DDD - 바운디드 컨텍스트
in DEV on DDD, Bounded-context, Open-host-service, Anti-corruption-layer, Shared-kernel, Separate-way, Context-map
- 바운디드 컨텍스트
- 바운디드 컨텍스트 간 통합과 관계
매핑되는 테이블은 DDD - ERD 을 참고하세요.
DDD - 도메인 복잡성 관리: 바운디드 컨텍스트 와 함께 보면 도움이 됩니다.
목차
- 1. 도메인 모델과 경계
- 2. 바운디드 컨텍스트
- 3. 바운디드 컨텍스트 구현
- 4. 바운디드 컨텍스트 간 통합
- 5. 바운디드 컨텍스트 간 관계
- 6. 컨텍스트 맵
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- 언어: java
- Spring Boot ver: 3.2.5
- Spring ver: 6.1.6
- IDE: intelliJ
- SDK: JDK 17
- 의존성 관리툴: Maven
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.assu</groupId>
<artifactId>ddd_me</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ddd</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>annotationProcessor</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-jpamodelgen -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
<version>6.5.2.Final</version>
<type>pom</type>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/com.mysql/mysql-connector-j -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.bsc.maven</groupId>
<artifactId>maven-processor-plugin</artifactId>
<version>2.0.5</version>
<executions>
<execution>
<id>process</id>
<goals>
<goal>process</goal>
</goals>
<phase>generate-sources</phase>
<configuration>
<processors>
<processor>org.hibernate.jpamodelgen.JPAMetaModelEntityProcessor</processor>
</processors>
</configuration>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
<version>6.5.2.Final</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
</project>
spring.application.name=ddd
spring.datasource.url=jdbc:mysql://localhost:13306/shop?characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.hikari.maximum-pool-size=10
spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
spring.jpa.open-in-view=false
logging.level.root=INFO
logging.level.com.myshop=DEBUG
logging.level.org.springframework.security=DEBUG
1. 도메인 모델과 경계
도메인 모델을 만들 때 하기 쉬운 실수 중 하나가 도메인을 완벽하게 표현하는 단일 모델을 만들려고 하는 것이다.
하나의 도메인은 다시 여러 하위 도메인으로 구분되기 때문에 한 개의 모델로 여러 하위 도메인을 모두 표현하려고 시도하면 오히려 모든 하위 도메인에 맞지 않는 모델을 만들게 된다.
예를 들어 상품이라는 모델을 보았을 때 카탈로그에서의 상품과 재고 관리에서의 상품은 이름만 같지 실제 의미하는 바는 바르다.
카탈로그에서의 상품은 상품 이미지, 상품명 등 상품 정보가 위주이고, 재고관리에서의 상품은 실존하는 개별 객체를 추적하기 위한 목적으로 사용된다.
즉, 카탈로그에서는 물리적으로 하나인 개인 상품이 재고 관리에서는 여러 개 존재할 수 있다.
논리적으로 같은 것처럼 보이지만 하위 도메인에 따라 다른 용어를 사용하는 경우도 있다.
예를 들어 시스템을 사용하는 사람을 회원 도메인에서는 회원, 주문 도메인에서는 주문자, 배송 도메인에서는 배송자 라고 부르기도 한다.
이렇게 하위 도메인마다 같은 용어라고 해도 의미가 다르고, 같은 대상이라고 해도 지칭하는 용어가 다를 수 있기 때문에 한 개의 모델로 모든 하위 도메인을 표현할 수 없다.
하위 도메인마다 사용하는 용어가 다르기 때문에 올바른 도메인 모델을 만들려면 하위 도메인마다 모델을 만들어야 한다.
각 모델은 명시적으로 구분되는 경계를 가져서 섞이지 않도록 해야 한다.
여러 하위 도메인의 모델이 섞이게 되면 각 하위 도메인별로 다르게 발전하는 요구사항을 모델에 반영하기 어려워진다.
모델은 특정한 컨텍스트 내에서 완전한 의미를 갖는다.
예) 같은 제품이라도 카탈로그 컨텍스트와 재고 컨텍스트에서 서로 의미가 다름
이렇게 구분되는 경계를 갖는 컨텍스트를 DDD 에서는 바운디드 컨텍스트라고 한다.
2. 바운디드 컨텍스트
바운디드 컨텍스트는 모델의 경계를 결정하며, 한 개의 바운디드 컨텍스트는 논리적으로 한 개의 모델을 갖는다.
바운디드 컨텍스트는 용어를 기준으로 구분한다.
예) 카탈로그 컨텍스트와 재고 컨텍스트는 서로 다른 용어를 사용하므로 이 용어를 기준으로 컨텍스트 분리 가능
바운디드 컨텍스트는 실제 기능을 제공하는 물리적 시스템으로서 도메인 모델은 이 바운디드 컨텍스트 안에서 도메인을 구현한다.
이상적으로는 하위 도메인과 바운디드 컨텍스트가 1:1 관계이면 좋겠지만 현실은 그렇지 못하다.
주문 하위 도메인이라도 주문을 처리하는 팀과 결제 금액 계산 로직을 구현하는 팀이 따로 있다면 이 경우에 주문 하위 도메인에 주문 바운디드 컨텍스트와 결제 금액 계산 바운디드 컨텍스트가 존재한다.
규모가 작은 기업은 전체 시스템을 한 개 팀에서 구현하기도 하는데 예를 들어 소규모 쇼핑몰은 한 개의 웹 애플리케이션으로 온라인 쇼핑을 서비스하며, 이 한 개의 시스템 안에 회원, 카탈로그, 결제 등 모든 기능을 포함되어 있다.
즉, 여러 하위 도메인이 하나의 바운디드 컨텍스트 안에서 구현되어 있다.
여러 하위 도메인을 하나의 바운디드 컨텍스트에서 개발할 때 주의할 점은 하위 도메인의 모델이 섞이지 않도록 하는 것이다.
한 프로젝트에 각 하위 도메인이 모두 위치한다고 해서 만일 전체 하위 도메인을 위한 단일 모델을 만들게 되면 결과적으로 도메인 모델이 개별 하위 도메인을 제대로 반영하지 못해서 하위 도메인별로 기능을 확장하기 어렵게 된다.
비록 한 개의 바운디드 컨텍스트가 여러 하위 도메인을 포함하더라도 하위 도메인마다 구분되는 패키지를 갖도록 구현해야 하며, 이렇게 함으로써 하위 도메인을 위한 모델이 서로 뒤섞이지 않고 하위 도메인마다 바운디드 컨텍스트를 갖는 효과를 낼 수 있다.
(= 물리적인 바운디드 컨텍스트가 한 개 이더라도 내부적으로 패키지를 활용하여 논리적으로 바운디드 컨텍스트를 만들어서 해야 함)
바운디드 컨텍스트는 도메인 모델을 구분하는 경계가 되기 때문에 바운디드 컨텍스트는 하위 도메인에 알맞는 모델을 포함한다.
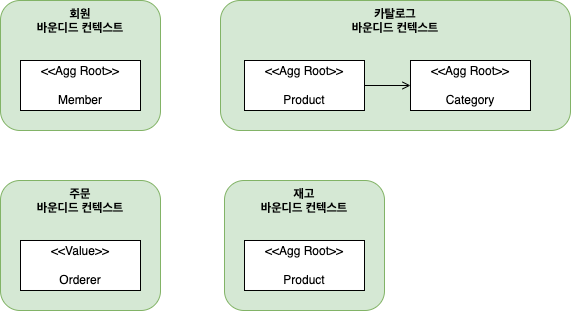
예) 같은 사용자라고 하더라도 주문 바운디드 컨텍스트와 회원 바운디드 컨텍스트가 갖는 모델은 다름
따라서 회원 바운디드 컨텍스트에서 Member 는 애그리거트 루트이지만 주문 바운디드 컨텍스트에서의 Orderer 는 밸류가 되고,
카탈로그 컨텍스트 바운디드에서 Product 는 상품이 속한 Category 와 연관을 갖지만 재고 바운디드 컨텍스트에서의 Product 는 Category 와 연관을 맺지 않는다.
3. 바운디드 컨텍스트 구현
바운디드 컨텍스트는 도메인 모델만 포함하는 것 뿐 아니라 도메인 기능을 제공하는데 필요한 표현 영역, 응용 서비스, 인프라스트럭처 영역 모두를 포함한다.
도메인 모델의 데이터 구조가 변경되면 DB 스키마도 변경되어야 하므로 테이블도 바운디드 컨텍스트에 포함된다.
표현 영역은 다른 바운디드 컨텍스트를 위한 REST API 를 제공할 수도 있음
모든 바운디드 컨텍스트를 반드시 도메인 주도로 개발할 필요는 없다.
리뷰 시스템처럼 복잡한 도메인 로직을 갖지 않는 기능은 단순 CRUD 처럼 DAO 와 데이터 중심의 밸류 객체를 이용하여 기능 구현을 해도 된다.
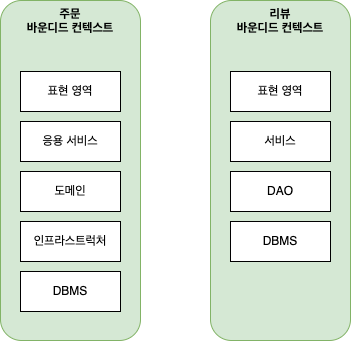
위처럼 서비스-DAO 구조를 사용하면 도메인 기능이 서비스에 흩어지게 되지만 도메인 기능 자체가 단순하면 문제가 되지 않는다.
한 바운디드 컨텍스트에서 두 방식을 혼합하여 사용할 수도 있다.
대표적인 예가 CQRS (Command Query Responsibility Segregation) 패턴이다.
CQRS 는 상태를 변경하는 명령 기능과 내용을 조회하는 쿼리 기능을 위한 모델을 구분하는 패턴임
CQRS 에 대한 좀 더 상세한 내용은 DDD - CQRS 를 참고하세요.
CQRS 패턴을 바운디드 컨텍스트에 적용하면 상태 변경과 관련된 기능은 도메인 모델 기반으로 구현하고, 조회 기능은 서비스-DAO 를 이용하여 구현할 수 있다.
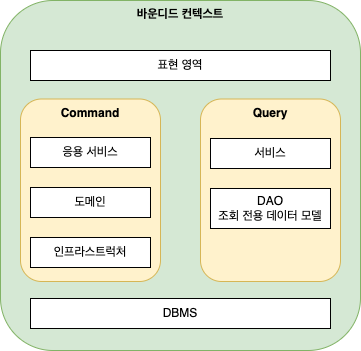
바운디드 컨텍스트가 반드시 사용자에게 보여지는 UI 를 가질 필요는 없음
REST API 를 제공할 수도 있음
4. 바운디드 컨텍스트 간 통합
예를 들어 카탈로그 하위 도메인에 개인화 추천 기능을 도입할 때 기존 카탈로그 시스템 개발팀과 추천 시스템 개발팀이 다르게 되면 카탈로그 하위 도메인에는 기존 카탈로그를 위한 바운디드 컨텍스트와 추천 기능을 위한 바운디드 컨텍스트가 생긴다.
두 팀이 관련된 바운디드 컨텍스트를 개발하면 자연스럽게 두 바운디드 컨텍스트 간 통합이 발생하게 되는데 위의 카탈로그와 추천 바운디드 컨텍스트 간 통합이 필요한 기능은 아래와 같다.
- 사용자가 제품 상세 페이지를 볼 때 보고 있는 상품과 유사한 상품 목록을 하단에 노출
4.1. 직접 통합
REST API 를 호출하는 것은 두 바운디드 컨텍스트를 직접 통합하는 방식이다.
API 흐름은 아래와 같다.
- 사용자가 카탈로그 바운디드 컨텍스트에 추천 제품 목록 요청
- 카탈로그 바운디드 컨텍스트는 추천 바운디드 컨텍스트로부터 추천 정보를 읽어옴
- 카탈로그 컨텍스트 바운디드는 추천 바운디드 컨텍스트로부터 받은 정보를 사용자에게 제공
이 때 카탈로그 컨텍스트와 추천 컨텍스트의 도메인 모델을 서로 다르다.
카탈로그는 제품을 중심으로 도메인 모델을 구현하고, 추천은 추천 연산을 위한 모델 (상품의 상세 정보를 포함하지 않고, 상품 번호 대신 아이템 ID 라는 용어로 식별자 표현 등) 을 구현한다.
따라서 카탈로그 시스템은 추천 시스템으로부터 추천 데이터를 받으면 추천 시스템 도메인 모델을 사용하는 것이 아니라 카탈로그 도메인 모델을 사용하여 추천 상품을 표현해야 한다.
(= 카탈로그 모델을 기반으로 하는 도메인 서비스를 이용하여 상품 추천 기능 표현)
상품 추천 기능을 표현하는 카탈로그 도메인 서비스 예시
public interface ProductRecommendationService {
List<Product> getRecommendationsOf(ProductId id);
}
도메인 서비스를 구현하는 클래스는 인프라스트럭처 영역에 위치하며, 외부 시스템과의 연동을 처리 및 외부 시스템의 모델과 현재 도메인 모델 간의 변환을 책임진다.
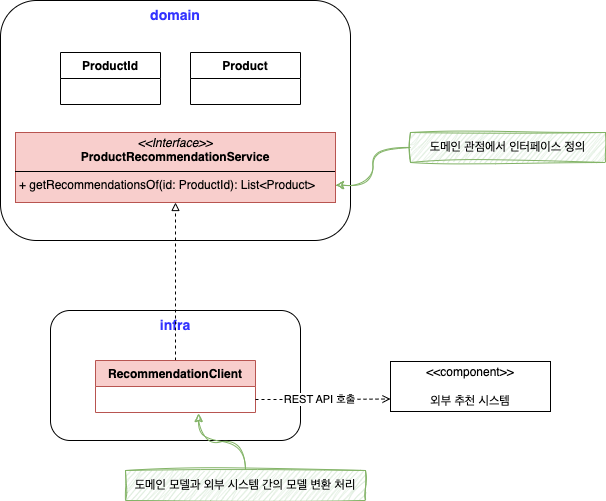
도메인 서비스를 구현한 클래스인 RecommendationClient 는 외부 추천 시스템이 제공하는 REST API 를 이용하여 추천 상품 목록을 조회하는데 이 REST API 의 데이터는 추천 시스템의 모델을 기반으로 하고 있다.
따라서 RecommendationClient 는 REST API 로부터 데이터를 조회한 후 카탈로그 도메인에 맞는 모델로 변환하게 된다.
도메인 서비스 구현 클래스가 REST API 로부터 데이터를 조회하여 카탈로그 도메인에 맞는 상품 모델로 변환하는 예시
@RequiredArgsConstructor
public class RecommendationClient implements ProductRecommendationService {
private final ProductRepository productRepository;
@Override
public List<Product> getRecommendationsOf(ProductId id) {
List<RecommendationItem> items = getRecommendationItems(id.getValue());
return toProducts(items);
}
// 리턴받는 RecommendationItem 은 추천 시스템의 모델임
private List<RecommendationItem> getRecommendationItems(String itemId) {
// externalRecommendationClient 는 외부 추천 시스템을 연결할 때 사용하는 클라이언트
return externalRecommendationClient.getRecommendations(itemId);
}
// 추천 시스템의 모델을 카탈로그 도메인의 Product 모델로 변환
private List<Product> toProducts(List<RecommendationItem> items) {
return items.stream()
.map(item -> toProductId(item.getItemId()))
.map(prodId -> productRepository.findById(prodId))
.collect(toList());
}
private ProductId toProductId(String itemId) {
return new ProductId(itemId);
}
// ...
}
4.2. 간접 통합
바운디드 컨텍스트를 간접적으로 통합하는 방법도 있는데 대표적인 간접 통합 방식이 메시지 큐를 사용하는 것이다.
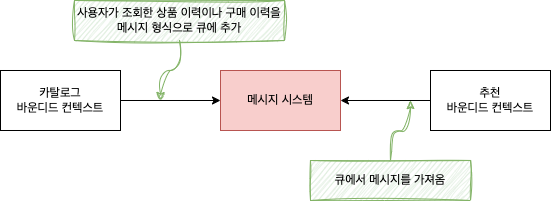
메시지 큐는 비동기로 메시지를 처리하기 때문에 카탈로그 바운디드 컨텍스트는 메시지를 큐에 추가한 후에 추천 바운디드 컨텍스트가 메시지를 처리할 때까지 기다리지 않고 자신의 처리를 계속한다.
추천 바운디드 컨텍스트는 큐에서 메시지를 읽어와서 사용한다.
이는 두 바운디드 컨텍스트가 사용할 메시지의 구조를 맞춰야 함을 의미한다.
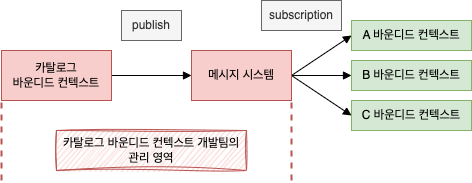
메시지 큐에 담을 메시지의 구조는 그 큐를 제공하는 바운디드 컨텍스트에서 결정한다.
예를 들어 카탈로그 시스템에서 큐를 제공한다면 큐에 담기는 내용은 카탈로그 도메인을 따르게 되고, 다른 바운디드 컨텍스트는 큐로부터 메시지를 가져와 자신의 모델에 맞게 메시지를 변환하여 처리한다.
4.3. MSA 와 바운디드 컨텍스트
MSA 는 개별 서비스를 독립된 프로세스로 실행하고, 각 서비스가 REST API 나 메시징을 이용하여 통신하는 구조를 갖는다.
이런 MSA 의 특징은 바운디드 컨텍스트와 잘 어울린다.
각 바운디드 컨텍스트는 모델의 경계를 형성하는데 바운디드 컨텍스트를 MSA 로 구현하면 자연스럽게 컨텍스트별로 모델이 분리된다.
MSA 마다 프로젝트를 생성하므로 바운디드 컨텍스트마다 프로젝트가 생성되게 되는데 이것은 코드 수준에서 모델을 분리하여 두 바운디드 컨텍스트 모델이 섞이지 않도록 해준다.
별도 프로세스로 개발한 바운디드 컨텍스트는 독립적으로 배포, 모니터링, 확장하는데 이 역시 MSA 의 특징이다.
5. 바운디드 컨텍스트 간 관계
바운디드 컨텍스트는 다양한 방식으로 관계를 맺는다.
관계를 맺는 방식은 크게 3가지가 있다.
- 공개 호스트 서비스 방식
- 공유 커널 방식
- 독립 방식
DDD - 바운디드 컨텍스트 연동 와 함께 보면 도움이 됩니다.
5.1. 공개 호스트 서비스 (Open host service): Anti-corruption Layer
두 바운디드 컨텍스트 관계 중 가장 흔한 관계는 한 쪽에서 REST API 를 제공하고 다른 한 쪽에서 그 API 를 호출하는 방식이다.
이 때 API 를 사용하는 바운디드 컨텍스트는 API 를 제공하는 바운디드 컨텍스트에 의존하게 된다.
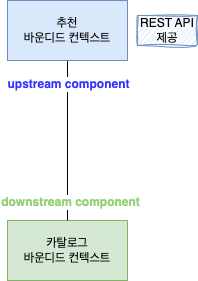
downstream 컴포넌트인 카탈로그 컨텍스트(고객)는 upstream 컴포넌트인 추천 컨텍스트(공급자)가 제공하는 데이터와 기능에 의존한다.
upstream 컴포넌트는 downstream 컴포넌트가 사용할 수 있는 통신 프로토콜을 정의하고 이를 공개한다.
upstream 컴포넌트에 의존하는 downstream 컴포넌트가 여러 개 존재하면 upstream 컴포넌트는 이 다수의 downstream 컴포넌트의 요구사항을 수용할 수 있는 API 를 만들어서 서비스 형태로 공개하여 서비스의 일관성을 유지할 수 있다.
이런 서비스를 공개 호스트 서비스라고 한다.
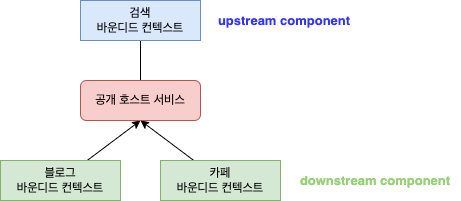
예를 들어 검색의 경우 블로그, 카페와 같은 서비스를 제공하는 포털은 각 서비스별로 검색 기능을 구현하는 것이 아니라 검색을 위한 전용 시스템을 구축하여 검색 시스템과 각 서비스를 통합한다.
이 때 검색 시스템은 upstream 컴포넌트이고 블로그, 카페는 downstream 컴포넌트가 된다.
검색 시스템은 블로그, 카페의 요구사항을 수용하는 단일 API 를 만들어 이를 공개하고, 각 서비스들은 공개된 API 를 사용하여 검색 기능을 구현한다.
upstream 컴포넌트 서비스는 자신의 컨텍스트 도메인 모델을 따르므로 downstream 컴포넌트는 upstream 컴포넌트의 모델이 자신의 도메인 모델에 영향을 주지 않도록 조치를 취해야 하는데 4.1. 직접 통합 에서 보았던 도메인 서비스를 구현하는 클래스가 바로 그 역할을 한다.
RecommendationClient 는 외부 시스템의 모델이 자신의 도메인 모델을 침범하지 않도록 만들어주는 안티코럽션 계층(Anti-corruption Layer) 역할을 한다.
안티코럽션 계층에서 두 바운디드 컨텍스트 간의 모델 변환을 처리해주므로 다른 바운디드 컨텍스트 모델에 영향을 받지 않고 본인의 도메인 모델을 유지할 수 있다.
5.2. 공유 커널 (Shared kernel)
두 바운디드 컨텍스트가 같은 모델을 공유하는 경우도 있다.
예를 들어 운영자를 위한 주문 관리툴과 고객을 위한 주문 관리툴이 관리하는 팀이 다를 경우 두 팀은 주문을 표현하는 모델을 공유함으로써 주문과 관련된 중복 설계를 막을 수 있다.
이렇게 두 개의 바운디드 컨텍스트가 공유하는 모델을 공유 커널이라고 한다.
공유 커널의 장점은 중복을 줄여준다는 점이다.
하지만 한 팀에서 임의로 모델을 변경하면 안되기 때문에 두 팀이 밀접한 관계를 형성해야 하며 이 점이 공유 커널을 사용할 때의 장점보다 공유 커널로 인해 개발이 지연되고 정체되는 문제가 더 커질수도 있다.
5.3. 독립 방식 (Separate way)
독립 방식은 그냥 서로 통합하지 않는 방식이다.
독립 방식에서 두 바운디드 컨텍스트 간의 통합은 수동으로 이루어진다.
예를 들어 쇼핑몰 서비스에서 외부 ERP 서비스와의 연동을 지원하지 않을 경우 운영자가 쇼핑몰 시스템에서 판매 정보를 보고 ERP 시스템에 직접 입력한다.
수동으로 통합하는 방식은 서비스 규모가 커질수록 한계가 있으므로 규모가 어느 정도 커지게 되면 두 바운디드 컨텍스트를 통합해야 한다.
이 때 쇼핑몰 바운디드 컨텍스트와 외부 ERP 바운디드 컨텍스트를 통합해주는 별도의 시스템을 만들어야 할 수도 있다.
6. 컨텍스트 맵
컨텍스트 맵은 바운디드 컨텍스트 간의 관계를 표시한 것이다.
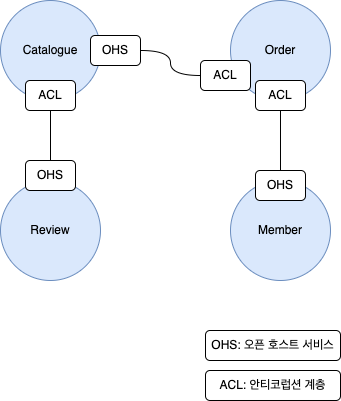
컨텍스트 맵을 보면 각 바운디드 컨텍스트의 경계가 명확하게 드러나고 서로 어떤 관계를 맺는지 알 수 있다.
바운디드 컨텍스트 영역에 주요 애그리거트를 함께 표시하면 모델에 대한 관계가 더 명확히 드러난다.
위 그림은 오픈 호스트 서비스와 안티코럽션 계층만 표시했지만 하위 도메인이나 조직 구조를 함께 표시하면 도메인을 포함한 전체 관계를 이해하는데 도움이 된다.
컨텍스트 맵은 시스템의 전체 구조를 보여주므로 하위 도메인과 일치하지 않는 바운디드 컨텍스트를 찾아 도메인에 맞게 바운디드 컨텍스트를 조절하고 사업의 핵심 도메인을 위해 조직 역량을 어떤 바운디드 컨텍스트에 집중할 지 파악하는데 도움을 준다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 최범균 저자의 도메인 주도 개발 시작하기을 기반으로 스터디하며 정리한 내용들입니다.
