AI - 생성형 인공지능 원리
in DEV on Ai, Ml, Llm, Large-language-model, Natural-language-processing, Nlp, Transformer, Rnn, Lstm, Gru, Seq2seq, Attention, Self-attention, Multi-head-attention, Encoder, Decoder, Bert, Gpt, Tokenization, Embedding, Auto-regressive, Masked-language-model, Mlm
챗GPT 는 이제 많은 사람들의 일상과 업무에 깊숙이 자리 잡은 강력한 도구이다.
우리는 그 원리를 상세히 몰라도 얼마든지 훌륭한 결과물을 얻을 수 있다. 마치 자동차 운전법을 안다고 해서 엔진의 구조까지 알 필요는 없는 것과 같다.
하지만 만약 우리가 자동차 엔진의 동작 원리를 이해한다면 어떻게 될까?
아마 특정 상황에서 차의 성능을 극한까지 끌어올리거나, 예상치 못한 문제에 더 현명하게 대처할 수 있을 것이다.
대규모 언어 모델(LLM, Large Language Model)도 마찬가지이다.
그저 사용자를 넘어, 내부의 동작 원리를 이해하는 개발자가 된다면 기술의 명확한 한계와 무한한 가능성을 동시에 파악하고, 비즈니스와 기술의 미래를 바꾸는 혁신을 이끌어낼 수 있다.
이번 포스트에서는 AI 기술의 결정체인 대규모 언어 모델이 어떤 기술적 배경에서 탄생했으며, 어떤 과정을 거쳐 지금까지 발전해왔는지, 그리고 앞으로는 어떻게 나아갈지에 대해 알아본다.
목차
- 1. 토큰화(Tokenization)와 텍스트 임베딩(Text Embedding)
- 2. 트랜스포머 이전 문장을 다루던 방법
- 3. 어텐션(Attention)의 등장과 트랜스포머(Transformer)
- 4. 트랜스포머를 구성하는 인코더와 디코더
- 5. 트랜스포머의 후손
- 6. 왜 디코더 모델이 더 강세를 보이고 있을까?
- 참고 사이트 & 함께 보면 좋은 사이트
1. 토큰화(Tokenization)와 텍스트 임베딩(Text Embedding)
우리가 사용하는 생성형 AI 는 어떻게 사람처럼 자연스러운 문장을 만들어내는 걸까?
AI 는 “너 지금 뭐해?”라는 문장의 의미를 사람처럼 ‘이해’하지 않는다. AI 는 자연어를 생성하지만, 그 자체를 이해하는 것이 아니라 숫자로 바꿔 분석하고 처리할 뿐이다.
따라서 AI 에게 언어를 가르치는 첫 번째 단계는 인간의 언어를 컴퓨터가 이해할 수 있는 숫자로 변환하는 것이다.
이 핵심적인 과정을 가능하게 하는 두 가지 개념이 바로 토큰화(Tokenization)와 텍스트 임베딩(Text Embedding)이다.
1.1. 토큰화: 문장을 의미있는 조각으로 나누기
컴퓨터는 숫자 처리에 특화되어 있지만, 우리가 쓰는 언어는 단어와 문장으로 이루어져 있다. AI 가 이 비정형 텍스트를 처리하게 하려면, 먼저 문장을 토큰이라는 작은 단위로 나누고, 이를 숫자로 변환해야 한다.
이처럼 문장을 정해진 규칙에 따라 의미 있는 조각으로 나누는 과정을 토큰화(Tokenization)라고 한다.
- 띄어쓰기 단위 토큰화
- 가장 직관적인 방식으로, 공백을 기준으로 문장을 나눈다.
- 입력: “아버지가방에들어가신다”
- 출력: [“아버지가방에들어가신다”]
- 음절 단위 토큰화
- 문장을 한 글자씩 나눈다. 한국어처럼 띄어쓰기가 명확하지 않은 경우에도 적용할 수 있지만, ‘아버지’, ‘가방’과 같은 고유한 의미를 파악하기 어렵다는 한계가 있다.
- 입력: “아버지가방에들어가신다”
- 출력: [“아”, “버”, “지”, “가”, “방”, “에”, “들”, “어”, “가”, “신”, “다”]
- 서브워드(Subword) 토큰화
- 현대 언어 모델에서 가장 널리 쓰이는 방식이다. 단어를 더 작은 의미 단위인 ‘서브워드’로 나눈다.
- 이 방식은 모델이 처음 보는 단어(신조어, 복합어 등)에도 효과적으로 대처할 수 있다.
- 입력: “초해상도영상처리”
- 출력: [“초”, “해상도”, “영상”, “처리”]
- ‘초해상도영상처리’라는 복잡한 단어도 모델이 이미 알고 있는 ‘초’, ‘해상도’, ‘영상’, ‘처리’라는 조각으로 나누어 의미를 유추할 수 있게 된다.
1.2. transformers 라이브러리로 토큰화 진행
허깅 페이스(Hugging Face)의 transformers 라이브러리를 사용하면 강력한 토크나이저를 쉽게 활용할 수 있다.
from transformers import AutoTokenizer
model_id = "microsoft/phi-4"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "I am studying tokenization."
tokens = tokenizer.tokenize(text)
print(tokens)
from transformers import AutoTokenizer
트랜스포머 라이브러리는 허깅페이스에서 제공하는 강력한 NLP(Natural Language Processing) 라이브러리이다.
AutoTokenizer 클래스는 모델 ID 만으로 해당 모델에 최적화된 토크나이저를 자동으로 로드한다.
model_id = “microsoft/phi-4”
여기서 사용할 인공지능은 마이크로소프트에서 개발한 phi-4 모델이다. 이 모델은 다른 모델에 비해 경량화되었으며, 한글도 잘 지원한다는 특징이 있다.
tokenizer = AutoTokenizer.from_pretrained(model_id)
model_id 에 해당하는 사전 학습된 토크나이저를 다운로드하여 초기화한다. 즉, phi-4 모델과 호환되는 토크나이저를 자동으로 설정해준다.
['I', 'Ġam', 'Ġstudying', 'Ġtoken', 'ization', '.']
결과를 보면 Ġ 문자가 앞에 붙어있는 걸 볼 수 있다.
이 문자는 특수 토큰으로 공백을 의미한다.
‘tokenization’ 이라는 단어가 두 개의 서브워드로 분리되었다. 이는 모델이 세상의 모든 단어를 통째로 외우는 것이 비효율적이기 때문이다.
대신, ‘token’ 과 ‘ization’ 처럼 자주 등장하는 조각으로 단어를 기억함으로써, 처음 보는 단어가 나타나도 유연하게 의미를 조합하여 처리할 수 있다.
The secret
HF_TOKENdoes not exist in your Colab secrets.
이런 Warning 이 뜬다면 TroubleShooting - Colab: The secretHF_TOKENdoes not exist in your Colab secrets. 를 참고하세요.
1.3. 고유 ID 부여: 토큰화로 문장을 숫자로 바꾸기
이제 텍스트는 의미 있는 조각인 토큰으로 나뉘었다. 하지만 여전히 컴퓨터는 이 문자열을 직접 처리할 수 없다.
다음 단계는 각 토큰을 모델의 단어 사전에 정의된 고유한 숫자 ID 로 변환하는 것인데 이 과정을 ‘토큰 ID 변환(token ID mapping)’이라고 한다. 각 토큰은 사용하는 언어 모델에 따라 고유한 숫자(token ID)를 갖고 있고, 토크나이저는 각 단어를 미리 학습한 단어 사전에 따라 변환한다.
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(token_ids)
[40, 1097, 21630, 4037, 2065, 13]
각 단어(토큰)은 특정 숫자로 변환되고, 컴퓨터는 이 숫자들을 통해 의미를 분석한다.
1.4. 숫자에 의미를 부여하는 임베딩(Embedding)
토큰 ID 는 각 토큰을 구별해주는 고유 번호일 뿐, 단어의 ‘의미’를 담고 있지는 않다. 예를 들어, ID 가 500번인 단어와 501번인 단어가 의미적으로 가깝다는 보장은 없다.
임베딩(Embedding)은 바로 이 숫자 ID 에 ‘의미’를 부여하는 과정이다.
각 토큰 ID 를 고차원 벡터(Vector) 공간의 한 점, 즉 좌표로 변환한다. 도시의 이름(서울, 뉴욕)을 지도 위에 배치하면 서로의 거리와 관계를 시각적으로 파악할 수 있듯이, 단어를 벡터 공간에 배치하면 단어 간의 의미적 관계를 수학적으로 계산할 수 있게 된다.
임베딩의 최종 목표는 단어 간의 관계를 계산하여 문맥에 맞는 다음 단어를 예측하는 것이다.
위에서 얻은 토큰 ID 를 한번 보자.
[40, 1097, 21630, 4037, 2065, 13]
이 숫자들이 의미를 가지려면 숫자 하나하나(각각의 토큰 ID)를 더 의미있는 좌표로 변환해야 하는데 이 과정이 바로 임베딩이다. 실제로 임베딩을 할 때는 512차원 이상의 고차원 벡터로 변환하는데 여기서는 쉽게 이해하기 위해서 2차원으로 임베딩해본다.
예를 들어, 학습 초기 단계의 임베딩 벡터를 아래와 같이 무작위로 설정될 수 있다.
| 토큰 | 토큰 ID | 초기 임베딩 벡터 |
|---|---|---|
| I | 40 | [3, 4] |
| am | 1097 | [10, 15] |
이 때 ‘I’와 ‘am’ 벡터는 아무런 의미 관계없이 멀리 떨어져 있다. 하지만 모델이 “I am a boy”, “I am studying” 과 같은 수많은 문장을 학습하면서 ‘I’ 다음에는 ‘am’ 이 자주 등장한다는 패턴을 발견한다. 이 과정에서 모델은 두 단어의 관계가 가깝다고 판단하고, 임베딩 벡터를 서로 가까워지도록 조정한다.
학습으로 조정된 임베딩
| 토큰 | 토큰 ID | 초기 임베딩 벡터 |
|---|---|---|
| I | 40 | [4, 5] |
| am | 1097 | [6, 4] |
이렇게 학습이 완료되면, 모델이 ‘I’ 라는 단어를 생성했을 때 벡터 공간에서 가장 가까운 위치에 있는 ‘am’ 이라는 단어를 다음 단어로 생성할 확률이 높아진다.
이것이 바로 생성형 인공지능의 핵심 원리이다.
결국, 앞으로 살펴볼 AI 모델의 학습 과정이란, 이 임베딩 벡터값들을 문맥에 맞게 끊임없이 조정하며 단어 간의 관계를 최적화하는 여정이라고 할 수 있다.
2. 트랜스포머 이전 문장을 다루던 방법
최신 대규모 언어 모델의 핵심인 트랜스포머(Transformer)가 등장하기 전, AI 는 어떻게 문장의 의미와 순서를 이해하게 됐을까?
여기서는 트랜스포머의 길을 닦은 이전 모델들인 RNN, LSTM, GRU, 그리고 Seq2Seq 모델에 대해 알아본다.
2.1. RNN(Recurrent Neural Network): 순서와 흐름 기억
“어젯밤 나는 너무 피곤해서 일찍 잠들었다. 그래서 늦잠을 잤다.”
우리가 마지막 문장인 ‘그래서 늦잠을 잤다’를 이해할 수 있는 이유는 앞선 문장인 ‘피곤해서 일찍 잠들었다’는 정보를 기억하고 있기 때문이다.
이처럼 순차적인 데이터의 문맥(Context)을 파악하는 능력은 자연어 처리의 핵심이다.
재귀 신경망(RNN)은 바로 이 문제를 해결하기 위해 고안되었다.
RNN 은 이전 단계의 출력(기억)을 현재 단계의 입력으로 다시 사용하는 순환 구조를 통해 정보의 흐름을 유지한다.
RNN 은 각 단어를 순차적으로 처리하면서, 앞부분의 정보를 뒤쪽으로 계속 전달한다.
하지만 이 방식에는 치명적인 단점이 있다.
문장이 길어질수록, 마치 사람이 긴 이야기를 들으면 앞부분을 잊어버리는 것처럼, 초반의 중요한 정보가 뒤로 갈수록 희미해지는 장기 의존성 문제(Long-Term Dependency Problem)가 발생했다.
2.2. LSTM(Long Short-Term Memory): 중요한 건 오래, 사소한 건 짧게
RNN 의 기억력 문제를 해결하기 위해 등장한 모델이 바로 LSTM(장단기 메모리)이다. 이름에서 알 수 있듯이, LSTM 은 단기 기억과 장기 기억으로 나누어 관리하는 구조를 가진다.
- 단기 기억
- ‘방금 본 단어’처럼 현재 문장을 이해하는데 직접적으로 필요한 정보 저장
- 장기 기억
- ‘글의 핵심 주제’처럼 전체 문맥을 관통하는 중요한 정보를 오랫동안 저장
LSTM 은 셀 상태(Cell State)를 통해 장기 기억을 관리하고, 게이트(Gate)라는 관문을 통해 정보를 선별적으로 기억하거나 잊어버린다.
이를 통해 정말 중요한 정보는 문장이 길어져도 잊지 않고 유지하며 RNN 의 한계를 극복했다.
LSTM 은 이런 방식으로 정보를 관리한다.
- 기억할 내용 선별
- 방금 본 내용 중 진짜 중요한 것만 장기 기억에 적고, 자주 나오는 개념은 단기 기억에 저장함
- 중요하지 않은 정보를 삭제
- 새로운 정보 업데이트
- 단기 기억 중에서 정말 중요한 정보는 장기 기억으로 정보를 옮김
- 필요할 때 기억 꺼내기
- 단기 기억에 남아있는 정보를 먼저 활용하고, 단기 기억에 없으면 장기 기억에서 중요한 개념을 찾음
2.3. GRU(Gated Recurrent Unit): 더 단순하고 빠르게
LSTM 은 RNN 의 문제를 효과적으로 해결했지만, 내부 구조가 복잡하고 계산량이 많아 학습 속도가 느리다는 단점이 있었다.
GRU는 LSTM 의 핵심적인 아이디어는 유지하면서 구조를 대폭 단순화한 모델이다.
LSTM 이 여러 개의 게이트로 정보를 정교하게 제어했다면, GRU 는 더 적은 수의 게이트로 비슷한 역할을 수행한다.
중요한 정보만 간략하게 요약해서 기록하는 방식으로, LSTM 보다 계산량이 적어 더 빠른 속도가 장점이다.
하지만 GRU 역시 RNN 기반 구조의 근본적인 한계, 즉 순차적으로 정보를 처리해야만 한다는 틀에서 완전히 벗어나지는 못했다.
‘기억’은 잘하지만, 번역이나 요약처럼 새로운 문장을 ‘생성’하는 데는 여전히 부족함이 있었다.
2.4. Seq2Seq(Sequence-to-Sequence): 문장을 이해하여 새로운 문장 생성
‘잘 기억하는 것’과 ‘잘 생성하는 것’은 다른 능력이다.
Seq2Seq 모델은 하나의 시퀀스(문장)를 입력받아, 다른 시퀀스를 출력하는 Encoder-Decoder 구조를 제시하며 자연어 생성(NLG, Natural Language Generation)의 새로운 지평을 열었다.
- 인코더(Encoder): 듣고 이해
- 입력 문장의 모든 단어를 순차적으로 읽어 들여 핵심 의미를 파악함
- 이해한 문장의 모든 정보를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터로 압축함
- 입력: “I am studying AI because I want to develop smart system in the future.”
- 요약(컨텍스트 벡터): “AI 공부 중, 스마트 시스템 개발 원함”이라는 의미를 담은 숫자 벡터
- 디코더(Decoder): 새로운 언어로 말하기
- 인코더가 전달한 컨텍스트 벡터를 받아서 새로운 문장을 한 단어씩 생성함
- 첫 단어를 예측하고, 그 단어를 다시 입력으로 사용하여 다음 단어를 예측하는 과정을 반복함
- 출력 생성: (컨텍스트 벡터) → “나는” → “나는 스마트” → “나는 스마트 시스템을” → …
Seq2Seq 모델 덕분에 기계 번역, 챗봇, 텍스트 요약과 같은 서비스가 비약적으로 발전할 수 있었다. 하지만 이 모델 역시 RNN 을 기반으로 했기 때문에 고질적인 문제점을 안고 있었다.
- 긴 문장 처리의 한계
- 문장이 길어질수록 인코더가 모든 정보를 하나의 컨텍스트 벡터에 압축하기 어려움
- 정보 병목 현상
- 문장의 모든 의미가 단 하나의 벡터에 담겨야 하기 때문에, 중요한 세부 정보가 손실될 위험이 큼
이러한 한계를 극복하기 위해 ‘문장의 모든 단어에 공평하게 집중하면 어떨까?’라는 아이디어가 나왔고, 그 아이디어가 바로 어텐션(Attention) 메커니즘의 시작이었다.
3. 어텐션(Attention)의 등장과 트랜스포머(Transformer)
지금까지 AI 가 문장을 이해하기 위해 RNN → LSTM → GRU → Seq2Seq 모델로 발전해온 과정을 살펴보았다.
Seq2Seq 모델은 ‘하나의 문장을 입력받아 다른 문장을 출력’하는 혁신적인 구조를 제시했지만, 여전히 긴 문장의 핵심 정보를 하나의 컨텍스트 벡터에 압축하면서 정보가 손실되는 한계를 안고 있다.
이 고질적인 정보 병목 현상을 해결하기 위해 등장한 것이 바로 어텐션(Attention) 메커니즘이다.
어텐션은 이름 그대로, AI 가 문장을 처리할 때 중요한 부분에 더 집중하도록 만드는 아이디어이다. 그리고 훗날 트랜스포머는 이 어텐션 개념을 셀프 어텐션(Self-Attention)으로 발전시켜 NLP(자연어 처리, Natural Language Processing) 의 역사를 새로 쓰게 된다.
3.1. 어텐션: Seq2Seq 모델의 한계 해결
Seq2Seq 모델의 디코더는 오직 인코더가 마지막에 전달해 준 하나의 고정된 컨텍스트 벡터에만 의존해 새로운 문장을 생성한다. 문장이 길어질수록 이 벡터 하나에 모든 의미를 담는 것은 불가능에 가깝다.
예를 들어 ‘인간의 심리’라는 방대한 문서를 참고하여 ‘편안한 상황과 위험한 상황에서 사람의 심리는 어떻게 변하는가?’라는 주제로 글을 쓴다고 해보자.
- Seq2Seq 방식
- 문서를 통째로 읽고 한 줄(컨텍스트 벡터)로 요약한 뒤, 오직 그 요약본만 보고 글을 써 내려가는 방식으로 세부 내용을 기억하기 어려움
- 어텐션 방식
- 글을 쓰다가 ‘편안한 상황’에 대해 서술할 차례가 되면, 원본 문서에서 ‘편안함’, ‘안정감’ 등 관련된 부분을 다시 찾아 집중적으로 참고함
이처럼 어텐션 기법은 디코더가 각 단어를 생성하는 매 순간, 고정된 컨텍스트 벡터 하나만 보는 것이 아니라, 입력 문장의 모든 단어를 다시 한번 훑어본다.
그리고 현재 생성할 단어와 가장 관련이 깊은 입력 단어에 높은 가중치(Weight)를 부여하여 해당 정보를 집중적으로 활용한다.
어텐션이란, 출력 단어를 생성할 때마다 입력 문장 전체를 참고하되, 문맥상 더 중요한 단어에 동적으로 가중치를 부여하여 집중하는 메커니즘이다.
‘I want to eat a hot dog’ 를 한국어로 번역할 때를 생각해보자.
어텐션이 없다면 모델은 ‘뜨거운 개’, 이렇게 따로따로 번역할 위험이 있다. 하지만 어텐션 메커니즘은 ‘hot dog’ 라는 음식 이름을 생성해야 하는 시점에, 입력 문장의 ‘hot’ 과 ‘dog’ 두 단어에 동시에 높은 가중치를 부여하여 이 둘이 하나의 의미(먹는 핫도그)를 형성한다는 것을 파악한다.
어텐션은 문맥에 따라 달라지는 중의적인 표현을 정확히 번역해내는 핵심 열쇠였으며, Seq2Seq 모델의 성능을 극적으로 향상시켰다.
3.2. 셀프 어텐션(Self-Attention): 트랜스포머의 핵심
어텐션이 Seq2Seq 의 한계를 극복하는데 큰 도움을 줬지만, 트랜스포머는 여기서 한 걸음 더 나아갔다. 바로 셀프 어텐션(Self-Attention) 개념을 도입한 것이다.
둘의 가장 큰 차이점은 아래와 같다.
- 어텐션(Cross-Attention)
- 주로 인코더와 디코더 사이, 즉 서로 다른 두 시퀀스 간에 동작한다.
- “출력 문장의 이 단어는 입력 문장의 어떤 단어와 관련이 더 깊은가?”를 묻는다.
- 셀프 어텐션(Self-Attention)
- 하나의 시퀀스 내부에서 동작한다.
- “이 문장 안에서, 이 단어는 같은 문장의 다른 어떤 단어들과 가장 관련이 깊은가?”를 묻는다.
셀프 어텐션은 번역처럼 두 문장을 잇는 것이 아니라, 하나의 문장 그 자체를 깊이 있게 이해하기 위해 단어 간의 내부 관계를 학습한다.
이 과정을 수행하기 위해 각 단어는 세 가지 다른 역할의 정보, 쿼리(Query), 키(Key), 밸류(Value)를 만들어 낸다.
아래는 ‘기쁨’이라는 단어가 문장 내 다른 단어들과 관계를 파악하려는 상황이다.
- 쿼리
- ‘기쁨’이라는 단어가 다른 단어들에게 던지는 질문
- 예) ‘나와 관련된 감정 중 ‘소심함’이라는 단어에 대해 궁금해
- 키
- 다른 단어들이 가지고 있는 자신을 나타내는 주제
- 예) ‘소심’ 단어의 키: 나는 ‘소심’에 대한 정보를 갖고 있음
- 밸류
- 해당 단어가 실제로 갖고 있는 진짜 정보
- 예) ‘소심’ 단어의 밸류: 낯선 환경에서 쉽게 긴장하는 행동
‘기쁨’(Query)은 모든 단어의 ‘키’를 훑어본 후 자신의 질문과 가장 잘 맞는 ‘소심’(Key)를 발견하고 높은 가중치를 부여한다. 반면, 관련성이 낮은 ‘분노’(Key)에는 낮은 가중치를 부여한다.
마지막으로, ‘기쁨’은 이 가중치를 바탕으로 다른 단어들의 ‘밸류’를 조합하여 자신의 의미를 새롭게 정의한다.
즉, ‘소심’의 밸류는 많이 참고하고, ‘분노’의 밸류는 조금만 참고하여 문맥에 맞는 ‘기쁨’의 새로운 의미를 만들어낸다.
이 과정은 문장을 이루는 모든 단어가 동시에 수행한다.
모든 단어가 자신만의 쿼리를 날려 다른 모든 단어의 키와 비교하여, 밸류를 참고하여 자신의 표현을 재정의한다.
이 셀프 어텐션 메커니즘 덕분에 트랜스포머는 문장 속 모든 단어 간의 복잡하고 풍부한 문맥 관계를 파악할 수 있게 되었고, 번역/요약/질문 답변 등 거의 모든 자연어 처리 작업에서 압도적인 성능을 발휘하게 되었다.
4. 트랜스포머를 구성하는 인코더와 디코더
트랜스포머는 어텐션 메커니즘에 전적으로 의존하며, 크게 Encoder 와 Decoder 라는 2개의 블록으로 구성되어 있다.
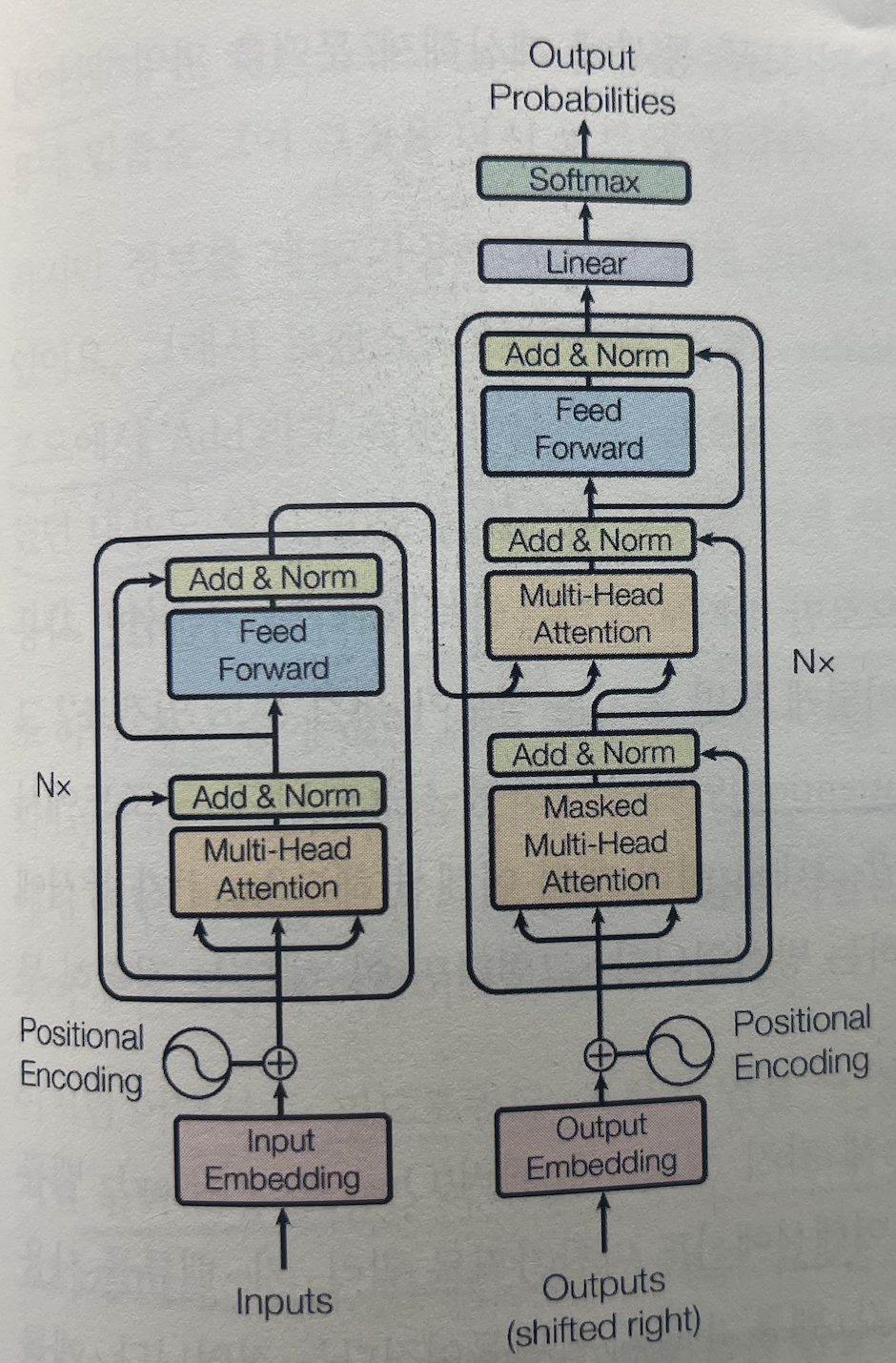
4.1. Encoder: 입력된 문장의 정보 요약
구조도에서 왼쪽 영역을 차지하는 인코더는, 입력된 문장을 받아 그 안에 담긴 복잡한 의미와 단어 간의 관계를 분석한다.
그 결과로 문장의 풍부한 문맥을 함축한 깊이 있는 표현(벡터)을 만들어내는 역할을 한다.
4.1.1. 문장 전체를 동시에 바라보는 Self-Attention
기존의 RNN 이 단어를 하나씩 순서대로 처리하느라 긴 문장의 앞부분 정보를 잊어버리는 단점이 있었다면, 트랜스포머의 인코더는 다르다.
핵심인 Self-Attention 을 통해 문장의 모든 단어가 다른 모든 단어와 어떤 관계를 맺고 있는지 한꺼번에 병렬로 분석한다.
4.1.2. 다양한 시선을 활용하는 Multi-Head Attention
트랜스포머는 문장을 단 하나의 시선으로만 해석하지 않는다.
한 가지 방식으로는 놓치는 정보가 생길 수 있기 때문이다. 그래서 Multi-Head Attention이라는 강력한 도구를 사용한다.
이름 그대로, 여러 개의 어텐션 Head가 각기 다른 관점에서 문장을 동시에 분석하는 방식이다.
Self-Attention 이 쿼리/키/밸류를 사용했다면, Multi-Head Attention은 이 쿼리/키/밸류를 여러 세트로 만든다.
예를 들어 Head-1 은 ‘주어-동사’의 문법적 관계에 집중하고, Head-2 는 문장 내의 ‘감정 표현’에 초점을 맞추는 식이다.
이렇게 여러 시선으로 분석한 결과를 하나로 통합하여 최종 어텐션 결과를 도출한다. 이 덕분에 트랜스포머는 단어가 가진 다채로운 문맥 정보를 훨씬 풍부하게 포착할 수 있다.
4.1.3. 어텐션 이후 정보를 정제하는 Feed-Forward
어텐션으로 문장의 핵심 정보를 모았다면, 다음은 이 정보를 다듬고 정리할 차례이다.
이 역할을 Feed-Forward 신경망이 수행한다.
하지만 정보를 계속 가공하다 보면 원본의 의미가 왜곡되거나 손실될 수 있다. 이를 방지하기 위해 트랜스포머는 두 가지 중요한 장치를 사용한다.
- 잔차 연결(Residual Connection)
- 구조도의
Add부분이다. - 어텐션을 거친 정보에 원본 입력 정보를 그대로 더해준다. ‘새로운 정보도 중요하지만, 원래 정보도 잊지 말라’는 신호로, 정보 손실을 막고 학습을 돕는다.
- 구조도의
- 레이어 정규화(Layer Normalization)
- 구조도의
Norm부분이다. - 계산 과정에서 값이 너무 커지거나 작아지는 것을 방지하여 학습 과정을 안정화 시킨다.
- 구조도의
이처럼 어텐션 → Add & Norm → 피드포워드 → Add & Norm의 과정이 하나의 인코더 블록을 구성하며, 트랜스포머는 이 블록을 여러 겹 쌓아 올려 문장의 의미를 더욱 깊이 있게 추출한다.
- 입력 임베딩이 Multi-Head Attention 레이어 통과
- 이 어텐션의 출력값이 원본 입력 임베딩과 더해짐(
Add) - 더해진 값이 정규화됨(
Norm) (여기까지가 첫 번째 하위 레이어) - 이 정규화된 값이 Feed-Forward 신경망을 통과함
- 이 Feed-Forward 의 출력값이 정규화된 값(4번째 값)과 더해짐(
Add) - 이 값이 다시 정규화됨(
Norm) (여기까지가 두 번째 하위 레이어)
4.2. Decoder: 새로운 문장 생성
인코더가 입력 문장을 정밀하게 분석했다면, 디코더는 그 분석 결과를 바탕으로 새로운 문장을 만들어낸다.
디코더 역시 어텐션을 사용하지만, 인코더와는 조금 다르게 두 종류의 어텐션을 결합하여 활용한다.
4.2.1. 생성된 문장 관계를 파악하는 Masked Self-Attention
디코더는 문장을 한 단어씩 순차적으로 생성한다. ‘오늘 날씨가 정말…’ 이라는 문장을 만들고 있다면, ‘정말’ 다음 단어를 예측하기 위해 앞서 생성한 ‘오늘’, ‘날씨’, ‘정말’ 의 문맥을 스스로 파악해야 한다.
이 때 인코더와 동일한 Self-Attention을 사용하지만 결정적인 차이가 있다.
인코더는 문장 전체를 한 번에 보지만, 디코더는 미래의 단어를 미리 봐서는 안 된다.
미리 다음 문장을 보고 나서 지금 쓸 문장을 결정해버리게 되면 실제로 예측하는 능력을 기르기 어렵기 때문이다.
그래서 이를 위해 Masking 이라는 장치를 사용한다. 현재 생성하려는 단어보다 뒤에 올 단어들의 정보는 가려서, 오직 이전에 생성된 단어들만 참고하여 다음 단어를 예측하도록 훈련한다. 이를 Masked Self-Attention 이라고 한다.
4.2.2. 인코더가 분석한 내용을 참고하는 Encoder-Decoder Attention
디코더는 자신이 생성 중인 문장의 흐름(Masked Self-Attention)만 보는 것이 아니라, 원본 입력 문장의 의미도 함께 참고한다.
인코더가 요약한 벡터를 참고하여 ‘이 영어 문장을 한국어로 번역하려면, 지금 시점에 영어 문장의 어떤 단어를 집중해서 봐야 할까?’를 판단해야 한다.
이 과정이 바로 Encoder-Decoder Attention이다. (구조도에서 두 번째 Multi-Head Attention 부분)
여기서 쿼리는 디코더가 ‘지금 이런 단어가 필요해’라고 던지는 질문이고, 키와 밸류는 인코더가 분석을 마친 입력 문장 전체의 의미 벡터이다.
디코더는 생성 중인 문장의 각 단어를 만들 때마다 인코더가 만든 의미 벡터 전체를 다시 한 번 살펴보고, 그 중 어떤 정보가 지금 가장 필요한지 동적으로 판단한다.
즉, 디코더는 앞서 자신이 만든 문장 흐름을 스스로 점검하고(Masked Self-Attention), 인코더가 이해한 입력 문장을 다시 훑어보며(Encoder-Decoder Attention), 가장 자연스럽고 적절한 다음 단어를 하나씩 생성해나간다.
이 부분이 디코더 구조도에서 Multi-Head Attention 이라고 적힌 부분이다. 인코더에서 2개의 화살표가 연결되어 있고, 디코더의 Masked Multi-Head Attention 에서 하나의 화살표가 연결된 것이 바로 그 의미이다.
4.2.3. 정보를 다듬는 Feed-Forward
디코더도 인코더와 마찬가지로, 두 종류의 어텐션을 거친 정보를 Feed-Forward 신경망과 Add & Norm 을 통해 한번 더 정제하여 최종적으로 다음 단어를 예측한다.
4.3. 트랜스포머 파이프라인 요약
트랜스포머의 인코더-디코더 흐름을 요약하면 아래와 같다.
| Encoder | Decoder | |
|---|---|---|
| 역할 | Self-Attention 으로 입력 문장을 이해 | Self-Attention 으로 새로운 문장을 생성 |
| 세부 내용 | - Self-Attention 으로 입력 문장의 단어 간 관계 파악 - 각 단어를 문맥에 맞게 표현하는 의미 벡터 생성 | - Masked Self-Attention 으로 지금까지 생성한 단어만 참고하여 다음 단어 예측 - Encoder-Decoder Attention 으로 입력 문장의 정보를 받아와 문장을 점차 완성함 |
이처럼 트랜스포머는 RNN 의 순차적 처리 방식을 과감히 버리고 어텐션 메커니즘을 채택함으로써 여러 장점을 얻었다.
- 병렬 처리
- 모든 단어를 동시에 처리할 수 있어 GPU 를 활용한 학습 속도가 매우 빠름
- 장기 의존성 해결
- Self-Attention 덕분에 문장의 맨 앞 단어와 맨 뒤 단어 사이의 연관성도 쉽게 계산 가능
- 풍부한 표현력
- Multi-Head Attention 이 다양한 관점으로 문맥 포착
- 확장성
- RNN 과 달리 구조가 간단하여 GPT, BERT 처럼 수백, 수천억 개의 파라미터를 가진 대규모 모델로 확장하기 좋음
5. 트랜스포머의 후손
트랜스포머의 인코더-디코더 아키텍처는 후속 연구자들에게 큰 영감을 주었다.
이들은 전체 구조를 그대로 사용하기보다 인코더만 사용하거나 디코더만 사용하는 방식으로 모델을 특화하기 시작했다.
5.1. BERT: Encoder
BERT(Bidirectional Encoder Representations from Transformers)는 이름에서 알 수 있듯이 인코더 구조만을 활용한 대표적인 모델이다.
인코더 기반이라는 것은 ‘문장을 깊이 이해하기에 최적화된 구조’라는 의미이다.
BERT의 핵심은 양방향(Bidirectional) 학습에 있다.
문장을 처음부터 끝까지 순차적으로 읽는 게 아니라 문장 전체를 앞뒤 방향에서 동시에 살펴본다.
‘나는 어제 __가 맛있어서 좋았다’
이런 문장의 빈칸을 추론하기 위해 BERT 는 빈칸의 앞 단어(‘어제’) 뿐만 아니라 뒷단어(‘맛있어서’)까지 모든 문맥을 참고한다.
이를 위해 MLM(Masked Language Model)이라는 독특한 학습 방식을 사용한다.
문장의 일부 단어를 무작위로 마스킹 처리하고, 모델이 앞뒤 문맥을 총동원하여 원래 단어가 무엇이었는지 맞추도록 훈련하는 것이다.
이런 훈련 덕분에 BERT 는 문장 내의 복잡한 의미 관계와 문맥을 풍부하게 학습한다.
따라서 분류(Classification), 문장의 의미 이해와 같은 분석 및 이해 작업에서 압도적인 성능을 발휘한다.
5.2. GPT: Decoder
GPT(Generative Pre-trained Transformer)는 트랜스포머의 디코더 구조만을 채택한 모델이다. GPT는 ‘문장을 만들어내는’ 생성 작업에 특화되어 있다.
GPT는 Auto-Regressive 모델이다. 이 방식은 ‘앞에서 만든 단어를 보고, 다음 단어를 하나씩 예측해 나가는’ 방식이다.
즉, 이전에 생성한 텍스트를 다시 입력으로 사용하여 다음 예측에 계속 누적해서 반영한다.
“오늘 날씨가” → (예측) → “정말”, “오늘 날씨가 정말” → (예측) → “좋네요”, “오늘 날씨가 정말 좋네요” → (예측) → “.”
이처럼 연속적으로 다음 단어를 생성해나가는 특성 때문에 GPT는 자연스럽고 논리적인 장문의 텍스트를 만들어내는 데 강력한 성능을 보인다.
요약하자면, BERT 가 인코더를 기반으로 문장을 깊이 있게 이해하는데 능숙하다면, GPT 는 디코더를 기반으로 문장을 자연스럽게 생성하는데 특화된 모델이라고 할 수 있다.
6. 왜 디코더 모델이 더 강세를 보이고 있을까?
최근 AI 분야의 화두는 단연 GPT, LLaMA, Gemma 등 디코더 기반의 모델들이다.
그렇다면 왜 BERT 와 같은 인코더 모델보다 GPT 계열의 디코더 모델이 더 큰 주목을 받고 있을까?
생성(generation)의 가치 상승 폭발
가장 큰 이유는 생성 AI 가 가져오는 막대한 비즈니스 기회와 파급력 때문이다.
디코더 기반의 Auto-Regressive 모델은 ‘다음 단어 예측’이라는 학습 목표 자체가 문장 생성 작업에 완벽하게 부합한다.
물론 디코더 모델이 생성에 최적화되어 있다고 해서 문맥 이해 능력이 떨어지는 것은 아니다.
GPT 시리즈가 수천억 개 이상의 파라미터와 인터넷 규모의 방대한 텍스트를 학습하면서, ‘이해’없이는 ‘생성’이 불가능하다는 것을 증명해보였다.
즉, 거대한 학습 과정을 거치며 자연스럽게 문맥을 파악하는 능력까지 갖추게 된 것이다.
활용 범위가 넓고, 주목받기 쉬운 성과
텍스트 생성은 눈에 보이는 성과를 즉각적으로 보여준다. 코드를 짜주고, 소설을 쓰고, 리포트를 요약해주는 능력은 대중에게 AI 의 힘을 가장 직관적으로 각인시켰다.
이는 인코더 기반 모델이 약해졌다는 의미가 절대 아니다. 지금 이 순간에도 검색 엔진, 감정 분석 등 수많은 서비스의 기저에는 BERT 와 같은 인코더 모델이 강력하게 동작하고 있다.
다만, 최근 기술의 화제성과 대중적 관심이 ‘문장 생성’쪽에 집중되다 보니, 자연스럽게 LLM 으로 확장하기 유리한 Auto-Regressive 구조의 디코더 모델들이 스포트라이트를 받게 된 것이다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 이영호 저자의 모두의 인공지능 with 파이썬을 기반으로 스터디하며 정리한 내용들입니다.
