DDD - 애그리거트, 애그리거트 루트, 도메인 이벤트, 애그리거트 참조, 애그리거트 간 집합 연관, 애그리거트를 팩토리로 사용
in DEV on DDD, Aggregate, Factory, Memberof, @embeddedid, @embeddable, @elementcollection, @collectiontable
- 애그리거트
- 애그리거트 루트와 역할
- 애그리거트와 리포지터리
- ID 를 이용한 애그리거트 참조
소스는 github 에 있습니다.
목차
- 1. 애그리거트
- 2. 애그리거트 루트
- 3. 리포지터리와 애그리거트
- 4. 애그리거트 참조
- 5. 애그리거트 간 집합 연관
- 6. 애그리거트를 팩토리로 사용: 팩토리 함수
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- 언어: java
- Spring Boot ver: 3.2.5
- Spring ver: 6.1.6
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Maven
1. 애그리거트
상위 수준 개념으로 전체 모델을 정리하면 전반적인 관계를 이해하는데 도움이 된다.
아래 그림에서 주문이 회원, 상품, 결제와 관련이 있다는 것을 쉽게 파악할 수 있다.
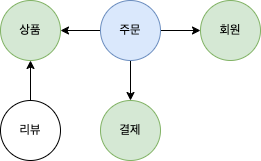
위의 상위 수준 모델을 개별 객체 단위로 나타내면 아래와 같다.
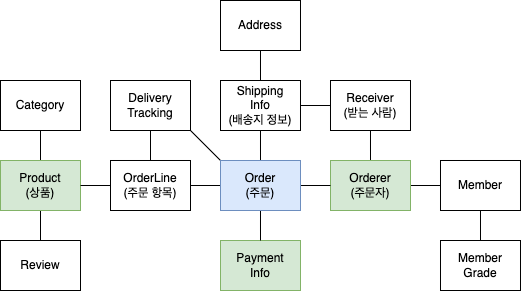
상위 모델에 대한 이해없이 위 그림만 보고 상위 수준에서 개념을 파악하려면 더 오랜 시간이 걸린다.
수많은 테이블을 한 장의 ERD 에 모두 표시하면 개별 테이블 간의 관계를 파악하느라 큰 틀에서 데이터 구조를 이해하는데 어려움을 겪는 것처럼, 도메인 객체 모델이 복잡해지면 개별 구성 요소 위주로 모델을 이해하게 되기 때문에 전반적인 구조에서의 도메인 관계를 파악하기 어렵다.
주요 도메인 요소 간의 관계를 파악하기 어렵다는 것은 코드를 변경하고 확장하는 것이 어려워진다는 것을 의미한다.
상위 수준에서 모델이 어떻게 엮여있는지 알아야 전체 모델을 망가뜨리지 않으면서 추가 요구사항을 모델에 반영할 수 있는데 세부적인 모델만 이해한 상태로는 코드를 수정하는 것이 어렵게 된다.
애그리거트는 복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들기 위해 상위 수준에서 모델을 볼 수 있도록 해준다.
애그리거트는 관련된 객체를 하나의 군으로 묶어주는데, 수많은 객체를 애그리거트로 묶어서 바라보면 상위 수준에서 도메인 모델 간의 관계를 파악할 수 있다.
아래는 위 개별 객체 수준에서 정리한 모델을 애그리거트 단위로 묶어서 다시 표현한 것이다.
동일한 모델이지만 애그리거트를 사용함으로써 모델 간의 관계를 개별 모델 수준과 상위 수준에서 모두 이해할 수 있다.
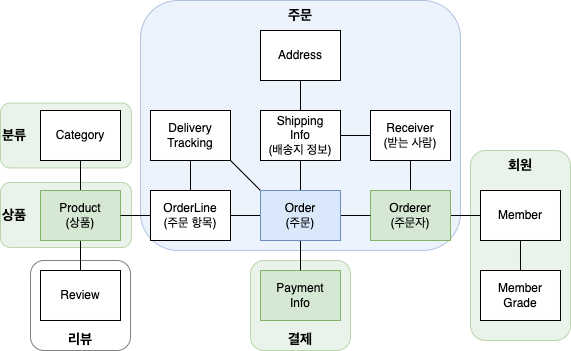
애그리거트는 모델을 이해하는데 도움을 주고, 일관성을 관리하는 기준이 된다.
애그리거트 단위로 일관성을 관리하기 때문에 복잡한 도메인을 단순한 구조로 만들어 준다.
복잡도가 낮아지는 만큼 도메인 기능을 확장/변경하는데 노력도 줄어든다.
1.1. 애그리거트 나누기
애그리거트는 관련된 모델을 하나로 모았기 때문에 보통 한 애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다.
예) 주문 애그리거트를 만들려면 Order, OrderLine 등과 같은 객체를 함께 생성해야 함
Order 를 생성했는데 ShippingInfo 는 만들지 않는 경우는 없음
도메인 규칙에 따라 최초 주문 시점에 일부 객체를 만들 필요가 없는 경우도 있지만 애그리거트에 속한 구성 요소는 대부분 함께 생성되고 함께 제거된다.
위 그림처럼 애그리거트는 경계를 갖는다.
한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않는다.
애그리거트는 독립된 객체군이며, 각 애그리거트는 자기 자신만 관리할 뿐 다른 애그리거트를 관리하지 않는다.
예) 주문 애그리거트는 배송지를 변경하는 등 자기 자신은 관리하지만, 회원의 비밀번호를 변경하지는 않음
애그리거트 경계를 설정할 때 기본이 되는 것은 도메인 규칙과 요구사항이다.
도메인 규칙에 따라 함께 생성되는 구성 요소는 한 애그리거트에 속할 가능성이 높다.
예) 주문할 상품 개수, 배송지 정보, 주문자 정보는 주문 시점에 함께 생성되므로 이것들은 한 애그리거트에 속함
사용자 요구사항에 따라 주문 상품 개수와 배송지를 함께 변경하기도 하는데 이렇게 함께 변경되는 빈도가 높은 객체는 한 애그리거트에 속할 가능성이 높다.
‘A가 B를 갖는다’ 로 설계할 수 있는 요구사항이 있을 때 A, B를 한 애그리거트로 묶어서 생각하기 쉬운데 이는 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하지 않는다.
예) 상품 상세 페이지에 들어가면 상품 상세 정보와 함께 리뷰 내용을 보여주기 때문에 Product 와 Review 를 한 애그리거트에 속한다고 할 수 있지만 사실은 아님
Product 와 Review 는 함께 생성되지 않고, 함께 변경되지도 않음
또 Product 의 변경 주체는 상품 담당자이고, Review 의 변경 주체는 고객임
즉, Product 와 Review 는 함께 생성되거나 변경되지 않고 변경 주체도 다르기 때문에 서로 다른 애그리거트에 속함
또 Review 의 변경이 Product 에 영향을 주지 않고 반대도 마찬가지임
도메인 규칙을 제대로 이해할수록 애그리거트의 실제 크기는 줄어든다.
설계를 하다보면 다수의 애그리거트가 한 개의 엔티티 객체만 갖는 경우가 많고, 2개 이상의 엔티티로 구성되는 애그리거트는 드물다.
2. 애그리거트 루트
주문 애그리거트는 아래를 포함한다.
- totalAmounts 를 갖는 Order 엔티티
- 개별 구매 상품의 개수인 quantity 와 price 를 갖고 있는 OrderLine 밸류
구매할 상품 개수를 변경하면 한 OrderLine 의 quantity 를 변경하고, Order 의 totalAmounts 도 변경해야 한다.
그렇지 않으면 도메인 규칙을 어기고 데이터 일관성이 깨진다.
애그리거트는 여러 객체로 구성되기 때문에 한 객체만 정상이면 안된다.
주문 애그리거트에서는 OrderLine 을 변경하면 Order 의 totalAmounts 도 다시 계산하여 총 금액이 맞아야 한다.
애그리거트에 속한 모든 객체가 일관된 상태를 유지하려면 애그리거트 전체를 관리할 주체가 필요한데 이 책임을 지는 것이 바로 애그리거트 루트 엔티티이다.
애그리거트에 속한 객체는 애그리거트 루트 엔티티에 직접 또는 간접적으로 속하게 된다.
주문 애그리거트에서 루트 역할을 하는 엔티티는 Order 엔티티이다.
그 외의 OrderLine, ShippingInfo 등 주문 애그리거트에 속한 모델은 Order 에 직접 또는 간접적으로 속한다.
애그리거트의 상태는 커맨드 중 하나를 슬행해서만 수정이 되어야 한다.
애그리거트가 엔티티의 계층 구조이므로 그 중 하나만 애그리거트의 public 인터페이스, 즉 애그리거트 루트로 지정되어야 한다.
1. 도메인 모델 의 예를 보자.
아래는 티켓 애그리거트의 일부이다.
public class Ticket {
// ...
List<Message> messages;
public void execute(AcknowledgeMessage cmd) {
Message message = messages.where(x -> x.id == cmd.id).first();
message.wasRead = true;
}
// ...
}
애그리거트는 특정 메시지의 읽음 상태를 수정할 수 있는 커맨드를 노출한다.
이 오퍼레이션은 Message 엔티티의 인스턴스를 수정하지만, 애그리거트 루트인 Ticket 을 통해서만 접근할 수 있다.
애그리거트 루트의 public 인터페이스 외에도 외부에서 애그리거트와 통신할 수 있는 다른 메커니즘이 있는데 바로 도메인 이벤트이다.
도메인 이벤트에 대한 내용은 2.3.1. 한 트랜잭션에서 여러 애그리거트 수정: 도메인 이벤트 를 참고하세요.
2.1. 도메인 규칙과 일관성
애그리거트의 상태는 변경될 수 있기 때문에 데이터가 손상될 여러 경로가 있다.
데이터의 일관성을 강화하려면 애그리거트에 명확한 경계를 설정해야 한다.
즉, 애그리거트는 일관성을 강화하는 경계이다.
애그리거트의 로직은 모든 들어오는 변경 요청을 검사해서 그 변경이 애그리거트의 비즈니스 규칙에 위배되지 않게 해야 한다.
애그리거트 루트는 단순히 애그리거트에 속한 객체를 포함하는 것으로 끝나는 게 아니라 진짜 핵심 역할은 애그리거트의 일관성이 깨지지 않도록 하는 것이다.
이를 위해 애그리거트 루트는 애그리거트가 제공해야 할 도메인 기능을 구현한다.
예) 주문 애그리거트는 배송지 변경, 상품 변경과 같은 기능을 제공하고, 이 기능은 애그리거트 루트인 Order 가 제공함
애그리거트 루트가 제공하는 메서드는 도메인 규칙에 따라 애그리거트에 속한 객체의 일관성이 깨지지 않도록 구현해야 한다.
예) 배송이 시작되기 전까지만 배송지 정보 변경이 가능하다는 규칙에 맞게 Order 의 changeShippingInfo() 를 구현
// 주문 (애그리거트 루트)
public class Order {
// ...
// 애그리거트 루트는 도메인 규칙을 구현한 기능을 제공함
// 배송지 변경
public void changeShippingInfo(ShippingInfo newShipping) {
// 배송지 변경 가능 여부 확인
verifyNotYetShipped();
setShippingInfo(newShipping);
}
// 주문 취소
public void cancel() {
verifyNotYetShipped();
this.state = OrderState.CANCELED;
}
애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안된다. 이는 애그리거트 루트가 강제하는 규칙을 적용할 수 없어 모델의 일관성을 깨게 된다.
아래 코드를 보자.
ShippingInfo info = order.getShippingInfo();
info.setAddress(newAddress);
애그리거트 루트인 Order 에서 ShippingInfo 를 가져와서 직접 정보를 변경하고 있다.
주문 상태에 관계없이 배송지 주문을 변경하는 것은 업무 규칙을 무시하고 직접 DB 에서 데이터를 수정하는 것과 동일하다.
즉, 논리적인 데이터 일관성이 깨지게 된다.
일관성을 지키기 위해 응용 서비스에 상태 확인 로직을 넣을수도 있지만 이는 동일한 검사 로직을 여러 응용 서비스에서 중복으로 구현할 가능성이 높아져서 유지 보수에 도움이 되지 않는다.
ShippingInfo info = order.getShippingInfo();
// 주요 도메인 로직이 중복됨
if (state != OrderState.PAYMENT_WAITING && state != OrderState.PREPARING) {
throw new IllegalArgumentException();
}
info.setAddress(newAddress);
불필요한 중복을 피하고, 애그리거트 루트를 통해서만 도메인 로직을 구현하려면 도메인 모델에 아래 2가지를 적용해야 한다.
- 필드를 변경하는 setter 를 public 으로 하지 않음
- 밸류 타입은 불변으로 구현
2.1.1. 필드를 변경하는 setter 를 public 으로 하지 않음
애그리거트의 상태는 애그리거트 비즈니스 로직을 통해서만 변경이 되어야 한다.
애그리거트 외부에서는 애그리거트의 상태를 읽을 수만 있고, 애그리거트 public 인터페이스에 포함된 관련 메서드를 실행해야만 변경할 수 있어야 한다.
public setter 는 도메인 로직을 도메인 객체가 아닌 응용 영역이나 표현 영역으로 분산시킨다.
도메인 로직이 한 곳에 응집되지 않으므로 유지 보수할 때도 분석하고 수정하는데 많은 노력이 든다.
응용 영역, 표현 영역에 대한 좀 더 상세한 설명은 1. 4개의 영역 을 참고하세요.
도메인 모델의 엔티티나 밸류에 public setter 만 넣지 않아도 일관성이 깨질 가능성이 줄어들고, 의미가 드러나는 메서드를 사용해서 구현할 가능성이 높아진다.
예) public setter 가 없으면 cancel(), changePassword() 처럼 의미가 잘 드러나는 이름을 사용하는 빈도가 높아짐
애그리거트의 public 인터페이스는 입력값의 유효성을 검사하고, 관련된 모든 비즈니스 규칙과 불변성을 강화한다.
즉, 애그리거트와 관련된 모든 비즈니스 로직은 애그리거트 자체 한 곳에서 구현되어야 한다.
모든 비즈니스 로직이 한 곳에서 구현되면 애그리거트에서 애플리케이션 계층(서비스 계층) 의 조율 동작을 좀 더 간단하게 만들 수 있다.
각 계층에 대한 설명은 1. 4개의 영역 을 참고하세요.
즉, 조율 동작에서 해야하는 모든 일은 결국 애그리거트의 현재 상태를 적재해서 필요한 동작을 수행하고, 수정된 상태를 저장한 후, 오퍼레이션의 결과를 호출자에게 반환하는 것이다.
2.1.1.1. 커맨드(command) 구현 방식
애그리거트의 public 인터페이스로 노출된 상태 변경을 ‘어떤 것을 지시하는 명령’이라는 의미에서 커맨드(command)라고 한다.
커맨드는 2가지로 구현할 수 있다.
- 파라미터를 각각 받는 방식
- 커맨드 실행에 필요한 모든 입력값을 포함하는 파라미터 객체로 받는 방식
파라미터로 각각 받는 방식
// 애그리거트
public class Person {
// ...
public void address(UserId from, String body) {
String message = new Message(from, body);
}
}
파라미터 객체로 받는 방식
// 애그리거트
public class Person {
// ...
public void address(MessageCommand cmd) {
String message = new Message(cmd.from, cmd.body);
}
}
어떤 방식으로 해도 상관없지만 명시적으로 커맨드 구조를 정의하여 다형적으로 전달하는 것을 더 권장한다. (= 파라미터 객체로 받는 방식)
2.1.2. 밸류 타입은 불변으로 구현
밸류 객체의 값을 변경할 수 없으면 애그리거트 루트에서 밸류 객체를 구해도 애그리거트 외부에서 밸류 객체의 상태를 변경할 수 없다.
밸류 타입에 대한 좀 더 상세한 내용은 4.3. 밸류 타입 을 참고하세요.
/order/domain/ShippingInfo.java
// 배송지 정보
@RequiredArgsConstructor
@Getter
@EqualsAndHashCode // 밸류 타입
public class ShippingInfo {
private final Receiver receiver;
private final Address address;
}
ShippingInfo info = order.getShippingInfo();
// ShippingInfo 가 불변이면 컴파일 오류남
info.setAddress(newAddress);
애그리거트 외부에서 내부 상태를 변경할 수 없으므로 애그리거트의 일관성이 깨질 가능성이 줄어든다.
밸류 객체가 불변이면 밸류 객체의 값을 변경하는 방법은 아래와 같이 애그리거트 루트가 제공하는 메서드에 새로운 밸류 객체를 전달해서 값을 변경하는 방법 뿐이다.
즉, 밸류 타입의 내부 상태를 변경하려면 애그리거트 루트를 통해서만 가능하다.
// 주문 (애그리거트 루트)
public class Order {
// ...
// 배송지 변경
public void changeShippingInfo(ShippingInfo newShipping) {
// 배송지 변경 가능 여부 확인
verifyNotYetShipped();
setShippingInfo(newShipping);
}
// 배송지 정보 검사 후 배송지 값 설정
private void setShippingInfo(ShippingInfo newShippingInfo) {
// 배송지 정보는 필수임
if (newShippingInfo == null) {
throw new IllegalArgumentException("no shippingInfo");
}
// 밸류가 불변이면 새로운 객체를 할당해서 값을 변경해야 함
// 즉, 아래와 같은 코드는 사용 불가
// this.shippingInfo.setAddress(newShippingInfo.getAddress())
// 밸류 타입의 데이터를 변경할 때는 새로운 객체로 교체함
this.shippingInfo = newShippingInfo;
}
}
만일 팀 표준이나 기술 제약으로 밸류 타입을 불변으로 구현할 수 없다면 해당 밸류의 변경 기능을 패키지나 protected 범위로 한정해서 외부에서 실행할 수 없도록 제한하는 방법도 있다.
보통 한 애그리거트에 속하는 모델은 한 패키지에 속하기 때문에 protected 범위를 사용하면 애그리거트 외부에서 상태 변경 기능을 실행하는 것을 방지할 수 있다.
2.1.3. 애그리거트의 동시성 관리
애그리거트 상태의 일관성을 유지하려면 여러 프로세스가 동시에 동일한 애그리거트를 갱신하려고 할 때 첫 번째 트랜잭션이 커밋한 변경을 나중의 트랜잭션이 덮어쓰지 않게 해야 한다.
따라서 애그리거트를 저장하는 DB 에서 동시성 관리를 지원해야 한다.
가장 간단한 방식은 매번 갱신할 때마다 증가하는 버전 필드를 애그리거트에서 관리하는 것이다.
class Person {
PersonId id;
int _version;
}
DB 에서 변경을 커밋할 때 덮어쓰려는 버전이 처음에 읽었던 원본의 버전과 동일할 때만 애그리거트 인스턴스의 상태를 반영하고, 버전 카운터를 증가시킨다.
UPDATE Person
SET age = @age,
agg_version = agg_version + 1
WHERE id = @id
AND agg_version = @version;
2.2. 애그리거트 루트의 기능 구현
애그리거트 루트는 애그리거트 내부의 다른 객체를 조합해서 기능을 완성한다.
아래는 애그리거트 루트인 Order 가 총 주문 금액을 구하기 위해 OrderLine 목록을 사용하는 예시이다.
/order/command/domain/Order.java
// 주문 (애그리거트 루트)
public class Order {
// ...
private List<OrderLine> orderLines; // 주문 항목
private Money totalAmounts; // 총 주문 금액
// 총 주문 금액 계산
private void calculateTotalAmounts() {
int sum = orderLines.stream()
.mapToInt(x -> x.getAmounts().getValue())
.sum();
this.totalAmounts = new Money(sum);
}
// ...
}
아래는 회원의 애그리거트 루트인 Member 가 암호를 변경하기 위해 Password 밸류에 암호가 일치하는지 확인하는 예시이다.
/member/command/domain/Member.java
// 회원 (애그리거트 루트)
public class Member {
private Password password;
public void changePassword(String currentPassword, String newPassword) {
if (!password.match(currentPassword)) {
throw new PasswordNotMatchingException();
}
// 밸류 타입의 데이터를 변경할 때는 새로운 객체로 교체함
this.password = new Password(newPassword);
}
}
/member/command/domain/Password.java
@Getter
@RequiredArgsConstructor
@EqualsAndHashCode // 밸류 타입
public class Password {
private final String value;
// 기존 암호와 일치하는지 확인
public boolean match(String password) {
return this.value.equals(password);
}
}
/member/command/PasswordNotMatchingException.java
public class PasswordNotMatchingException extends RuntimeException {
}
2.3. 트랜잭션 범위
트랜잭션의 범위는 작을수록 좋다.
한 트랜잭션이 한 개 테이블을 수정하는 것과 3개의 테이블을 수정하는 것을 비교하면 성능에서 차이가 발생한다.
트랜잭션 충돌을 막기 위해 잠그는 테이블의 대상이 많아지면 그만큼 동시에 처리할 수 있는 트랜잭션 수가 줄어든다는 것을 의미하고, 이것은 전체적인 성능을 떨어뜨린다.
동일하게 한 트랜잭션에서는 한 개의 애그리먼트만 수정해야 한다.
이 말을 애그리거트에서 다른 애그리거트를 변경하지 않는다는 것을 의미한다.
한 트랜잭션에서 두 개 이상의 애그리거트를 수정하면 트랜잭션 충돌이 발생할 가능성이 더 높아지기 때문에 한 번에 수정하는 애그리거트 개수가 많아질수록 전체 처리량이 떨어지게 된다.
아래는 배송지 정보를 변경하면서 동시에 배송지 정보를 회원의 주소로 설정하는 기능의 예시이다.
이 때 주문 애그리거트는 회원 애그리거트의 정보를 변경하면 안된다.
안 좋은 예시
public class Order {
private Orderer orderer;
public void shipTo(ShippingInfo newShipping) {
// 배송지 변경 가능 여부 확인
verifyNotYetShipped();
setShippingInfo(newShipping);
if (userNewShippingAddrAsMemerAddr) {
// 다른 애그리거트의 상태를 변경하면 안됨!!
orderer.getMember().changeAddress(newShippingInfo.getAddress());
}
}
위와 같은 코드는 애그리거트가 자신의 책임 범위를 넘어서 다른 애그리거트의 상태까지 관리하게 된다.
애그리거트는 최대한 서로 독립적이어야 하는데 한 애그리거트가 다른 애그리거트의 기능에 의존하기 시작하면 애그리거트 간 결합도가 높아지고, 결합도가 높아질수록 향후 수정 비용이 증가하게 된다.
만일 부득이하게 한 트랜잭션으로 두 개 이상의 애그리거트를 수정해야 한다면 애그리거트에서 다른 애그리거트를 직접 수정하지 말고, 응용 서비스에서 두 애그리거트를 수정하도록 구현한다.
public class ChangeOrderService {
// 2개 이상의 애그리거트를 변경해야 한다면 응용 서비스에서 각 애그리거트의 상태를 변경함
@Transactional
public void changeShippingInfo(OrderId id, ShippingInfo newShippingInfo
, boolean userNewShippingAddrAsMemberAddr) {
Order order = orderRepository.findById(id);
if (order == null) {
throw new OrderNotFoundException();
}
// 배송지 정보 변경 (주문 애그리거트)
order.shipTo(newShippingInfo);
// 회원 주소 변경 (회원 애그리거트)
if (userNewShippingAddrAsMemberAddr) {
Member member = findMember(order.getOrderer());
member.changeAddress(userNewShippingAddrAsMemberAddr);
}
}
}
2.3.1. 한 트랜잭션에서 여러 애그리거트 수정: 도메인 이벤트
도메인 이벤트를 사용하면 한 트랜잭션에서 한 개의 애그리거트를 수정하면서 동기 혹은 비동기로 다른 애그리거트의 상태를 변경하는 코드를 작성할 수 있다.
위에 대한 좀 더 상세한 내용은 DDD - 이벤트(2): 비동기 이벤트 처리 를 참고하세요.
<한 트랜잭션에서 2개 이상의 애그리거트를 변경하는 것을 고려할 수 있는 경우>
- 팀 표준
- 사용자 유스케이스와 관련된 응용 서비스의 기능을 한 트랜잭션으로 실행해야 하는 경우
- 기술 제약
- 기술적으로 이벤트 방식을 도입할 수 없는 경우 한 트랜잭션에서 다수의 애그리거트를 수정하여 일관성 처리
- UI 구현의 편리성
- 운영상 편리를 위해 주문 목록 화면에서 여러 주문 상태를 한 번에 변경하고자 할 때 한 트랜잭션에서 여러 주문 애그리거트의 상태 변경
2.3.1.1. 도메인 이벤트
도메인 이벤트는 비즈니스 도메인에서 일어나는 이벤트를 설명하는 메시지이다.
1. 도메인 모델 을 예시로 보자.
- 티켓이 할당됨
- 티켓이 상부에 보고됨
- 메시지가 수신됨
도메인 이벤트는 이미 발생된 것이기 때문에 과거형으로 명명한다.
도메인 이벤트의 목적은 비즈니스 도메인에서 일어난 일을 설명하고, 이벤트와 관련된 모든 필요한 데이터를 제공하는 것이다.
예를 들어 아래 도메인 이벤트는 언제, 무슨 이유로 특정 티켓이 상부에 보고되었는지 설명한다.
{
"ticket-id": "1234",
"event-id": 1,
"event-type": "ticket-escalated",
"escalation-reason": "missed-sla",
"escalation-time": 124837458
}
다른 프로세스, 애그리거트, 외부 시스템도 도메인 이벤트를 구독할 수 있고, 도메인 이벤트에 반응하는 자신만의 로직을 실행할 수 있다.
도메인 이벤트 구독자에게 도메인 이벤트를 안정적으로 게시하는 방법에 대해서는 2. 애그리거트 연동 을 참고하세요.
3. 리포지터리와 애그리거트
애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 객체의 영속성을 처리하는 리포지터리는 애그리거트 단위로 존재한다.
예) Order 와 OrderLine 을 물리적으로 각각 별도의 DB 테이블에 저장한다고 해서 Order 와 OrderLine 을 위한 리포지터리를 각각 만드는 것이 아님
Order 가 애그리거트 루트이고, OrderLine 은 애그리거트에 속하는 구성 요소이므로 Order 를 위한 리포지터리만 존재함
ORM 기술 중 하나인 JPA 를 사용하면 DB 관계형 모델에 객체 도메인 모델을 맞춰야 할 때도 있다.
이 때 밸류 타입인 도메인 모델을 JPA 에서 밸류 타입을 매핑할 때 사용하는 @Component 가 아닌 엔티티를 매핑할 때 사용하는 @Entity 를 이용해야 할 수도 있다.
애그리거트는 개념적으로 하나이므로 리포지터리는 애그리거트 전체를 저장소에 영속화해야 한다.
예) Order 애그리거트와 관련된 테이블이 3개라면 Order 애그리거트를 저장할 때 애그리거트 루트와 매핑되는 테이블 뿐 아니라 애그리거트에 속한 모든 구성 요소에 매핑된 테이블에 데이터를 저장해야 함
// 리포지터리에 애그리거트를 저장하면 애그리거트 전체를 영속화해야 함
orderRepository.save(order);
비슷하게 애그리거트를 구하는 리포지터리 메서드도 완전한 애그리거트를 제공해야 한다.
즉, 아래처럼 Order 를 조회하면 order 애그리거트는 OrderLine, Orderer 등 모든 구성 요소를 포함하고 있어야 한다.
리포지터리가 완전한 애그리거트를 제공하지 않으면 필드나 값이 올바르지 않아 애그리거트의 기능을 실행하는 도중에 NPE 와 같은 문제가 발생할 수 있다.
// 완전한 order 를 제공해야 함
Order order = orderRepository.findById(orderId);
// order 가 완전한 애그리거트가 아니면 기능 실행 도중 NPE 와 같은 문제 발생
order.cancel();
RDBMS 와 JPA 를 이용하여 리포지터리를 구현하는 방법은 DDD - 리포지터리(1): 엔티티와 JPA 매핑 구현, 엔티티와 밸류 매핑(@Embeddable, @AttributeOverrides, AttributeConverter), 기본 생성자, 필드 접근 방식(@Access), 밸류 컬렉션 매핑 을 참고하세요.
4. 애그리거트 참조
애그리거트도 다른 애그리거트를 참조한다.
애드리거트 관리 주체는 애그리거트 루트이므로 애그리거트에서 다른 애그리거트를 참조한다는 것은 다른 애그리거트의 루트를 참조한다는 것과 같다.
애그리거트 간의 참조는 필드를 통해 쉽게 구현 가능하다.
아래는 주문 애그리거트에 속해있는 Orderer 로 주문한 회원을 참조하기 위해 회원 애그리거트 루트인 Member 를 필드 참조하는 예시이다.
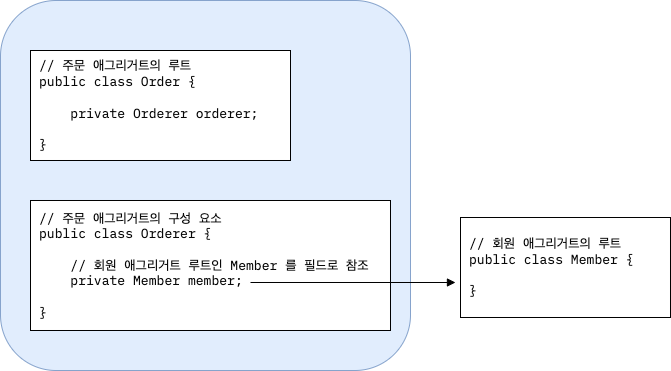
필드를 이용해서 다른 애그리거트를 참조하는 것은 개발의 편리성을 더해준다.
아래는 주문 정보 조회 화면에서 회원 ID 를 이용해야 할 경우 Order 로부터 회원 ID 를 구하는 예시이다.
order.getOrderer().getMember().getId();
JPA 는 @ManyToOne, @OneToOne 등의 애너테이션을 이용하여 연관된 객체를 로딩하는 기능을 제공하고 있기 때문에 필드를 이용하여 다른 애그리거트를 쉽게 참조할 수 있다.
4.1. 필드를 이용한 애그리거트 참조
애그리거트 간 참조를 필드가 아닌 ID 를 통해 참조하는 것이 좋으므로 아래 내용은 참고만 할 것
필드를 이용하여 애그리거트 참조를 쉽게 구현 가능하지만, 필드를 이용한 애그리거트 참조(=애그리거트 내의 모든 객체는 같은 트랜잭션 경계를 공유하므로 애그리거트가 너무 커지면)는 아래와 같은 문제점을 야기할 수 있다.
- 편한 참조의 오용
- 성능에 대한 고민
- 확장의 어려움
애그리거트는 가능한 작게 유지하고, 비즈니스 로직에 따라 강력하게 일관적으로 상태를 유지할 필요가 있는 객체만 포함한다.
4.1.1. 편한 참조의 오용
한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다른 애그리거트의 상태를 쉽게 변경할 수 있다.
한 애그리거트가 관리하는 범위는 자기 자신으로 한정해야 하는데 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 구현의 편리함 때문에 다른 애그리거트를 수정하는 코드를 작성할 수도 있다.
안 좋은 예시
public class Order {
private Orderer orderer;
// 배송지 변경
public void changeShippingInfo(ShippingInfo newShipping, boolean useNewShippingAddrAsMemberAddr) {
// ...
if (useNewShippingAddrAsMemberAddr) {
// 한 애그리거트 내부에서 다른 애그리거트에 접근할 수 있으면 구현이 쉬워진다는 편리함 때문에
// 다른 애그리거트의 상태를 변경하고자 하는 유혹에 빠질 수 있음
orderer.getMember().changeAddress(newShipping.getAddress());
}
}
}
한 애그리거트에서 다른 애그리거트의 상태를 변경하는 것은 애그리거트 간의 의존 결합도를 높이기 때문에 결과적으로 애그리거트의 변경을 어렵게 만든다.
4.1.2. 성능에 대한 고민
애그리거트를 직접 참조하면 성능과 관련된 여러가지 고민을 해야 한다.
JPA 를 사용하면 참조한 객체를 지연(lazy) 로딩과 즉시(eager) 로딩, 두 가지 방식으로 로딩할 수 있다.
단순히 연관된 객체의 데이터를 함께 보여줘야 하는 경우엔 즉시 로딩이 조회 성능에 유리하지만, 애그리거트의 상태를 변경하는 기능을 실행하는 경우에는 불필요한 객체를 함께 로딩할 필요가 없으므로 지연 로딩이 유리하다.
이런 다양한 경우의 수를 고려하여 연관 매핑과 JPQL/Criteria 쿼리의 로딩 전략을 결정해야 한다.
4.1.3. 확장의 어려움
서비스가 확장될수록 부하를 분산하기 위해 하위 도메인별로 시스템을 분리하기 시작한다.
이 과정에서 하위 도메인마다 서로 다른 DBMS 를 사용하기도 하는데, 이것은 더 이상 다른 애그리거트 루트를 참조하기 위해 JPA 와 같은 단일 기술을 사용할 수 없음을 의미한다.
예) 한 하위 도메인은 몽고 DB 를 사용하고, 한 하위 도메인은 마리아 DB 사용
4.2. ID 를 이용한 애그리거트의 간접 참조
필드를 이용하여 애그리거트를 참조할 때 발생하는 문제들을 완화해주는 것이 ID 를 이용하여 다른 애그리거트를 참조하는 것이다.
DB 에서 외래키를 참조하는 것과 비슷하게 ID 를 이용한 참조는 다른 애그리거트를 참조할 때 ID 를 사용한다.
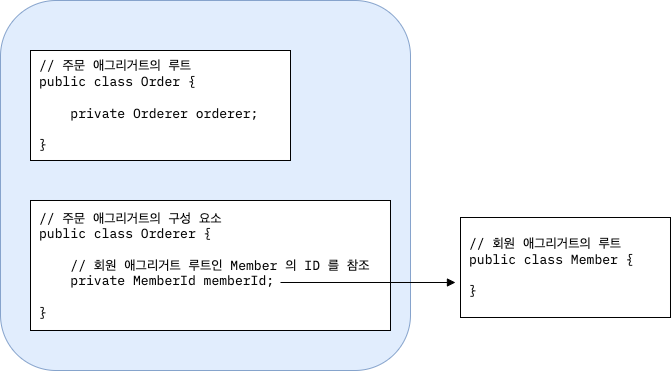
ID 참조를 사용하면 모든 객체가 참조로 연결되는 것이 아니기 때문에 한 애그리거트에 속한 객체들만 참조로 연결된다.
따라서 애그리거트의 경계를 명확히 하고, 애그리거트 간 물리적인 연결을 제거하기 때문에 모델의 복잡도를 낮춰준다.
애그리거트 간 의존를 제거하므로 응집도를 높여주고, 구현 복잡도도 낮아진다.
또한 각 애그리거트가 자신의 트랜잭션 경계를 갖도록 보장할 수 있다.
다른 애그리거트를 직접 참조하지 않으므로 애그리거트 간 참조를 지연 로딩으로 할지 즉시 로딩으로 할지 고민하지 않아도 된다.
참조하는 애그리거트가 필요하면 응용 서비스에서 ID 를 이용하여 로딩하면 된다.
public class ChangeOrderService {
@Transactional
public void changeShippingInfo(OrderId id, ShippingInfo newShippingInfo, boolean useNewShippingAddrAsMemberAddr) {
Order order = orderRepository.findById(id);
if (order == null) {
throw new OrderNotFoundException();
}
// 배송지 정보 변경
order.changeShippingInfo(newShippingInfo);
if (useNewShippingAddrAsMemberAddr) {
// ID 를 이용하여 참조하는 애그리거트를 구함
Member member = memberRepository.findById(order.getOrderer().getMemberId());
member().changeAddress(newShipping.getAddress());
}
}
}
응용 서비스에서 필요한 애그리거트를 로딩하기 때문에 애그리거트 수준에서 지연 로딩을 하는 것과 동일한 결과를 만든다.
또한 한 애그리거트에서 다른 애그리거트를 직접 참조하지 않기 때문에 다른 애그리거트를 수정하는 문제를 근원적으로 방지할 수 있다.
애그리거트별로 다른 구현 기술을 사용하는 것도 가능해지고, 각 도메인을 별도의 프로세스로 서비스하도록 구현할 수도 있다.
1. 도메인 모델 의 예시를 보자.
public class Ticket {
private UserId customerId;
private List<ProductrId> products;
private UserId assignedAgentId;
private List<Message> messages;
}
‘에이전트가 상부 보고된 티켓의 응답 제한 시간의 절반이 지나기 전에 티켓을 열람하지 않으면 자동으로 다른 에이전트가 할당됨’ 을 보자.
만일 어느 정도 지연이 된 후 티켓을 열람했다는 알림을 받는다면 상당수의 티켓이 불필요하게 재할당될 것이므로 시스템의 상태가 손상된다.
따라서 위 코드에서 메시지의 데이터는 애그리거트의 경계에 속하므로 필드 참조로 구성하였고, 그 외 나머지는 ID 참조를 하고 있다.
4.2.1. ID 를 이용한 참조와 조회 성능: N+1 조회 문제
다른 애그리거트를 ID 로 참조하면 참조하는 여러 애그리거트를 읽을 때 조회 속도에 문제가 될 수도 있다.
예를 들어 주문 목록을 보여주기 위해 상품 애그리거트와 회원 애그리거트를 함께 읽어와야 한다면 아래처럼 각 주문마다 상품과 회원 애그리거트를 읽어와야 한다.
하나의 DBMS 에 데이터가 있으면 조인을 이용하여 한 번에 모든 데이터를 가져올 수 있음에도 불구하고 주문마다 상품, 회원 정보를 읽어오는 쿼리를 실행하게 된다.
Member member = memberRepository.findById(orderId);
List<Order> orders = orderRepository.findByOrderer(ordererId);
List<OrderView> dtos = orders.stream()
.map(order -> {
ProductId prodId = order.getOrderLines().get(0).getProductId();
// 각 주문마다 첫 번째 주문 상품 정보 로딩을 위한 쿼리 실행
Product product = productRepository.findById(prodId);
return new OrderView(order, member, product);
}).collect(toList());
위 코드는 주문 개수가 10개면 주문을 읽어오기 위한 1번의 쿼리와 주문별로 각 상품을 읽어오기 위한 10번의 쿼리를 실행한다.
‘조회 대상이 N개 일 때 N개를 읽어오는 한 번의 쿼리와 연관된 데이터를 읽어오는 쿼리를 N번 실행한다’ 해서 이를 N+1 조회 문제 라고 한다.
ID 를 이용한 애그리거트 참조는 지연 로딩과 같은 효과를 만드는데, 지연 로딩과 관련된 대표적인 문제가 바로 N+1 조회 문제 이다.
N+1 조회 문제 는 더 많은 쿼리를 실행하기 때문에 전체 조회 성능에 영향을 미친다.
이 문제를 발생하지 않도록 하려면 조인을 사용해야 하고, 조인을 사용하는 가장 쉬운 방법을 ID 참조 방식을 객체 참조 방식으로 바꾼 후 즉시 로딩을 사용하도록 매핑 설정을 하는 것인데 이것은 애그리거트 간 참조를 ID 참조에서 다시 객체 참조 방식으로 되돌리는 것이다.
ID 참조 방식을 사용하면서 N+1 조회 문제 가 발생하지 않도록 하려면 조회 전용 쿼리를 사용하면 된다.
예를 들어 데이터 조회를 위한 DAO 를 만들고, DAO 의 조회 메서드에서 조인을 이용하여 한 번의 쿼리로 필요한 데이터를 로딩한다.
DAO 에 대한 좀 더 상세한 내용은 9. Spring bean, Java bean, DTO, VO, DAO 를 참고하세요.
@Repository
public class JpaOrderViewDao implements OrderViewDao {
@PersistenceContext
private EntityManager em;
@Override
public List<OrderView> selectByOrderer(String ordererId) {
String selctQuery =
"select ew com.assu.study.order.application.dto.OrderView(o, m, p) " +
"from Order o join o.orderLines ol, Member m, Product p " +
"where o.orderer.memberId = m.id " +
"and index(ol) = 0 " +
"and ol.productId = p.id " +
"order by o.number desc";
TypedQuery<OrderView> query = em.createQuery(selctQuery, OrderView.class);
query.setParameter("orderId", orderId);
return query.getRresultList();
}
}
위 쿼리는 JPQL 을 사용하는데 즉시 로딩이나 지연 로딩과 같은 로딩 전략을 고민할 필요 없이 한번에 필요한 애그리거트 데이터를 로딩한다.
쿼리가 복잡하거나 SQL 에 특화된 기능을 사용해야 한다면 마이바티스와 같은 기술을 이용해서 구현할 수도 있다.
애그리거트마다 서로 다른 저장소를 사용하면 한 번의 쿼리로 관련 애그리거트를 조회할 수 없다.
이 때는 조회 성능을 높이기 위해 캐시를 적용하거나 조회 전용 저장소를 따로 구성한다.
이 방법은 코드가 복잡해지는 단점이 있지만 시스템 처리량을 높일 수 있다는 장점이 있고, 특히 한 대의 DB 장비로 대응할 수 없는 수준의 트래픽이 발생하는 경우엔 캐시나 조회 전용 저장소를 선택이 아닌 필수이다.
JPA 에서 조회 전용 쿼리를 실행하는 방법은
DDD - 스펙(1): 스펙 구현, 스펙 사용,
DDD - 스펙(2): 스펙 조합, Sort, 페이징(Pageable), 스펙 빌더 클래스, 동적 인스턴스 생성, @Subselect, @Immutable, @Synchronize 를 참고하세요.
CQRS 을 통해 명령 모델과 조회 전용 모델을 분리해서 구현할 수 있는데 이 방법에 대해서는 DDD - CQRS 를 참고하세요.
5. 애그리거트 간 집합 연관
5.1. 애그리거트 간 1-N 연관 관계
애그리거트 간 1-N 연관 관계의 대표적인 예시는 카테고리와 상품 간의 연관이다.
카테고리 입장에서 한 카테고리에 한 개 이상의 상품이 속할 수 있으니 카테고리와 상품은 1-N 관계이다.
한 상품이 한 카테고리에만 속할 수 있다면 상품과 카테고리 관계는 N-1 관계이다.
애그리거트 간 1-N 관계는 Set 과 같은 컬렉션을 이용해서 표현할 수 있다.
안 좋은 예시
public class Category {
private Set<Product> products; // 다른 애그리거트에 대한 1-N 연관 관계
}
하지만 개념적으로 존재하는 애그리거트 간의 1-N 관계를 실제 구현에 반영하는 것은 어려울 경우가 많다.
예를 들어 특정 카테고리에 속한 상품 목록을 보여주는 화면이라면 페이징을 이용하여 상품을 나눠서 보여준다.
안 좋은 예시
public class Category {
private Set<Product> products;
public List<Product> getProducts(int page, int size) {
List<Product> sortedProducts = sortById(products);
return sortedProducts.subList((page-1)*size, page*size);
}
}
이 코드를 실제 반영하게 되면 Category 에 속한 모든 Product 를 조회하게 되므로 성능에 심각한 문제를 야기한다.
개념적으로 애그리거트 간에 1-N 연관이 있더라도 이런 성능 문제 때문에 애그리거트 간의 1-N 연관을 실제 구현에 반영하지 않는다.
카테고리에 속한 상품을 구할 필요가 있다면 카테고리가 아닌 상품 입장에서 자신이 속한 카테고리를 N-1 연관을 지어서 구하면 된다.
이를 구현 모델에 반영하면 Product 에 Category 로의 연관을 추가하고, 그 연관을 이용하여 특정 Category 에 속한 Product 목록을 구하게 된다.
좋은 예시
public class Product {
private CategoryId categoryId;
}
카테고리에 속한 상품 목록을 제공하는 응용 서비스는 아래처럼 ProductRepository 를 이용하여 categoryId 가 지정한 카테고리 식별자인 Product 목록을 구한다.
좋은 예시
public class ProductListService {
public Page<Product> getProductOfCategory(Long categoryId, int page, int size) {
Category category = categoryRepository.findById(categoryId);
checkCategory(category);
List<Product> products = productRepository.findByCategoryId(category.getId(), page, size);
int totalCount = productRepository.countsByCategoryId(category.getId());
return new Page(page, size, totalCount, products);
}
}
5.2. 애그리거트 간 M-N 연관 관계: member of
M-N 연관은 개념적으로 양쪽 애그리거트에 컬렉션으로 연관을 만든다.
상품이 여러 카테고리에 속할 수 있다고 하면 카테고리와 상품은 M-N 연관 관계이다.
보통 특정 카테고리에 속한 상품 목록을 보여줄 때 목록 화면에서 각 상품이 속한 모든 카테고리를 보여주지는 않는다.
상품 상세 화면에 들어갔을 때 상품이 속한 모든 카테고리 정보를 노출해준다.
이러한 요구 사항으로 보면 카테고리에서 상품으로의 집합 연관은 필요하지 않다.
상품에서 카테고리로의 집합 연관만 존재하면 된다.
즉, 개념적으로는 상품과 카테고리가 양방향 M-N 관계이지만, 실제 구현에서는 상품에서 카테고리로의 단방향 M-N 연관만 적용하면 되는 것이다.
public class Product {
private Set<Category> categoryIds;
}
RDBMS 에서 M-N 연관은 조인 테이블을 이용한다.

JPA 를 이용하면 아래와 같은 매핑 설정을 사용하여 ID 참조를 이용한 M-N 단방향 연관을 구현할 수 있다.
/catalog/command/domain/product/Product.java
package com.assu.study.catalog.command.domain.product;
import com.assu.study.catalog.command.domain.category.CategoryId;
import jakarta.persistence.*;
import java.util.Set;
@Entity
@Table(name = "product")
public class Product {
@EmbeddedId
private ProductId id;
@ElementCollection // 값 타입 컬렉션
@CollectionTable(name = "product_category",
joinColumns = @JoinColumn(name = "product_id")) // 테이블명 지정
private Set<CategoryId> categoryIds;
}
@EmbeddedId와@Embeddable에 대한 좀 더 상세한 내용은 5.2.1. 키 클래스:@EmbeddedId과@Embeddable을 참고하세요.
@ElementCollection과@CollectionTable에 대한 좀 더 상세한 내용은 5.2.2.@ElementCollection과@CollectionTable를 참고하세요.
@ElementCollection에 대한 추가 설명은 3.10. ID 참조와 조인 테이블을 이용한 단방향 M-N 매핑 을 참고하세요.
/catalog/command/domain/product/ProductId.java
package com.assu.study.catalog.command.domain.product;
import jakarta.persistence.Embeddable;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import java.io.Serializable;
@EqualsAndHashCode // 밸류 타입
@Getter
@Embeddable
public class ProductId implements Serializable {
private String id;
private ProductId(String id) {
this.id = id;
}
public static ProductId of(String id) {
return new ProductId(id);
}
}
/catalog/command/domain/catalog/CatalogId.java
package com.assu.study.catalog.command.domain.category;
import jakarta.persistence.Embeddable;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import java.io.Serializable;
@EqualsAndHashCode // 밸류 타입
@Getter
@Embeddable
public class CategoryId implements Serializable {
private Long value;
private CategoryId(Long value) {
this.value = value;
}
public static CategoryId of(Long value) {
return new CategoryId(value);
}
}
위의 매핑은 카테고리 ID 목록을 보관하기 위해 밸류 타입의 대한 컬렉션 매핑을 사용하였다.
이 매핑을 사용하면 아래와 같이 JPQL 의 member of 연산자를 이용하여 특정 Category 에 속한 Product 목록을 구할 수 있다.
@Repository
public class JpaProductRepository implements ProductRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<Product> findByCategoryId(CategoryId catId, int page, int size) {
TypedQuery<Product> query = entityManager.createQuery(
"select p from Product p " +
"where :catId member of p.categoryIds",
Product.class
);
}
}
위에서 :catId member of p.categoryIds 는 categoryIds 컬렉션에 catId 로 지정한 값이 존재하는지 검사한다.
응용 서비스에서 이 기능을 활용하여 특정 카테고리에 속한 Product 목록을 구할 수 있다.
JPA 를 이용한 모델 매핑과 컬렉션을 사용할 때의 성능 관련 문제는
3.9.1. @Entity 로 매핑된 밸류를 컬렉션으로 매핑:@OneToMany,cascade,orphanRemoval, 1. 애그리거트 로딩 전략
을 참고하세요.
목록이나 상세 화면과 같은 조회 기능은 조회 전용 모델을 이용하여 구현하는 것이 좋다.
이에 대한 상세한 내용은 DDD - CQRS 를 참고하세요.
5.2.1. 키 클래스: @EmbeddedId 과 @Embeddable
하나의 엔티티에 @Id 를 하나 이상 쓰게 되면 매핑 오류가 발생하므로 복합 기본키를 사용할 때는 별도의 키 클래스를 생성해야 한다.
<키 클래스의 특징>
- 복합키는 별도의 키 클래스로 생성
- Serializable 을 implements 해야함
equals()와hashCode()를 오버라이드 해야함- 기본 생성자가 있어야 함 (
@NoArgsConstructor) - 키 클래스는 public 으로 생성해야 함
아래와 같이 @EmbeddedId 를 선언하여 키 클래스를 기본키로 사용하겠다고 선언하고, 키 클래스에는 @Embeddable 를 추가하여 사용한다.
@Entity
public class Book {
@EmbeddedId
private BookId id;
}
@Embeddable
@NoArgsConstructor
@EqualsAndHashCode
public class BookId implements Serializable {
private String author;
private String title;
}
5.2.2. @ElementCollection 과 @CollectionTable
@ElementCollection과@CollectionTable에 대한 좀 더 상세한 설명은 3.5. 밸류 컬렉션: 별도 테이블 매핑:@ElementCollection,@CollectionTable,@OrderColumn을 참고하세요.
primitive 타입은 자바에서 값 복사를 지원하므로 데이터 정합성을 가지지만 참조 타입은 참조 복사를 하므로 다른 객체에서 데이터를 조작할 수 있다.
따라서 객체(컬렉션) 은 참조 복사가 아닌 값 복사가 지원되어야 한다.
값 타입이란 참조 복사가 아닌 값 복사가 지원되는 객체 및 컬렉션을 의미한다.
값 타입 중 컬렉션에 대해 알아보자.
테이블은 컬렉션을 가질 수 없으므로 별도의 테이블을 구성해야 하고, 이렇게 만들어진 테이블은 엔티티 테이블과 구분되어야 한다.
값 타입 테이블은 본인이 속한 엔티티에 종속된다.
엔티티와 엔티티의 종속은 영속성 전이와 고아객체 제거로 구현되지만, 이 경우 값 타입 컬렉션임만 명시하면 종속 설정이 자동으로 이루어진다.
@ElementCollection 은 해당 컬렉션이 값 타입 컬렉션임을 표시하는 애너테이션이다.
@ElementCollection 은 targetClass 속성을 가지며, targetClass 속성은 컬럼이 매핑될 때의 타입을 지정한다.
보통 컬렉션은 제네릭으로 타입을 지정하므로 targetClass 를 설정하지 않으면 제네릭 타입에 맞춰서 타입이 정해진다.
값 타입 컬렉션은 지연 로딩 전략을 사용한다.
추가로 컬렉션 데이터가 저장될 테이블의 구체적인 설정을 하고 싶다면 @CollectionTable 애너테이션을 통해 설정한다.
package com.assu.study.catalog.command.domain.product;
import com.assu.study.catalog.command.domain.category.CategoryId;
import jakarta.persistence.*;
import java.util.Set;
@Entity
@Table(name = "product")
public class Product {
@EmbeddedId
private ProductId id;
@ElementCollection
@CollectionTable(name = "product_category",
joinColumns = @JoinColumn(name = "product_id"))
private Set<CategoryId> categoryIds;
}
6. 애그리거트를 팩토리로 사용: 팩토리 함수
예를 들어 상점이 여러 번 신고를 당해서 해당 상점이 더 이상 물건을 등록하지 못하도록 차단한 상태라고 해보자.
상품 등록 기능을 구현하는 응용 서비스는 아래와 같이 상품 계정이 차단 상태가 아닌 경우에만 상품을 생성할 수 있도록 구현할 수 있다.
나쁜 예시
public class RegisterProductService {
public ProductId registerNewProduct(NewProductRequest req) {
Store store = storeRepository.findById(req.getStoreId);
checkNull(store);
// Store 가 Product 를 생성할 수 있는 상태인지 확인함
if (store.isBlocked()) {
throw new StoreBlockedException();
}
ProductId id = productRepository.nextId();
Product product = new Product(id, store.getId(), .. 생략);
productRepository.save(product);
return id;
}
}
위 로직은 도메인 로직 처리가 응용 서비스에 노출되었다.
Store 가 Product 를 생성할 수 있는지 판단 후 Product 를 생성하는 것은 논리적으로 하나의 도메인 기능인데 이 도메인 기능을 응용 서비스에서 구현하고 있다.
이 도메인 기능을 넣기 위해 별도의 도메인 서비스나 팩토리 클래스를 만들어도 되지만, 이 기능을 Store 애그리거트에 구현해도 된다.
좋은 예시
public class Store {
public Product createProduct(ProductId newProductId, ... 생략) {
if (isBlocked) {
throw new StoreBlockedException();
}
return new Product(newProductId, getId(), .. 생략);
}
}
위의 createProduct() 는 Product 애그리거트를 생성하는 팩토리 역할을 하면서도 중요한 도메인 로직을 구현하고 있다.
팩토리 로직을 구현했으므로 이제 응용 서비스는 팩토리 기능을 이용하여 Product 를 생성할 수 있다.
팩토리 함수
팩토리 함수는 함수를 선언해서 함수 내부에서 객체를 생성하여 반환하는 함수임
팩토리 함수는 보통 객체 리터럴 형태로 객체를 생성하는 것과는 달리, 동적으로 객체를 생성함
매개변수를 받아서 새로운 객체를 생성한 후 이를 반환하는 형태임따라서 팩토리 함수를 사용하면 객체 생성에 필요한 로직을 모듈화하고, 재사용성을 높일 수 있음
좋은 예시
public class RegisterProductService {
public ProductId registerNewProduct(NewProductRequest req) {
Store store = storeRepository.findById(req.getStoreId);
checkNull(store);
ProductId id = productRepository.nextId();
Product product = store.createProcuct(id, ... 생략);
productRepository.save(product);
return id;
}
}
이제 응용 서비스에서 더 이상 Store 가 Product 를 생성할 수 있는 상태인지 확인하지 않는다.
Store 가 Product 를 생성할 수 있는지 확인하는 도메인 로직은 Store 에서 구현하고 있기 때문에 Product 생성 가능 여부를 확인하는 도메인 로직을 변경해도 도메인 영역의 Store 만 변경하면 되고, 응용 서비스는 영향을 받지 않으며, 도메인 응집도도 높아졌다.
이것이 애그리거트를 팩토리로 사용할 때 얻을 수 있는 장점이다.
애그리거트가 갖고 있는 데이터를 이용해서 다른 애그리거트를 생성해야 한다면 애그리거트에 팩토리 메서드를 구현하는 것을 고려해보는 것이 좋다.
위의 Product 의 경우 제품을 생성한 Store 의 식별자를 필요로 하는데 이는 Store 의 데이터를 이용해서 Product 를 생성한다는 의미이다.
또한 Product 를 생성하는 조건을 판단할 때도 Store 의 상태를 이용한다.
따라서 Store 에 Product 를 생성하는 팩토리 메서드를 추가하면 Product 생성 시 필요한 데이터의 일부를 직접 제공하면서 동시에 중요 도메인 로직을 함께 구현할 수 있다.
Store 애그리거트가 Product 애그리거트를 생성할 때 많은 데이터를 알아야 한다면 Product 애그리거트 생성을 Store 애그리거트가 아니라 다른 팩토리에 위임하는 방법도 있다.
다른 팩토리에 위임하더라도 차단 상태의 상점은 상품을 만들 수 없다는 도메인 로직은 한 곳에 계속 위치한다.
public class Store {
public Product createProduct(ProductId newProductId, ProductInfo pi) {
if (isBlocked) {
throw new StoreBlockedException();
}
return ProductFactory.create(newProductId, getId(), pi);
}
}
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 최범균 저자의 도메인 주도 개발 시작하기 와 블라드 코노노프 저자의 도메인 주도 설계 첫걸음을 기반으로 스터디하며 정리한 내용들입니다.
- 도메인 주도 개발 시작하기
- 도메인 주도 설계 첫걸음
- 책 예제 git
- @IdClass @EmbeddedId 의 활용 차이
- 값타입 컬렉션 (@ElementCollection, @CollectionTable)
- Parameter Object
