Architecture(2) - 대규모 지표 모니터링 및 경보 시스템 설계 아키텍처
in DEV on Architecture System-design Time-series-database Tsdb Prometheus Influxdb Kafka 대규모시스템설계 모니터링시스템 시계열데이터베이스 카프카
- 1. 요구사항 정의
- 2. 시계열 데이터 모델 및 저장소 아키텍처
- 3. 상세 설계 1: 지표 수집 및 전송 파이프라인 확장 전략
- 4. 상세 설계 2: 질의 서비스
- 5. 경보 및 시각화 시스템
- 4. 마무리
- 5. 최종 다이어그램 및 요약
- 참고 사이트 & 함께 보면 좋은 사이트
수많은 서버와 마이크로 서비스로 구성된 대규모 인프라 환경에서 모니터링 시스템은 매우 중요하다.
시스템에 문제가 발생했을 때 즉각적으로 경보를 울려 대형 장애를 막아주고, 서비스가 안정적으로 운영되고 있는지 시각화해 주기 때문이다.
여기서는 대형 IT 업체에서 내부적으로 사용하는 것과 유사한 서비스를 설계해본다.
- Datadog
- influxdb
- NewRelic
- Nagios
- Prometheus
- MUNIN
- Grafana
- graphite
1. 요구사항 정의
- 시스템 타깃
- Q: 시스템의 고객은 누구인가? 회사 내부에서 사용하는 시스템인가, 아니면 Datadog처럼 제 3자 SaaS 제품을 설계하는 것인가?
- A: 회사 내부에서 엔지니어들이 사용할 사내 인프라 모니터링 시스템이다.
따라서 범용적인 멀티테넌시(Multi-tenancy) 기능보다 우리 회사의 대규모 인프라를 안정적이고 비용 효율적으로 처리하는데 집중한다.
- 모니터링할 지표의 종류
- Q: 어떤 지표들을 수집하는가? 에러로그나 비즈니스 매출 지표로 이 시스템에서 처리해야 하는가?
- A: 운영 지표만 수집한다.
CPU 부하, 메모리 사용률부터 RPS, 웹 서버 프로세스 개수, 메시지 큐의 대기량 같은 고차원 지표가 대상이다.
회사의 매출같은 사업 지표나 에러 로그 수집, 분산 시스템 추적은 설계 범위가 아니다.
- 수집 데이터 규모
- Q: 이 시스템에서 모니터링해야 할 인프라의 규모는 어느 정도인가?
- A: 일간 능동 사용자 수(DAU)는 1억 명 기준이다.
인프라는 약 1,000개의 서버 풀로 구성되어 있으며, 풀마다 100개의 서버 하드웨어가 존재하므로 관리 대상 장비는 총 100,000대이다.
서버 한 대당 100개의 운영 지표를 수집한다고 가정하면 시스템이 추적하고 관리해야 하는 지표의 총 개수는 약 1,000만 개(100 지표 * 100 서버 * 1,000 서버 풀)에 달한다.
- 데이터 수명 주기 및 해상도 변환 정책
- Q: 지표 데이터의 최종 보관 기간은 얼마이며, 저장 공간을 아끼기 위해 데이터의 해상도(Resolution)를 낮추어 보관해도 되는가?
- A: 전체 데이터 보관 기간은 1년이다. 데이터 보관 비용을 최적화하기 위해 시간이 지남에 따라 해상도를 점진적으로 낮추는 정책을 채택한다.
- 최근 7일: 수집된 원본 데이터를 그대로 보관
- 7일 이후~30일: 데이터를 1분 단위로 요약(집계)하여 보관
- 30일 이후~1년: 데이터를 다시 1시간 단위로 다시 요약하여 보관
- 알림 발송 채널 범위
- Q: 시스템 장애나 이상 징후 감지 시 어떤 채널로 경보를 보내야 하는가?
- A: 엔지니어가 즉시 인지할 수 있도록 이메일, SMS, PagerDuty, 그리고 외부 시스템과 연동 가능한 HTTPS 서비스 엔드포인트(Webhook)를 기본적으로 지원해야 한다.
멀티테넌시(Multi-tenancy)
하나의 시스템을 여러 고객(테넌시)이 함께 나누어 쓰는 아키텍처
💡’1분 단위 데이터로 변환한다’의 의미는 무엇일까?
시계열 데이터의 다운샘플링(Downsampling)이라고 한다.
예를 들어 수집 에이전트가 특정 서버의 CPU 사용량을 10초에 한 번씩 측정한다고 하면 1분 동안 총 6번의 데이터가 쌓이게 된다.
- 수집된 원본 데이터(10초 주기): [50%, 55%, 65%, 70%, 60%, 60%] -> 총 6개 로우(Row) 저장
7일이 지나면 이 6개의 row를 모두 들고있을 필요성이 떨어진다. 대시보드로 3주 전 기록을 조회할 때는 10초 단위의 미세한 떨림보다는 전체적인 흐름만 보면 되기 때문이다.
따라서 1분이 지나는 시점에 이 6개의 값을 하나의 대표값으로 저장한다.
- 1분 단위 데이터로 변환 후: [평균값: 60%] 또는 [최댓값: 70%] -> 단 1개의 로우(Row)로 압축
1.1. 기능적 요구사항
- 다양한 레이어의 지표 수집
- 인프라 저수준 지표: CPU 사용률, 메모리 사용량, 디스크 사용량 등 OS 레벨 데이터 수집
- 애플리케이션 고수준 지표: RPS, 웹 서버 프로세스 개수, 메시지 큐 내 대기 메시지 수 등
- 1,000개 서버풀 * 풀 당 100대 서버 = 총 100,000대의 장비
- 장비당 100개의 운영 지표를 동시 수집하며 총 10,000,000개의 실시간 지표 트래픽을 누락없이 소화
- 기간별 데이터 해상도 자동 변환(다운샘플링)
- 실시간성 보장: 수집 직후 최근 7일 동안은 가공되지 않은 고해상도 원본 데이터 보관
- 1차 요약: 저장소 효율을 위해 7일이 지난 데이터는 1분 단위로 압축하여 30일간 보관
- 장기 보관: 30일이 지난 데이터는 1시간 단위로 최종 압축하여 총 1년 동안 보관
- 멀티 채널 경보
- 지정된 임계치(예: 디스크 사용량 > 90%) 초과 시 이상 징후 즉시 감지
- 이메일, SMS, PagerDuty로 경보 발송
- 사내 타 시스템과의 유연한 연동을 위해 HTTPS 서비스 엔드포인트(Webhook) 기능 제공
1.2. 비기능 요구사항
- 규모 확장성
- 인프라가 증설되면서 밀려드는 지표의 수와 실시간 경보 연산의 양에 맞춰 시스템이 Scale-out 될 수 있어야 함
- 낮은 응답 지연
- 대시보드와 경보를 신속히 처리 가능할 수 있도록 질의에 대한 낮은 응답 지연을 보장
- 안전성
- 높은 안정성을 제공하여 중요 경보를 놓치지 않도록 함
- 유연성
- 기술 트렌드는 빠르게 변화한다. 향후 새로운 데이터 수집 도구나 데이터 파이프라인 소프트웨어를 손쉽게 교체할 수 있도록 컴포넌트 간의 결합도가 낮은 유연한 아키텍처 구조를 가져야 함
2. 시계열 데이터 모델 및 저장소 아키텍처
대규모 인프라 환경에서 발생하는 수많은 메트릭을 유실 없이 처리하기 위해서는 데이터 모델과 저장소 계층의 기술적 타당성을 먼저 검토해야 한다.
모니터링 시스템은 일반적인 CRUD 중심의 애플리케이션과 상이한 데이터 접근 패턴을 가진다.
RDBMS의 한계를 분석하고, 시계열 데이터베이스(TSDB)를 채택해야 하는 아키텍처적 근거에 대해 알아본다.
2.1. 모니터링 시스템의 5가지 컴포넌트
지표 모니터링 파이프라인은 기능과 책임에 따라 아래 5가지 컴포넌트로 구성된다.
- 데이터 수집
- 호스트, 컨테이너, DB, 메시지 큐 등 모니터링 대상 자원으로부터 메트릭 데이터를 생성하고 수집
- 데이터 전송
- 수집된 지표 데이터를 지연없이 모니터링 스토리지로 유입시키는 데이터 파이프라인 레이어
- 데이터 저장소
- 고빈도로 유입되는 시계열 데이터를 효율적으로 압축하여 메모리 및 디스크에 적재하는 영속성 스토리지 계층
- 경보
- 인입되는 실시간 데이터를 지속적으로 연산/평가하여 임계치 초과 등 이상 징후 감지 시 이메일, SMS 등으로 이벤트를 라우팅
- 시각화
- 수집된 지표를 차트나 그래프 형태로 렌더링하여 전체 인프라 상태를 직관적으로 관측할 수 있도록 돕는 대시보드(예: Grafana) 컴포넌트
2.2. 시계열 데이터 모델과 라인 프로토콜(Line Protocol)
모니터링 시스템이 처리하는 지표 데이터는 시간의 흐름에 따라 순차적으로 누적되는 시계열 데이터(Time-Series Data) 모델을 따른다.
프로메테우스(Prometheus) 및 InfluxDB 등의 메인스트림 솔루션은 상호 운용성을 확보하기 위해 텍스트 기반의 표준 포맷인 라인 프로토콜(Line Protocol)을 준수한다.
# Line Protocol 데이터 포맷 예시
CPU.load host=webserver01,region=us-west 1613707265 50
CPU.load host=webserver01,region=us-west 1613707275 62
행의 마지막에 기록된 CPU 부하 수치의 평균을 구하면 되는 것이다.
시계열 레코드는 내부적으로 아래 3가지 속성으로 가공되어 저장소에 적재된다.
| 이름 | 자료형 | 아키텍처적 역할 및 특징 |
|---|---|---|
| 지표 이름 | 문자열(String) | 측정 대상 자체를 식별하기 위한 고유 명칭 예: CPU.load, memory.usage |
| 태그/레이블 집합 | <Key:Value> 쌍의 리스트(List) | 다차원 분석, 필터링 및 그룹화를 위한 메타데이터셋 예: host=webserver01 |
| 지표 값 및 그 타임스탬프의 배열 | <Value, Timestamp> 쌍의 배열(Array) | Epoch 시간대별 실제 측정 수치 데이터의 시퀀스 엔트리 |
💡데이터 구조 관점에서의 List와 Array를 채택한 이유
지표 모델에서 메타데이터는 List로, 실제 수치 데이터는 Array 구조로 정의하는 것은 메모리 및 디스크 I/O 효율을 극대화하기 위함이다.
- 태그/레이블 집합 → List
- 배포 환경이나 인프라 토폴로지에 따라 태그 속성은 동적으로 추가/삭제될 수 있어야 하므로 크기가 가변적임
- 따라서 요소의 삽입과 제거가 자유롭고 크기 확장이 유연한 동적 리스트 구조가 적합
- 지표 값 및 타임스탬프 → Array
- 타임스탬프와 지표 값은 정형화된 고정 크기의 데이터가 시간순으로 인입됨
- 이를 메모리상에서 연속된 공간(Array)으로 고정 배치해야만 특정 시간 범위를 스캔하는 Range Query 시 Disk Seek Time을 줄이고 순차 읽기 성능을 최적화할 수 있음
- 연속된 숫자형 데이터 배열은 압축 알고리즘을 적용하기에도 훨씬 유리함
2.3. 데이터 접근 패턴
지표 모니터링 시스템이 처리해야 하는 워크로드는 극단적인 I/O 비대칭성을 가진다.
- 압도적인 쓰기 중심 워크로드
- 수만 대의 호스트와 컨테이너가 10초~1분 주기로 지표를 끊임없이 밀어넣기 때문에, 시스템의 인입 쓰기 트래픽은 상시 높은 수준의 고점을 유지한다.
- 시스템 리소스의 대부분은 이 대량의 쓰기 적재 처리에 할당된다.
- 간헐적인 읽기 스파이크 워크로드
- 읽기 연산은 상시 균등하게 발생하지 않는다.
- 경보 시스템이 매 분마다 평가 규칙을 실행하거나, 대시보드를 일제히 새로고침하는 시점에만 일시적으로 읽기 요청이 급증(Bursty Spike)하는 패턴을 보인다.
따라서 상시 몰아치는 대용량 쓰기 성능을 최우선으로 받아내면서, 간헐적인 대량 읽기 요청이 스토리지 엔진의 쓰기 파이프라인을 블로킹하지 않도록 I/O 격리 및 버퍼링 구조를 반드시 확보해야 한다.
2.4. 범용 저장소의 한계와 TSDB(Time-Series Database) 채택 근거
데이터 접근 패턴 및 시계열 연산 특성으로 인해 RDBMS나 범용 NoSQL은 대규모 환경에서 아래와 같은 기술적 임계점에 직면한다.
- RDBMS의 한계
- ‘시계열 데이터의 지수 이동 평균값’같은 연속성 기반의 윈도우 연산을 SQL로 처리할 경우 쿼리 복잡도가 급격히 상승하며 실행 계획 최적화가 어렵다.
- 또한 다차원 필터링을 위해 레이블마다 B-Tree 인덱스를 생성하면, 대량의 쓰기 작업 시 인덱스 페이지 분할 및 갱신 오버헤드로 인해 스토리지 쓰기 성능이 급격히 저하된다.
- 범용 NoSQL(Cassandra, Bigtable 등)의 한계
- Scale-out을 통해 대용량 데이터를 수용할 수 있지만, 효과적인 시계열 질의(Range Scan 등)를 지원하려면
내부 컬럼 패밀리 레이아웃에 최적화된 고도의 스키마 설계가 강제된다. - 운영 공수와 인프라 관리 비용이 대폭 증가하는 단점이 있다.
- Scale-out을 통해 대용량 데이터를 수용할 수 있지만, 효과적인 시계열 질의(Range Scan 등)를 지원하려면
- 시계열 데이터베이스(TSDB)의 최적화 구조
- InfluxDB나 프로메테우스 같은 전용 TSDB는 쓰기 최적화된 로그 구조 스토리지 엔진(LSM-Tree 변형 아키텍처)과 인메모리 캐시 계층을 결합하여 대량 인입 트래픽을 효율적으로 소화한다.
- 8 CPU 코어와 32GB RAM을 갖춘 단일 InfluxDB 노드 환경에서도 초당 250,000회의 쓰기 연산을 안정적으로 처리하도록 벤치마킹되어 있다.
- InfluxDB는 레이블 기반의 신속한 데이터 질의를 위해 레이블별로 인덱스를 구축한다.
컬럼 패밀리(Column-Family) 레이아웃
구글의 Bigtable이나 아파치 Cassandra같은 와이드 컬럼 스토어(Wide-Column Store) 데이터베이스가 데이터를 디스크에 물리적으로 정렬하고 저장하는 구조를 말한다.
행(Row) 중심으로 데이터를 모아 저장하는 RDBMS와 달리, 컬럼 패밀리 데이터베이스는 행 키(Row Key)를 기준으로 데이터를 정렬한 뒤, 그 내부에서 연관된 컬럼들을 그룹(Column Family) 단위로 묶어서 디스크에 연속적으로 저장한다.
시계열 데이터에 최적화된 저장소 시스템들은 아래와 같다.
- OpenTSDB
- 분산 시계열데이터베이스지만 하둡과 HBase에 기반하고 있어서 하둡/HBase 클러스터를 구성하고 운영해야 하므로 복잡
- MetricsDB: X에서 사용 중
- Timestream: 아마존에서 출시
DB-engines에 따르면 시장에서 가장 인기 있는 시계열 데이터베이스 2개는 InfluxDB 와 프로메테우스이다.
핵심은 각 레이블이 가질 수 있는 값의 Cardinality가 낮아야 한다는 것이다.
💡시계열 DB 가용성을 결정짓는 인덱스 Cardinality 관리
시계열 DB는 레이블 단위의 고속 필터링을 지원하기 위해 내부적으로 역인덱스(Inverted Index)를 구성하며, 이 인덱스는 빠른 쿼리 응답 속도를 위해 주로 메모리에 상주한다.
따라서 메타데이터의 카디널리티(고유값의 수) 제어가 전체 시스템 가용성의 핵심 지표가 된다.
- 낮은 카디널리티:
region,zone,env등 고유값의 범위가 명확히 한정된 메타데이터 유형으로, 인덱스 엔트리의 크기가 예측 가능한 범위 내에서 안전하게 유지된다. - 높은 카디널리티:
user_id,uuid처럼 거의 무한대에 가까운 고유값을 가지는 유형이다.
만일 지표의 태그 정보로 user_id나 매 요청마다 새로 생성되는 임의의 식별 문자열을 포함할 경우, 시계열 DB 내부의 인덱스 엔트리가 기하급수적으로 증가하는 시계열 폭발(Time-Series Explosion) 현상이 발생한다.
이는 OOM 예외를 유발하여 DB 전체 노드를 다운시키는 치명적인 아키텍처적 결함으로 이어진다.
따라서 모니터링 시스템의 태그/레이블을 반드시 카디널리티가 낮은 인프라 식별자 위주로 설계해야 한다.
2.5. 개략적 설계안
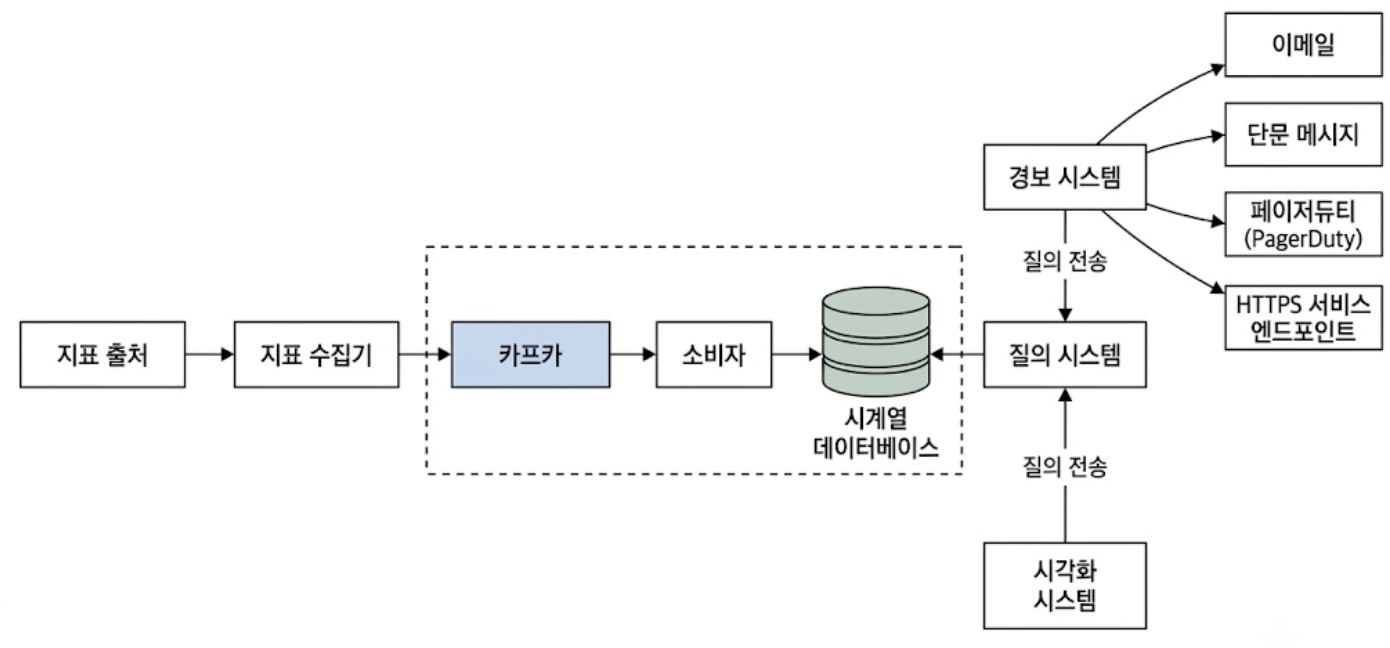
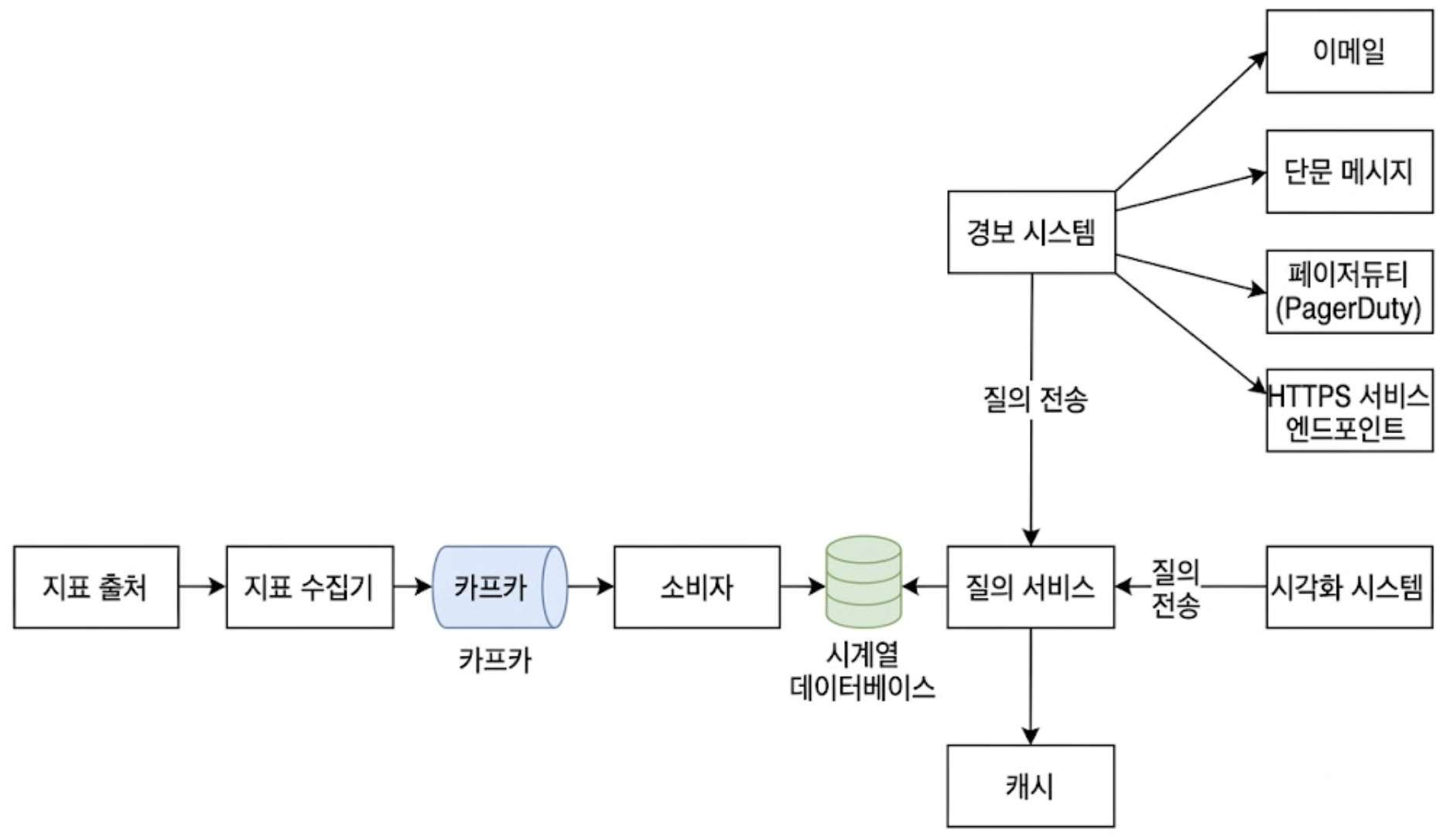
앞서 정의한 컴포넌트 간의 책임 분리와 데이터 흐름을 반영한 시스템 개략 설계안은 아래와 같다.
지표의 수집부터 영속화, 소비 레이어가 명확히 격리된 구조를 가진다.
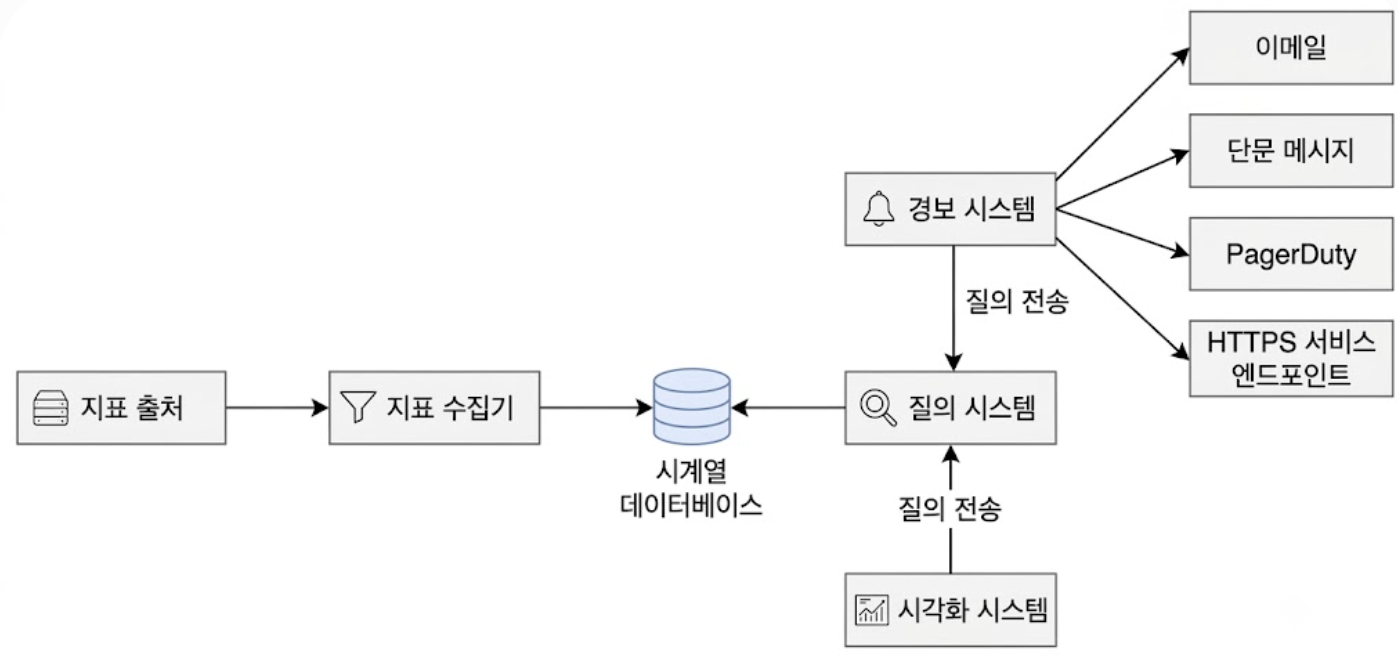
- 지표 출처
- 애플리케이션 서버, SQL DB, 메시지 큐 등 원시 메트릭 데이터를 생성하는 인프라 컴포넌트
- 지표 수집기
- 지표 출처로부터 원시 데이터를 폴링하거나 수신하여 시계열 데이터 포맷으로 정돈하는 게이트웨이 역할
- 시계열 데이터베이스(TSDB)
- 파이프라인을 통해 들어오는 메트릭 데이터를 압축 및 인덱싱하여 디스크에 영속화하는 타깃 저장소
- 질의 시스템
- TSDB 전면에 위치하여 외부 시스템의 조회 요청을 대리 처리하는 전담 서비스 레이어
- DB 직접 접근을 차단하여 스토리지 엔진의 부하를 격리함
- 경보 시스템 & 시각화 시스템
- 질의 시스템을 인터페이스로 활용하여 정제된 데이터를 컨슈밍하는 다운스트림 컴포넌트
- 수집된 메트릭을 기반으로 알림을 하거나 대시보드를 렌더링함
3. 상세 설계 1: 지표 수집 및 전송 파이프라인 확장 전략
인프라 규모가 커질수록 지표 수집기 클러스터와 시계열 데이터베이스(TSDB)가 직면하는 대역폭 압박은 심화된다.
대량의 메트릭 데이터를 정체 없이 적재하고, 특정 컴포넌트의 장애가 전체 파이프라인의 유실로 이어지지 않도록 제어하는 확장 전략을 다룬다.
3.1. 지표 수집 아키텍처 분석
CPU 사용량이나 네트워크 트래픽 같은 운영 지표는 결제나 정산 데이터와 달리 일부 패킷이 소실되더라도 시스템 전체의 비즈니스 정밀도에 치명적인 타격을 주지 않는다.
따라서 수집 클라이언트는 전송 성공 여부에 과도한 리소스를 할당하지 않고 동기식 확인(ACK)을 생략하는 형태로 설계 가능하다.
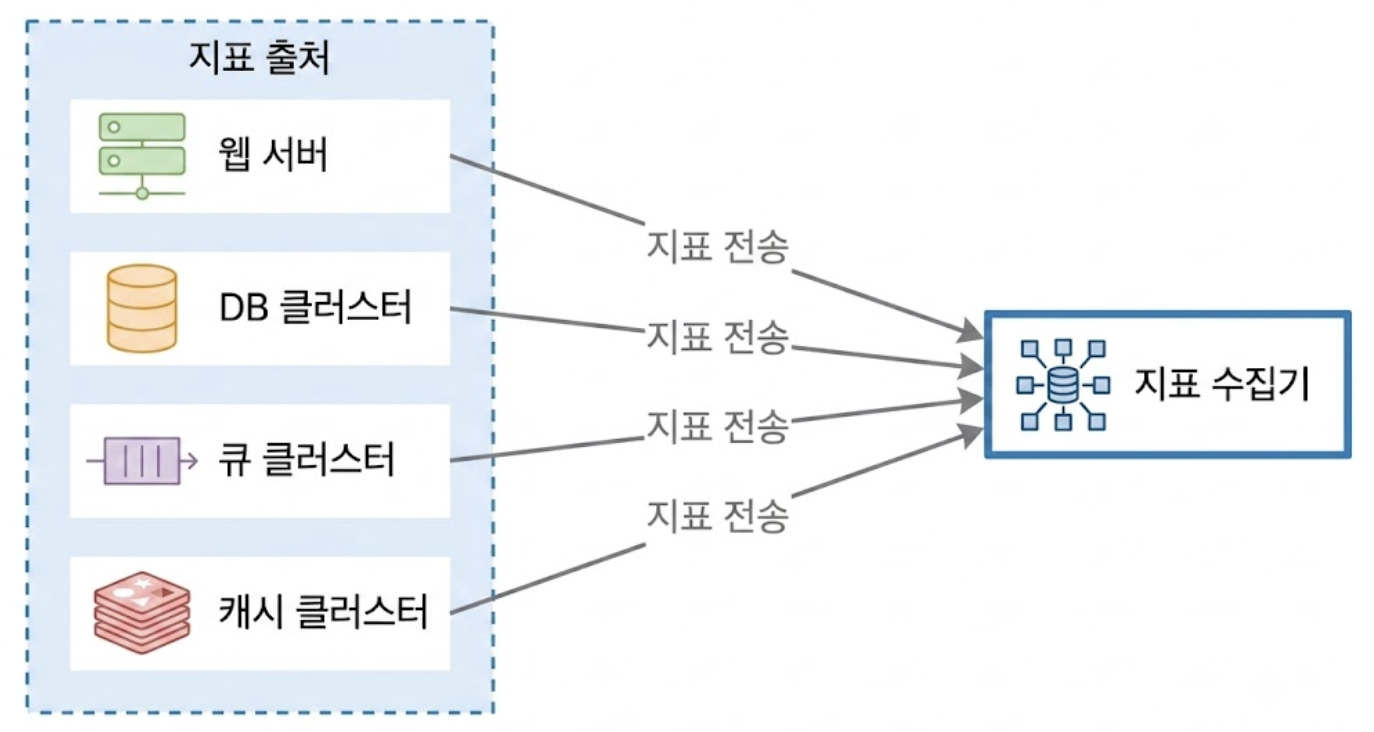
지표가 수집되는 전체적인 파이프라인 흐름은 아래와 같다.
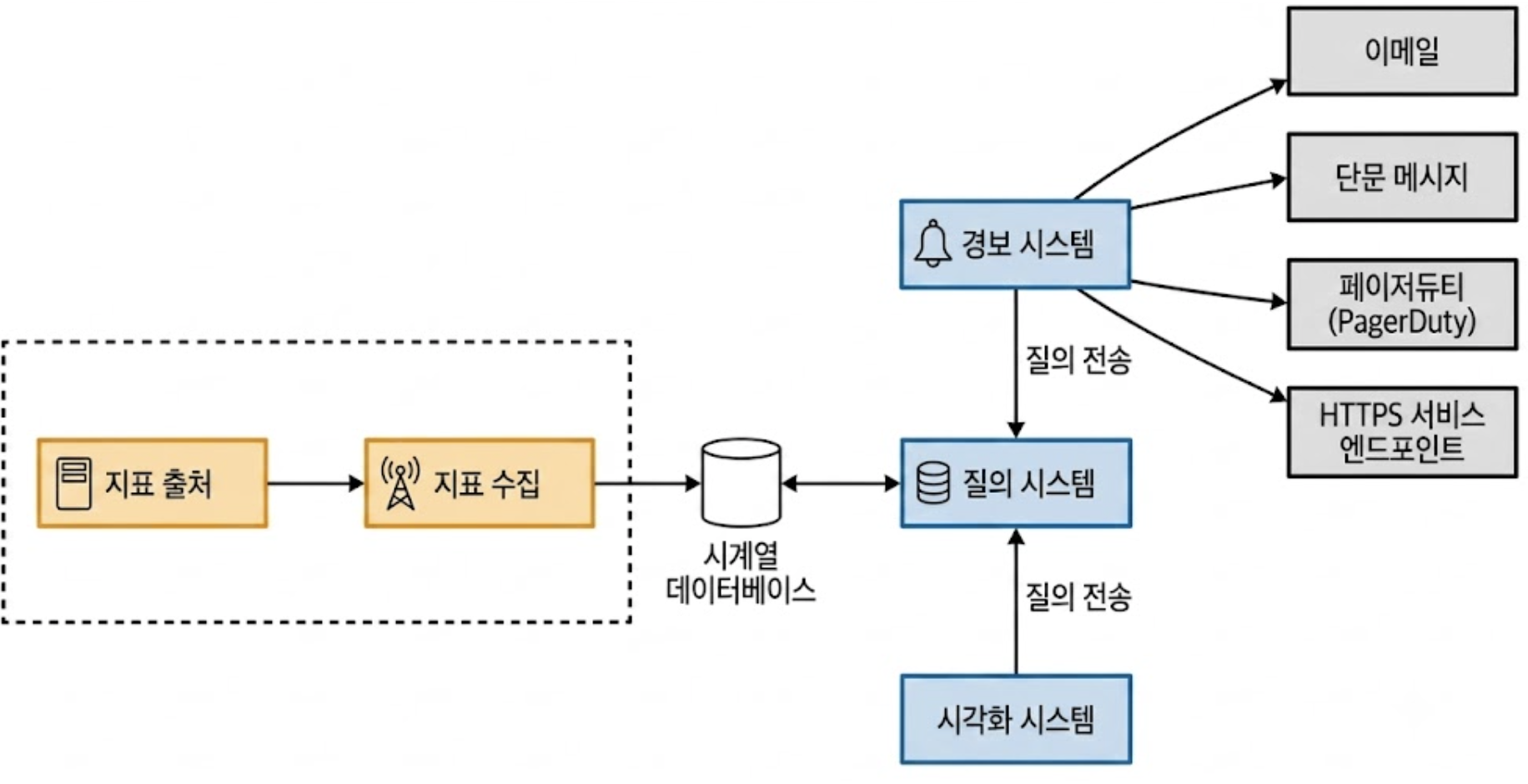
지표 데이터를 모니터링 코어 시스템으로 인입시키는 방식은 Pull 모델, Push 모델로 나뉘며, 인프라 토폴로지에 따라 명확한 트레이드오프가 존재한다.
3.1.1. Pull 모델
Pull 모델은 실행 중인 애플리케이션 서버나 인프라 타깃에 지표 수집기가 직접 접근하여 주기적으로 데이터를 폴링(Polling)하는 방식이다.
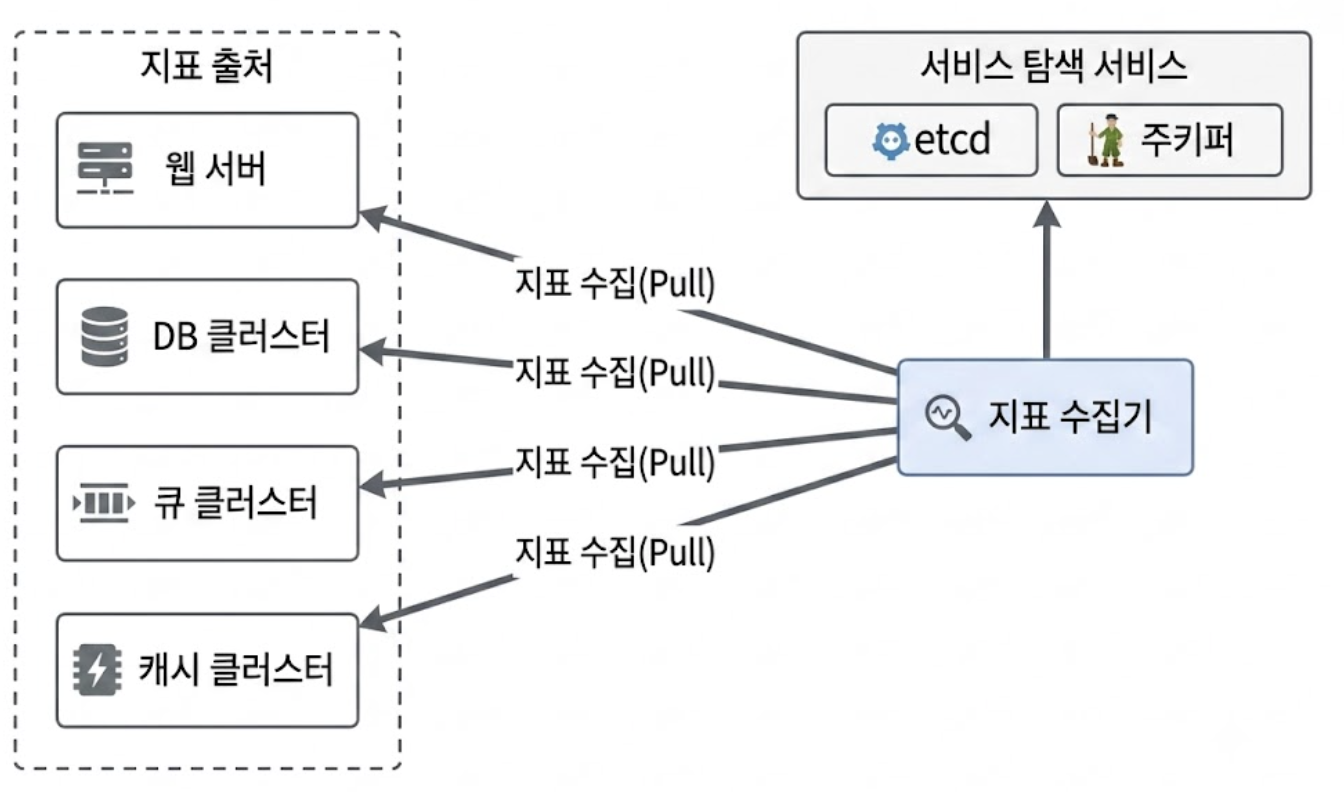
3.1.1.1. 서비스 탐색 연동을 통한 동적 대상 식별
서버 가상화 및 컨테이너 환경에서는 인스턴스가 수시로 생성되고 소멸한다.
지표 수집기 내부에 대상 서버의 IP 목록을 고정 파일 형태로 관리하는 방식은 대규모 환경에서 적용이 불가하다.
이를 해결하기 위해 etcd나 아파치 주키퍼같은 서비스 탐색(Service Discovery) 시스템을 파이프라인 전면에 연동한다.
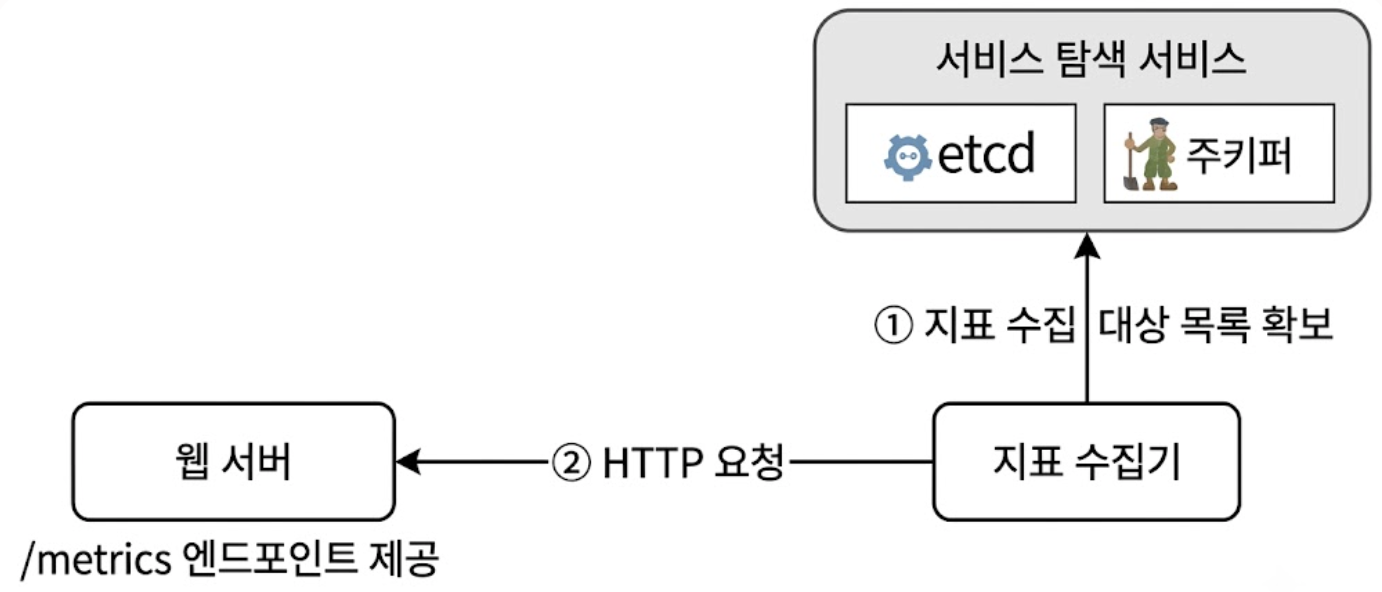
- 각 서비스 인프라는 기동 시 자신의 엔드포인트 및 가용성 메타데이터를 서비스 탐색 시스템에 등록
- 지표 수집기는 서비스 탐색 시스템으로부터 활성화된 타깃 목록(IP, 포트, 수집 주기 등)을 동적으로 확보
- 지표 수집기는 서비스 탐색의 변경 이벤트 알림 콜백을 수신하여 수집 대상을 실시간으로 최신화
3.1.1.2. 안정 해시 링(Consistent Hashing Ring)을 통한 수집 부하 분산
엄청난 양의 지표를 단일 수집기 노드로 처리할 수 없으므로 수집기 서버를 대규모 클러스터로 확장해야 한다.
이 때 여러 수집기가 동일한 대상 서버에 접근하여 지표를 중복 수집하는 현상을 방지하기 위해 안정 해시 링 분산 메커니즘을 도입한다.
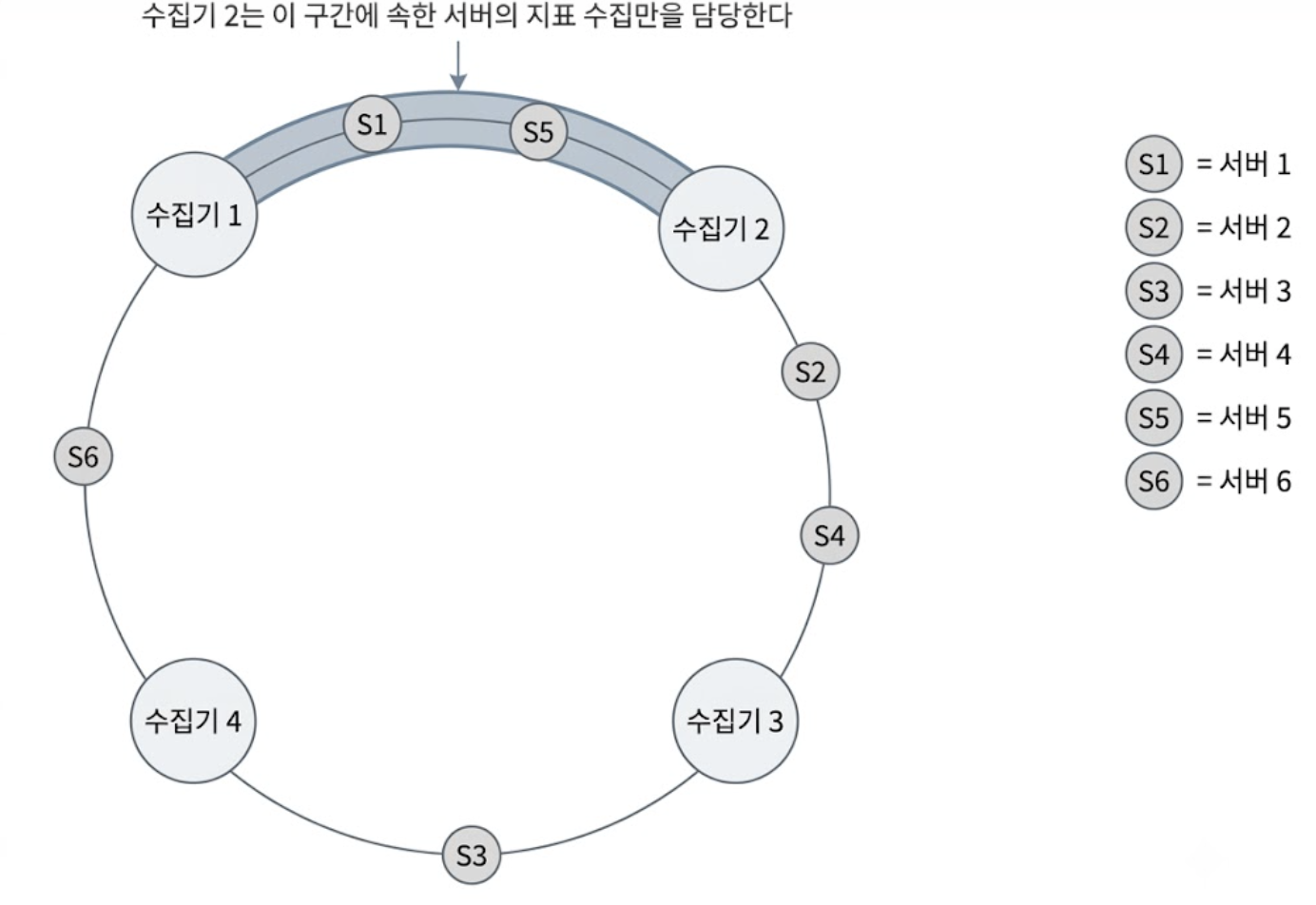
- 대상 서버의 식별자 해시값을 기반으로 해시 링 위에 위치를 할당하고, 수집기 노드가 특정 구간에 속한 서버들의 지표 수집 워크로드만 전담하도록 격리
- 위 그림에서 수집기 2는 해시 공간 구조에 따라 S1(서버 1)과 S5(서버 5) 구간의 지표 수집만을 담당하므로 클러스터 내의 중복 연산을 원천 차단함
3.1.2. Push 모델
Push 모델은 대상 호스트 내부에서 메트릭을 생성하는 서비스나 에이전트가 주체가 되어, 수집기 서버로 데이터를 직접 전송하는 방식이다.
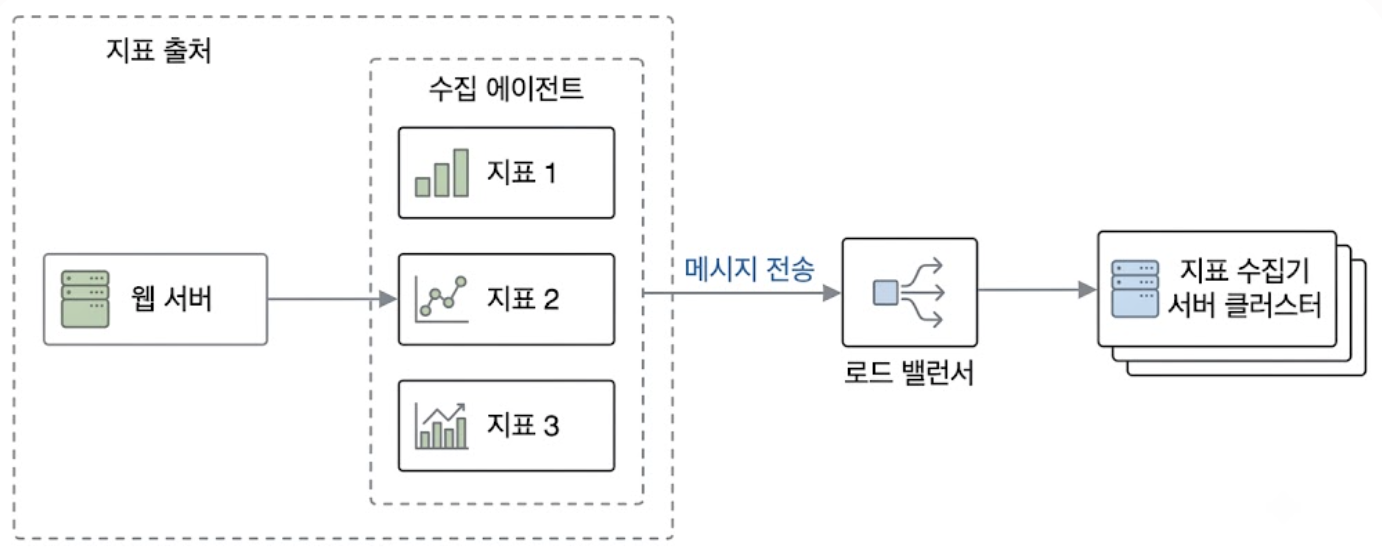
3.1.2.1. 에이전트 측 버퍼링 및 로드밸런서 배치
모니터링 대상 장비에 가벼운 수집 에이전트 소프트웨어를 설치하여 커널 및 애플리케이션 지표를 수집한다.
- 로컬 집계 및 버퍼링
- 에이전트는 원시 데이터를 즉시 전송하지 않고, 로컬 메모리 버퍼에서 1차적인 메트릭 요약 및 집계를 수행하여 아웃바운드 패킷 밀도를 낮춤
- 다운스트림 수집기 서버가 일시적인 부하로 에러를 반환하면, 에이전트는 로컬 디스크나 링 버퍼에 데이터를 임시 보관한 후 재전송하여 데이터 소실 방지
- 로드밸런싱 및 오토스케일링
- 대량의 에이전트가 동시다발적으로 메트릭을 전송할 수도 있으므로 수집기 서버는 레이어 전면에 고가용성 로드 밸런서 배치가 강제됨
- 트래픽 인입 강도에 대응할 수 있도록 수집기 서버 클러스터 또한 오토스케일링 그룹으로 구성해야 함
푸시 모델의 경우 모니터링 대상 서버에 통상 수집 에이전트라고 부르는 소프트웨어를 설치한다. 수집 에이전트는 해당 장비에서 실행되는 서비스가 생산하는 지표 데이터를 받아 모은 후 주기적으로 수집기에 전달한다. 간단한 지표의 경우 수집기에 보내기 전에 에이전트가 직접 데이터 집계 등의 작업을 처리할 수도 있다. 데이터 집계는 수집기에 보내는 데이터의 양을 줄이는 효과적인 방법이다.
3.1.3. Pull vs Push 모델
두 모델은 기술적 장단점이 뚜렷하므로 인프라 환경의 제약 조건에 따라 채택해야 한다.
| 비교 항목 | Pull(풀) 모델 (예: Prometheus) | Push(푸시) 모델 (예: CloudWatch, Graphite) |
|---|---|---|
| 디버깅 편의성 | 각 서버가 /metrics HTTP 엔드포인트를 열어두므로, curl 명령어로 실제 노출되는 지표 데이터 포맷을 즉시 검증할 수 있어 Pull 모델이 유리합니다. | 에이전트 내부 링 버퍼 상태나 전송 아웃바운드 패킷을 추적해야 하므로 디버깅 상태 강도가 높습니다. |
| 상태 진단 (Health Check) | 수집기가 Pull 요청을 날렸을 때 대상 서버가 응답하지 않으면, 인프라 장애나 애플리케이션 크래시 상태임을 즉각적이고 명확하게 판별할 수 있습니다. | 지표 유입이 중단되었을 때, 에이전트 프로세스 자체의 다운인지 단순 네트워크 패킷 드롭인지 원인 추적이 모호합니다. |
| 단기 프로세스 처리 | 수집 주기(Poll Interval)보다 생명 주기가 짧은 일괄 작업(Batch Job)이나 서버리스 함수의 지표는 미처 수집하기 전에 증발하므로 단독 처리 방식으로는 불리합니다. | 프로세스 소멸 직전에 수집기로 데이터를 직접 푸시하고 종료할 수 있으므로 임시 프로세스 모니터링에 적합합니다. |
| 네트워크 구성 및 방화벽 | 수집기가 대상 서버 내부망 포트로 진입해야 하므로, 멀티 데이터센터 망이나 DMZ망 구조 환경에서는 인바운드 방화벽 규칙 관리가 매우 복잡해집니다. | 수집기 전면의 로드밸런서(주로 아웃바운드 HTTPS 단일 포트) 방향으로만 데이터를 밀어 넣으면 되므로 네트워크 보안 구성이 간결합니다. |
| 데이터 신뢰성 | 서비스 탐색을 통해 이미 신뢰 관계가 검증된 화이트리스트 대상 서버의 지표만 수집하므로 타겟 위조 위험이 낮습니다. | 외부 노드가 수집기 엔드포인트로 위조 패킷을 주입할 위험이 존재하므로, 수집기 레이어에서 API 토큰 인증이나 IP ACL 검증 로직이 추가로 요구됩니다. |
💡TCP vs UDP 전송 성능 특성
지표 전송 파이프라인에서 Pull 모델은 HTTP 기반의 안정적인 TCP 연결을 지향하며, 일부 Push 모델은 오버헤드 최소화를 위해 UDP 를 활용한다.
- TCP
- 3-way handshake 및 슬라이딩 윈도우 기반의 흐름 제어로 패킷 전송을 보장하여 지표의 정밀도를 보장함
- 연결 비용은 HTTP/2 멀티플렉싱이나 지속 커넥션(Keep-Alive) 풀링으로 최적화함
- UDP
- 세션 연결 및 확인 응답 과정이 없어 패킷 전송 지연이 극도로 낮음
- 패킷 유실 가능성이 존재하지만, 메트릭 특성상 일부 유실이 치명타가 아니라는 전제하에 호스트 리소스를 극도로 아껴야하는 초고빈도 전송 환경에서 제한적으로 채택됨
풀 모델과 푸시 모델 가운데 무엇이 나은지는 정답이 없다. 서버리스 기술이 각광받음에 따라 많은 조직이 두 모델을 모두 지원하고 있다. 지표 수집 에이전트를 설치할 서버가 마땅히 존재하지 않을 수도 있다는 점을 감안해야 한다는 뜻이다.
💡서버리스 패러다임과 하이브리드 수집 모델의 부상 이유
최근 대규모 아키텍처는 AWS Lambda 등의 서버리스 및 이피머럴(Ephemeral, 임시) 인프라의 도입 비중이 높다.
서버리스 환경은 개발자가 하부 VM 인프라에 접근할 수 없어 수집 에이전트를 상주시킬 수 없으며, 요청 처리가 완료되면 수초 내에 컨테이너가 소멸한다.
이러한 제약 조건으로 인해 최신 대규모 시스템은 단일 수집 아키텍처를 고집하지 않고 하이브리드방식을 취한다.
상시 가동되는 코어 인프라는 서비스 탐색 기반의 Pull 모델로 고가용성 상태 감시를 수행하고,
서버리스 및 단기 배치 프로세스 레이어는 실행 종료 시점에 메트릭 게이트웨이로 데이터를 전송하는 Push 모델을 혼용하여 상호 보완하도록 설계한다.
3.2. 지표 전송 파이프라인의 규모 확장
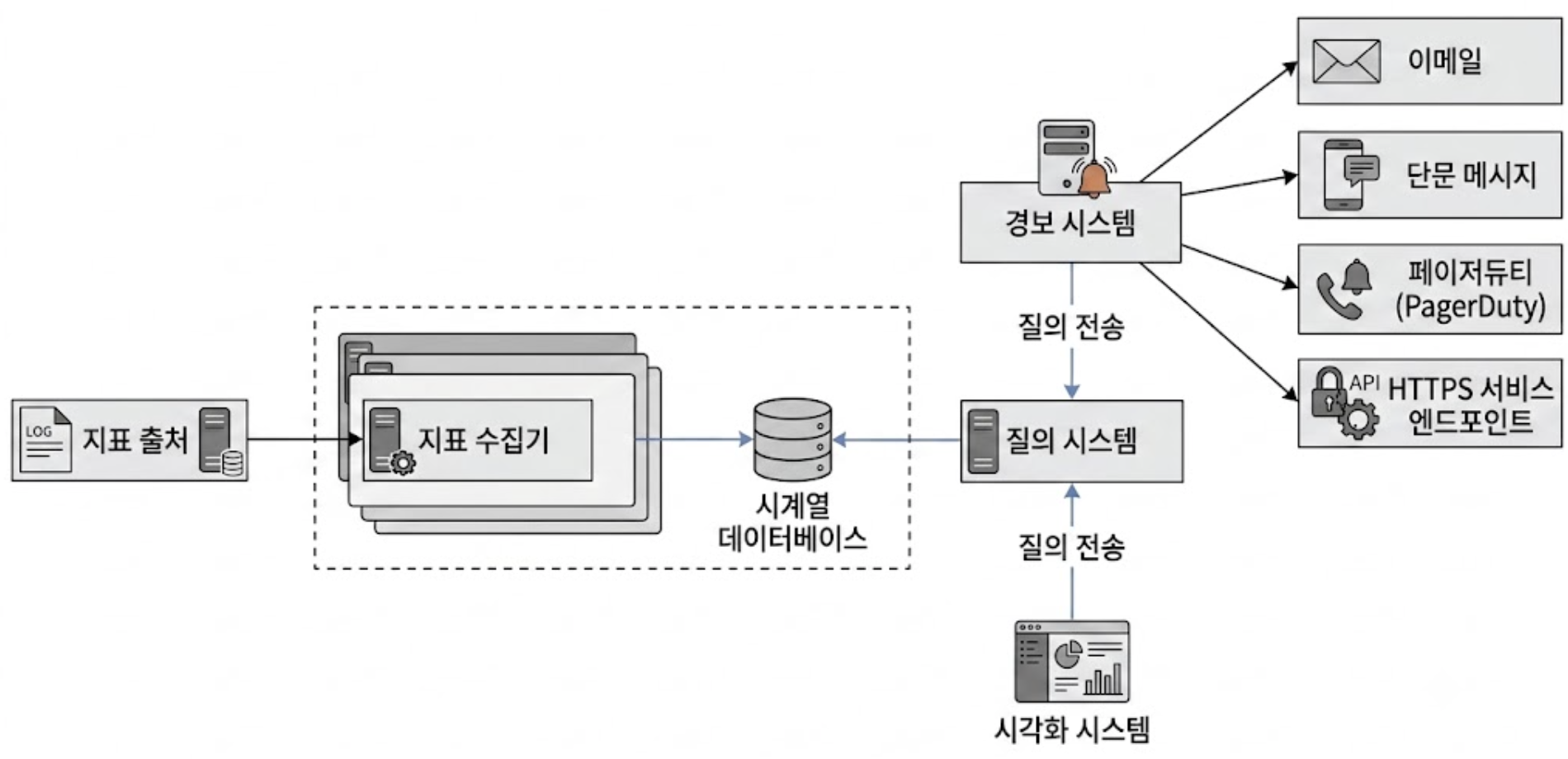
수집기 클러스터가 TSDB에 직접 데이터를 동기식으로 쓰게 되면 대량의 쓰기 스파이크가 발생하거나 TSDB 레이어에 장애가 생겼을 때 파이프라인 전체가 마비되어 메트릭이 대거 소실될 리스크가 존재한다.
지표 수집기와 시계열 데이터베이스 사이에 분산 메시지 큐인 아파치 카프카를 배치하여 안정적인 비동기 버퍼 계층을 구현한다.
위 그림에서 지표 수집기는 지표 데이터를 카프카와 같은 큐 시스템에 전송한다. 그러면 아파치 스톰(Storm)이나 플링크(Flink), 스파크(Spark) 같은 소비자 즉 스트림 처리 서비스가 해당 데이터를 받아 시계열 데이터베이스에 저장한다.
- 장애 도메인 격리(Decoupling)
- 데이터 수집 레이어와 저장 처리 레이어를 물리적으로 격리하여, 후방의 데이터베이스가 다운되더라도 전방의 수집 파이프라인은 정상 가동되도록 보장
- 배압(Backpressure) 제어
- 카프카가 인입된 대량의 데이터를 로그 세그먼트 디스크에 안전하게 적재하므로, 다운스트림 스트림 프로세서(Flink, Storm, Consumer가 포함된 스트림 서비스 등)는 TSDB의 쓰기 한계 용량에 맞춰 적절한 속도로 데이터를 컨슈밍(소비 속도 제어)할 수 있음
3.2.1. 카프카를 통한 대역폭 확장 및 메트릭 분류
카프카의 병렬 처리 단위인 파티션 메커니즘을 이용하면 천만 개 지표 트래픽을 선형적으로 Scale-out 할 수 있다.
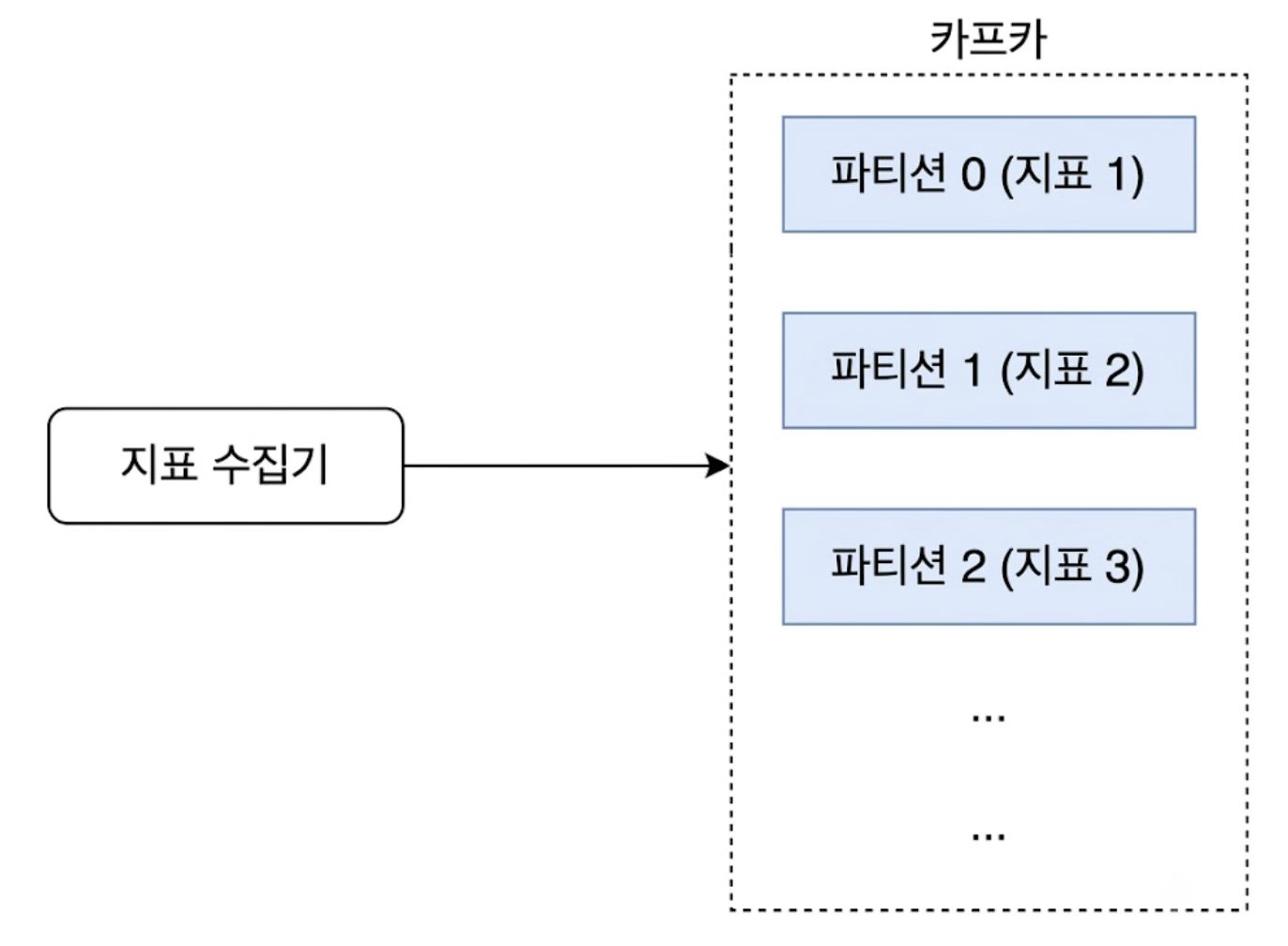
- 지표 이름 기반 파티셔닝
- 수집된 메트릭 데이터를 카프카 토픽으로 발행할 때 지표 이름을 파티션 키로 지정
- 이 구성을 통해 동일한 종류의 지표는 항상 동일한 파티션 번호로 정렬되어 유입되므로, 다운스트림 소비자가 데이터를 메모리에 올려 시간 윈도우별 집계 연산을 수행하기가 수월해짐
- 태그 조합을 통한 핫스팟 방지
- 특정 핵심 지표의 트래픽이 비정상적으로 몰려 단일 파티션의 대역폭 임계치를 넘어설 경우, 지표 이름 뒤에
region이나zone같은 카디널리티가 낮은 태그 정보를 조합하여 파티션 키를 생성함으로써 부하를 여러 파티션으로 균등하게 분산
- 특정 핵심 지표의 트래픽이 비정상적으로 몰려 단일 파티션의 대역폭 임계치를 넘어설 경우, 지표 이름 뒤에
- 중요 지표는 먼저 처리될 수 있도록 우선순위 지정
💡지표별 우선순위 지정을 위한 큐 설계 기법
카프카의 파티션은 구조적으로 FIFO 방식으로 동작하므로, 단일 파티션 내부에서 특정 메시지의 우선순위를 인위적으로 변경할 수 없다.
따라서 실시간 가용성에 직접 영향을 주는 핵심 지표(예: 서비스 다운과 직결되는 5xx 에러율)를 일반 운영 지표(예: 디스크 남은 용량)보다 먼저 적재하기 위해서는 우선순위별 멀티 토픽 아키텍처를 설계해야 한다.
- 토픽의 등급별 격리
- 카프카 내부에
metrics.priority.high와metrics.priority.low토픽을 물리적으로 분리하여 개설
- 카프카 내부에
- Producer 레이어의 라우팅 분류
- 지표 수집기에서 메트릭을 카프카로 발행하기 전 등급을 평가함
- 임계치 평가가 실시간으로 필요한 핵심 지표는
high토픽으로, 지연되어도 무방한 일반 지표는low토픽으로 분기하여 전송
- Consumer 가중치 할당 제어
- 다운스트림 프로세서는 두 토픽을 동시에 폴링하되, 컨슈머 루프 내부에서
high토픽의 처리 스레드 풀 배정 비율과 폴링 빈도를low토픽보다 높게 가져가는 가중치 기반 라운드 로빈(Weighted Round-robin) 방식을 적용 - 이를 통해 트래픽 폭주 상황에서 크리티컬 경보 지표가 큐에 갇혀 지연되는 현상 방지
- 다운스트림 프로세서는 두 토픽을 동시에 폴링하되, 컨슈머 루프 내부에서
3.2.2. 카프카의 대안: 인메모리 시계열 DB ‘고릴라(Gorilla)’ 아키텍처
아키텍처 구성 요소의 복잡성을 줄이기 위해 중간 미들웨어인 카프카를 생략하고 스토리지 레이어 자체의 쓰기 고가용성으로 대량 트래픽을 감당하는 대안도 있다.
페이스북이 엔지니어링 논문으로 공개한 인메모리 시계열 데이터베이스 시스템인 고릴라(Gorilla)가 대표적인 레퍼런스이다.
- 고릴라는 디스크 I/O 병목을 우회하기 위해 모든 실시간 인입 데이터를 완전한 인메모리 구조로 관리하며, 네트워크 단절이나 일부 노드 장애가 발생하더라도 느슨한 동기화 및 복제 메커니즘을 통해 높은 수준의 쓰기 연산 가용성을 유지
- 이와 같이 초고성능 쓰기 전용 스토리지 아키텍처를 직접 구축하여 매핑할 경우, 메시지 큐 인프라의 관리 오버헤드와 트레이드오프할 수 있음
3.3. 데이터 집계 지점별 장단점
천만 개 수준의 대규모 메트릭 환경에서는 Raw 데이터를 어느 파이프라인 단계에서 요약/집계하여 적재할지가 전체 스토리지 용량 최적화의 핵심이 된다.
집계는 파이프라인 상의 3가지 지점에서 수행 가능하다.
- 수집 에이전트 단계(호스트 소스 로컬)
- 방식: 대상 호스트 내부 메모리에서 10초~1분간 유입된 지표를 미리 평균 및 합산하여 수집기 서버로 전송
- 장점: 아웃바운드로 나가는 네트워크 대역폭과 패킷 발생 수가 급격히 감소하여 전송 비용 절감
- 단점: 에이전트 프로세스가 호스트의 CPU 및 RAM 자원을 일부 점유하며, 여러 호스트의 데이터를 묶어 처리하는 복잡한 다차원 스트림 연산이 불가능
- 데이터 전송 파이프라인 단계(수집기 및 스트림 엔진 레이어)
- 방식: 카프카 소비단 전면에 Flink, Spark 같은 스트림 처리 엔진을 배치하여 TSDB에 쓰기 전 인메모리 타임 윈도우 연산으로 데이터를 요약 처리
- 장점: TSDB에 최종 적재되는 row 수 자체가 압축되므로 스토리지 용량을 아낄 수 있음
- 단점: 네트워크 지연으로 인해 늦게 도착하는 지표 데이터에 대한 정밀한 정리가 까다로우며, Raw 데이터가 유실되어 사후 장애 정밀 분석(Forensics)이 어려워짐
- 질의 실행 단계(On-Query Aggregation)
- 방식: 가공되지 않은 모든 원시 시계열 데이터를 TSDB에 100% 그대로 적재하고, 대시보드를 조회하거나 경보 시스템이 규칙을 평가하는 쿼리 시점에 실시간 연산
- 장점: 원본 데이터의 손실이 전혀 없으므로 필요한 시간 구간에 맞춰 정밀도와 필터링을 무제한으로 유연하게 변경 가능
- 단점: 질의를 처리하는 순간에 수억 건의 레코드 세트를 대상으로 매번 전체 집계 연산을 계산해야 하므로, 대시보드 로딩 속도가 느려지고 DB에 막대한 부하 유발
4. 상세 설계 2: 질의 서비스
대규모 시계열 데이터 백엔드는 밀려오는 쓰기 트래픽을 소화하는 것만큼, 적재된 대규모 데이터셋을 지연없이 조회하고 스토리지 비용을 효율적으로 통제하는 것이 중요하다.
여기서는 질의 계층의 격리 구조와 디스크 I/O 및 용량을 최적화하는 방법에 대해 알아본다.
4.1. 질의 서비스 캡슐화 및 캐시 계층
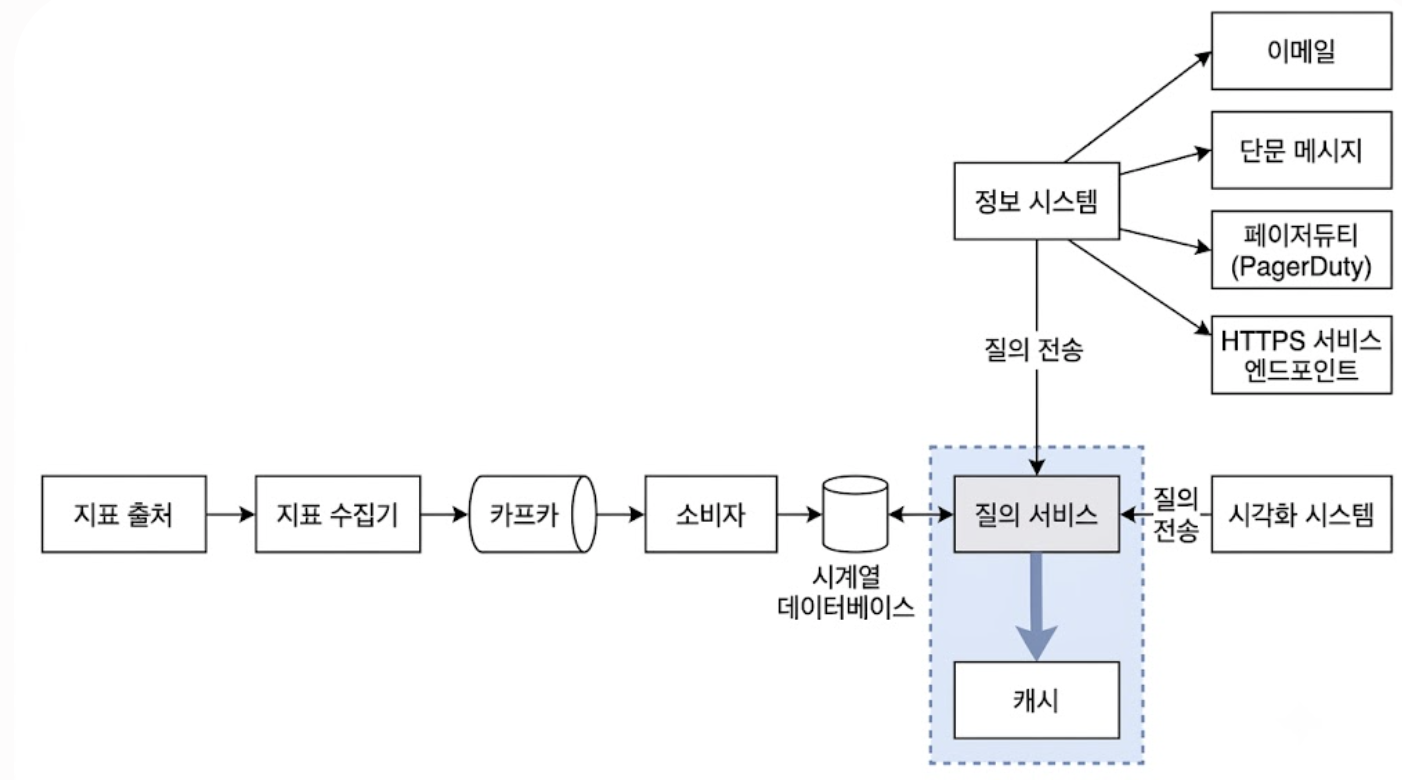
시각화 대시보드(Grafana)나 경보 시스템이 시계열 데이터베이스(TSDB)에 직접 대량의 원시 쿼리를 수행하게 되면, 스토리지 엔진의 자원이 고갈되어 실시간 인입 쓰기 파이프라인까지 마비되는 연쇄 장애가 발생할 수 있다.
이를 방지하기 위해 stateless 질의 서버 클러스터 풀로 구성된 질의 서비스 레이어를 전면에 배치한다.
- 저장소 추상화 및 캡슐화
- 질의 서비스는 하부의 구체적인 TSDB 솔루션을 캡슐화하는 인터페이스 역할을 함
- 다운스트림 클라이언트(시각화, 경보)는 질의 서비스의 API 표준만 바라보므로, 후방의 TSDB를 다른 제품군으로 교체하더라도 상위 레이어의 코드 변경이 발생하지 않는 유연성 확보
- 캐시 계층 도입을 통한 I/O 격리
- 엔지니어들이 상시 열어두는 대시보드나 주기적으로 반복 실행되는 경보 평가 규칙은 동일한 시간 범위의 데이터를 중복 요청하는 경향이 강함
- 질의 서비스 전면에 Redis 또는 인메모리 캐시 계층을 배치하여 동일 질의 결과를 캐싱함으로써 TSDB의 읽기 연산 부하를 낮춤
4.2. 시계열 데이터베이스 질의어
시계열 데이터 분석에 관계형 표준 SQL을 사용하는 것은 데이터 처리 아키텍처 관점에서 비효율적이다.
연속적인 시간 범위 내의 가중치 연산이나 누적 이동 평균을 계산할 때 SQL을 극도로 복잡한 윈도우 함수와 서브쿼리, Gaps-and-Islands 기법 처리가 강제되어 파싱 오버헤드가 크고 실행 계획 최적화가 어렵다.
반면 시계열 특화 도메인 언어(DSL)은 InfluxDB의 Flux나 프로메테우스의 PromQL은 시간 윈도우 기반의 스트림 파이프라인 연산자를 네이티브하게 지원하므로, 연산 파이프라인이 간결하며 스토리지 엔진 내부에서 인덱스를 타고 고속 처리된다.
💡프로메테우스(Prometheus)와 InfluxDB의 솔루션 포지셔닝 비교
두 솔루션 모두 ‘단순한 DB인가?’라는 의문에 대해 시스템 아키텍처 관점에서는 명확한 컴포넌트적 차이가 존재한다.
- InfluxDB
- 구조적으로 범용적이고 독립적인 고성능 시계열 데이터베이스 자체에 집중
- 대량의 데이터 쓰기를 받아내기 위한 스토리지 엔진 최적화가 핵심
- 데이터 수집은 외부 에이전트에 위임하는 구조
- 프로메테우스
- 단순 데이터베이스를 넘어 수집(Scraper), 저장(Built-in TSDB), 알림 연동(Alertmanager) 기능을 내장한 올인원 모니터링 에코 시스템
- 시계열 저장소 기능도 훌륭하지만, 서비스 탐색과 결합하여 대상 인프라를 능동적으로 폴링하는 ‘수집 파이프라인 런타임’으로서의 포지셔닝이 강함
4.3. 저장 용량 최적화를 위한 인코딩 및 델타 압축
대규모 지표가 실시간 적재되는 환경에서는 압축 알고리즘의 효율성이 인프라 비용 통제의 성패를 가른다.
TSDB는 데이터 타입별 특성을 고려하여 타임스탬프 영역과 지표 수치(Value) 영역을 분리하여 압축한다.
대표적인 기법이 페이스북 고릴라(Gorilla) 아키텍처에서 정립된 이중-델타 인코딩이다.
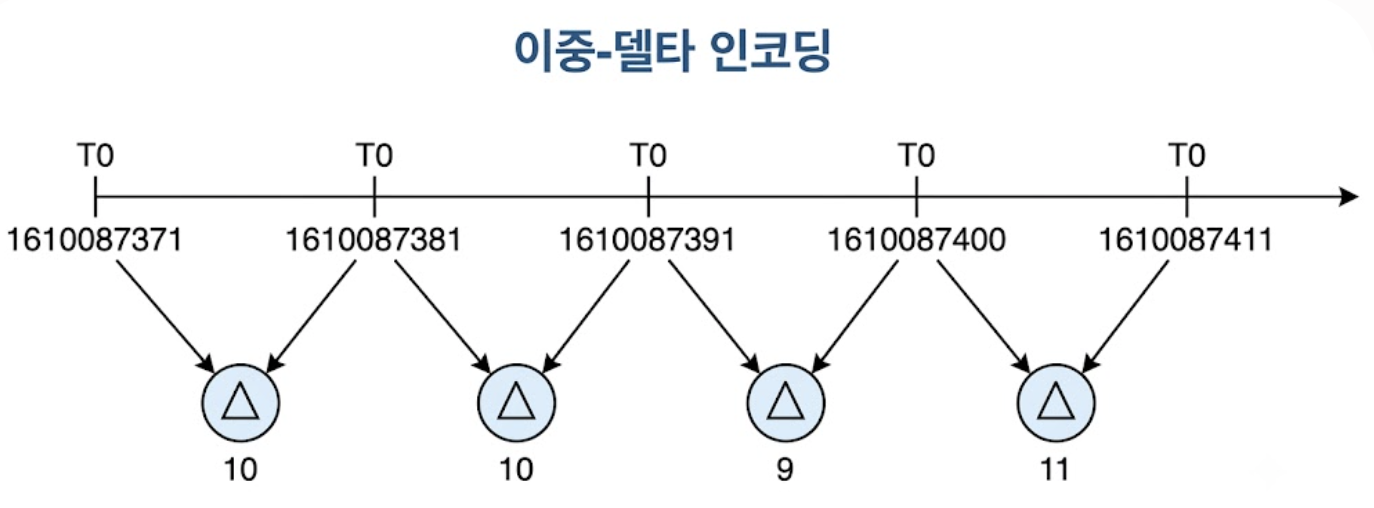
일반적으로 Unix 타임스탬프 하나를 온전히 표현하려면 32bit 또는 64bit의 정밀도가 필요하다.
(위 그림에서 보듯 1610087371과 1610087381은 딱 10초만큼만 다른 값이며, 타임스탬프 하나를 온전히 표현하는데는 32비트가 필요하지만 10을 표현하는데는 4비트면 충분) 하지만 모니터링 에이전트가 10초 주기로 정확히 지표를 수집한다면, 타임스탬프 간의 차이(첫 번째 델타, \(\Delta\))는 항상 10이라는 고정값을 가진다.
따라서 데이터를 완전한 형태로 저장하는 대신 기준값과의 차이를 1610087371, 10, 10, 9, 11과 같이 저장한다.
여기서 한 단계 더 나아가 델타 값 간의 차이인 이중 델타(\(D\))를 계산하면 아래와 같은 흐름을 보인다. \[D = \Delta_t - \Delta_{t-1}\]
수집 주기가 일정하다면 이중 델타 값은 지속적으로 0이 도출된다.
위 그림의 구조를 수식으로 풀면 아래와 같다.
- 정기 수집 구간 (T1, T2):
- 수집 오프셋이 정확히 10초이므로 이중 델타 값은 0이 되며, 이는 비트 패킹을 통해 단 1비트의 공간만으로 디스크에 저장 가능
- 미세 지연 구간 (T3, T4):
- 네트워크 지연 등으로 수집 주기가 9초, 11초로 흔들리더라도 이중 델타 값은 -1, 2 등 영(0)에 극도로 수렴하는 작은 정수형 데이터가 도출되므로,
표준 가변 길이 비트 인코딩(Huffman Coding 변형)을 통해 수 비트 이내로 물리적 크기를 극대화하여 압축 가능
- 네트워크 지연 등으로 수집 주기가 9초, 11초로 흔들리더라도 이중 델타 값은 -1, 2 등 영(0)에 극도로 수렴하는 작은 정수형 데이터가 도출되므로,
4.4. 다운샘플링
인프라 요구사항에 다라 7일이 지난 고해상도 원본 데이터는 저장 공간 절감을 위해 30초 또는 1분 주기의 저해상도 데이터로 변환(다운샘플링) 가공 과정을 거친다.
| 지표 | 타임스탬프 | 호스트명 | 지표 값 |
|---|---|---|---|
| cpu | 2021-10-24T19:00:00Z | host-a | 10 |
| cpu | 2021-10-24T19:00:10Z | host-a | 16 |
| cpu | 2021-10-24T19:00:20Z | host-a | 20 |
| cpu | 2021-10-24T19:00:30Z | host-a | 30 |
| cpu | 2021-10-24T19:00:40Z | host-a | 20 |
| cpu | 2021-10-24T19:00:50Z | host-a | 30 |
위 10초 해상도 데이터를 30초 해상도 데이터로 집계한 결과는 아래와 같다.
| 지표 | 타임스탬프 | 호스트명 | 지표 값(avg) |
|---|---|---|---|
| cpu | 2021-10-24T19:00:00Z | host-a | 19 |
| cpu | 2021-10-24T19:00:30Z | host-a | 25 |
- 타임스탬프 2021-10-24T19:00:00Z 구간의 지표값 ‘19’ 도출 구조
- 시스템에 설정된 다운샘플링 타임 윈도우가 시작 경계면을 포함하는 구조([19:00:00Z, 19:00:30Z])로 작동할 경우, 해당 30초 구간 내에 포함되는 4개의 원시 Raw 값을 타깃으로 지정
- \(\frac{10 + 16 + 20 + 30}{4} = \frac{76}{4} = 19\) (평균치 통계 적용)
- 타임스탬프 2021-10-24T19:00:30Z 구간의 지표값 ‘25’ 도출 구조
- 앞선 윈도우의 경계면 바로 다음 시점부터 그 다음 30초 구간을 커버하는 원시 로우셋
- \[\frac{20 + 30}{2} = \frac{50}{2} = 25\]
4.5. Cold Storage
대규모 인프라 관측 가능성 연구 논문에 따르면, 실제 프로덕션 환경에서 발생하는 운영 데이터 질의의 약 85%는 최근 26시간 이내에 수집된 최신 지표 데이터를 대상으로 집중된다.
이 워크로드 특성을 기반으로 스토리지 계층화 정책을 수립해야 인프라 비용 상승을 막을 수 있다.
- Hot Tier - 최적화 구조
- 최근 26~48시간 이내의 고해상도 메트릭 데이터는 고성능 SSD 또는 초고속 인메모리 스토리지 영역에 배치하여 경보 시스템 평가 및 실시간 트러블슈팅 질의 지연 최소화
- Warm/Cold Tier - 저비용 구조
- 다운샘플링이 완료된 30일 이상, 1년 미만의 장기 보관용 메트릭 데이터는 블록 스토리지가 아닌 GB당 단가가 저렴한 오브젝트 스토리지(AWS S3, Google Cloud Storage 등)로 이관 처리
- 오브젝트 스토리지는 탐색 지연이 존재하지만, 수개월 전의 장기 추세를 분석하는 리포팅 질의 특성 상 수 초 내외의 응답 지연은 충분히 허용 가능한 트레이드오프 범위 내에 있기 때문임
5. 경보 및 시각화 시스템
모니터링 시스템의 최종 목적지는 수집된 데이터를 기반으로 위험 상황을 실시간 감지하여 전송하는 경보와 인프라 상태를 직관적으로 파악할 수 있게 하는 시각화이다.
이 두 도메인은 시장에 오픈소스 및 기성 솔루션(Grafana, PagerDuty 등)이 매우 성숙해 있으므로, 직접 구현하기보다 안정적인 컴포넌트를 연동하는 아키텍처를 취하는 것이 비용 대비 효과 측면에서 유리하다.
5.1. 경보 시스템 연동 구조
경보 파이프라인은 실시간 쓰기 레이어와 결합도를 낮추고 분산 가용성을 확보하기 위해 아래와 같이 이벤트 기반 아키텍처(EDA)로 설계한다.
경보 처리 워크로드 흐름 1. 규칙 설정 파일 로드: 미리 정의한 경보 규칙(예: CPU 사용량 90% 이상 시 경보) 설정 파일을 읽어 캐시 메모리에 로드 2. 경보 관리자의 규칙 참조: 경보 관리자(Alert Manager)는 캐시에서 활성화된 경보 규칙들을 지속적으로 스캔 3. 질의 서비스를 통한 데이터 평가: 경보 관리자는 설정된 주기마다 질의 서비스에 요청을 날려 디스크/메모리에 적재된 시계열 메트릭이 임계치를 초과했는지 평가 4. 상태 기록 및 영속화: 경보의 상태 변환(정상 → 경고 → 심각) 및 발송 이력을 경보 저장소에 기록하여 영속화 5. 메시지 큐 발행: 조건이 충족되어 경보가 발생하면, 경보 발생자는 이벤트를 카프카의 경보 전용 토픽으로 즉시 발행함, 후속 알림 레이어와의 비동기 격리를 위한 구조임 6. 경보 소비자 컨슈밍: 경보 소비자 클러스터가 카프카로부터 알림 이벤트 컨슈밍 7. 멀티채널 라우팅: 소비자는 이벤트를 파싱하여 이메일, SMS 등 지정된 타깃 다운스트림 채널로 알림 패킷을 최종 라우팅
5.2. 경보 피로(Alert Fatigue) 방지를 위한 이벤트 병합
단일 호스트 내에 장애가 수많은 경보 이벤트를 동시다발적으로 유발할 수 있다.
예를 들어 특정 인스턴스의 디스크 사용량이 임계치를 넘으면 초 단위로 수십 개의 경보 이벤트가 유입된다.
이를 필터링 없이 그대로 발송하면 엔지니어가 중요한 알림을 놓치는 경보 피로(Alert Fatigue) 현상이 발생한다.
이를 제어하기 위해 경보 소비자 또는 관리자 레이어에서 이벤트 병합 메커니즘을 수행한다.
- 식별자 기반 그룹핑
- 동일한 호스트에서 동일한 규칙 원인으로 발생하는 다량의 이벤트를 시간 윈도우 블록 내에서 하나의 고유한 그룹 ID로 바인딩
- 중복 제거 및 요약
- 수천 개의 장애 이벤트를 단 하나의 요약된 경보 알림(
인스턴스 1에서 발생한 1개 경보)으로 병합 처리하여 알림 채널로 전달함으로써 관측 효율성 극대화
- 수천 개의 장애 이벤트를 단 하나의 요약된 경보 알림(
5.3. Grafana 기반의 시각화 시스템
시각화 계층은 사내에서 웹 FE를 직접 구현하기보다, 업계 표준으로 자리 잡은 오픈소스 대시보드 솔루션인 Grafana를 도입하는 것이 적합하다.
6. 요약
- 지표 출처 → 지표 수집기
- 안정 해시 링과 서비스 탐색 기술을 결합하여, 인프라의 동적 오토스케일링 환경에서도 수집기 노드 간 중복 없이 천만 개의 지표 트래픽 수집을 Scale-out함
- 환경적 요구 사항에 따라 Pull/Push 하이브리드 수집 모델 적용
- 지표 수집기 → 카프카 → 소비자
- 데이터 적재 전면에 분산 메시지 큐를 배치함으로써 대용량 쓰기 스파이크에 대한 Backpressure를 제어하고, 영속성 계층의 가용성 저하 시에도 데이터 유실을 차단하는 버퍼 계층 구현
- 메트릭의 식별자를 기반으로 파티셔닝 전략을 적용하여 처리 성능 최적화
- TSDB → 캐시 및 질의 서비스
- 쓰기 최적화 스토리지 엔진을 채택하여 초당 수십만 건의 적재를 처리
- 백그라운드 다운샘플링 및 이중-델타 인코딩을 가동하여 디스크 비용 절감
- 읽기 연산은 전단의 무상태 질의 서버와 캐시 계층을 거치도록 강제하여 스토리지 엔진의 I/O를 물리적으로 격리
- 다운스트림(경보 및 시각화)
- 분리된 질의 인터페이스를 통해 데이터를 안전하게 컨슈밍하며, 비동기 큐 기반의 경보 시스템과 그라파나 대시보드를 연동하여 인프라 가시성과 높은 장애 감지 정밀도 제공
- 지표 데이터 수집 모델: 풀 모델 vs 푸시 모델
- 카프카를 활용한 규모 확장 방안
- 최적 시계열 데이터베이스의 선정
- 다운샘플링을 통한 데이터 크기 절감
- 경보/시각화 시스템: 구현할 것인가 구입할 것인가
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 알렉스 쉬, 산 람 저자의 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2를 기반으로 스터디하며 정리한 내용들입니다.
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2
- 책에 나온 링크들 모음
- splunk
- PagerDuty
- ELK
- Distributed Systems Tracing with Zipkin
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
- Prometheus
- OpenTSDB - A Distributed, Scalable Monitoring System
- 프로메테우스 데이터 모델
- Bigtable 시계열 데이터의 스키마 설계
- MetricsDB: TimeSeries Database for storing metrics at Twitter
- Amazon Timestream
- DB-Engines Ranking of Time Series DBMS
- InfluxDB
- Amazon CloudWatch
- Graphite
- 프로메테우스의 pushgateway
- Serverless
- 고릴라(Gorilla)
