Kubernetes - 모니터링(Metric Server, Prometheus, Grafana, Loki)
in DEV on DevOps Kubernetes K8s Monitoring Observability Metric-server Prometheus Grafana Loki Plg-stack Helm
쿠버네티스 모니터링은 클러스터 내의 노드, 파드, 컨테이너 등 다양한 리소스의 상태와 성능 지표(Metric)를 수집하고, 발생한 로그를 분석하여 시스템의 성능을 지속적으로 관찰하는 프로세스이다.
단순한 상태 확인을 넘어 가시성(Observability)을 확보하여 장애를 사전에 예방하고 효율적인 리소스 관리를 가능하게 하는 핵심 운영 요소이다.
쿠버네티스 클러스터의 규모가 확장됨에 따라, 수십에서 수백 개에 이르는 노드와 그 위에서 동작하는 수많은 파드를 개별적으로 관리하는 것은 사실상 불가능에 가깝다.
시스템의 복잡도가 증가할수록 클러스터 전체의 현황을 한 눈에 파악하고, 특정 지점에서 발생하는 병목이나 오류를 신속하게 탐지할 수 있는 통합된 모니터링 방법론이 필수적이다.
이번 포스트에서는 쿠버네티스 운영 환경에서 가장 널리 사용되는 표준 모니터링 스택을 구축하는 과정을 단계별로 다룬다.
리소스의 기초적인 사용량을 확인하는 단계부터, 데이터를 수집하고 시각화하며, 로그를 중앙에서 통합 관리하는 방법까지, 관측 가능한(Observable) 쿠버네티스 환경을 만드는 방법에 대해 알아본다.
- 메트릭 서버(Metric-Server)
kubectl top명령어 등을 통해 노드와 파드의 실시간 CPU 및 메모리 사용량을 확인하는 기초적인 방법
- 프로메테우스(Prometheus)
- 시계열 데이터 기반으로 클러스터의 방대한 모니터링 메트릭을 수집하고 저장하는 방법
- 그라파나(Grafana)
- 수집된 데이터를 직관적인 대시보드로 시각화하여 운영 효율성을 높이는 방법
- 로키(Loki)
- 여러 노드에 분산된 파드의 로그를 중앙에서 효율적으로 수집하고 조회하는(PLG Stack) 방법
- 1. 메트릭 서버(Metric-Server)를 통한 리소스 확인
- 2. 프로메테우스(Prometheus)를 통한 모니터링 데이터 수집
- 3. 그라파나(Grafana)를 통한 모니터링 데이터 시각화
- 4. 로키(Loki)를 활용한 쿠버네티스 로그 확인
- 정리하며..
- 참고 사이트 & 함께 보면 좋은 사이트
개발 환경
- Guest OS: Ubuntu 24.04.2 LTS
- Host OS: Mac Apple M3 Max
- Memory: 48 GB
- Kubernetes: v1.29.15
1. 메트릭 서버(Metric-Server)를 통한 리소스 확인
쿠버네티스는 파드의 부하량에 따라 자동으로 파드 수를 조절해주는 Horizontal Pod Autoscaler(HPA)가 존재한다.
그렇다면 HPA는 무엇을 근거로 스케일 업/다운을 결정할까?
이를 위해서는 현재 시스템의 리소스 상태를 파악해야 하는데, 이를 가능하게 해주는 것이 바로 메트릭 서버(Metric-Server)이다.
메트릭 서버는 쿠버네티스 클러스터 내의 노드와 파드로부터 CPU, 메모리 사용량 등의 메트릭(성능 지표)을 수집하여 API 서버를 통해 제공하는 핵심 애드온이다.
이 데이터는 HPA 뿐만 아니라 kubectl top 명령어를 통해 운영자가 리소스 현황을 파악하는 데에도 사용된다.
애드온(Add-on)
기본 기능에 덧붙여 설치하는 확장 프로그램
대표적인 쿠버네티스 애드온은 아래가 있다.
- 네트워크 플러그인(CNI)
- 파드끼리 통신할 수 있게 해줌(필수)
- 예) Calico, Flannel
- DNS 서버(CoreDNS)
- IP 주소 대신 도메인 이름으로 서비스를 찾게 해줌(필수)
- 대시보드
- 명령어가 아닌 웹 UI 화면으로 클러스터를 관리하게 해줌(선택)
- 로깅
- 컨테이너의 로그를 수집하고 저장함(선택)
- 모니터링
- 메트릭 서버나 프로메테우스 등(거의 필수)
1.1. 메트릭 서버 설치
먼저 설치를 진행할 작업 디렉터리를 생성한다.
assu@myserver01:~$ cd work/app
assu@myserver01:~/work/app$ ls
argocd helm metallb nginx-ingress-controller
assu@myserver01:~/work/app$ mkdir metric-server
assu@myserver01:~/work/app$ cd metric-server/
1.1.1. 헬름(Helm) 차트 준비
헬름 리포지토리에 metrics-server를 추가하고 최신 정보를 업데이트한다.
assu@myserver01:~/work/app/metric-server$ helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server
"metrics-server" has been added to your repositories
assu@myserver01:~/work/app/metric-server$ helm repo update
헬름 리포지토리에서 설치 가능한 버전을 확인하고 차트를 다운로드한다.
assu@myserver01:~/work/app/metric-server$ helm search repo metric
NAME CHART VERSION APP VERSION DESCRIPTION
...
metrics-server/metrics-server 3.13.0 0.8.0 Metrics Server is a scalable, efficient source ...
...
# 차트 다운로드 및 압축 해제
assu@myserver01:~/work/app/metric-server$ helm pull metrics-server/metrics-server
assu@myserver01:~/work/app/metric-server$ ls
metrics-server-3.13.0.tgz
assu@myserver01:~/work/app/metric-server$ tar xvfz metrics-server-3.13.0.tgz
metrics-server/Chart.yaml
...
assu@myserver01:~/work/app/metric-server$ ls
metrics-server metrics-server-3.13.0.tgz
assu@myserver01:~/work/app/metric-server$ mv metrics-server metrics-server-3.13.0
assu@myserver01:~/work/app/metric-server$ ls
metrics-server-3.13.0 metrics-server-3.13.0.tgz
1.1.2. values.yaml 수정(설정 커스터마이징)
기본 설정 파일인 values.yaml 을 복사하여 사용자 정의 설정 파일인 my-values.yaml 을 생성하고, 환경에 맞게 인자를 수정한다.
assu@myserver01:~/work/app/metric-server$ cd metrics-server-3.13.0/
assu@myserver01:~/work/app/metric-server/metrics-server-3.13.0$ ls
CHANGELOG.md Chart.yaml ci README.md RELEASE.md templates values.yaml
assu@myserver01:~/work/app/metric-server/metrics-server-3.13.0$ cp values.yaml my-values.yaml
assu@myserver01:~/work/app/metric-server/metrics-server-3.13.0$ ls
CHANGELOG.md Chart.yaml ci my-values.yaml README.md RELEASE.md templates values.yaml
defaultArgs:
- --cert-dir=/tmp
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls # 추가
- --kubelet-preferred-address-types=InternalIP # 추가
--kubelet-insecure-tls- 메트릭 서버가 kubelet에 접근할 때 TLS 인증서 검증을 건너뛰도록 설정
- 테스트 환경이나 사설 인증서(self-signed certificate)를 사용하는 환경에서 인증서 오류를 방지하기 위해 사용됨
- 프로덕션 환경에서는 보안상 주의가 필요함
--kubelet-preferred-address-types=InternalIP- 노드 간 통신 시 호스트 이름이나 외부 IP 대신 내부 IP(InternalIP)를 우선적으로 사용하도록 강제함
- 이는 DNS 설정이 완벽하지 않거나 내부 네트워크 통신만 허용된 환경에서 연결 문제를 해결해 줌
1.1.3. 설치 및 확인
작성한 my-values.yaml 파일을 적용하여 kube-system 네임 스페이스에 메트릭 서버를 설치한다.
# 아직은 메트릭 서버와 관련된 오브젝트가 없음
assu@myserver01:~/work/app/metric-server/metrics-server-3.13.0$ kubectl get all -n kube-system
NAME READY STATUS RESTARTS AGE
pod/coredns-76f75df574-lpvsm 1/1 Running 1 (19d ago) 20d
pod/coredns-76f75df574-m2mtp 1/1 Running 1 (19d ago) 20d
pod/etcd-myserver01 1/1 Running 1 (19d ago) 20d
pod/kube-apiserver-myserver01 1/1 Running 1 (19d ago) 20d
pod/kube-controller-manager-myserver01 1/1 Running 1 (19d ago) 20d
pod/kube-proxy-dlhdm 1/1 Running 1 (19d ago) 20d
pod/kube-proxy-jz4j8 1/1 Running 1 (19d ago) 20d
pod/kube-proxy-rjltj 1/1 Running 1 (19d ago) 20d
pod/kube-scheduler-myserver01 1/1 Running 1 (19d ago) 20d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 20d
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 20d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/coredns 2/2 2 2 20d
NAME DESIRED CURRENT READY AGE
replicaset.apps/coredns-76f75df574 2 2 2 20d
assu@myserver01:~/work/app/metric-server/metrics-server-3.13.0$ helm install -n kube-system \
--generate-name metrics-server/metrics-server -f my-values.yaml
NAME: metrics-server-1767493116
LAST DEPLOYED: Sun Jan 4 02:18:37 2026
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
DESCRIPTION: Install complete
TEST SUITE: None
NOTES:
***********************************************************************
* Metrics Server *
***********************************************************************
Chart version: 3.13.0
App version: 0.8.0
Image tag: registry.k8s.io/metrics-server/metrics-server:v0.8.0
***********************************************************************
설치가 완료되면 kube-system 네임스페이스의 리소스를 확인하여 파드가 정상적으로 실행 중인지 확인한다.
이제 다시 kube-system 네임스페이스의 오브젝트들을 확인해보자.
assu@myserver01:~/work/app/metric-server/metrics-server-3.13.0$ kubectl get all -n kube-system
NAME READY STATUS RESTARTS AGE
...
pod/metrics-server-1767493116-59cc4c4cb4-sv49h 0/1 Running 0 27s # 추가
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
service/metrics-server-1767493116 ClusterIP 10.102.162.208 <none> 443/TCP 27s # 추가
...
NAME READY UP-TO-DATE AVAILABLE AGE
...
deployment.apps/metrics-server-1767493116 0/1 1 0 27s # 추가
NAME DESIRED CURRENT READY AGE
...
replicaset.apps/metrics-server-1767493116-59cc4c4cb4 1 1 0 27s # 추가
metrics-server와 관련된 오브젝트(파드, 서비스, 디플로이먼트, 레플리카셋)가 추가된 것을 확인할 수 있다.
1.2. 메트릭 서버를 통한 리소스 사용량 확인
메트릭 서버 설치 후 1~2분 정도 후 수집된 데이터를 바탕으로 노드와 파드의 리소스 사용량을 조회할 수 있다.
1.2.1. 노드 및 파드 사용량 조회
# 노드의 CPU, 메모리 사용량 확인
assu@myserver01:~$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
myserver01 140m 3% 2637Mi 33%
myserver02 51m 1% 1720Mi 22%
myserver03 46m 1% 1817Mi 23%
# 파드 사용량 확인
assu@myserver01:~$ kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-76f75df574-lpvsm 3m 15Mi
metrics-server-1767493116-59cc4c4cb4-sv49h 5m 20Mi
...
1.2.2. 단위(Unit) 상세 해석과 전체 용량 확인 방법
kubectl top 명령어를 처음 접하면 140m, 2637Mi 와 같은 단위가 생소할 수 있다.
정확한 모니터링을 위해 이 단위들이 의미하는 바를 명확히 이해해야 한다.
1) CPU 단위: m(millicores)
- 오해
- 140m은 140MB가 아니다. CPU는 저장 공간이 아니므로 바이트 단위를 사용하지 않는다.
- 정의
m은 밀리코어(millicores)를 의미한다.- 1000m = 1 Core(vCPU)
- 즉, 140m은 0.14 Core를 사용 중이라는 뜻이다.
- 파드 예시
coredns파드가3m을 사용한다는 것은 0.003 Core 만큼의 CPU 연산을 수행 중이라는 의미이다.
2) Memory 단위: Mi(Mebibytes)
- 정의
Mi는 메비바이트(Mebibytes)를 의미한다.- 우리가 흔히 사용하는 MB(Megabytes)는 \(10^{6}(1,000,000)\) 바이트 기준이다.
- Mi는 \(2^{20}(1,048,576)\) 바이트 기준이다.
- 대략적으로 1 Mi ≈ 1.048 MB 이므로, 2637Mi는 약 2,765MB 정도의 메모리를 사용 중임을 나타낸다.
3) 전체 용량(Capacity) 및 사용률(%) 계산 확인
kubectl top nodes에서 보이는 CPU%와 MEMORY%는 해당 노드의 Allocatable(할당 가능) 리소스 대비 현재 사용량을 나타낸다.
전체 용량(Capacity)과 할당 가능 용량(Allocatable)을 정확히 확인하려면 kubectl describe node 명령어를 사용한다.
# 특정 노드의 상세 정보 확인
assu@myserver01:~$ kubectl describe node myserver01
...
Capacity:
cpu: 4 # 노드의 물리적 전체 CPU 코어 수
ephemeral-storage: 61202244Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 8086200Ki # 노드의 물리적 전체 메모리
pods: 110
Allocatable:
cpu: 4 # 파드에 할당 가능한 CPU 코어 수 (시스템 예약분 제외)
ephemeral-storage: 56391747653
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7983800Ki # 파드에 할당 가능한 메모리
...
kubectl top nodes 결과에서 myserver01의 CPU 사용량은 140m이고, 3%라고 출력되었었다.
- Allocatable CPU: 4 Core = 4000m
- Current Usage: 140m
- 계산: (140/4000) * 100 = 3.5% 인데 이를 반올림하여 약 3% 사용중이다.
따라서 전체 리소스 중 얼마를 쓰고 있는지 정확한 수치를 보고 싶다면 kubectl describe node를 통해 분모(전체 용량)를 확인하고, kubectl top을 통해 분자(현재 사용량)를 확인하면 된다.
2. 프로메테우스(Prometheus)를 통한 모니터링 데이터 수집
앞서 메트릭 서버를 통해 실시간 리소스 현황을 확인했다면, 이제는 시계열 데이터를 저장하고 분석할 수 있는 프로메테우스를 구축해본다.
프로메테우스의 개념을 이해하고, 헬름을 사용하여 프로메테우스와 그라파나가 포함된 스택을 설치한 후, 실제로 데이터가 수집되는지 확인한다.
2.1. 프로메테우스 개념
모니터링 시스템의 핵심은 메트릭이다.
메트릭이란 웹 서버 요청 횟수, CPU, 메모리 사용량 등 시스템 성능과 상태를 숫자로 나타낸 지표를 의미한다.
프로메테우스는 이러한 메트릭을 수집하는 도구로, 쿠버네티스 생태계에서 사실상의 표준으로 자리잡았다.
프로메테우스는 쿠버네티스 노드, 파드, 그리고 Persistent Volume 등에서 데이터를 주기적으로 긁어오는(pull) 구조를 가진다.
여기서는 kube-prometheus-stack 이라는 헬름 차트를 사용한다.
이 차트를 설치하면 단순히 프로메테우스만 설치되는 것이 아니라, 모니터링에 필요한 세트가 함께 설치된다.
- Prometheus: 메트릭 수집 및 저장
- Grafana: 수집된 메트릭 시각화
- Alertmanager: 경고 메시지 전송 관리
- Node Exporter: 하드웨어 및 OS 레벨의 메트릭 노출
2.2. 프로메테우스와 그라파나 설치
먼저 설치 작업을 진행할 디렉터리를 생성한다.
assu@myserver01:~$ cd work/app
assu@myserver01:~/work/app$ ls
argocd helm metallb metric-server nginx-ingress-controller
assu@myserver01:~/work/app$ mkdir prometheus
assu@myserver01:~/work/app$ cd prometheus/
2.2.1. 헬름 차트 준비
프로메테우스 커뮤니티 리포지토리를 추가하고 차트를 다운로드한다.
assu@myserver01:~/work/app/prometheus$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
# 헬름 업데이트
assu@myserver01:~/work/app/prometheus$ helm repo update
# 차트 검색
assu@myserver01:~/work/app/prometheus$ helm search repo prometheus
NAME CHART VERSION APP VERSION DESCRIPTION
...
prometheus-community/kube-prometheus-stack 80.10.0 v0.87.1 kube-prometheus-stack collects Kubernetes manif...
# 다운로드
assu@myserver01:~/work/app/prometheus$ helm pull prometheus-community/kube-prometheus-stack
assu@myserver01:~/work/app/prometheus$ ls
kube-prometheus-stack-80.10.0.tgz
assu@myserver01:~/work/app/prometheus$ tar xvfz kube-prometheus-stack-80.10.0.tgz
assu@myserver01:~/work/app/prometheus$ ls
kube-prometheus-stack kube-prometheus-stack-80.10.0.tgz
assu@myserver01:~/work/app/prometheus$ mv kube-prometheus-stack kube-prometheus-stack-80.10.0
assu@myserver01:~/work/app/prometheus$ ls
kube-prometheus-stack-80.10.0 kube-prometheus-stack-80.10.0.tgz
assu@myserver01:~/work/app/prometheus$ cd kube-prometheus-stack-80.10.0/
2.2.2. values.yaml 수정(프로메테우스 설정)
기본 설정 파일을 복사하여 my-values.yaml 을 만들고, 운영 환경에 맞게 수정한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ ls
Chart.lock charts Chart.yaml README.md templates values.yaml
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ cp values.yaml my-values.yaml
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ ls
Chart.lock charts Chart.yaml my-values.yaml README.md templates values.yaml
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ vim my-values.yaml
주요 수정 사항 및 설명
1) 서비스 타입 변경(NodePort)
prometheus.service.type 수정
service:
...
nodePort: 30090
type: NodePort # 수정 (기존 ClusterIP)
기본적으로 프로메테우스 서비스는 클러스터 내부에서만 접근 가능한 ClusterIP 타입이다.
이를 외부(호스트 머신) 등에서 직접 웹 UI에 접속할 수 있도록 NodePort 타입으로 변경하고, 30090 포트를 고정으로 할당하였다.
2) Service Monitor Selector 설정
serviceMonitorSelectorNilUsesHelmValues: false # 수정 (기존 true)
프로메테우스는 ServiceMonitor 라는 리소스를 통해 어떤 파드를 모니터링할지 결정한다.
이 값이 true 이면 헬름 차트가 관리하는 ServiceMonitor만 수집한다.
이를 false로 설정해야 나중에 우리가 직접 배포할 애플리케이션의 ServiceMonitor도 프로메테우스가 감지하여 데이터를 수집할 수 있다.
3) 데이터 보관 주기 및 용량 설정
# 데이터 유지기간 10일(기본값)
retention: 10d
retentionSize: "1GiB" # 수정 (기존: "")
수집한 메트릭 데이터를 10일간 보관하고, 저장된 데이터 용량이 1GB를 초과하면 보관기간(10일)이 지나지 않았더라도 가장 오래된 데이터부터 삭제한다.
디스크 용량 부족을 방지하기 위한 안전 장치이다.
2.2.3. values.yaml 수정(그라파나 설정)
프로메테우스 뿐 아니라 그라파나의 서비스 타입도 변경해야 한다.
그라파나 차트는 charts/grafana 경로에 위치한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ ls
Chart.lock charts Chart.yaml my-values.yaml README.md templates values.yaml
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ cd charts/
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0/charts$ ls
crds grafana kube-state-metrics prometheus-node-exporter prometheus-windows-exporter
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0/charts$ cd grafana/
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0/charts/grafana$ ls
Chart.yaml ci dashboards README.md templates values.yaml
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0/charts/grafana$ vim values.yaml
# 수정 후
service:
enabled: true
type: NodePort # 수정 (기존 ClusterIP)
2.2.4. 설치 진행
모니터링 전용 네임스페이스 mymonitoring 을 생성하고 스택을 배포한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl create namespace mymonitoring
namespace/mymonitoring created
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get namespace
NAME STATUS AGE
...
mymonitoring Active 11s
...
이제 프로메테우스를 설치한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ helm install -n mymonitoring --generate-name \
prometheus-community/kube-prometheus-stack -f my-values.yaml
NAME: kube-prometheus-stack-1767502407
LAST DEPLOYED: Sun Jan 4 04:53:30 2026
NAMESPACE: mymonitoring
STATUS: deployed
REVISION: 1
DESCRIPTION: Install complete
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace mymonitoring get pods -l "release=kube-prometheus-stack-1767502407"
Get Grafana 'admin' user password by running:
kubectl --namespace mymonitoring get secrets kube-prometheus-stack-1767502407-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Access Grafana local instance:
export POD_NAME=$(kubectl --namespace mymonitoring get pod -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=kube-prometheus-stack-1767502407" -oname)
kubectl --namespace mymonitoring port-forward $POD_NAME 3000
Get your grafana admin user password by running:
kubectl get secret --namespace mymonitoring -l app.kubernetes.io/component=admin-secret -o jsonpath="{.items[0].data.admin-password}" | base64 --decode ; echo
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
2.3. 프로메테우스를 통한 데이터 확인
설치가 완료되면 파드와 서비스 상태를 확인한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get all -n mymonitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-1767-alertmanager-0 2/2 Running 0 16s
pod/kube-prometheus-stack-1767-operator-579c9cd49f-l7hs2 1/1 Running 0 21s
pod/kube-prometheus-stack-1767503046-grafana-655c88c77b-54gc4 3/3 Running 0 21s
pod/kube-prometheus-stack-1767503046-kube-state-metrics-67c945ndvpq 1/1 Running 0 21s
pod/kube-prometheus-stack-1767503046-prometheus-node-exporter-2k4mw 1/1 Running 0 21s
pod/kube-prometheus-stack-1767503046-prometheus-node-exporter-9bv2l 1/1 Running 0 21s
pod/kube-prometheus-stack-1767503046-prometheus-node-exporter-j2dw8 1/1 Running 0 21s
pod/prometheus-kube-prometheus-stack-1767-prometheus-0 2/2 Running 0 16s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 16s
service/kube-prometheus-stack-1767-alertmanager ClusterIP 10.111.7.79 <none> 9093/TCP,8080/TCP 22s
service/kube-prometheus-stack-1767-operator ClusterIP 10.106.8.158 <none> 443/TCP 22s
service/kube-prometheus-stack-1767-prometheus NodePort 10.106.34.63 <none> 9090:30090/TCP,8080:32011/TCP 22s
service/kube-prometheus-stack-1767503046-grafana ClusterIP 10.101.160.47 <none> 80/TCP 22s
service/kube-prometheus-stack-1767503046-kube-state-metrics ClusterIP 10.108.142.71 <none> 8080/TCP 22s
# node-exporter가 9100 포트를 사용하고 있음
service/kube-prometheus-stack-1767503046-prometheus-node-exporter ClusterIP 10.102.144.228 <none> 9100/TCP 22s
service/prometheus-operated ClusterIP None <none> 9090/TCP 16s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prometheus-stack-1767503046-prometheus-node-exporter 3 3 3 3 3 kubernetes.io/os=linux 21s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prometheus-stack-1767-operator 1/1 1 1 21s
deployment.apps/kube-prometheus-stack-1767503046-grafana 1/1 1 1 21s
deployment.apps/kube-prometheus-stack-1767503046-kube-state-metrics 1/1 1 1 21s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prometheus-stack-1767-operator-579c9cd49f 1 1 1 21s
replicaset.apps/kube-prometheus-stack-1767503046-grafana-655c88c77b 1 1 1 21s
replicaset.apps/kube-prometheus-stack-1767503046-kube-state-metrics-67c9457ccf 1 1 1 21s
NAME READY AGE
statefulset.apps/alertmanager-kube-prometheus-stack-1767-alertmanager 1/1 16s
statefulset.apps/prometheus-kube-prometheus-stack-1767-prometheus 1/1 16s
2.3.1. Node Exporter 확인
목록을 보면 prometheus-node-exporter 라는 서비스와 데몬셋(DaemonSet)이 보인다.
Node Exporter
쿠버네티스 노드(서버) 자체는 기본적으로 자신의 CPU, 메모리, 디스크 I/O, 네트워크 트래픽 등의 하드웨어 정보를 프로메테우스가 이해할 수 있는 메트릭 형태로 제공하지 않는다.
Node Exporter는 모든 노드에 하나씩 설치(DaemonSet)되어, 노드의 OS 레벨 메트릭을 수집하고, 이를 /metrics 엔드포인트로 노출하여 프로메테우스가 가져갈 수 있도록 변환해주는 역할을 한다.
Node Exporter가 정상 동작하는지 확인하기 위해 포트포워딩을 설정한다.
(로컬 호스트의 8080 포트를 9100 포트로 포트포워딩)
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl port-forward --address 0.0.0.0 \
service/kube-prometheus-stack-1767503046-prometheus-node-exporter 8080:9100 \
--namespace mymonitoring
Forwarding from 0.0.0.0:8080 -> 9100
2.3.2. 프로메테우스 웹 UI 접속
프로메테우스 대시보드에 접속하기 위해 위의 서비스 정보를 다시 확인해보자.
service/kube-prometheus-stack-1767-prometheus NodePort 10.106.34.63 <none> 9090:30090/TCP,8080:32011/TCP 22s
여기서 포트 정보가 9090:30090/TCP,8080:32011/TCP 두 가지가 보인다.
- 9090:30090/TCP
- 9090번은 프로메테우스 서버의 메인 포트이다.
- 이를 NodePort 30090으로 매핑했다.
- 우리가 접속해야 할 포트이다.
- 8080:32011/TCP
- 8080번은 프로메테우스 파드 내에 있는 사이드카(Config Reloader 등) 컨테이너용 포트이다.
- 이는 NodePort 32011로 매핑되어 있다.
- 메인 UI가 아니므로 이곳으로 접속하면 UI를 볼 수 없다.
따라서 외부에서 접속했을 때 Node Exporter에 접속할 수 있도록 호스트(VM) 포트포워딩 설정 시 30090 포트를 열어야 한다.
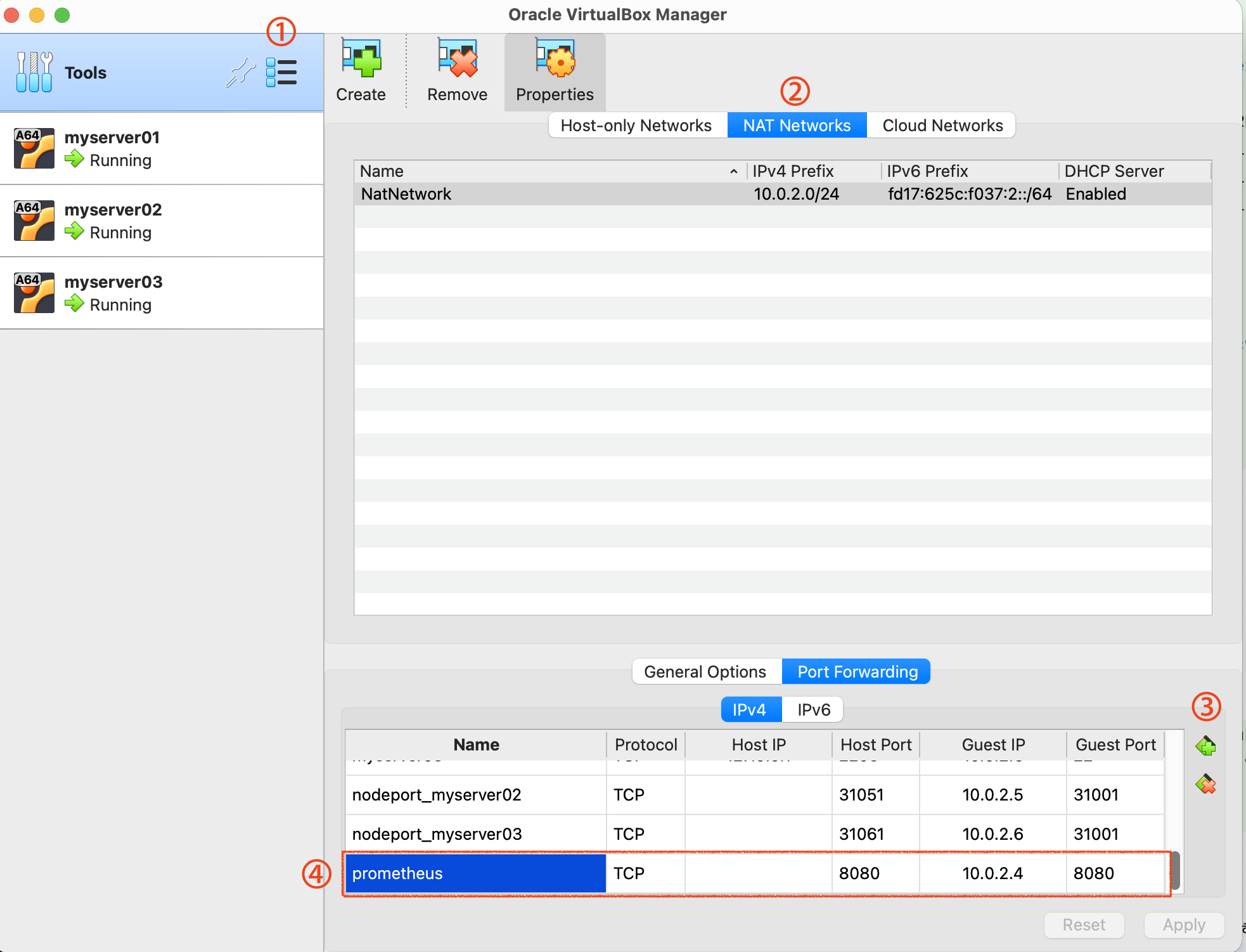
웹 브라우저에서 http://127.0.0.1:8080 으로 접속하면 프로메테우스 메인 화면을 확인할 수 있다. (Node Exporter)
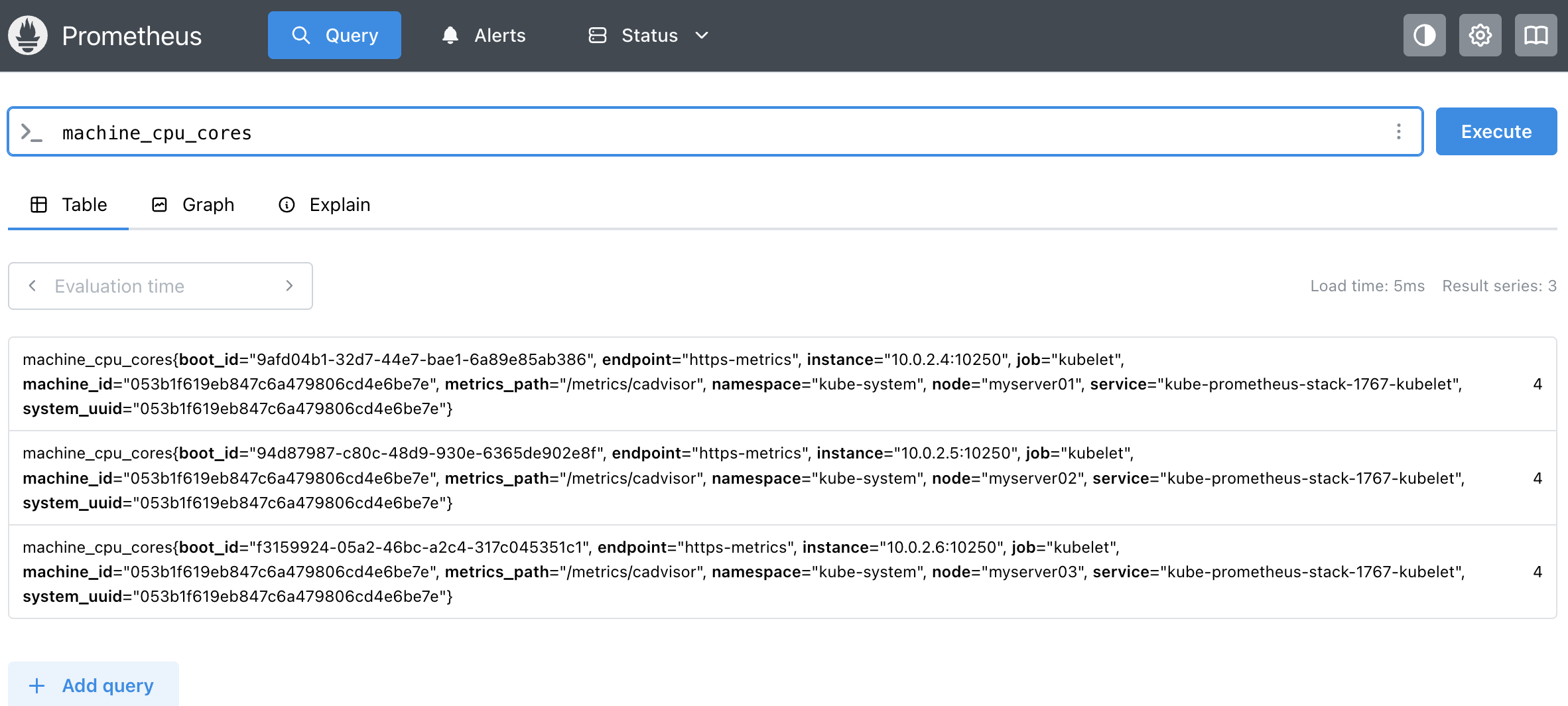
상단 검색창에 node_memory_MemTotal_bytes와 같은 쿼리를 입력하고 실행하면, Node Exporter가 수집한 데이터가 조회되는 것을 확인할 수 있다.
아래와 같이 다양한 정보를 검색할 수 있다.
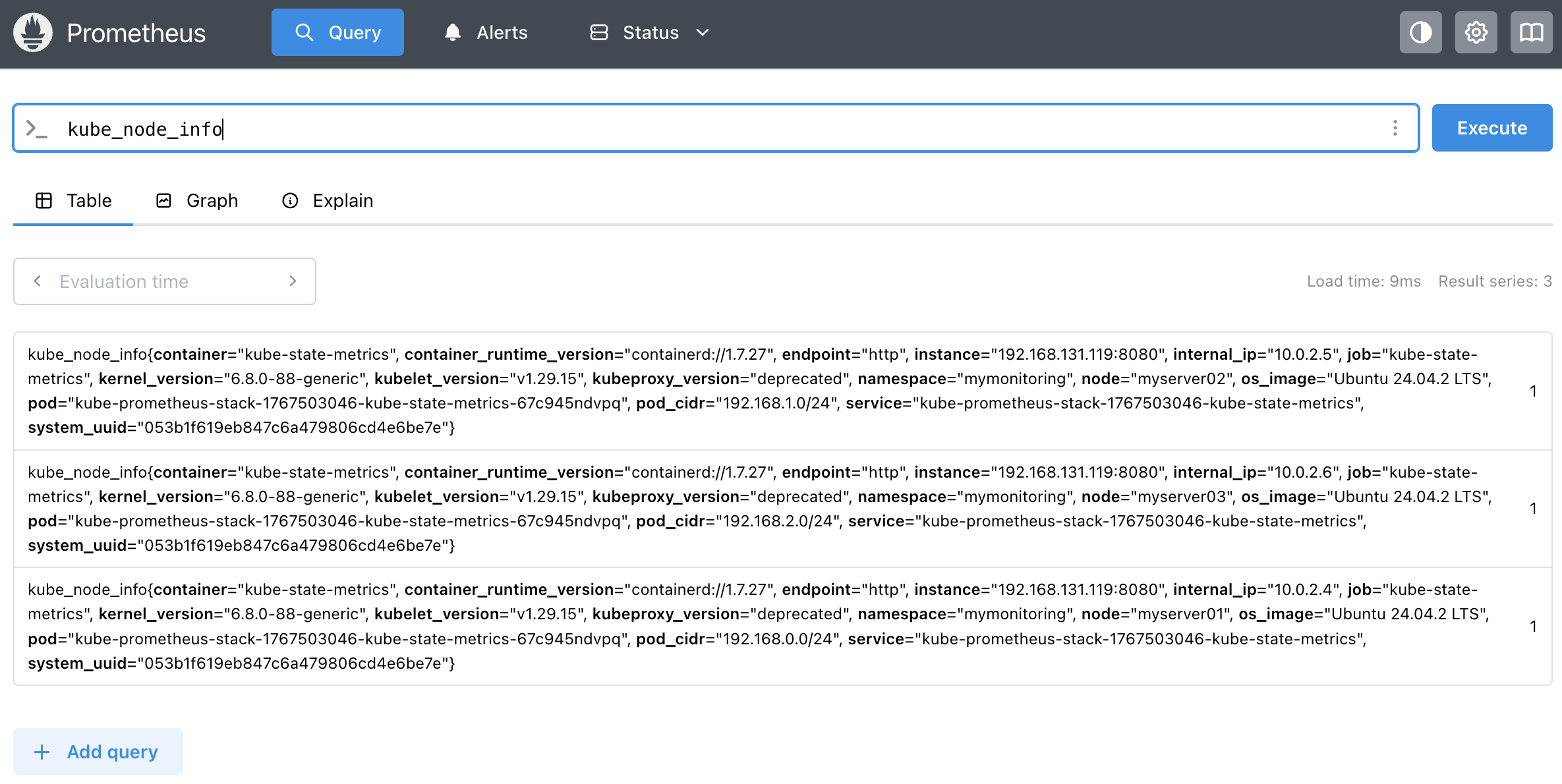
3. 그라파나(Grafana)를 통한 모니터링 데이터 시각화
프로메테우스가 데이터를 수집하고 저장하는 역할을 한다면, 그라파나는 이 데이터를 시각화해주는 도구이다.
프로메테우스 자체 UI는 디버깅 용도로는 훌륭하지만, 운영자가 전체 시스템 현황을 한 눈에 파악하기에는 부족함이 있다.
따라서 프로메테우스와 그라파나는 바늘과 실처럼 항상 함께 사용된다.
앞서 kube-prometheus-stack을 설치할 때 그라파나도 함께 설치되었으므로, 여기서는 그라파나의 외부 접속 설정을 변경하고 대시보드를 구성하는 방법을 다룬다.
3.1. 그라파나 서비스 타입 변경(LoadBalancer)
먼저 현재 그라파나 서비스의 상태를 확인한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get svc -n mymonitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 76m
kube-prometheus-stack-1767-alertmanager ClusterIP 10.111.7.79 <none> 9093/TCP,8080/TCP 76m
kube-prometheus-stack-1767-operator ClusterIP 10.106.8.158 <none> 443/TCP 76m
kube-prometheus-stack-1767-prometheus NodePort 10.106.34.63 <none> 9090:30090/TCP,8080:32011/TCP 76m
# 그라파나 존재
kube-prometheus-stack-1767503046-grafana ClusterIP 10.101.160.47 <none> 80/TCP 76m
kube-prometheus-stack-1767503046-kube-state-metrics ClusterIP 10.108.142.71 <none> 8080/TCP 76m
kube-prometheus-stack-1767503046-prometheus-node-exporter ClusterIP 10.102.144.228 <none> 9100/TCP 76m
prometheus-operated ClusterIP None <none> 9090/TCP 76m
기본적으로 ClusterIP로 설정되어 있어 외부에서 직접 접속이 불가능하다.
이를 LoadBalancer 타입으로 변경하여 외부 IP를 할당받도록 설정한다.
3.1.1. 서비스 패치(Patch)
kubectl edit 을 사용할 수도 있지만, kubectl patch 명령어를 사용하면 CLI에서 즉시 설정을 변경할 수 있어 편리하다.
서비스 타입 변경 전
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get svc kube-prometheus-stack-1767503046-grafana \
-n mymonitoring -o yaml
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: kube-prometheus-stack-1767503046
meta.helm.sh/release-namespace: mymonitoring
creationTimestamp: "2026-01-04T05:04:12Z"
labels:
app.kubernetes.io/instance: kube-prometheus-stack-1767503046
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 12.3.1
helm.sh/chart: grafana-10.4.3
name: kube-prometheus-stack-1767503046-grafana
namespace: mymonitoring
resourceVersion: "539399"
uid: d7c2426c-9f08-4396-92d9-18ff27dc705e
spec:
clusterIP: 10.101.160.47
clusterIPs:
- 10.101.160.47
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http-web
port: 80
protocol: TCP
targetPort: grafana
selector:
app.kubernetes.io/instance: kube-prometheus-stack-1767503046
app.kubernetes.io/name: grafana
sessionAffinity: None
type: ClusterIP # spec.type 이 ClusterIP로 되어있음
status:
loadBalancer: {}
patch 명령어를 통해 서비스 타입을 수정한다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl patch svc kube-prometheus-stack-1767503046-grafana \
> -n mymonitoring -p '{"spec": {"type": "LoadBalancer"}}'
service/kube-prometheus-stack-1767503046-grafana patched
다시 서비스를 확인하면 그라파나의 서비스 타입이 LoadBalancer로 변경된 것을 볼 수 있다.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get svc -n mymonitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-prometheus-stack-1767503046-grafana LoadBalancer 10.101.160.47 10.0.2.22 80:31072/TCP 83m
...
- Type: LoadBalancer
- External-IP: 10.0.2.22
- Port: 80 (내부적으로 31082 NodePort와 매핑됨)
다시 그라파나의 정보를 확인해보자.
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get svc kube-prometheus-stack-1767503046-grafana -n mymonitoring -o yaml
apiVersion: v1
kind: Service
metadata:
...
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 10.0.2.22
3.1.2. 접속을 위한 포트포워딩 설정
VM 환경에서 운영 중이므로, 호스트 OS(내 PC)에서 VM 내부의 LoadBalancer의 IP(10.0.2.22)에 접속하기 위해 VM 포트포워딩을 추가한다.
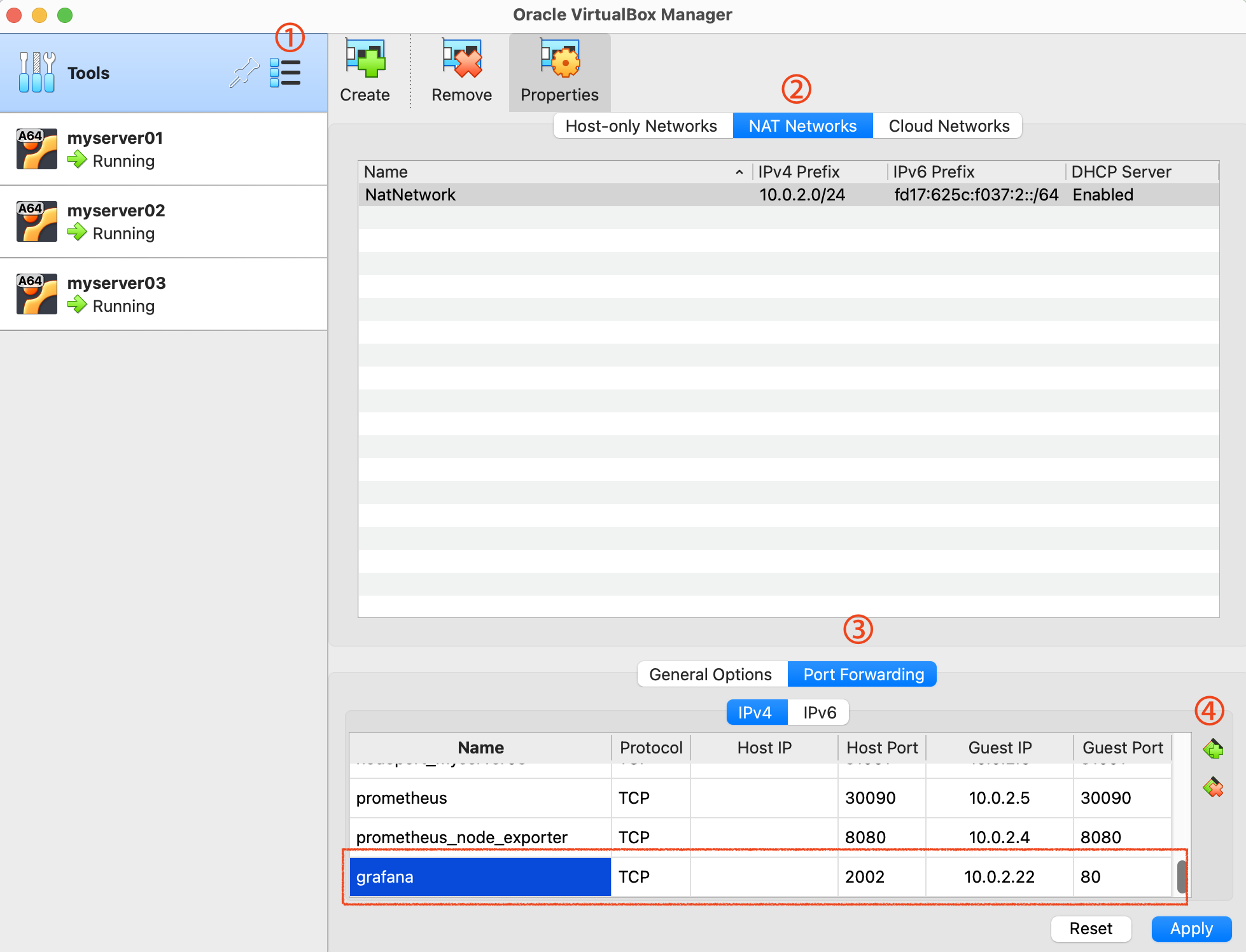
설정이 완료되면 http://127.0.0.1:2002 을 통해 그라파나에 접근할 수 있게 된다.
3.2. 그라파나 접속 및 초기 설정
3.2.1. 관리자 비밀번호 확인
그라파나의 초기 계정 정보는 쿠버네티스 Secret 리소스에 안전하게 저장되어 있다.
# 그라파나와 관련된 시크릿 정보 확인
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get secrets kube-prometheus-stack-1767503046-grafana -n mymonitoring -o yaml
apiVersion: v1
data:
# 접속 비밀번호가 암호화되어 있는 것을 확인할 수 있음
admin-password: SVBseTFtb0o1cnA3VWJTeHQ5RHBsZWozaDVMNVgzOUIyTkpxcTBwQw==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
...
시크릿의 내용은 base64로 인코딩되어 있다.
jsonpath 옵션과 base64 -d 명령을 조합하여 디코딩된 실제 비밀번호를 확인한다.
# 인코딩된 비밀번호를 확인하기 위해 `base64 -d`를 입력하여 인코딩된 비밀번호를 디코딩함
assu@myserver01:~/work/app/prometheus/kube-prometheus-stack-80.10.0$ kubectl get secrets kube-prometheus-stack-1767503046-grafana \
> -n mymonitoring -o jsonpath="{.data.admin-password}" | base64 -d
# 실제 비밀번호 확인
IPly1moJ5rp7UbSxt9Dplej3h5L5X39B2NJqq0pC
3.2.2. 로그인 및 기본 대시보드 확인
웹 브라우저에서 http://127.0.0.1:2002 에 접속하면 로그인 화면이 뜬다.
- User: admin
- Password: 위에서 확인한 비밀번호
로그인 후 좌측 메뉴의 Dashboards를 클릭하면 kube-prometheus-stack이 기본적으로 제공하는 다양한 대시보드 목록을 볼 수 있다.
예를 들어 ‘Kubernetes / Compute Resources / Node (Pods)’ 등을 클릭하면 별도의 설정 없이도 노드별 리소스 사용량을 그래프로 확인할 수 있다.
3.3. 외부 대시보드 임포트
기본 대시보드 외에도 전 세계 사용자들이 만들어 공유한 대시보드를 쉽게 가져와 사용할 수 있다.
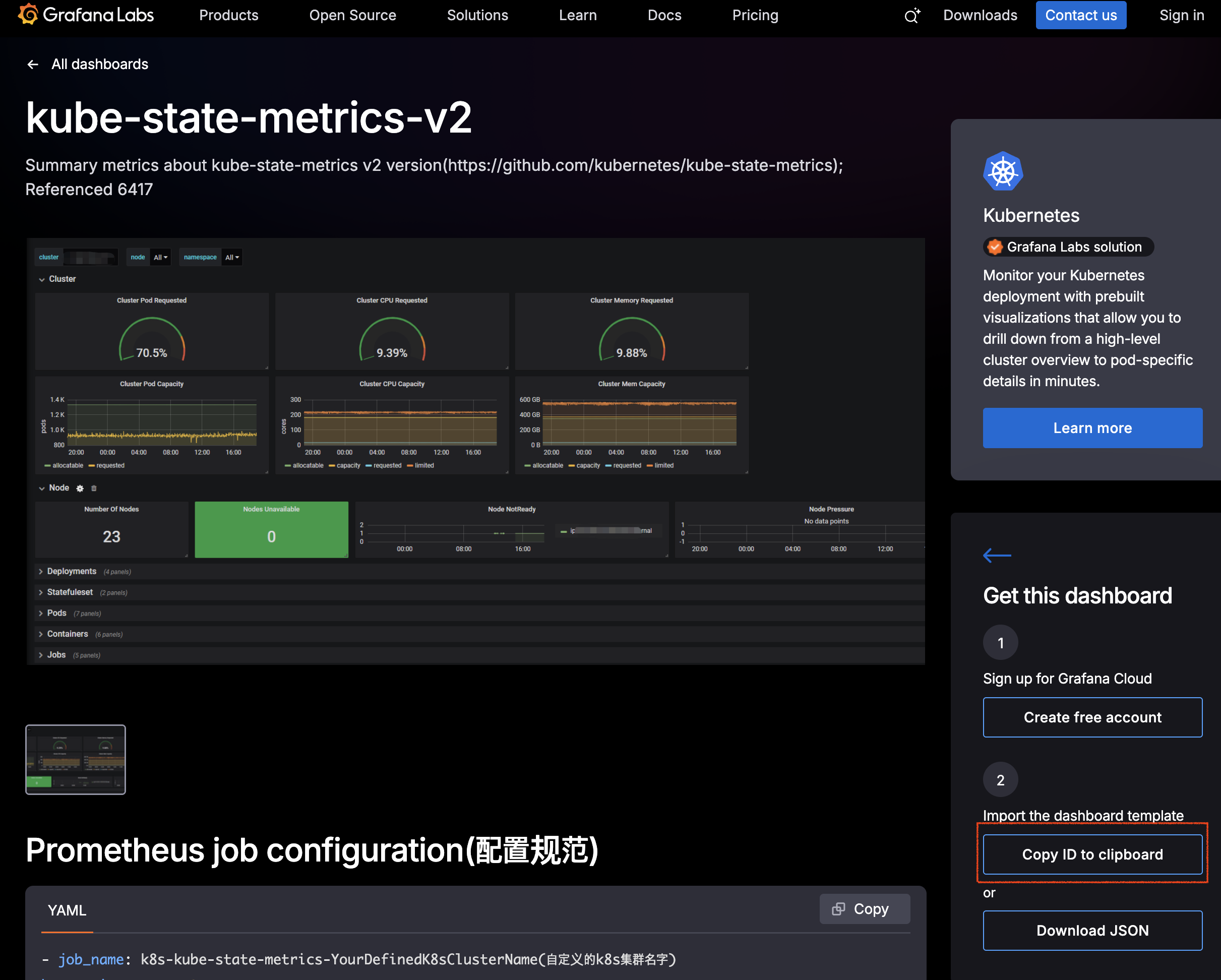
여기서는 ‘Kubernetes / Views / Global’ 뷰를 제공하는 ID 13332 대시보드를 추가해본다.
1) 대시보드 ID 복사
- https://grafana.com/grafana/dashboards/13332-kube-state-metrics-v2 접속
- 우측 하단의 Copy ID to clipboard 클릭
2) 그라파나에서 임포트
- 그라파나 메뉴: Dashboards > New > Import
13332 입력 후 Load 클릭
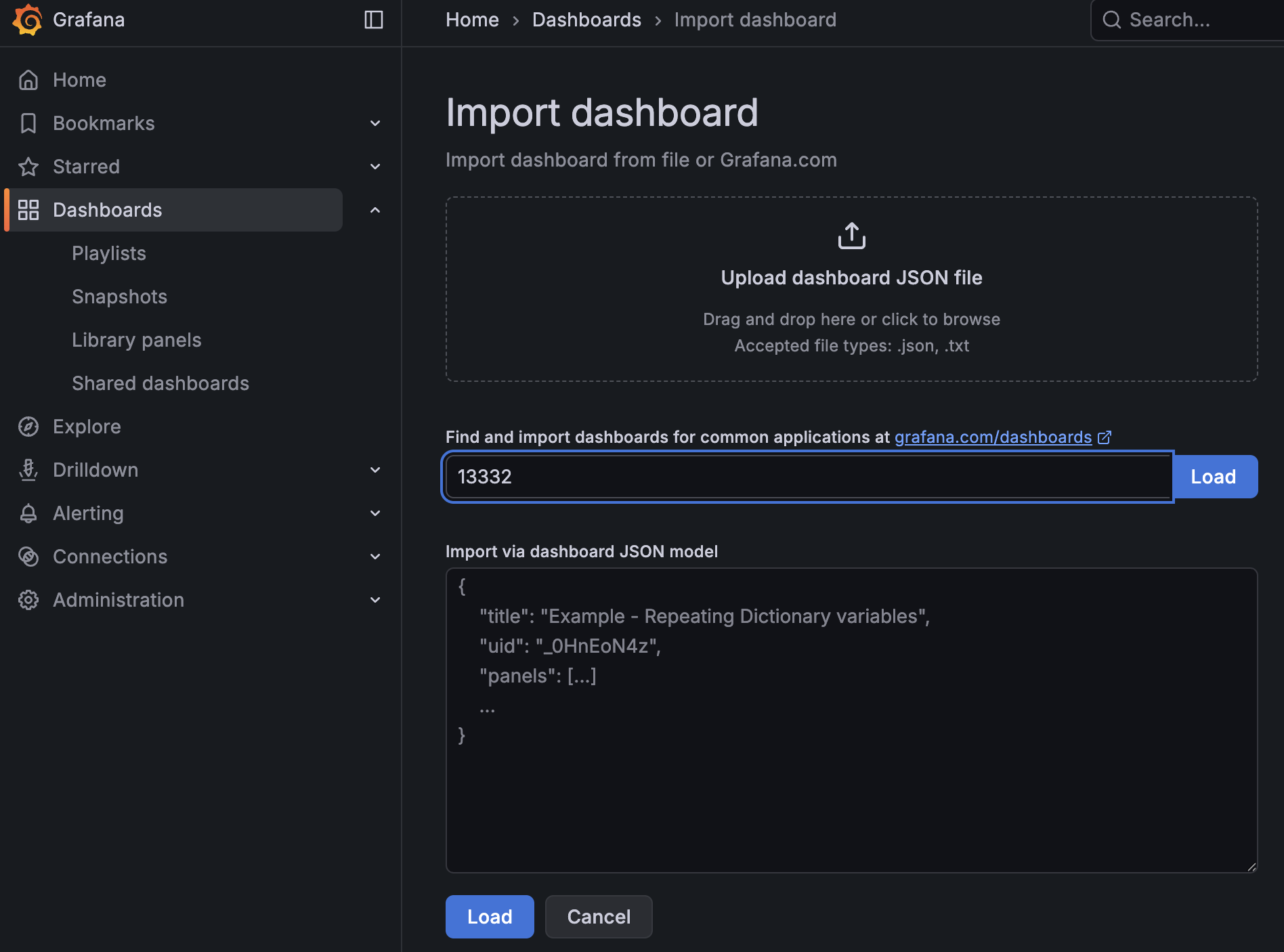
3) 데이터 소스 연결
설정 화면 하단의 Prometheus 드롭다운 메뉴에서 데이터 소스로 Prometheus를 선택하고 Import 버튼을 클릭한다.
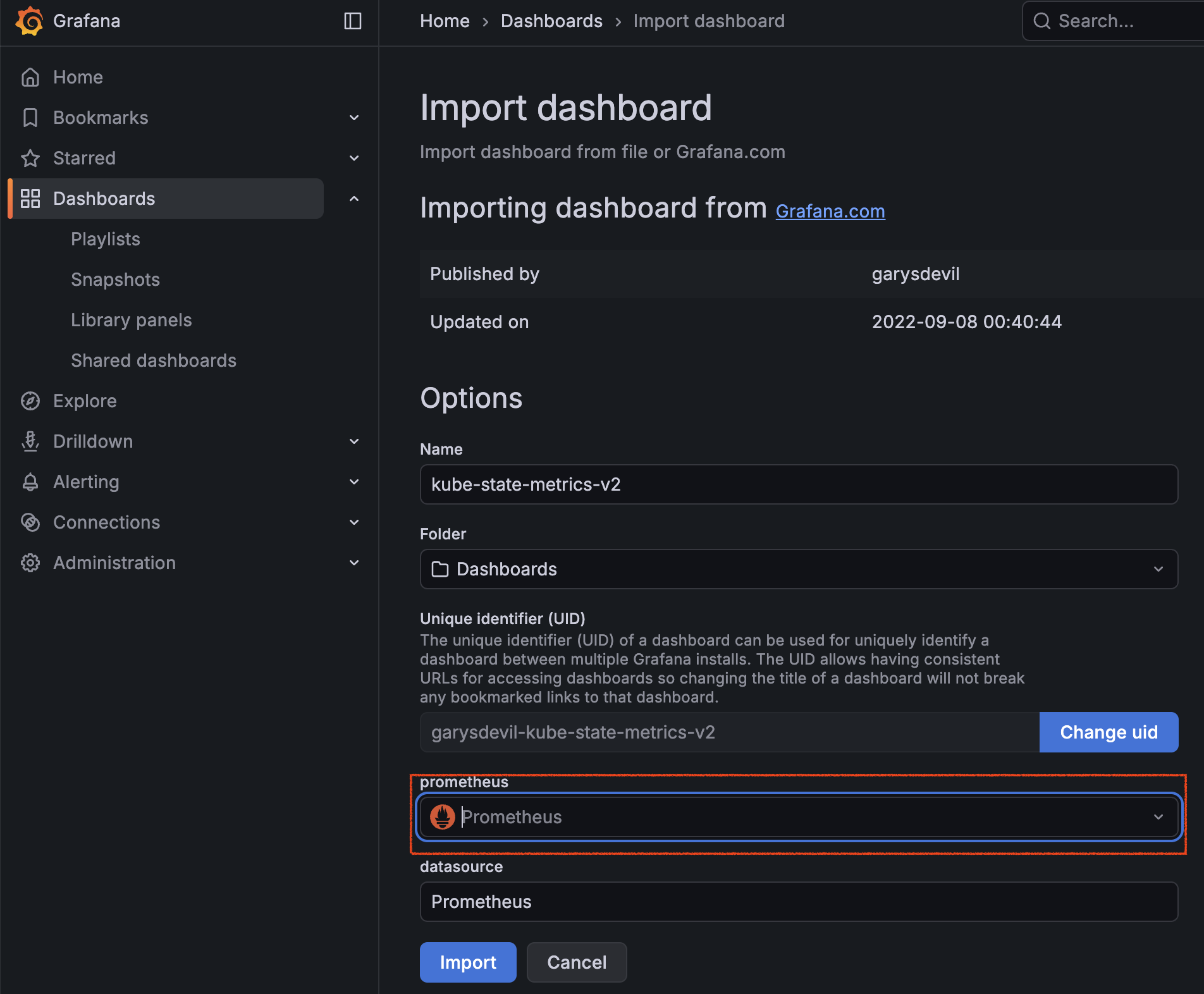
4) 결과 확인
임포트가 완료되면 아래와 같이 클러스터 전체의 상태를 보여주는 새로운 대시보드가 생성된다.
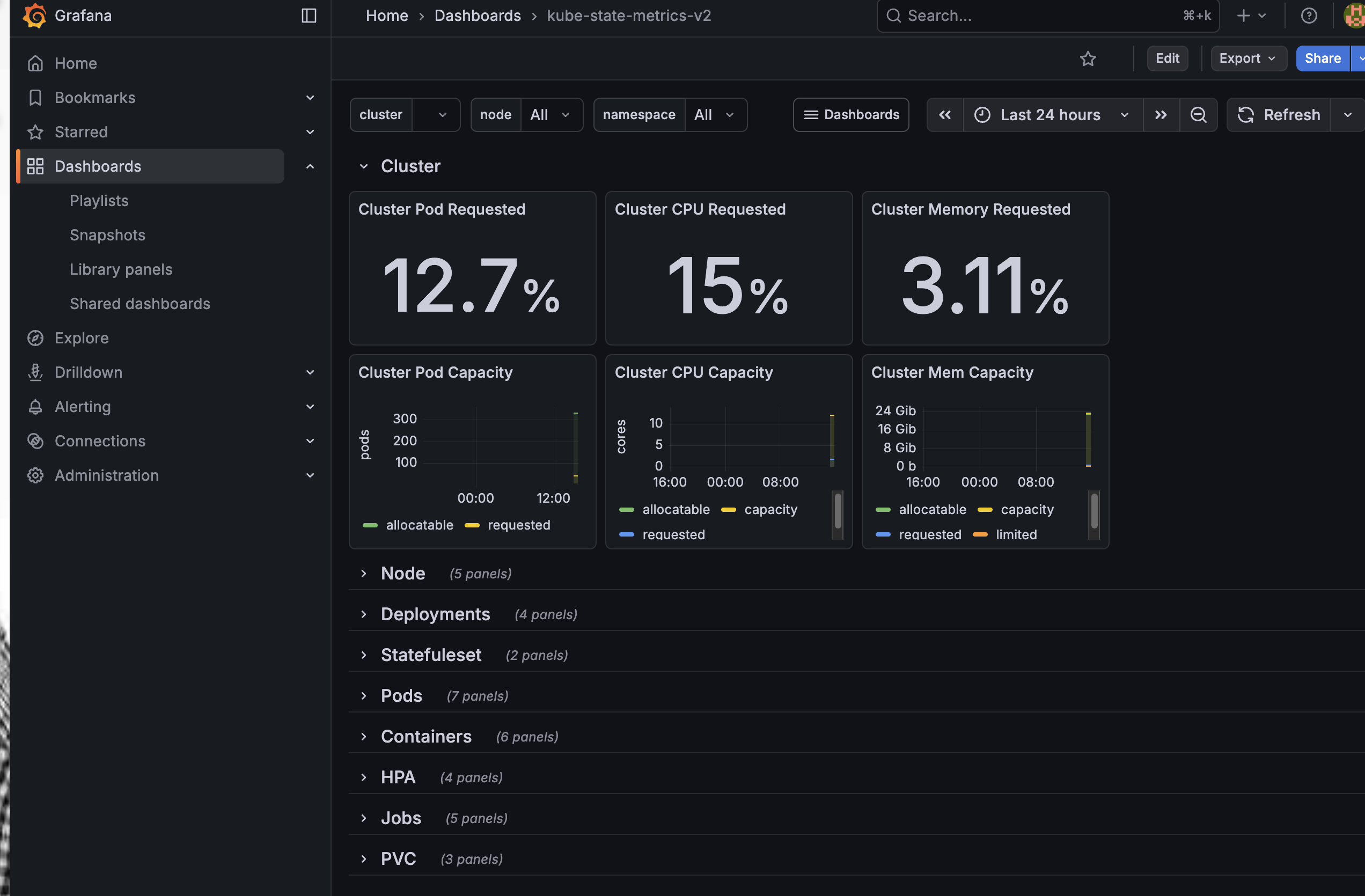
이처럼 그라파나는 강력한 커뮤니티 생태계를 가지고 있어, 필요한 거의 모든 형태의 모니터링 뷰를 손쉽게 구축할 수 있다.
4. 로키(Loki)를 활용한 쿠버네티스 로그 확인
리소스 사용량은 프로메테우스로 확인했다면, 애플리케이션이나 시스템에서 발생하는 로그는 어떻게 관리해야 할까?
전통적인 리눅스 서버라면 각 노드에 접속하여 /var/log 를 뒤지겠지만, 파드가 수시로 생성되고 사라지는 쿠버네티스 환경에서는 불가능하다.
이를 해결하기 위해 PLG 스택(Promtail + Loki + Grafana)을 구축하여 로그를 중앙에서 통합 관리한다.
4.1. 로키 개념과 PLG(Promtail+Loki+Grafana) 개념
로키는 ‘로그를 위한 프로메테우스’라고 불리는 오픈소스 로그 집계 시스템이다.
로그 데이터 전체를 인덱싱하는 대신, 로그에 붙은 라벨(Label)만 인덱싱하여 자원 소모가 적고 운영 비용이 저렴하다는 장점이 있다.
로키는 단독으로 쓰이지 않고 보통 다음의 PLG 구조로 동작한다.
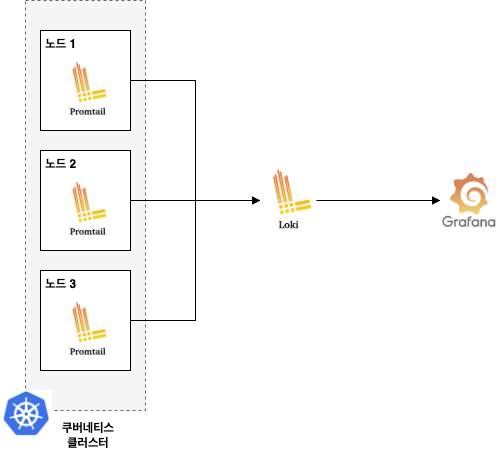
- Promtail
- 로그 수집기 역할
- 모든 노드에 데몬셋(DaemonSet)으로 설치되어 각 파드와 노드의 로그를 수집(Tail)하여 로키로 전송
- Loki
- 로그 저장소 역할
- 수집된 로그를 저장하고 LogQL이라는 쿼리 언어를 통해 조회할 수 있게 해줌
- Grafana
- 시각화 역할
- 로키를 데이터 소스로 등록하여 로그를 검색하고 대시보드로 보여줌
4.2. 로키 설치(Loki Stack)
4.2.1. 헬름 차트 준비
작업 디렉터리를 생성하고 그라파나 공식 헬름 리포지토리를 추가한다.
assu@myserver01:~/work/app$ pwd
/home/assu/work/app
assu@myserver01:~/work/app$ ll
total 32
drwxrwxr-x 8 assu assu 4096 Jan 4 03:02 ./
drwxrwxr-x 10 assu assu 4096 Jan 3 07:54 ../
drwxrwxr-x 3 assu assu 4096 Jan 3 08:54 argocd/
drwxrwxr-x 2 assu assu 4096 Dec 27 04:40 helm/
drwxrwxr-x 3 assu assu 4096 Dec 27 11:18 metallb/
drwxrwxr-x 3 assu assu 4096 Jan 4 02:08 metric-server/
drwxrwxr-x 3 assu assu 4096 Dec 27 06:45 nginx-ingress-controller/
drwxrwxr-x 3 assu assu 4096 Jan 4 03:07 prometheus/
assu@myserver01:~/work/app$ mkdir loki
assu@myserver01:~/work/app$ cd loki/
assu@myserver01:~/work/app/loki$ helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
assu@myserver01:~/work/app/loki$ helm repo update
우리는 loki-stack 차트를 사용할 것이다.
이 차트는 로키와 프롬테일을 한 번에 설치해준다.
assu@myserver01:~/work/app/loki$ helm search repo loki
NAME CHART VERSION APP VERSION DESCRIPTION
...
grafana/loki-stack 2.10.3 v2.9.3 Loki: like Prometheus, but for logs.
...
assu@myserver01:~/work/app/loki$ helm pull grafana/loki-stack
assu@myserver01:~/work/app/loki$ ls
loki-stack-2.10.3.tgz
assu@myserver01:~/work/app/loki$ tar xvfz loki-stack-2.10.3.tgz
assu@myserver01:~/work/app/loki$ ls
loki-stack loki-stack-2.10.3.tgz
assu@myserver01:~/work/app/loki$ mv loki-stack loki-stack-2.10.3
assu@myserver01:~/work/app/loki$ ls
loki-stack-2.10.3 loki-stack-2.10.3.tgz
4.2.2. values.yaml 수정
설정 파일을 복사하여 my-values.yaml 을 생성한다.
assu@myserver01:~/work/app/loki$ cd loki-stack-2.10.3/
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ ls
charts Chart.yaml README.md requirements.lock requirements.yaml templates values.yaml
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ cp values.yaml my-values.yaml
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ ls
charts Chart.yaml my-values.yaml README.md requirements.lock requirements.yaml templates values.yaml
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$
이미 kube-prometheus-stack을 통해 프로메테우스와 그라파나를 설치했다.
따라서 loki-stack에서는 그라파나와 프로메테우스를 중복 설치하지 않도록 비활성화하고, 로그 수집에 필요한 로키와 프롬테일만 활성화한다.
test_pod:
enabled: true
...
loki:
enabled: true
...
promtail:
enabled: true...
4.2.3. 설치 및 확인
myloki 네임스페이스를 생성하고 로키 스택을 배포한다.
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ kubectl create namespace myloki
namespace/myloki created
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ kubectl get namespace
NAME STATUS AGE
...
myloki Active 13s # 확인
...
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ helm install -n myloki \
> --generate-name grafana/loki-stack -f my-values.yaml
level=WARN msg="this chart is deprecated"
NAME: loki-stack-1768029200
LAST DEPLOYED: Sat Jan 10 07:13:21 2026
NAMESPACE: myloki
STATUS: deployed
REVISION: 1
DESCRIPTION: Install complete
NOTES:
The Loki stack has been deployed to your cluster. Loki can now be added as a datasource in Grafana.
See http://docs.grafana.org/features/datasources/loki/ for more detail.
설치 후 상태를 확인한다.
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ kubectl get all -n myloki -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/loki-stack-1768029200-0 1/1 Running 0 7m40s 192.168.131.122 myserver02 <none> <none>
pod/loki-stack-1768029200-promtail-4lz8f 0/1 Running 0 7m40s 192.168.143.195 myserver01 <none> <none>
pod/loki-stack-1768029200-promtail-fwf5m 1/1 Running 0 7m40s 192.168.131.121 myserver02 <none> <none>
pod/loki-stack-1768029200-promtail-hpknz 0/1 Running 0 7m40s 192.168.149.249 myserver03 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/loki-stack-1768029200 ClusterIP 10.109.170.180 <none> 3100/TCP 7m40s app=loki,release=loki-stack-1768029200
service/loki-stack-1768029200-headless ClusterIP None <none> 3100/TCP 7m40s app=loki,release=loki-stack-1768029200
service/loki-stack-1768029200-memberlist ClusterIP None <none> 7946/TCP 7m40s app=loki,release=loki-stack-1768029200
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
daemonset.apps/loki-stack-1768029200-promtail 3 3 1 3 1 <none> 7m40s promtail docker.io/grafana/promtail:3.5.1 app.kubernetes.io/instance=loki-stack-1768029200,app.kubernetes.io/name=promtail
...
- Loki Pod
- StatefulSet으로 관리되며 1개가 실행된다.
- Promtail Pod
- DaemonSet으로 관리되며 클러스터의 모든 노드(여기서는 3개)에 각각 하나씩 실행된다.
특정 파드의 로그를 보고 싶다면 아래와 같이 보면 된다.
assu@myserver01:~/work/app/loki/loki-stack-2.10.3$ kubectl describe pod loki-stack-1768029200-promtail-4lz8f -n myloki
4.3. 로그 확인(테스트 앱 배포)
로그가 잘 수집되는지 확인하기 위해, 접속 시 로그를 남기는 간단한 Flask 애플리케이션을 배포한다.
4.2.1. 배포용 매니페스트 작성 및 Push 에서 진행했던 디렉터리로 이동하여 디플로이먼트, 서비스, 인그레스를 실행한다.
assu@myserver01:~/work/ch10/ex02$ cd ~/work/ch10
assu@myserver01:~/work/ch10$ ls
ex01 ex02 ex03
assu@myserver01:~/work/ch10$ cd ex02
assu@myserver01:~/work/ch10/ex02$ ls
flask-deploy.yml flask-ingress.yml flask-service.yml myFlask02 myNginx02f
assu@myserver01:~/work/ch10/ex02$ kubectl apply -f flask-deploy.yml
deployment.apps/deploy-flask created
assu@myserver01:~/work/ch10/ex02$ kubectl apply -f flask-service.yml
service/flask-service created
assu@myserver01:~/work/ch10/ex02$ kubectl apply -f flask-ingress.yml
ingress.networking.k8s.io/flask-ingress created
assu@myserver01:~/work/ch10/ex02$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/deploy-flask-b8ffb7c86-qm22s 2/2 Running 0 30s
pod/deploy-flask-b8ffb7c86-qzjwm 2/2 Running 0 30s
pod/deploy-flask-b8ffb7c86-w587h 2/2 Running 0 30s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flask-service ClusterIP 10.99.99.174 <none> 80/TCP 22s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 15d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/deploy-flask 3/3 3 3 30s
NAME DESIRED CURRENT READY AGE
replicaset.apps/deploy-flask-b8ffb7c86 3 3 3 30s
assu@myserver01:~/work/ch10/ex02$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
flask-ingress nginx * 80 35s
배포가 완료되면 http://127.0.0.1:2002/test02 등으로 접속하여 트래픽을 발생시킨다.
화면에 hello world! 가 출력되면 로그가 생성된 것이다.
4.4. 그라파나와 로키 연동 및 로그 조회
이제 그라파나(화면)와 로키(데이터)를 연결해본다.
4.4.1. 데이터 소스(Data Source) 추가
- 그라파나(http://127.0.0.1:2002/)에 접속한다.
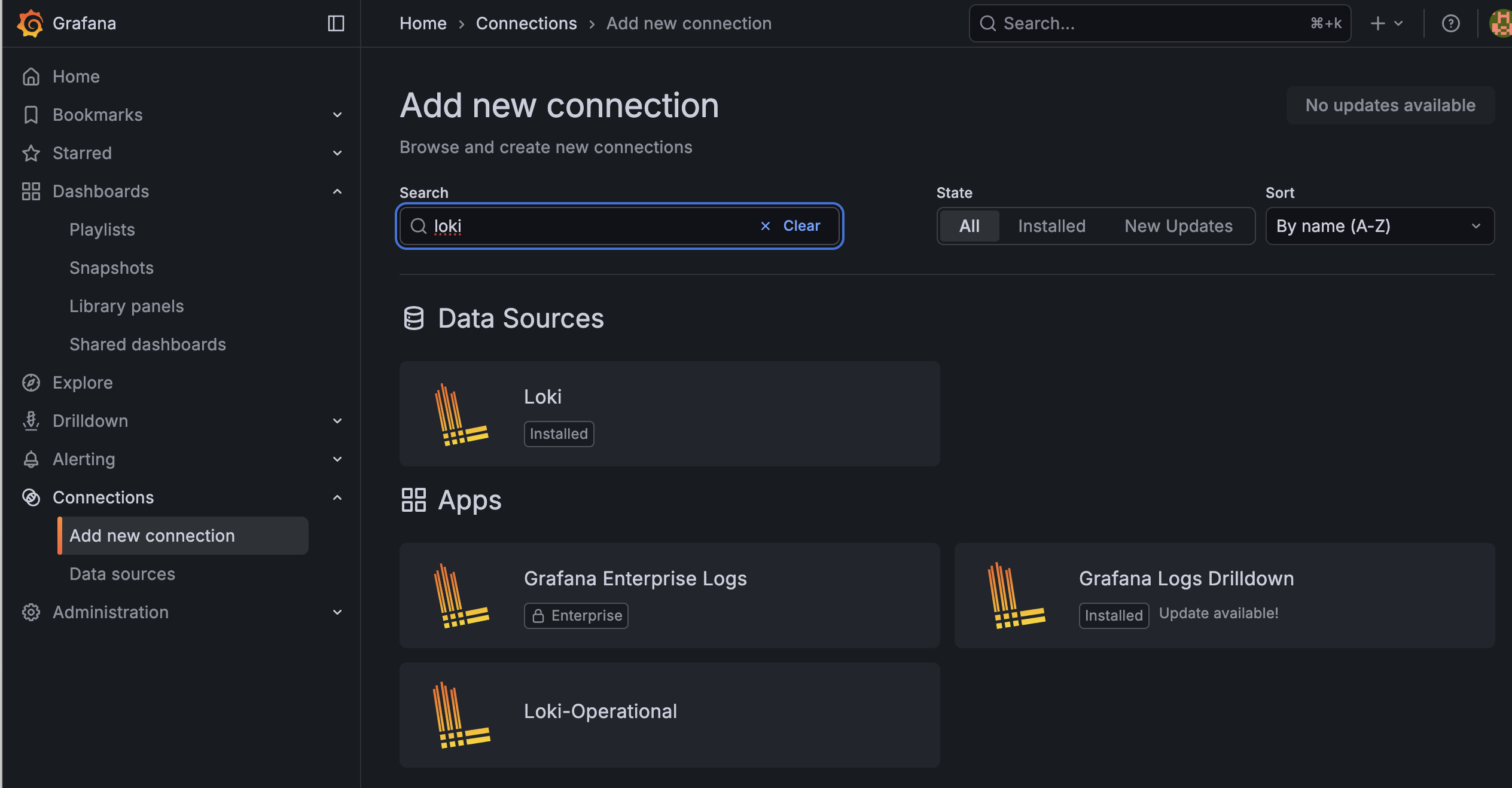
- 좌측 메뉴 Connections > Add new connection 으로 이동한다.
- Loki를 검색하고 클릭한 뒤, 우측 상단의 Add new data source를 누른다.
4.4.2. 연결 정보 설정
로키 서비스의 내부 도메인 주소를 입력해야 한다. 먼저 서비스 이름을 확인한다.
assu@myserver01:~/work/ch10/ex02$ kubectl get svc -n myloki
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki-stack-1768029200 ClusterIP 10.109.170.180 <none> 3100/TCP 29m
loki-stack-1768029200-headless ClusterIP None <none> 3100/TCP 29m
loki-stack-1768029200-memberlist ClusterIP None <none> 7946/TCP 29m
설정값:
- Name: Loki(임시 지정)
- URL: http://loki-stack-1768029200.myloki:3100
- 형식:
http://<로키서비스이름>.<네임스페이스>:3100
- 형식:
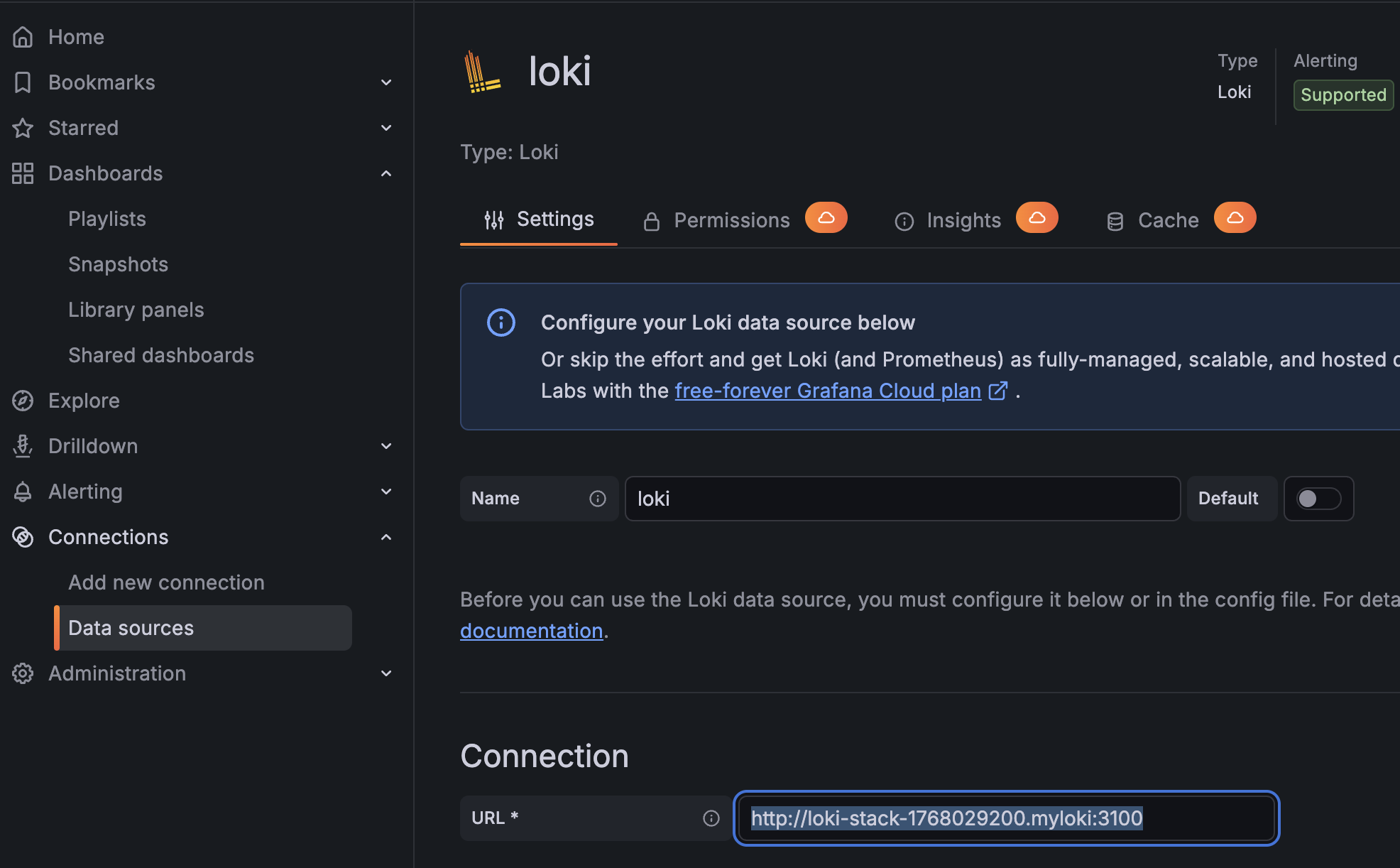
Save & test 버튼을 누른다.
4.4.3. 로그 쿼리(LogQL)
이제 실제로 로그를 검색해보자.
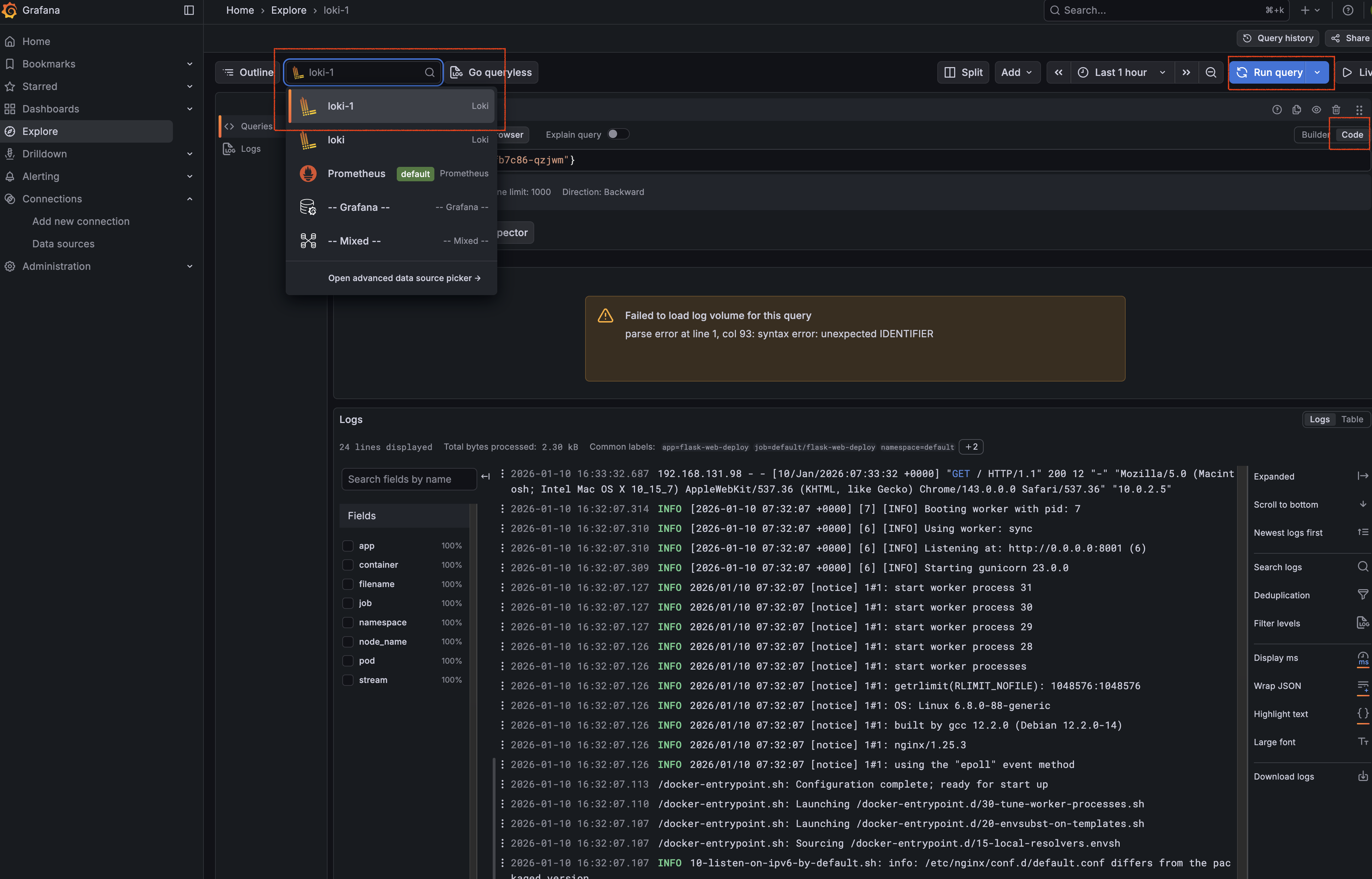
- 좌측 메뉴의 Explore를 클릭한다.
- 좌측 상단 데이터 소스 드롭다운에서 방금 추가한 Loki를 선택한다.
- Label filters 혹은 Code 모드에서 쿼리를 입력한다.
- 쿼리 형식:
{pod="파드 이름"} - 예:
{pod="deploy-flask-b8ffb7c86-qm22s"}
- 쿼리 형식:
우측 상단의 Run query를 클릭하면 아래와 같이 해당 파드에서 발생한 로그가 시간순으로 출력된다.
{namespace="default"} 처럼 네임스페이스 단위로 검색하거나, |= "error"와 같이 특정 문자열이 포함된 로그만 필터링할 수도 있다.
파드 이름은 아래와 같이 확인한다.
assu@myserver01:~/work/ch10/ex02$ kubectl get pod
NAME READY STATUS RESTARTS AGE
deploy-flask-b8ffb7c86-qm22s 2/2 Running 0 33m
deploy-flask-b8ffb7c86-qzjwm 2/2 Running 0 33m
deploy-flask-b8ffb7c86-w587h 2/2 Running 0 33m
이제 리소스를 정리한다.
assu@myserver01:~/work/ch10/ex02$ kubectl delete -f flask-ingress.yml
ingress.networking.k8s.io "flask-ingress" deleted
assu@myserver01:~/work/ch10/ex02$ kubectl delete -f flask-service.yml
service "flask-service" deleted
assu@myserver01:~/work/ch10/ex02$ kubectl delete -f flask-deploy.yml
deployment.apps "deploy-flask" deleted
assu@myserver01:~/work/ch10/ex02$ kubectl get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 15d
정리하며..
- Metrics Server
kubectl top을 통해 노드와 파드의 즉각적인 리소스 사용량을 확인한다.
- Prometheus
- 시계열 데이터 수집의 표준인 프로메테우스를 헬름으로 구축하고 Node Exporter 데이터를 확인한다.
- Grafana
- 프로메테우스와 연동하여 리소스 사용량을 시각화하고, 외부 대시보드를 임포트하여 모니터링 환경을 완성할 수 있다.
- Loki(PLG Stack)
- 분산된 노드의 로그를 중앙으로 수집하고, 그라파나에서 통합 조회하는 환경을 구축할 수 있다.
참고 사이트 & 함께 보면 좋은 사이트
본 포스트는 장철원 저자의 한 권으로 배우는 도커&쿠버네티스를 기반으로 스터디하며 정리한 내용들입니다.
