를 저장할 때 트래픽이 어디로 흐르는지만 정의한 ‘쓰기 전용 정책’이다.
협업에서는 Cache-Aside 패턴을 기본 아키텍처로 잡고, 쓰기 전략은 캐시를 우회하는 Write-Around 방식을 조합해서 사용한다.
새로운 데이터를 저장할 때 Cache-Aside, Write-Around 모두 DB 에만 저장한다.
하지만 기존 데이터를 수정할 때 Cache-Aside는 DB 수정 후 캐시 데이터를 강제 삭제하지만 Write-Around는 DB만 수정하고 캐시는 방치한다.
7. CDN(Content Delivery Network)
CDN은 전 세계에 지리적으로 분산된 서버 네트워크를 활용하여, 이미지/비디오/CSS/Javascript 등 변경이 잦지 않은 정적 콘텐츠를 사용자와 가까운 Edge 서버에서 빠르게 제공하는 시스템이다. 이를 통해 원본 서버의 부하를 획기적으로 줄이고 대역폭 비용을 절감할 수 있다.
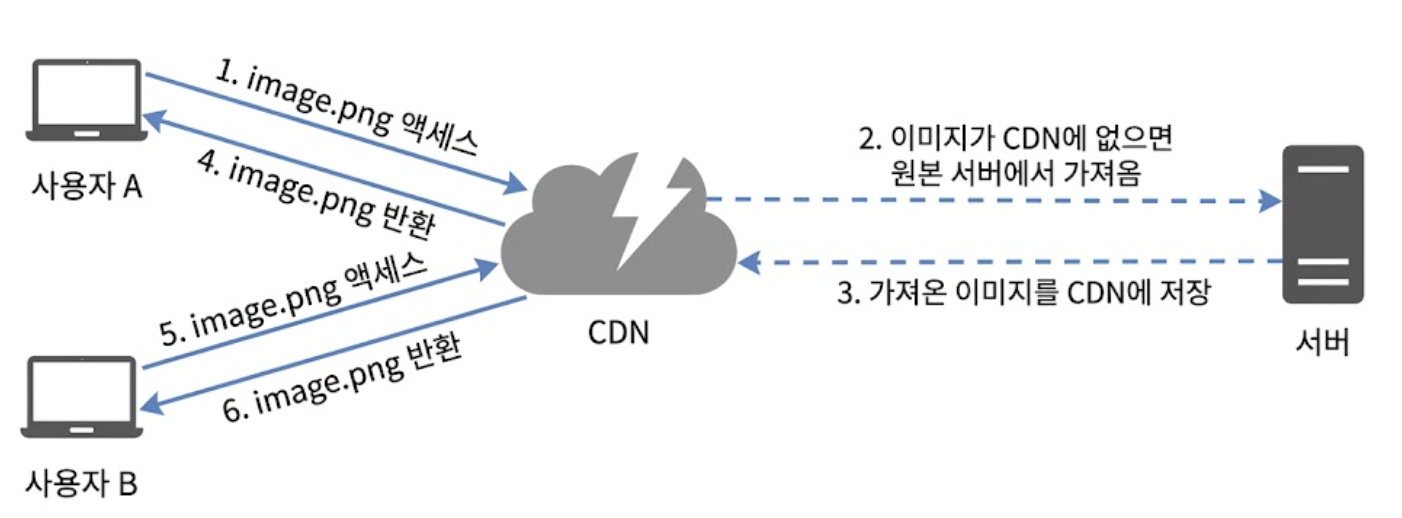
CDN 서버에 데이터가 있느냐 없느냐에 따라 트래픽은 다음과 같이 흐른다.
- 최초 요청 및 Cache Miss
- 사용자 A가 CDN 도메인이 적용된 이미지 URL(image.png)에 접근
- CDN 에지 서버에 해당 이미지가 없다면(Cache Miss), CDN 서버가 직접 원본 서버에 해당 파일을 요청
- 캐싱 및 응답
- 원본 서버가 파일을 CDN 서버로 반환할 때, HTTP 헤더에 해당 파일의 유효 기간을 명시하는 TTL 값을 함께 보냄
- CDN 서버는 이 파일을 메모리/디스크에 캐시하고 사용자 A에게 최종 반환함
- Cache Hit를 통한 초고속 반환
- 이후 다른 사용자 B가 동일한 이미지에 접근하면, CDN 서버는 만료되지 않은 캐시 데이터를 확인하고 원본 서버를 거치지 않고 즉시 반환(Cache Hit)함
<CDN 도입 시 반드시 고려해야 할 사항들>
CDN은 강력한 도구이지만 실제 사용할 때는 비용과 효율성 관점에서 아래 5가지 요소를 반드시 따져봐야 한다.
- 데이터 전송량 기반의 비용 산정
- CDN은 보통 서드파티(Cloudflare, Akamai 등) 서비스로 운영되며, 에지 서버로 들어오고 나가는 데이터 전송량(Data Transfer Output)에 따라 요금이 부과된다.
- 트래픽이 폭발할 때 예상치 못한 비용 폭탄을 맞지 않도록 트래픽 패턴을 미리 예측해야 한다.
- 롱테일 콘텐츠 캐싱의 비효율성
- 자주 쓰이지 않는 콘텐츠까지 캐싱하는 것은 비용 대비 이득이 크지 않다.
- 캐시 히트율(Cache Hit Ratio)이 낮다면 CDN에서 제외하고 원본 서버에서 직접 처리하는 것이 경제적이다.
- 적절한 TTL 설정
- 콘텐츠의 성격에 맞춰 만료 시간을 정교하게 셋팅해야 한다.
- 너무 길면 실시간 데이터 반영이 늦어지고, 너무 짧으면 캐시 미스가 자주 발생해 원본 서버가 부하를 고스란히 받게 된다.
- 원본 서버 직접 복구 대처 방안
- 만일 전 세계 CDN 에지 서버가 일시적으로 먹통이 된다면 CDN 장애를 감지하는 즉시 클라이언트(웹/앱)가 원본 서버로부터 직접 콘텐츠를 다운로드하도록 우회 경로를 구성(fallback)하는 방안이 아키텍처에 반영되어야 한다.
- 캐시를 강제로 비우는 콘텐츠 무효화(Invalidation) 방법
- 수정된 데이터를 즉시 전 세계에 반영해야 할 때, 아래 두 가지 무효화 전략 중 비즈니스 상황에 맞는 방식을 택한다.
- CDN Provider API 활용: 서비스 사업자가 제공하는 퍼지(Purge/Invalidation) API를 호출하여 에지 서버의 캐시를 강제로 삭제
- 오브젝트 버저닝(Object Versioning): URL 뒤에 버전 query string을 붙이거나 파일명 자체를 바꾼다. 예) image.png?v=2
- 수정된 데이터를 즉시 전 세계에 반영해야 할 때, 아래 두 가지 무효화 전략 중 비즈니스 상황에 맞는 방식을 택한다.
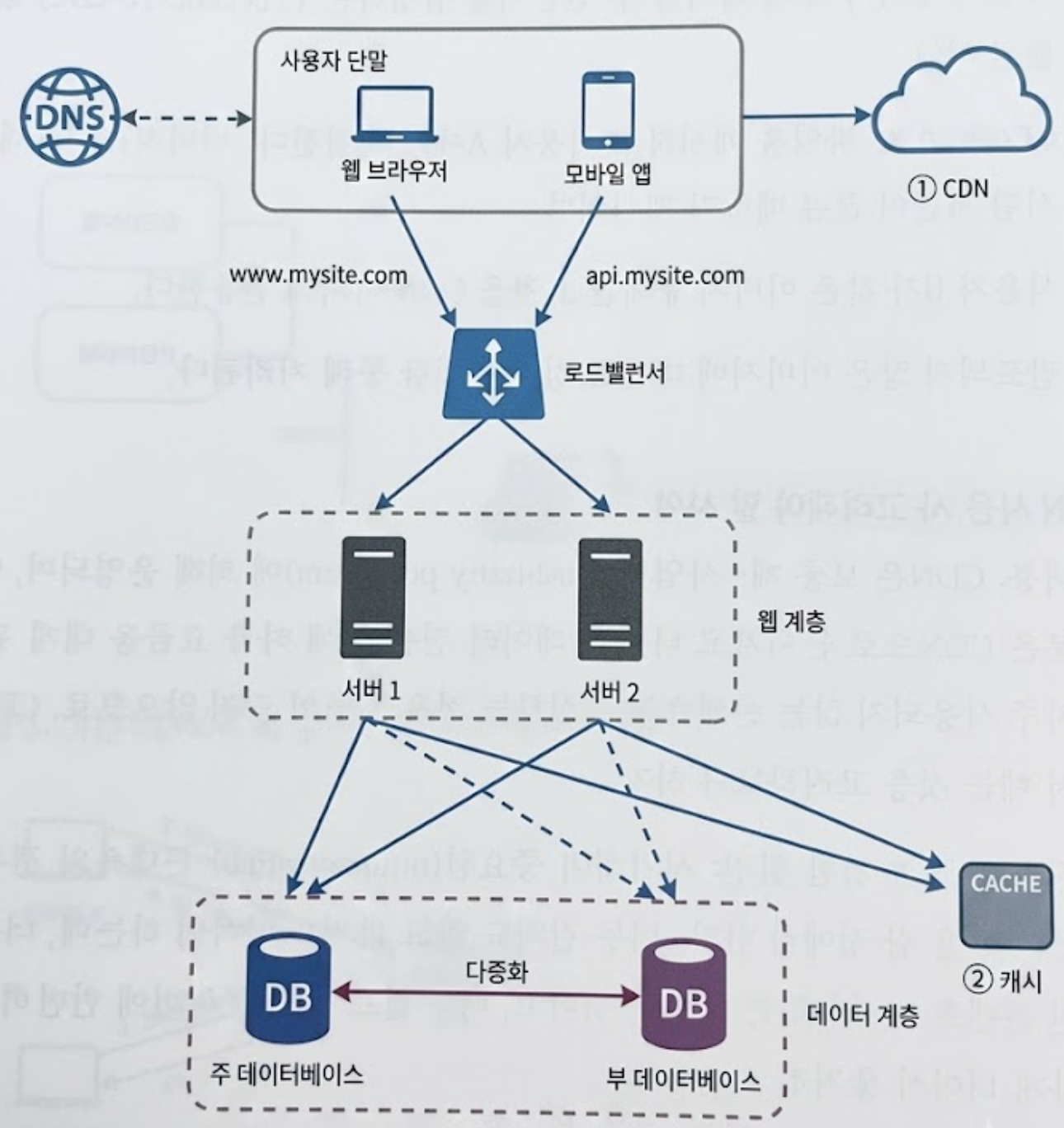
정적 콘텐츠(js, css, 이미지 등)은 더 이상 웹 서버를 통해 서비스하지 않으며, CDN을 통해 제공하여 더 나은 성능을 보장한다.
그리고 캐시가 데이터베이스 부하를 줄여준다.
🚀Deep Dive: 동적 콘텐츠 캐싱
정적 파일만 캐싱하는 줄 알았던 CDN이 어떻게 매번 변하는 동적 콘텐츠(Dynamic Content)까지 최적화할 수 있을까?
AWS CloudFront같은 최신 CDN 솔루션은 단순히 파일을 저장하는 것을 넘어, 캐싱할 수 없는 API 요청이나 가변적 HTML 페이지 같은 동적 콘텐츠 전달 속도도 획기적으로 개선한다.
- 연결 최적화(Persistent Connection)
- 네트워크 통신에서 가장 오랜 시간이 걸리는 작업 중 하나는 TCP Handshake와 TLS/SSL 암호화 연결을 맺는 과정이다.
- CloudFront는 전 세계 사용자 근처의 에지 로케이션과 AWS 내부 원본 서버 간의 전용 네트워크 연결을 항상 ‘최신 유지(Keep Alive)’ 상태로 맺어준다.
- 사용자는 근처 에지까지만 빠르게 연결하면 되므로 전체 지연 시간이 급격히 줄어든다.
- 최적의 네트워크 경로 라우팅(Routing Optimization)
- 일반 인터넷 망은 트래픽 혼잡도에 따라 데이터가 빙빙 돌아가기 일쑤이다.
- CloudFront는 가공되지 않은 동적 요청을 수신하면, 공용 인터넷 망이 아닌 AWS가 보유한 글로벌 사설 전용 광섬유 네트워크 아키텍처를 통해 원본 서버까지 가장 빠르고 안정적인 최적의 경로로 뚫고 지나간다.
- 에지 단에서의 스마트 처리(Edge Computing)
- AWS CloudFront Functions나 Lambda@Edge를 활용하면 query string, cookie, request header의 조건에 따라 사용자 정의 HTTP 응답을 에지 단에서 직접 가공하여 반환할 수 있어 원본 서버가 아예 연산할 필요 조차 없게 만든다.
8. Stateless 웹 계층
Stateless 웹 계층이란 웹 서버가 클라이언트의 상태 정보나 세션 데이터를 자신의 로컬 메모리나 디스크에 저장하지 않는 아키텍처를 말한다.
모든 요청이 완전히 독립적으로 처리되므로, 사용자는 로드밸런서 뒷단의 어떤 웹 서버로 접속하더라도 항상 중단 없이 서비스를 이용할 수 있다.
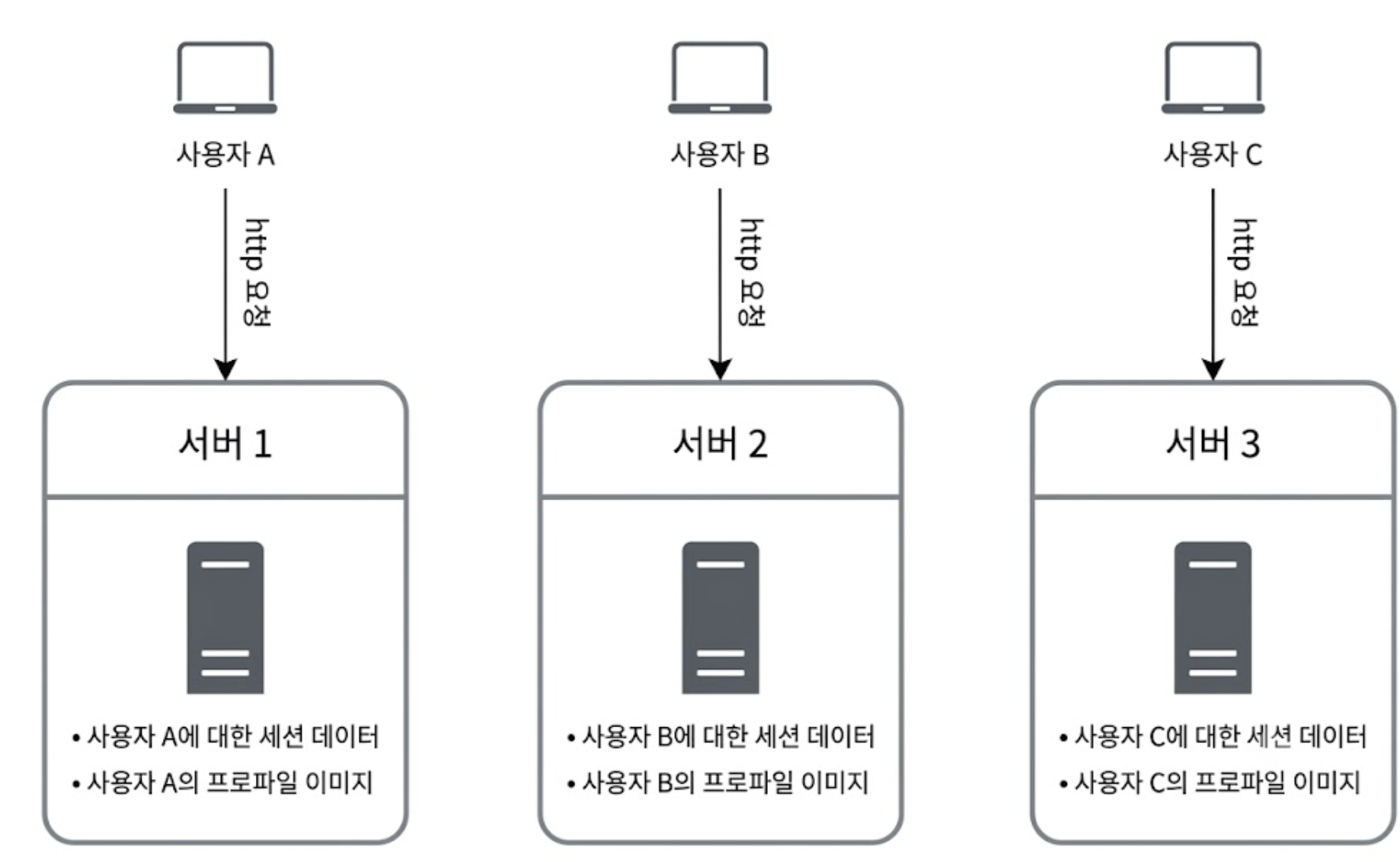
🚨Stateful 아키텍처의 한계
Stateful 아키텍처에서는 특정 사용자의 세션 정보가 ‘서버 1’의 내부 메모리에 종속된다. 이 경우 사용자 A의 다음 요청은 무조건 서버 1로만 가야 인증이 유지된다.
이를 해결하기 위해 로드밸런서가 특정 사용자의 요청을 지정된 서버로만 보내주는 Sticky Session 기능을 제공하지만, 이는 대규모 시스템에서 치명적인 문제를 발생시킨다.
🚀Deep Dive: AWS ELB Sticky Session 의 한계
AWS의 대표적인 로드밸런서인 ELB(Elastic Load Balancing)에서 Sticky Session을 활성화하면 Cookie 기반으로 특정 인스턴스에 트래픽을 묶어둘 수 있어 편리해 보이지만, 규모 확장성 관점에서는 아래와 같은 한계에 부딪힌다.
- 부하 불균형
- 특정 무거운 작업을 수행하는 헤비 유저들이 하나의 서버에 Sticky하게 몰릴 경우, 로드밸런서가 아무리 라운드 로빈으로 트래픽을 쪼개려 해도 특정 서버만 과부하가 걸리는 병목 현상이 일어남
- Auto-Scaling 유연성 상실
- 트래픽이 몰려 자동으로 Scale-out을 하거나, 한가해서 Scale-in을 할 때 인스턴스가 쉽게 제거되지 못함
- 서버를 끄는 순간 해당 서버에 묶인 Sticky하게 묶여있던 수많은 유저의 세션 데이터가 사라지기 때문임
이런 문제를 해결하기 위해서는 세션 정보를 웹 서버 내부가 아닌 물리적으로 분리된 외부 공유 저장소로 일원화해야 한다.
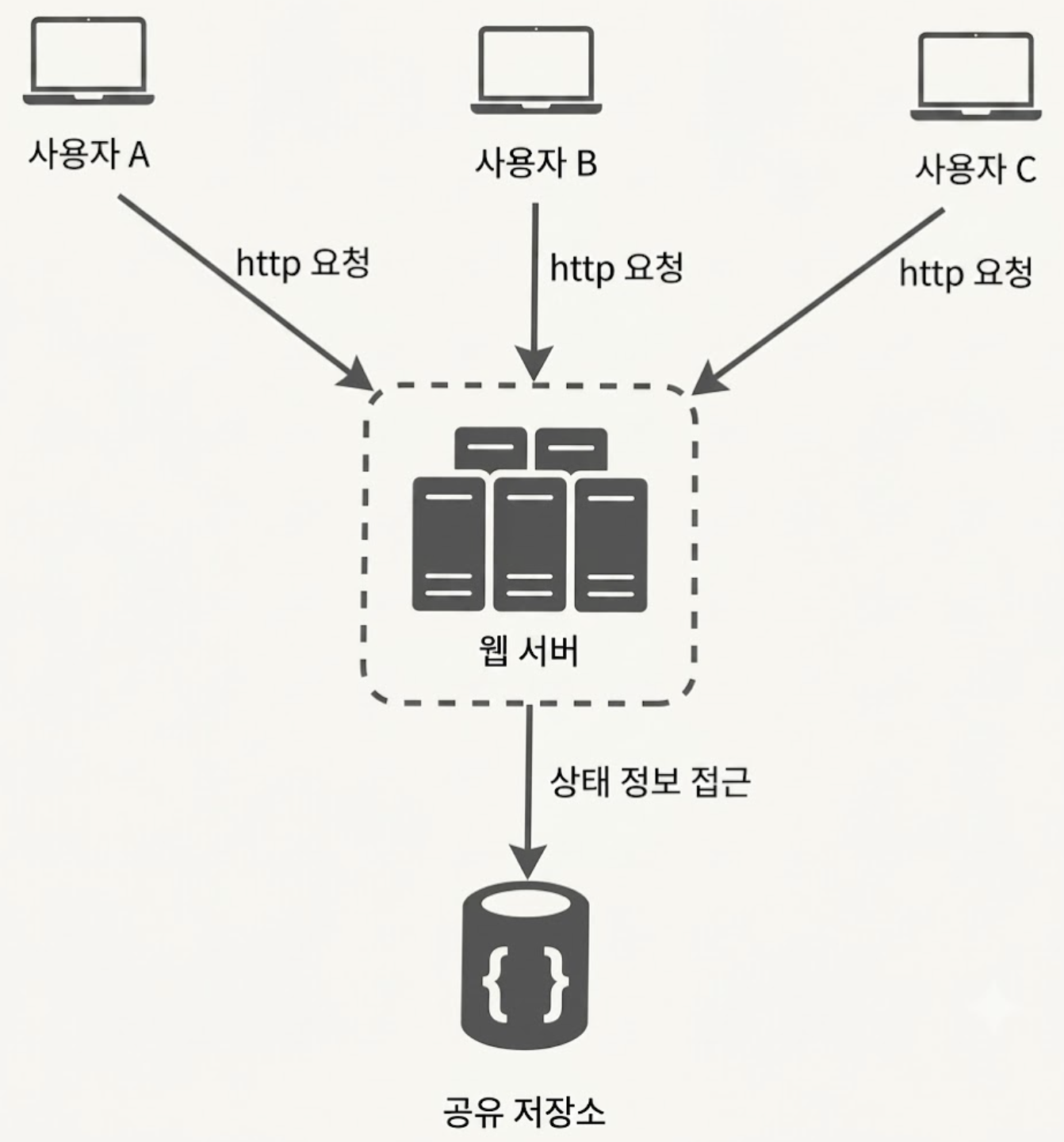
위 구조에서 웹 서버는 상태 정보가 필요한 경우 공유 저장소로부터 데이터를 가져오기 때문에 사용자로부터 HTTP 요청은 어떤 웹서버로도 전달될 수 있다.
이 공유 저장소는 RDBMS일 수도 있고 Memcached/Redis 와 같은 캐시 시스템일 수도 있다.
아래는 Stateless 웹 계층을 갖도록 기존 설계를 변경한 것이다.
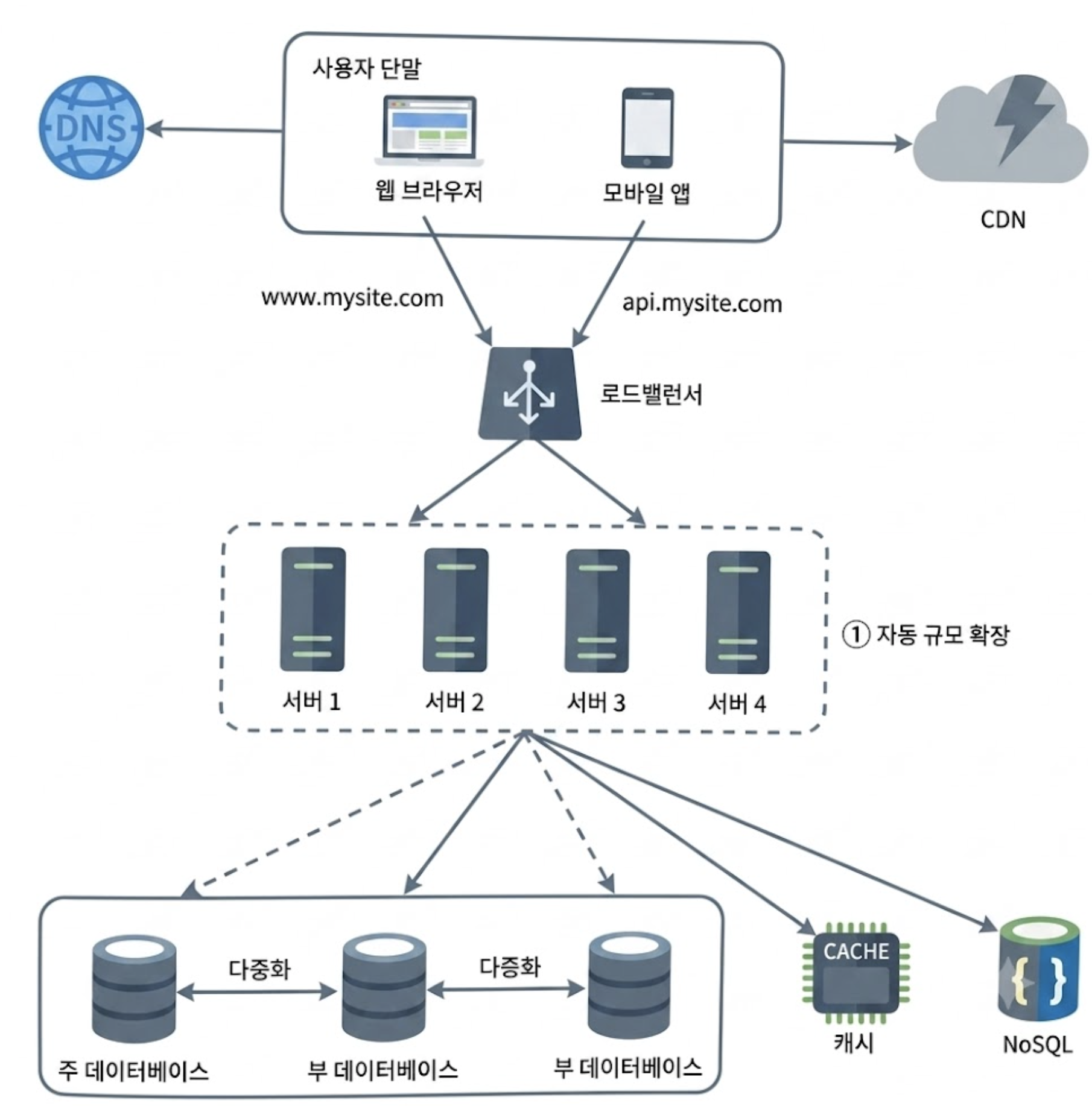
9. 다중 데이터 센터와 지리적 라우팅(GeoDNS)
다중 데이터 센터 아키텍처는 시스템의 가용성을 극대화하고 글로벌 사용자에게 최상의 속도를 제공하기 위해, 전세계 여러 물리적 거점에 동일한 세트의 웹 서버와 데이터 계층 인프라를 동시에 구축하여 운영하는 고도화된 전략이다.
만일 데이터 센터 중 한 곳에 지진이나 재앙이 발생하면, 모든 트래픽은 장애가 없는 정상 데이터 센터로 즉시 자동 우회된다.
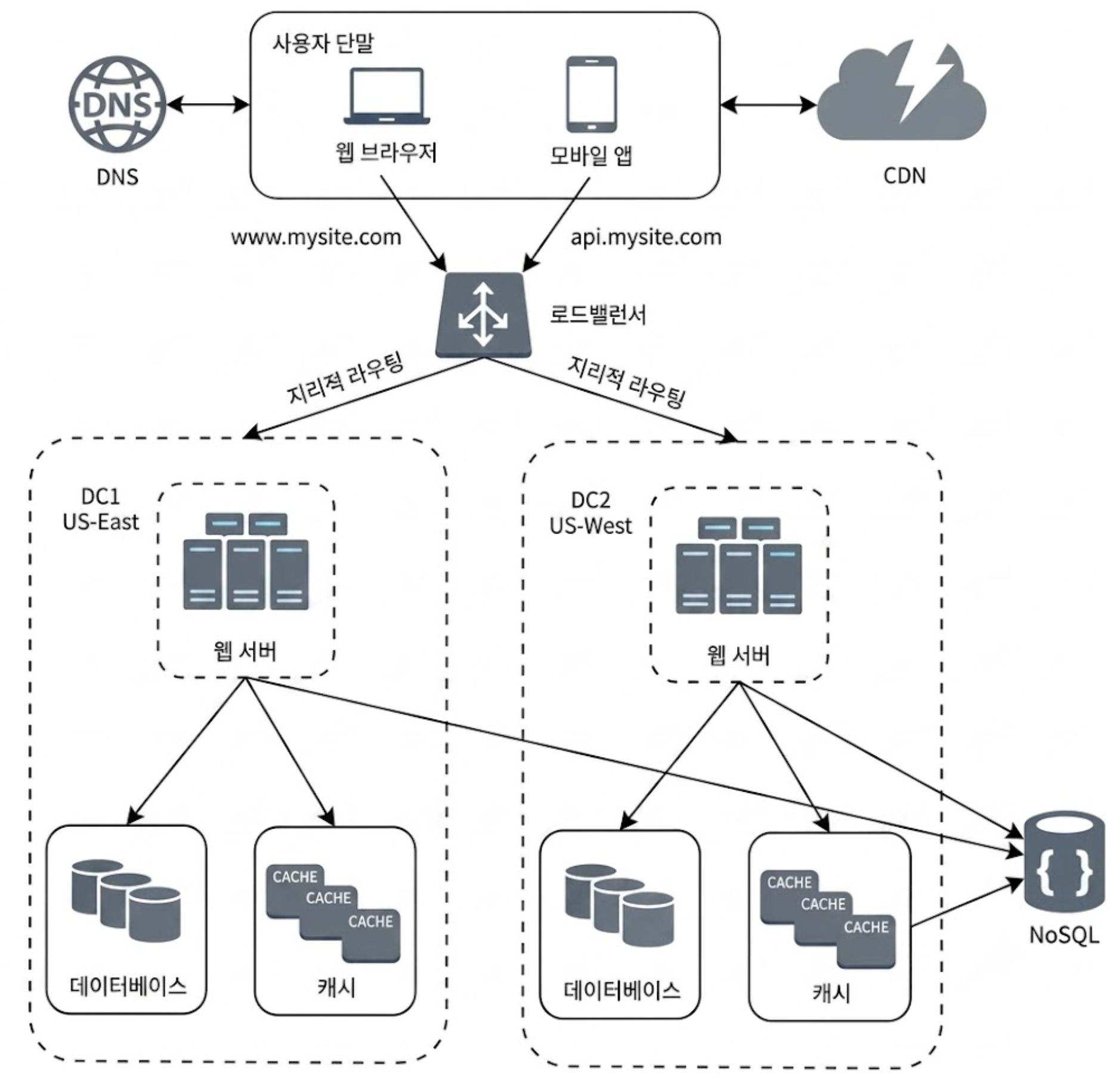
⚠️다중 데이터 센터 구축을 위한 2가지 기술적 난제
다중 데이터 센터 아키텍처가 주는 고가용성을 완벽하게 누리려면 반드시 해결해야 하는 핵심 난제 2가지가 있다.
- 트래픽 우회(Traffic Rerouting)
- 사용자의 요청을 가장 효과적인 데이터 센터로 보내는 방법을 찾아야 한다.
- 이 난제를 해결하는 보편적인 기술이 지리적 라우팅(GeoDNS)이다.
- GeoDNS는 사용자의 IP 주소를 기반으로 현재 위치를 실시간 계산하여, 물리적으로 가장 가까운 데이터 센터의 IP 주소로 트래픽을 안내한다.
- 데이터 동기화
- 만약 데이터 센터마다 서로 독립된 DB를 사용한다고 했을 때 동부 센터에 장애가 발생하여 서부 센터로 트래픽이 우회되었을 때, 서부 센터에는 사용자가 동부에서 작성했던 데이터가 존재하지 않을 수 있다. 이 문제를 막기 위한 보편적인 전략은 데이터를 여러 데이터 센터에 걸쳐 실시간으로 다중화하는 것이다.
🚀Deep Dive: Netflix 로 보는 Active-Active 다중 리전 복제 전략과 데이터 동기화
글로벌 OTT 최강자인 넷플릭스는 전 세계 3개 리전을 동시에 가동하는 Active-Active 다중 리전 아키텍처를 구축하여 데이터 동기화 난제를 해결하였다.
넷플릭스 기술 블로그인 Active-Active for Multi-Regional Resiliency의 핵심 기술 포인트는 아래와 같다.
- 왜 데이터가 누락되는 현상이 발생할까?
- 일반적인 Primary-Replica 기반의 교차 데이터 센터 구조(Active-Passive)나 느슨한 비동기 복제를 사용하면 동부 센터에서 발생한 쓰기 연산이 물리적인 거리 한계 때문에 실시간으로 서부 센터 DB에 동기화되지 못하고 몇 초간의 지연(Lag)이 생긴다.
- 이 찰나의 순간에 동부 데이터 센터가 예기치 않게 다운되어 유저들이 서부 데이터 센터로 강제 우회되면 ‘데이터가 존재하지 않는 현상’을 겪게 된다.
- Apache Cassandra를 활용한 글로벌 다중화
- 넷플릭스는 중앙 집중형 Primary-Replica 구조 대신, 전 세계 데이터 센터가 모두 Primary 서버처럼 동작하는 글로벌 분산 NoSQL 데이터베이스인 카산드라를 도입했다.
- 유저가 전 세계 어느 리전 DB에 데이터를 쓰더라도, 카산드라 고유의 내부 분산 알고리즘을 통해 다른 글로벌 리전의 모든 노드로 데이터가 실시간 교차 전파(Multi-Region Replication)된다.
- 데이터 충돌 해결: LWW(Last-Write-Win) 전략
- 데이터 센터 간 동기화 도중, 아주 미세한 차이로 동일한 데이터에 대한 수정 요청이 동부와 서부에서 동시에 일어난다면 어떻게 일관성을 맞출까?
- 카산드라는 LWW(최종 쓰기 승리) 기법을 사용한다.
- 각 데이터에 기록된 타임스탬프를 정밀하게 비교하여, 가장 나중에 들어온 최종 데이터를 전 세계 데이터 센터의 ‘정답’으로 인정하고 일치시킨다.
덕분에 넷플릭스는 데이터 센터 한 곳이 통째로 파괴되어 GeoDNS가 트래픽을 긴급 우회시켜도, 사용자가 데이터 유실이나 끊김을 전혀 느끼지 못하는 완벽한 글로벌 동기화를 달성하였다.
10. 시스템 간 결합도 낮추기: 메시지 큐
메시지 큐는 메시지의 무손실을 보장하는 비동기 통신을 지원하는 분산 시스템 컴포넌트이다.
메시지 큐에 보관된 메시지를 Consumer가 꺼내서 처리할 때까지 큐 메모리나 디스크에 보존된다. 이를 통해 대규모 시스템에서 서비스 간의 결합도를 낮추고 안정성을 확보할 수 있다.
<Producer와 Consumer의 결합도 완화>
- 비동기 통신: Producer는 시간이 오래 걸리는 작업을 큐에 던지기만 하고 즉시 유저에게 응답 반환
- 장애 격리: Consumer(작업 서버) 프로세스가 일시적으로 다운되거나 점검 중이라도 Producer는 아무런 제약 없이 메시지 발생, 반대로 Producer 서비스가 마비되어도 Consumer는 큐에 쌓여있던 기존 메시지들을 처리함
11. 로그, 메트릭 모니터링 그리고 자동화
- 로그: 대규모 환경에서는 서버마다 로그를 보러 들어갈 수 없으므로, 중앙 집중형 로그 수집 환경(예: ELK 스택, Grafana Loki)을 구축해야 함
- 메트릭: 시스템의 현재 상태를 수치화된 데이터로 수집
- 호스트 메트릭: CPU 사용량, 메모리 잔여량, 디스크 I/O 등 물리적 자원 상태
- 비즈니스 메트릭: 일일 활성 사용자(DAU), 초당 요청 수(RPS), 응답 지연 시간(Latency)
- 모니터링 알림: 수집된 메트릭을 대시보드(Grafana 등)로 시각화하고, 시스템 임계치(예: CPU 80% 이상 지속)를 초과하면 슬랙으로 개발자에게 즉시 경고를 보냄
모니터링 시스템이 메트릭을 감시하다가 설정된 규칙에 따라 인프라를 자동으로 제어한다.
예를 들어 트래픽이 폭발하여 CPU 부하가 걸리면 자동으로 웹 서버 인스턴스를 늘리고, 새벽 시간대에 트래픽이 한산해지면 서버를 자동으로 줄여 인프라 비용을 아껴준다.
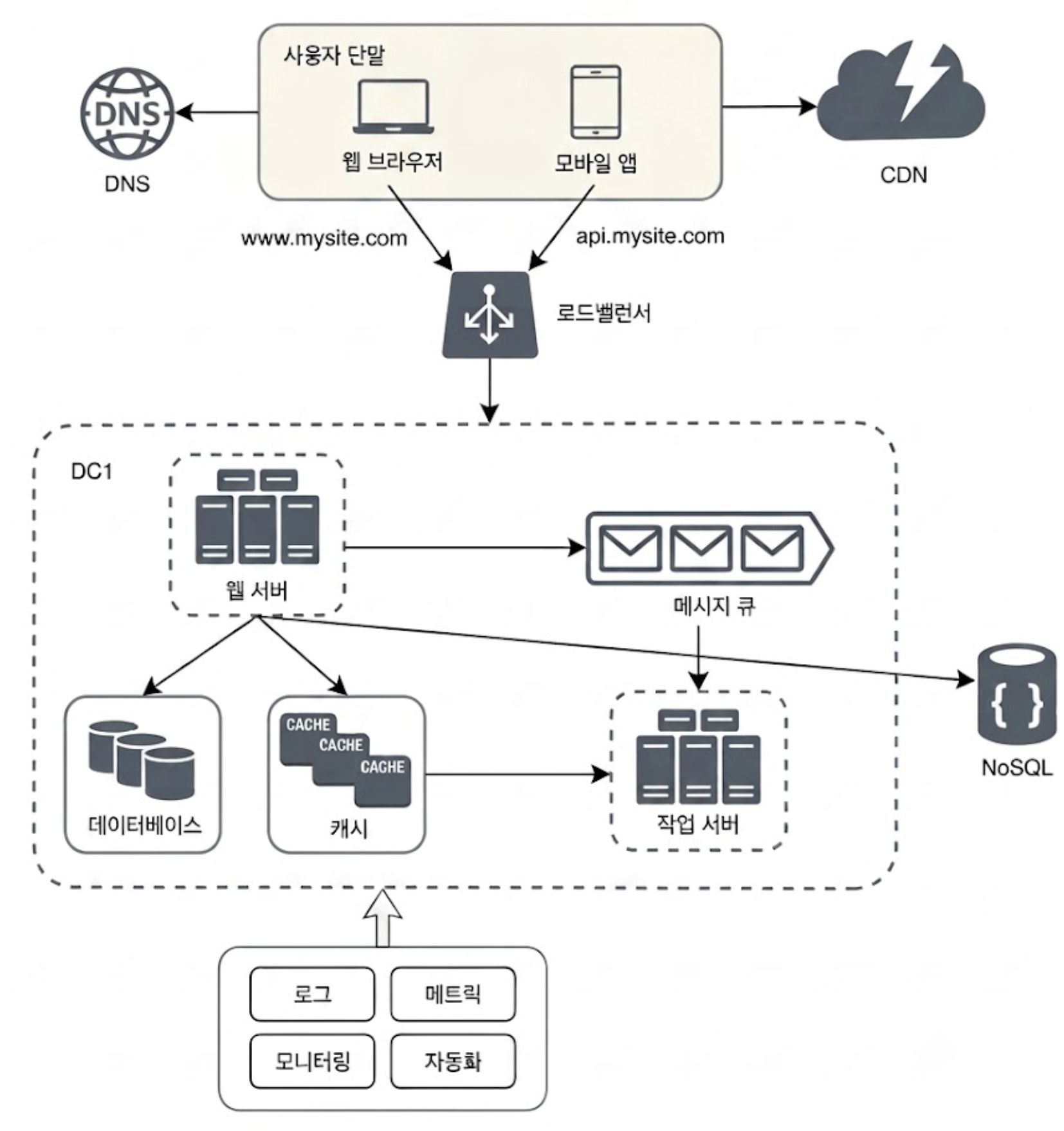
12. DB 샤딩 도입
DB 샤딩은 대규모 데이터 계층을 확장하기 위해, 하나의 거대한 DB를 ‘샤드(Shard)’라고 부르는 작은 단위의 독립된 DB 서버들로 분할하여 저장하는 기술이다.
모든 샤드는 동일한 테이블 구조(스키마)를 공유하지만, 각 샤드에 보관되는 데이터 간에는 서로 중복되거나 겹치는 부분이 없다.
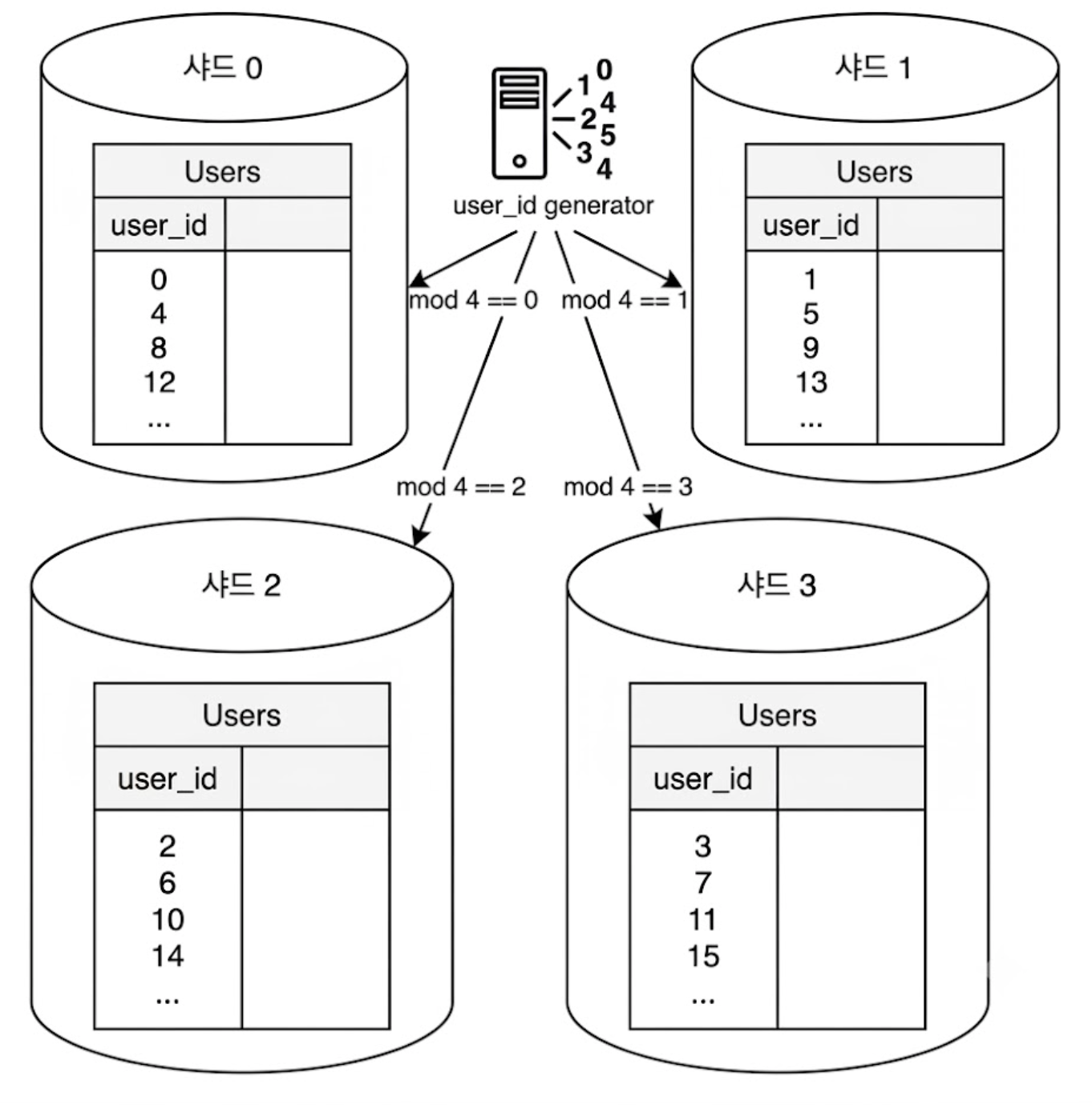
<샤딩 키의 중요성>
샤딩을 구현할 때 가장 중요한 것은 샤딩 키(파티션 키)를 무엇으로 정하느냐이다.
샤딩 키는 데이터를 어떤 샤드 서버에 저장할지 결정하는 기준 컬럼(예: user_id % 4 연산을 통해 0~3번 샤드로 분배)이다.
데이터가 모든 샤드에 수학적으로 균등하게 분산되도록 설계하는 것이 핵심이다.
⚠️샤딩 도입 시 반드시 해결해야 할 3가지 난제
샤딩은 데이터 계층의 무한 확장을 가능하게 하지만, 분산 시스템 고유의 난제를 치르게 한다.
12.1. 데이터의 재샤딩(Resharding)
- 원인: 특정 샤드의 데이터 성장 속도가 너무 빨라 공간이 먼저 소진되거나, 샤드 간 데이터 분포가 균등하지 못해 특정 샤드만 빠르게 데이터가 차는 상황이 발생할 수 있다.
- 해결책: 이 현상이 발생하면 샤드 배치 함수(해시 함수)를 수정하고 기존 데이터를 새로운 샤드 배열에 맞춰 다시 대규모 Data migration을 진행해야 한다. 이 비용을 최소화하기 위해 향후 배울 안정 해시(Consistent Hashing) 기법을 필수로 도입해야 한다.
안정 해시에 대해서는 추후 다룰 예정입니다.
12.2. 유명인사 문제(Celebrity)
- 원인
- 특정 샤드 서버에 질의와 트래픽이 비정상적으로 집중되어 서버가 터지는 현상이다. 핫스팟 문제라고도 한다.
- 예를 들어 SNS 서비스에서 팔로워 수천만 명인 유명인의 데이터가 샤드 2번에 할당되어 있다면, 해당 인물이 글을 쓴 순간 수많은 팬의 읽기/쓰기 연산이 2번 샤드로만 집중되어 과부하가 걸린다.
- 해결책: 해당 유명인사 유저들에게만 전용 샤드를 독립적으로 떼어주거나, 유명인사 관련 데이터를 더 잘게 쪼개는 특수한 파티셔닝 정밀 설계가 필요하다.
12.3. 조인과 비정규화
- 원인: 하나의 물리적 DB 안에서는 자유롭게 테이블 간 JOIN 연산이 가능했지만, 데이터가 여러 샤드 서버로 물리적으로 찢어지고 나면 여러 샤드에 걸린 데이터를 단 한 번의 쿼리로 조인하는 것은 사실상 불가능해진다.
- 해결책: 분산 네트워크 조인은 성능을 파괴하므로, 대규모 시스템에서는 DB를 의도적으로 비정규화하여 하나의 테이블 안에 필요한 정보를 중복으로 저장하여, 각 샤드 내부에서 단일 질의만으로 데이터를 조회할 수 있도록 데이터 구조를 전면 재설계해야 한다.
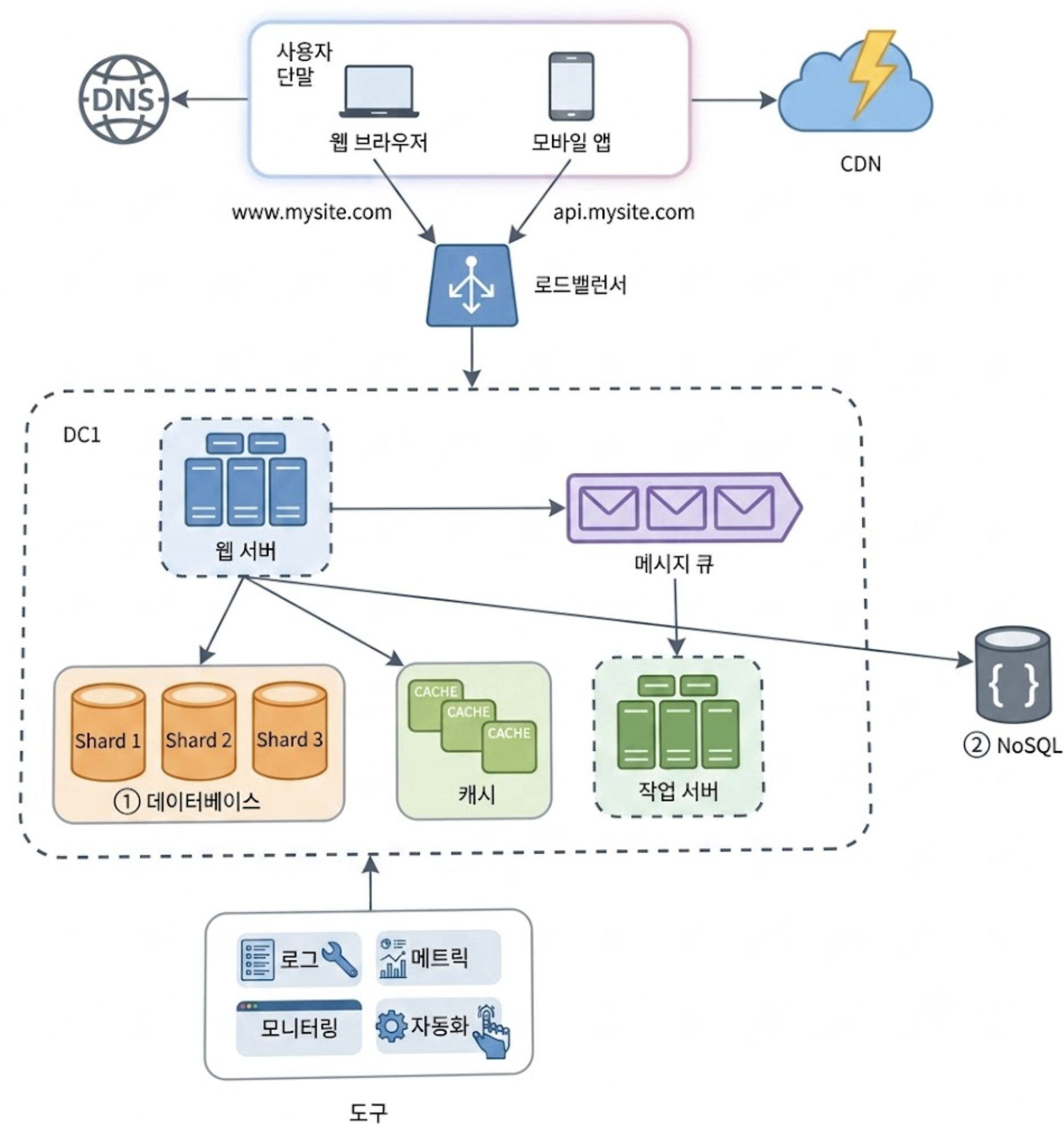
아래는 데이터베이스 샤딩이 적용된 아키텍처이다. 더불어 데이터베이스를 줄이기 위해 굳이 RDBMS가 요구되지 않는 기능들은 NoSQL로 이전하였다.
요약
시스템 규모 확장을 위한 설계 체크 리스트
- 웹 계층은 Stateless로 유지
- 서버 로컬 메모리에 세션이나 유저 정보를 귀속시키지 말 것
- 부하 분산과 무한 Scale-out, 유연한 Auto-Scaling의 대전제임
- 상태 정보는 분산 Key-Value NoSQL인 Redis 같은 외부 공유 저장소에 위임
- 인프라의 모든 계층에 다중화(Replication) 도입
- 웹 서버는 로드밸런서 뒷단에 병렬 배정하고, DB는 읽기 전용 사본과 쓰기 전용 원본으로 분리하여 SPOF(단일 장애 지점)을 완전히 제거
- 글로벌 유저를 위한 여러 데이터 센터와 CDN 활용
- 정적 파일은 전 세계 에지 서버에 뿌려주는 CDN을 통해 원본 서버 부하를 줄임
- GeoDNS 기반의 지리적 라우팅 난제를 해결하여 사용자를 가장 가까운 다중 데이터 센터로 안내하고, 데이터 센터 간 동기화 체계를 굳건히 해야 함
- 데이터 계층의 한계를 샤딩과 NoSQL로 돌파
- 단일 RDBMS의 용량과 성능 한계가 오면 데이터를 고르게 분산할 수 있는 샤딩 키를 선정하여 Scale-out 을 함
- 굳이 RDBMS 가 필요 없는 정형화되지 않은 대량의 데이터는 NoSQL로 이관하여 부하를 분산
- 메시지 큐로 서비스 간 결합도를 느슨하게 유지
- 시간이 오래 걸리거나 무거운 작업들은 메시지 큐를 통해 비동기 처리
- Producer와 Consumer의 결합도가 낮아져 한쪽 시스템이 다운되어도 전체 서비스가 마비되지 않는 탄력성을 얻게 됨
- 모니터링 자동화
- 중앙 집중형 로그 수집과 메트릭 모니터링을 통해 시스템의 이상 징후를 실시간 감시
- 트래픽에 맞춰 Auto-Scaling 자동화는 필수
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 알렉스 쉬 저자의 가상 면접 사례로 배우는 대규모 시스템 설계 기초를 기반으로 스터디하며 정리한 내용들입니다.
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- 책에 나온 링크들 모음
- 캐시 전략 심층 분석: Codeahoy - Caching Strategies and How to Choose the Right One
- 동적 콘텐츠 가속 원리: AWS 공식 문서 - CloudFront Dynamic Content Delivery
- 로드밸런서 Sticky Session: AWS 공식 문서 - Elastic Load Balancing Sticky Sessions
- 글로벌 데이터 동기화 사례: Netflix Tech Blog - Active-Active for Multi-Regional Resiliency
